Лекция курса "Большие данные и машинное обучение" (v2.0-МОТ)
Лекция-3: табличные данные в Python, библиотека Pandas
- Python + NumPy + Pandas + CSV: «эксель» без мышки (работа с табличными данными)
- Табличные данные и массивы в Python: Pandas и Numpy
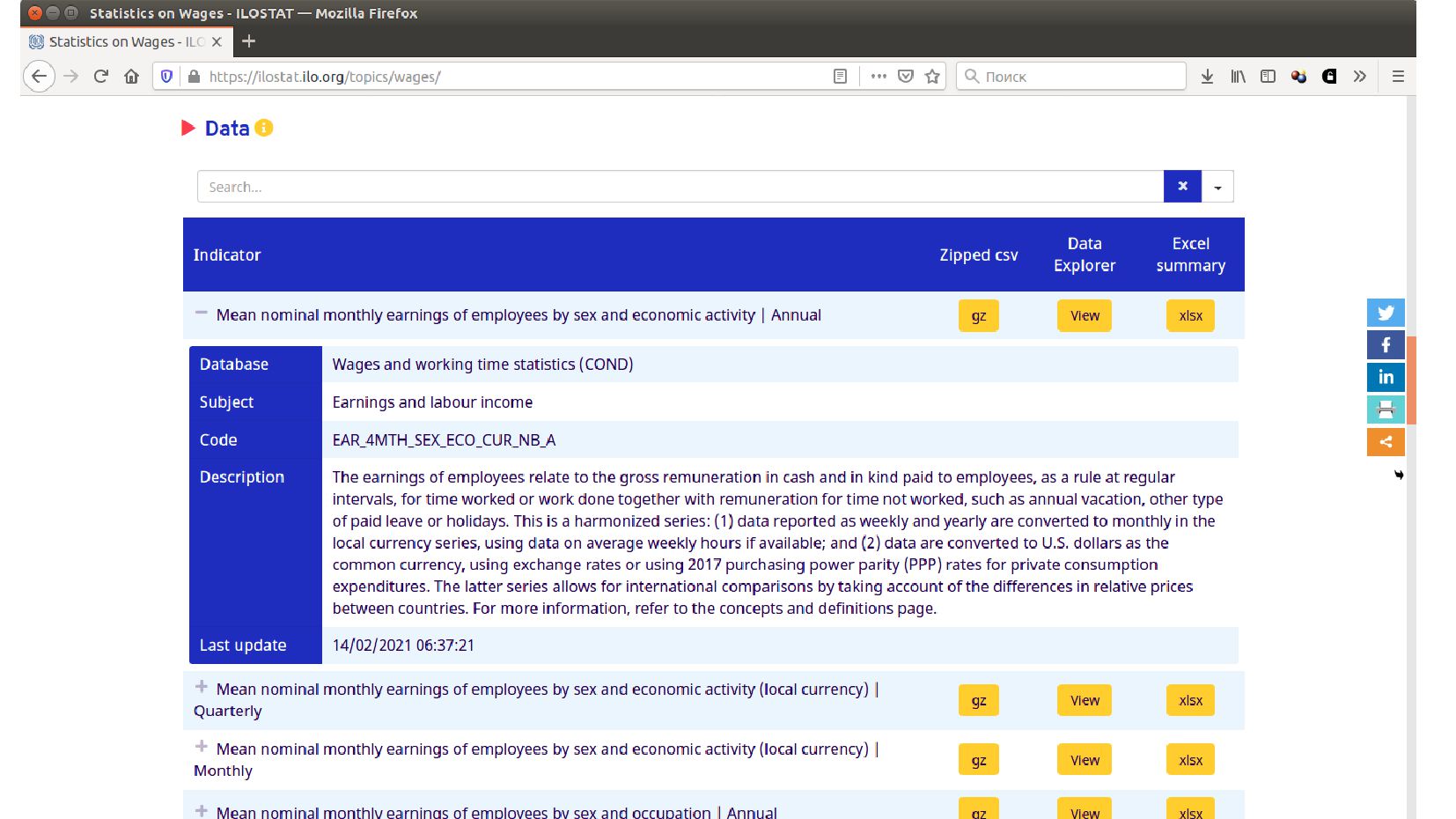
- Качаем данные: датасет ILO (МОТ - Международная организация труда) ilostat.ilo.org
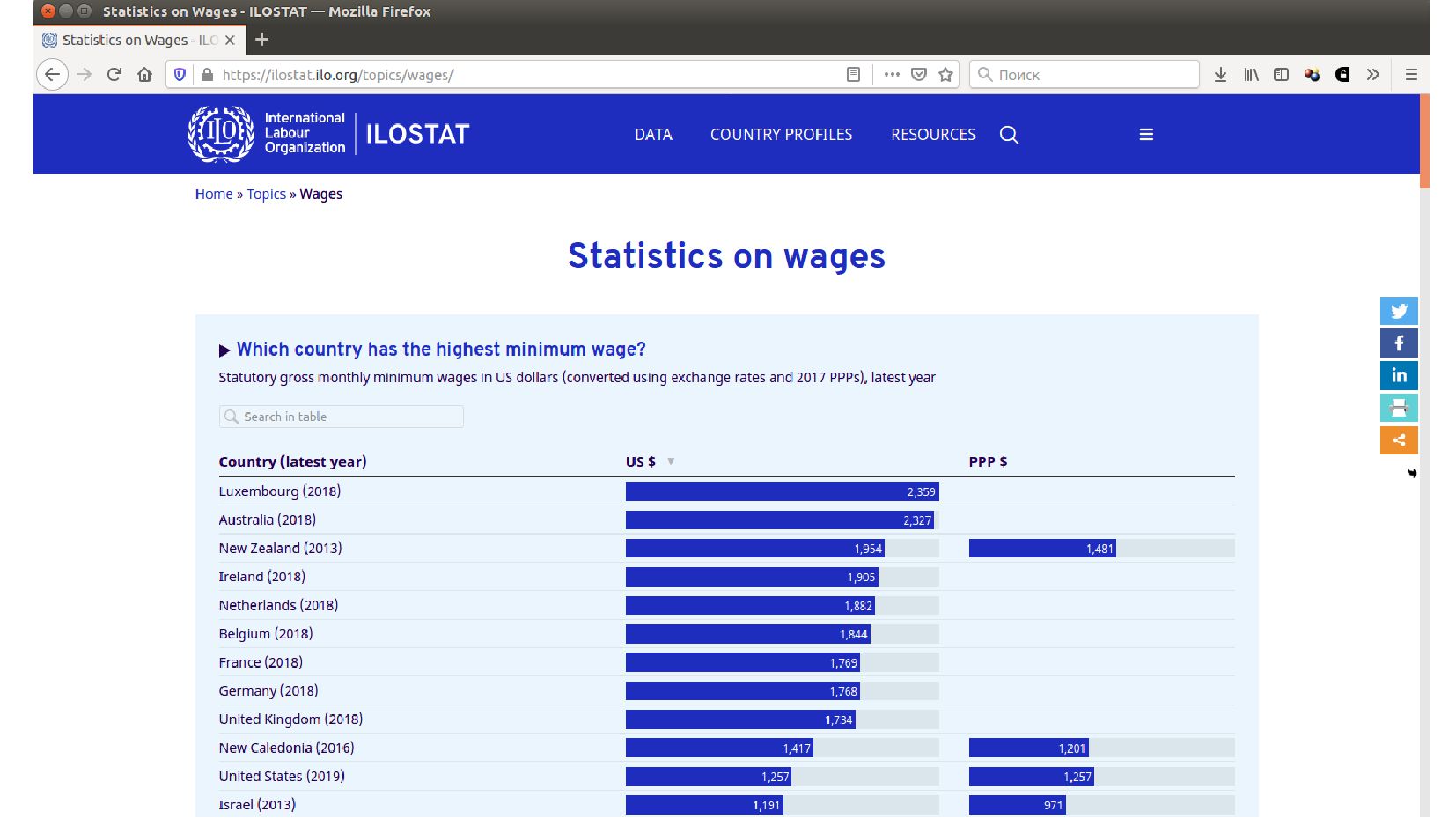
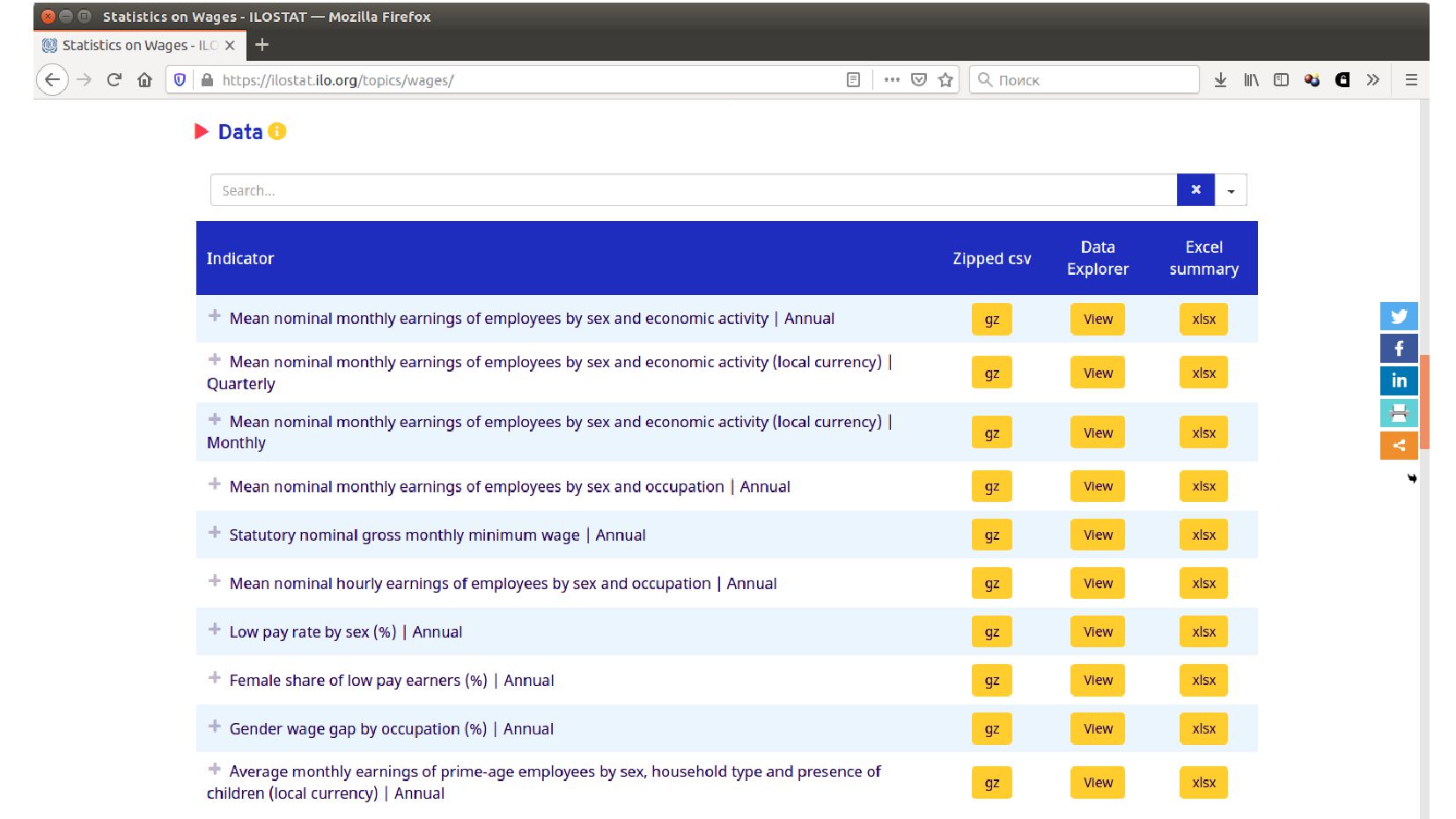
- Таблица для анализа: средня зарплата по видам деятельности, полу, странам и годам
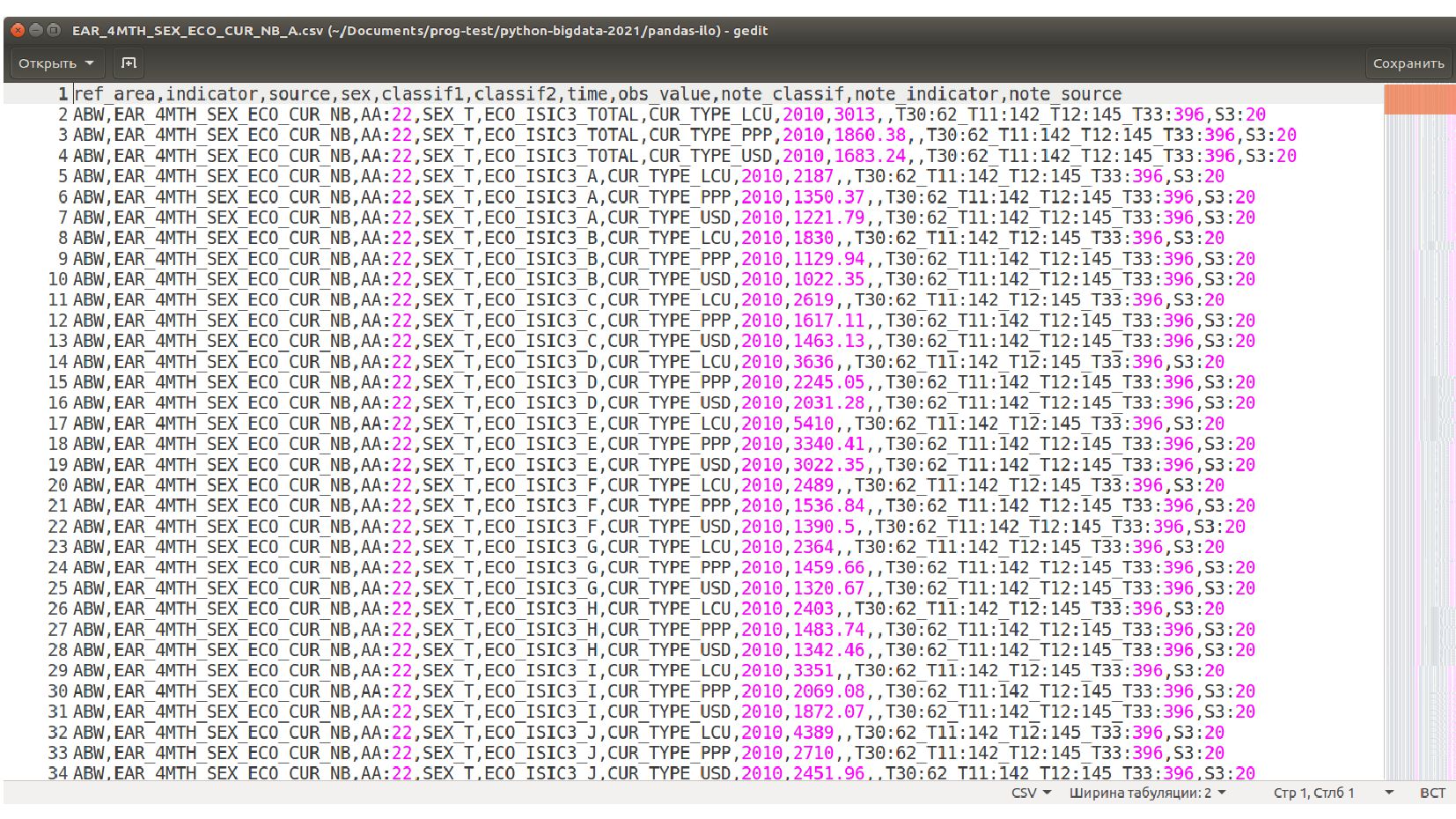
- Формат хранения табличных данных в тексте CSV - comma separated values, RFC-4180
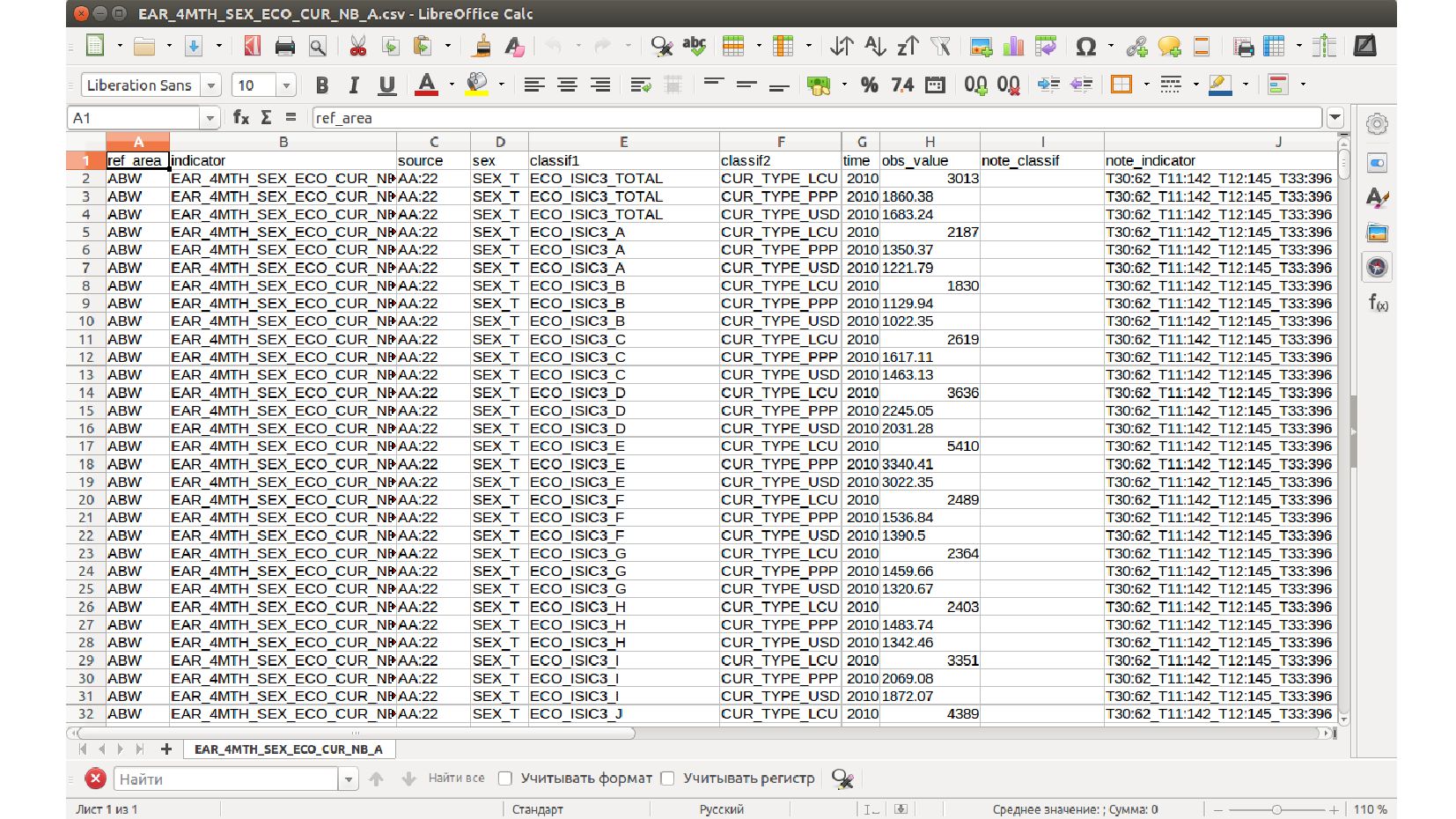
- Загружаем данные из файла CSV
- Pandas DataFrame - таблица, с которой можно делать что угодно (она же 2д-массив NumPy)
- Произвольный доступ к данным: диапазон строк, диапазон колонок, доступ к отдельный ячейке
- Оператор "квадратные скобки" DataFrame[] vs DataFrame.iloc[]
- Pandas Series - отдельная колонка таблицы (она же 1д-массив NumPy)
- Доступ к колонкам: через квадратные скобки по имени vs ООП-стиль через точку
- Запросы к данным: фильтр строк по значениям, больше волшебства оператора "квадратные скобки"
- Фильтр данных по значениям строковых значений
- Фильтр данных по диапазонам числовых значений
- Составные фильтры: средняя зарплата в стране за выбранный диапазон лет
- Разоблачение волшебства запросов через квадратные скобки: фильтрация данных массивом булевых значений
- Поэлементные логические операторы NumPy
- Статистические операции: минимум (min), максимум (max), среднее (mean), медиана (median)
- Среднее vs медиана (cредняя зарплата vs медианная зарплата)
- Проверка данных на правдоподобность, дополнительная проверка в сторонних источниках: откуда бы ни пришел датасет, всегда ожидайте подвох
- Больше загрузки данных: переименование колонок для приведения к удобному для использования в программе виду
- Склеивание таблиц по ключу: DataFrame.join
- Подключаем к таблице колонку с полным названием страны в дополнение к колонке с трехбуквенным кодом
- Итоги лекции: извлечение знаний из массивов данных
- Задания на самостоятельную работу
Большие данные и машинное обучение, лекция-2: предварительная подготовка, платформа Python
https://www.youtube.com/watch?v=GXbBDaKCiD8 (вторая половина)
Большие данные и машинное обучение, лекция-3: табличные данные в Python, библиотека Pandas
https://www.youtube.com/watch?v=ODFwEwMe8X0
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![] python pandas-ilo-test.py](https://files.speakerdeck.com/presentations/30dc1bc54b89458499caef6fba37df7b/slide_34.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
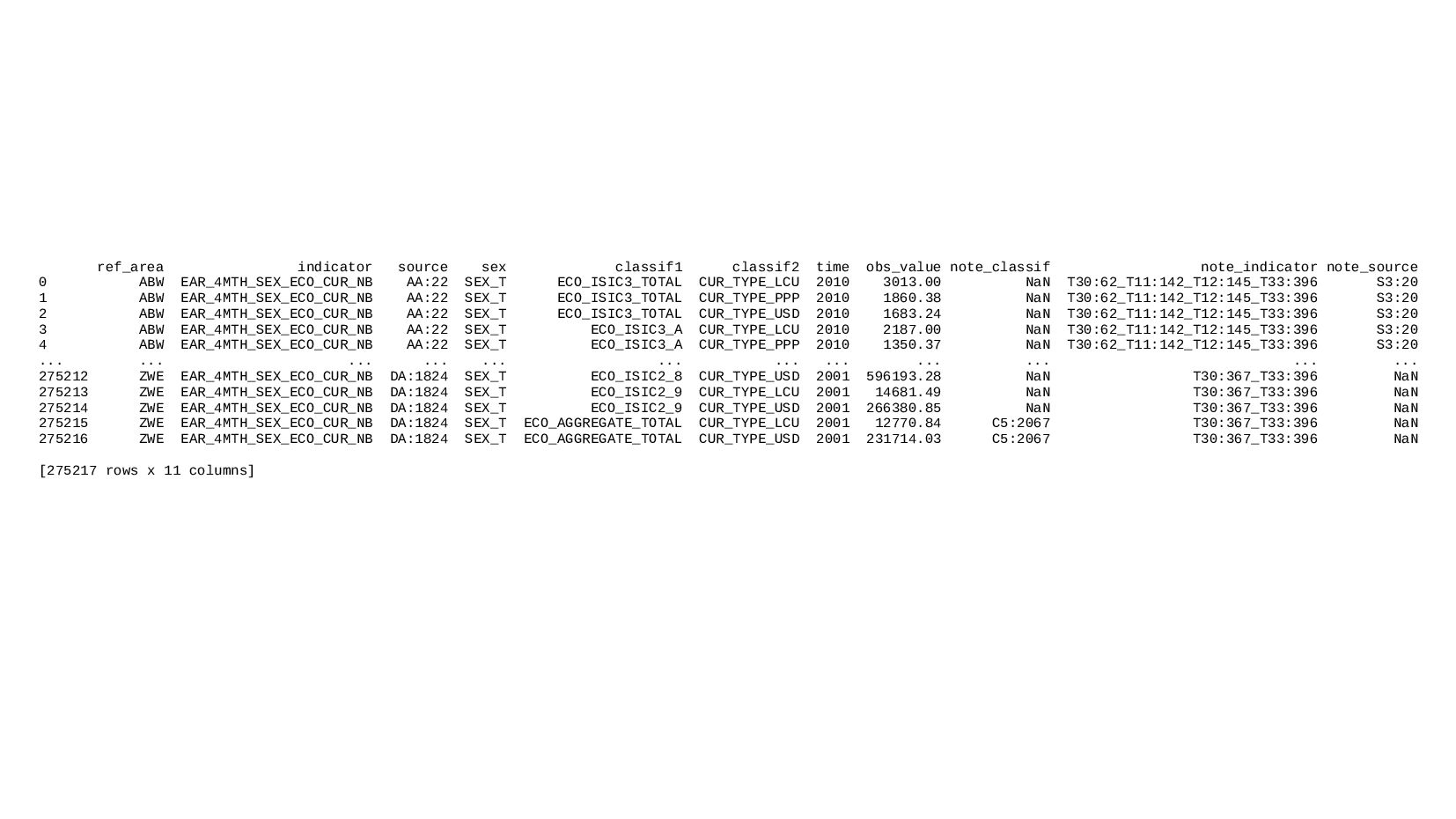
![print( "Column count:" ) print( data.shape[1] ) Column count: 11](https://files.speakerdeck.com/presentations/30dc1bc54b89458499caef6fba37df7b/slide_38.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![print( data[:10] ) Произвольный диапазон: первые 10 строк ref_area indicator](https://files.speakerdeck.com/presentations/30dc1bc54b89458499caef6fba37df7b/slide_43.jpg){kind=link}
![print( data[4:10] ) ref_area indicator source sex classif1 classif2 time](https://files.speakerdeck.com/presentations/30dc1bc54b89458499caef6fba37df7b/slide_44.jpg){kind=link}
{kind=link}
![Отдельная строка по индексу print( data[4] ) <= ERROR Traceback](https://files.speakerdeck.com/presentations/30dc1bc54b89458499caef6fba37df7b/slide_46.jpg){kind=link}
![Отдельная строка по индексу print( data.iloc[4] ) ref_area ABW indicator](https://files.speakerdeck.com/presentations/30dc1bc54b89458499caef6fba37df7b/slide_47.jpg){kind=link}
![Значение ячейки в строке print( data.iloc[4]['ref_area'] ) ABW print( data.iloc[4]['obs_value']](https://files.speakerdeck.com/presentations/30dc1bc54b89458499caef6fba37df7b/slide_48.jpg){kind=link}
![Диапазон строк с диапазоном колонок print( data.iloc[4:12, 0:8] ) print(](https://files.speakerdeck.com/presentations/30dc1bc54b89458499caef6fba37df7b/slide_49.jpg){kind=link}
{kind=link}
![Оператор «квадратные скобки» []: DataFrame[] vs DataFrame.iloc[] • Квадратные скобки](https://files.speakerdeck.com/presentations/30dc1bc54b89458499caef6fba37df7b/slide_51.jpg){kind=link}
![Оператор «квадратные скобки» []: DataFrame[] vs DataFrame.iloc[] • Они во](https://files.speakerdeck.com/presentations/30dc1bc54b89458499caef6fba37df7b/slide_52.jpg){kind=link}
![Оператор «квадратные скобки» []: DataFrame[] vs DataFrame.iloc[] • При этом,](https://files.speakerdeck.com/presentations/30dc1bc54b89458499caef6fba37df7b/slide_53.jpg){kind=link}
{kind=link}
{kind=link}
![Значения отдельной колонки print( data['sex'] ) print( type(data['sex']) ) 0](https://files.speakerdeck.com/presentations/30dc1bc54b89458499caef6fba37df7b/slide_56.jpg){kind=link}
{kind=link}
![Количество элементов в колонке print( data['sex'].size ) 275217 • обратить](https://files.speakerdeck.com/presentations/30dc1bc54b89458499caef6fba37df7b/slide_58.jpg){kind=link}
![Обращение к колонкам: через скобки vs через точку print( data['sex'].size](https://files.speakerdeck.com/presentations/30dc1bc54b89458499caef6fba37df7b/slide_59.jpg){kind=link}
{kind=link}
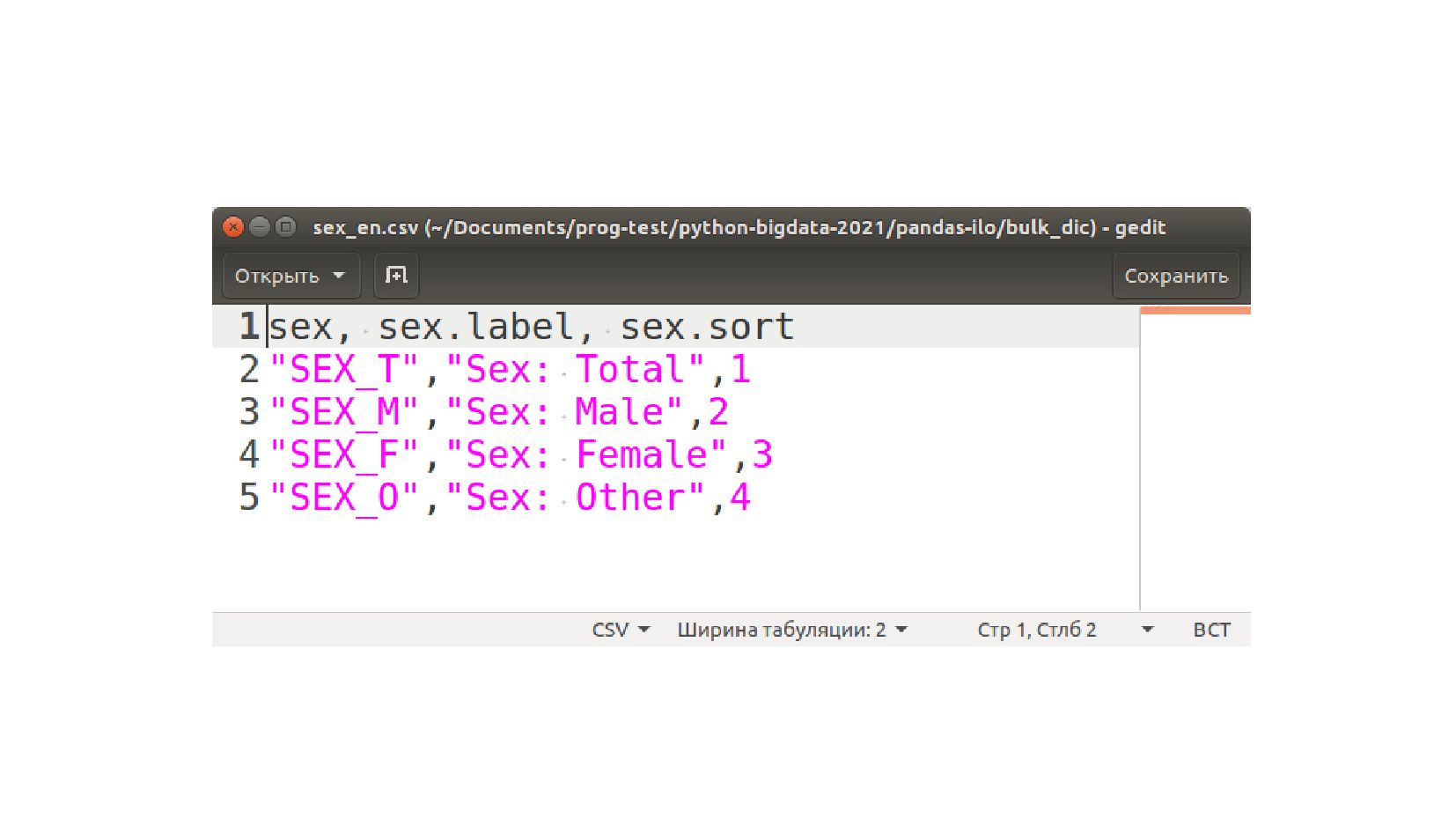
![print( data.sex.value_counts() ) print( data['sex'].value_counts() ) SEX_T 112279 SEX_M 82663](https://files.speakerdeck.com/presentations/30dc1bc54b89458499caef6fba37df7b/slide_61.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Посмотрим все страны print( data.ref_area.value_counts() ) print( data['ref_area'].value_counts() ) EGY](https://files.speakerdeck.com/presentations/30dc1bc54b89458499caef6fba37df7b/slide_68.jpg){kind=link}
{kind=link}
{kind=link}
![print( data[data.ref_area == 'USA'] ) ref_area indicator source sex classif1](https://files.speakerdeck.com/presentations/30dc1bc54b89458499caef6fba37df7b/slide_71.jpg){kind=link}
{kind=link}
![Данные по России print( data[data.ref_area == 'RUS'] ) ref_area indicator](https://files.speakerdeck.com/presentations/30dc1bc54b89458499caef6fba37df7b/slide_73.jpg){kind=link}
{kind=link}
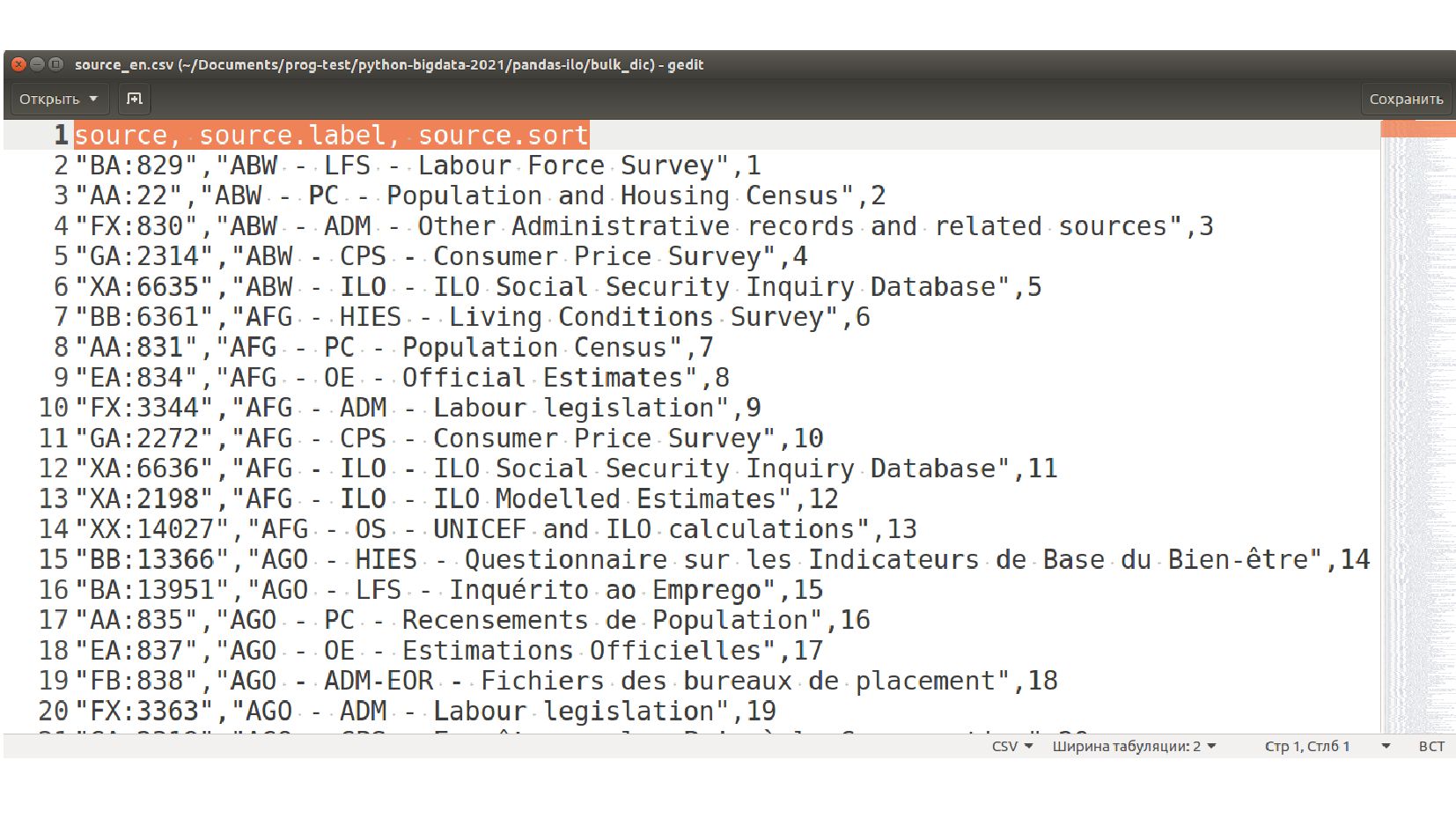{kind=link}
{kind=link}
{kind=link}
{kind=link}
![print( data[data.ref_area == 'RUS'].time .value_counts() ) 2017 162 2019 108](https://files.speakerdeck.com/presentations/30dc1bc54b89458499caef6fba37df7b/slide_79.jpg){kind=link}
![print( data[data.ref_area == 'RUS'].time .value_counts().sort_index() ) 1982 6 1983 6](https://files.speakerdeck.com/presentations/30dc1bc54b89458499caef6fba37df7b/slide_80.jpg){kind=link}
{kind=link}
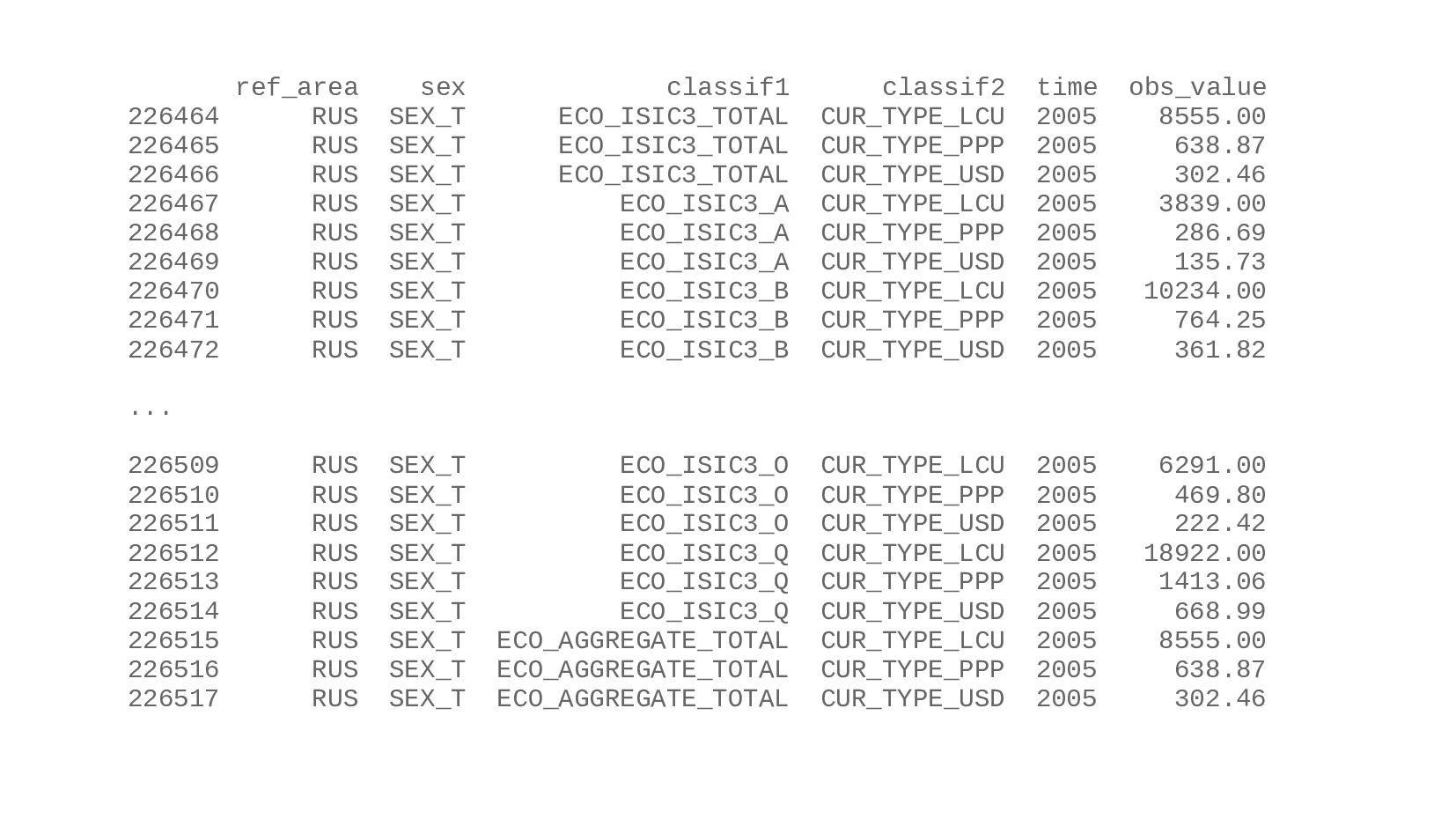{kind=link}
{kind=link}
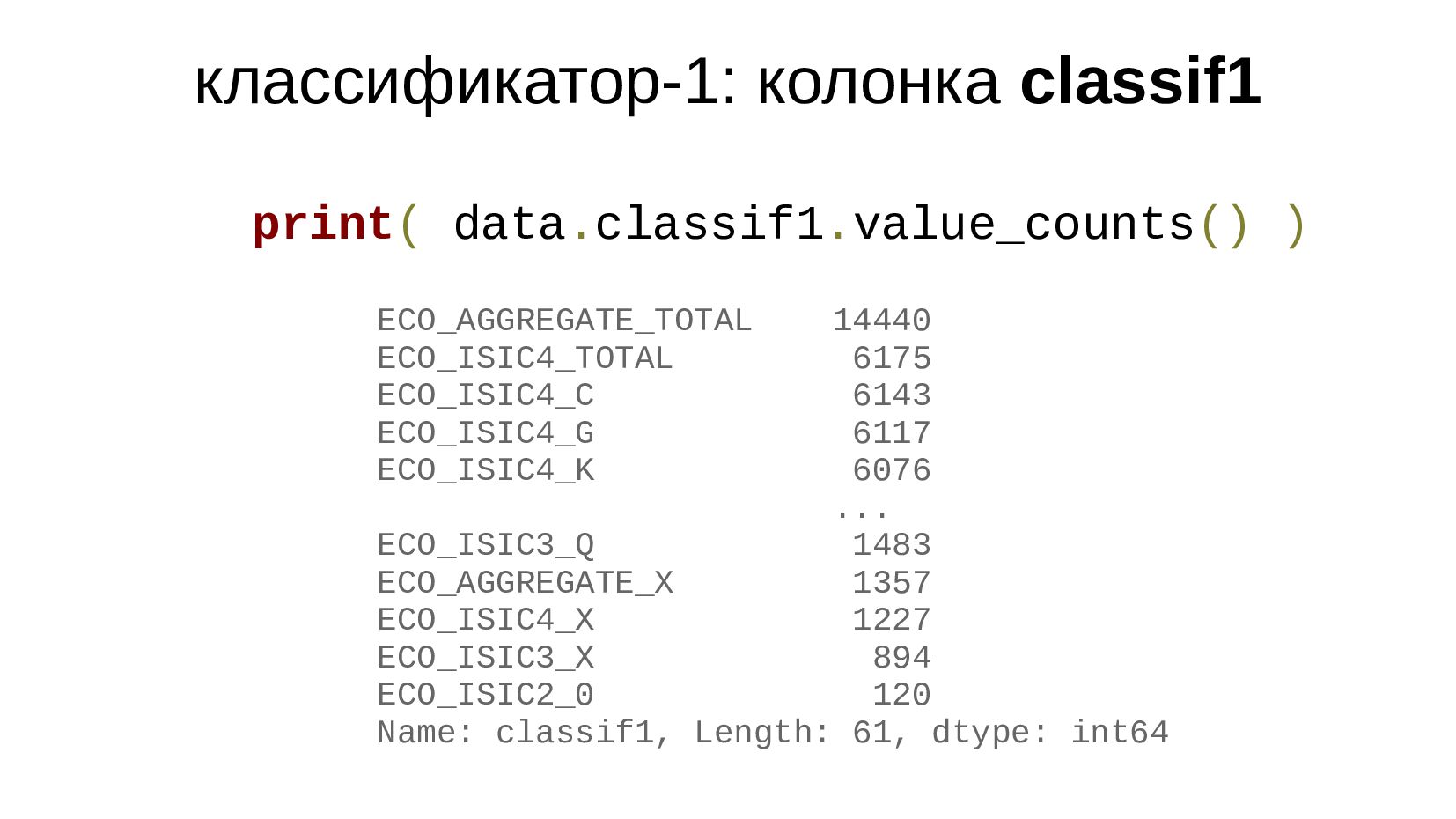{kind=link}
{kind=link}
{kind=link}
{kind=link}
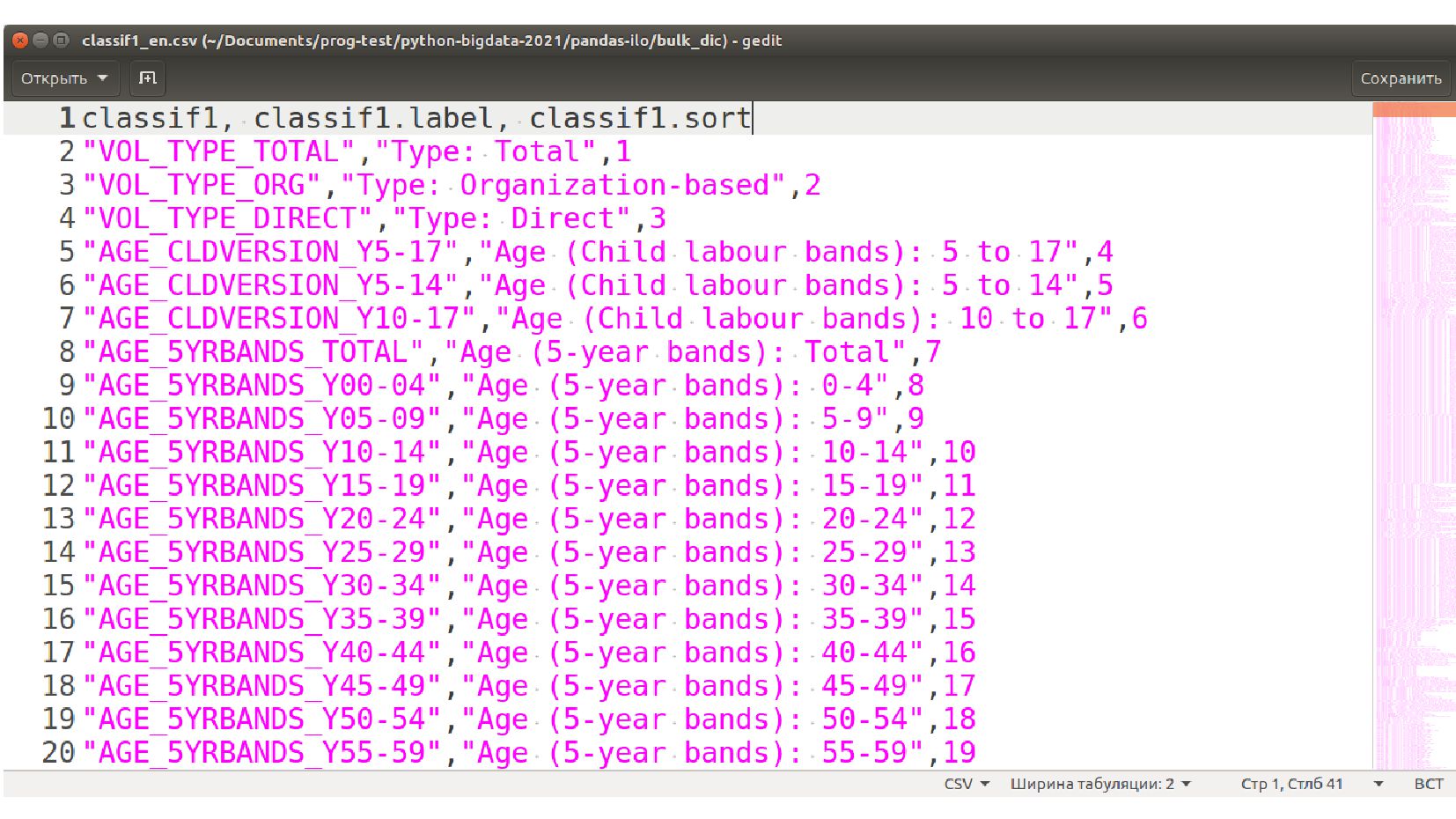{kind=link}
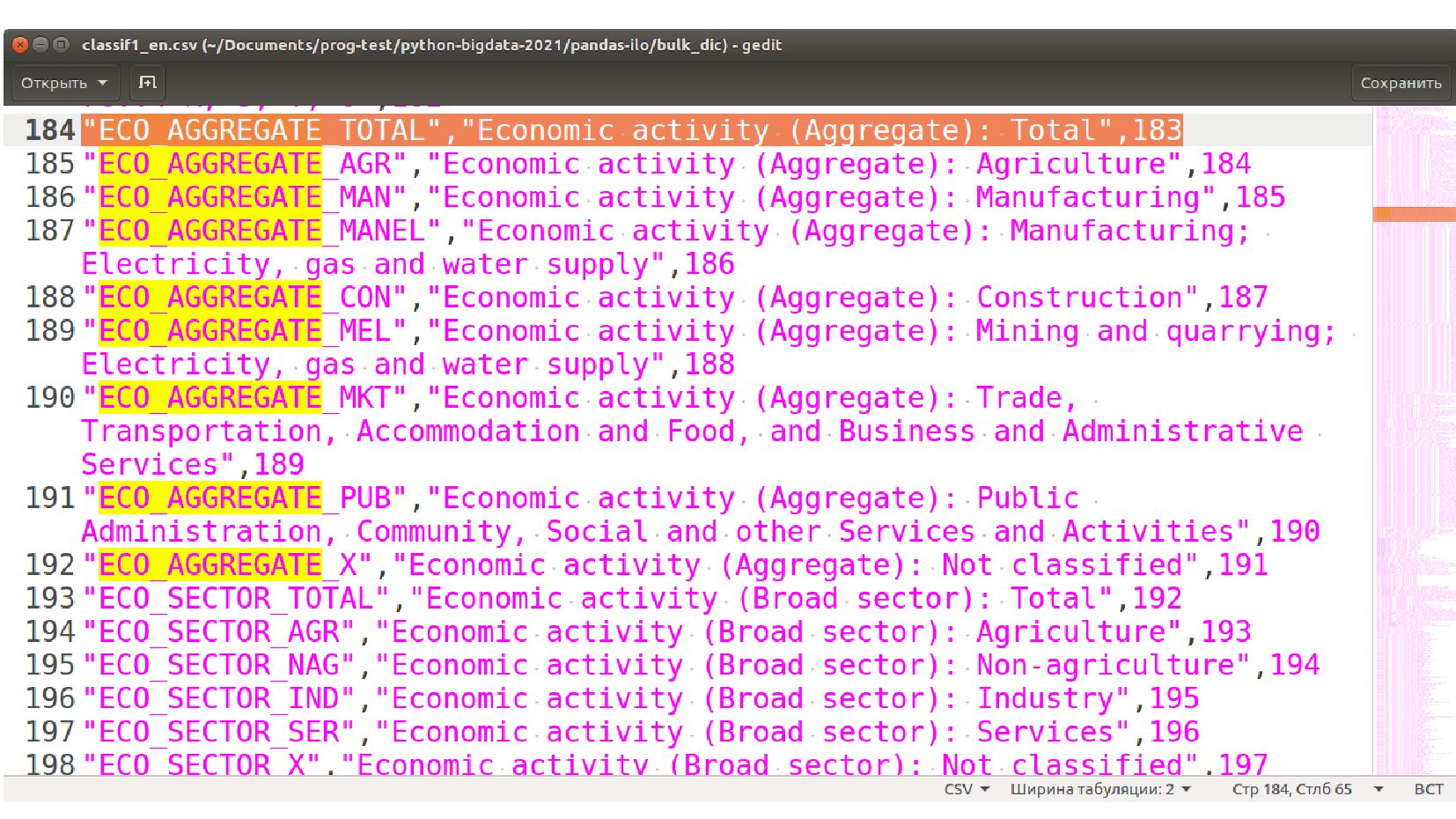{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
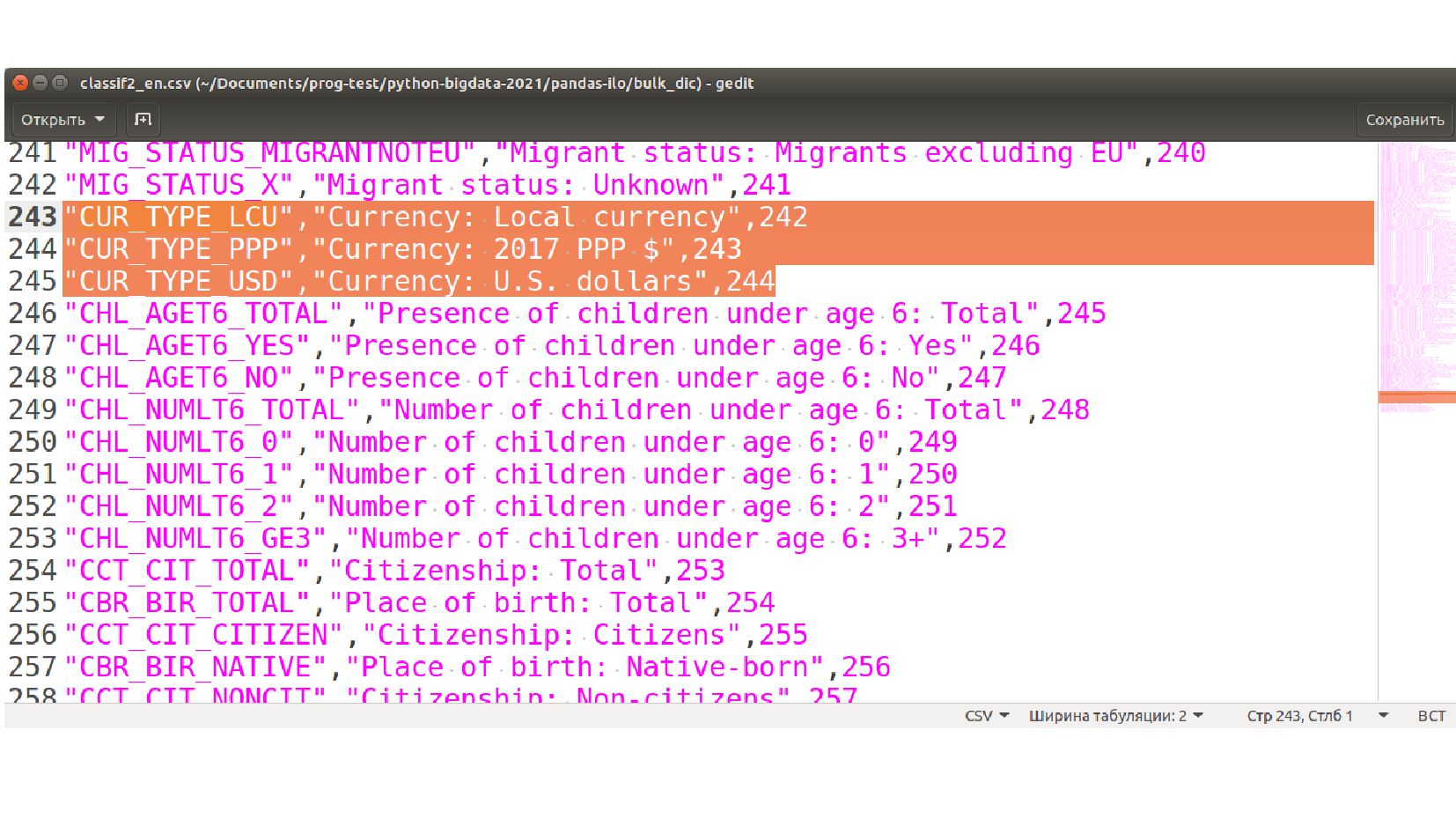{kind=link}
{kind=link}
{kind=link}
{kind=link}
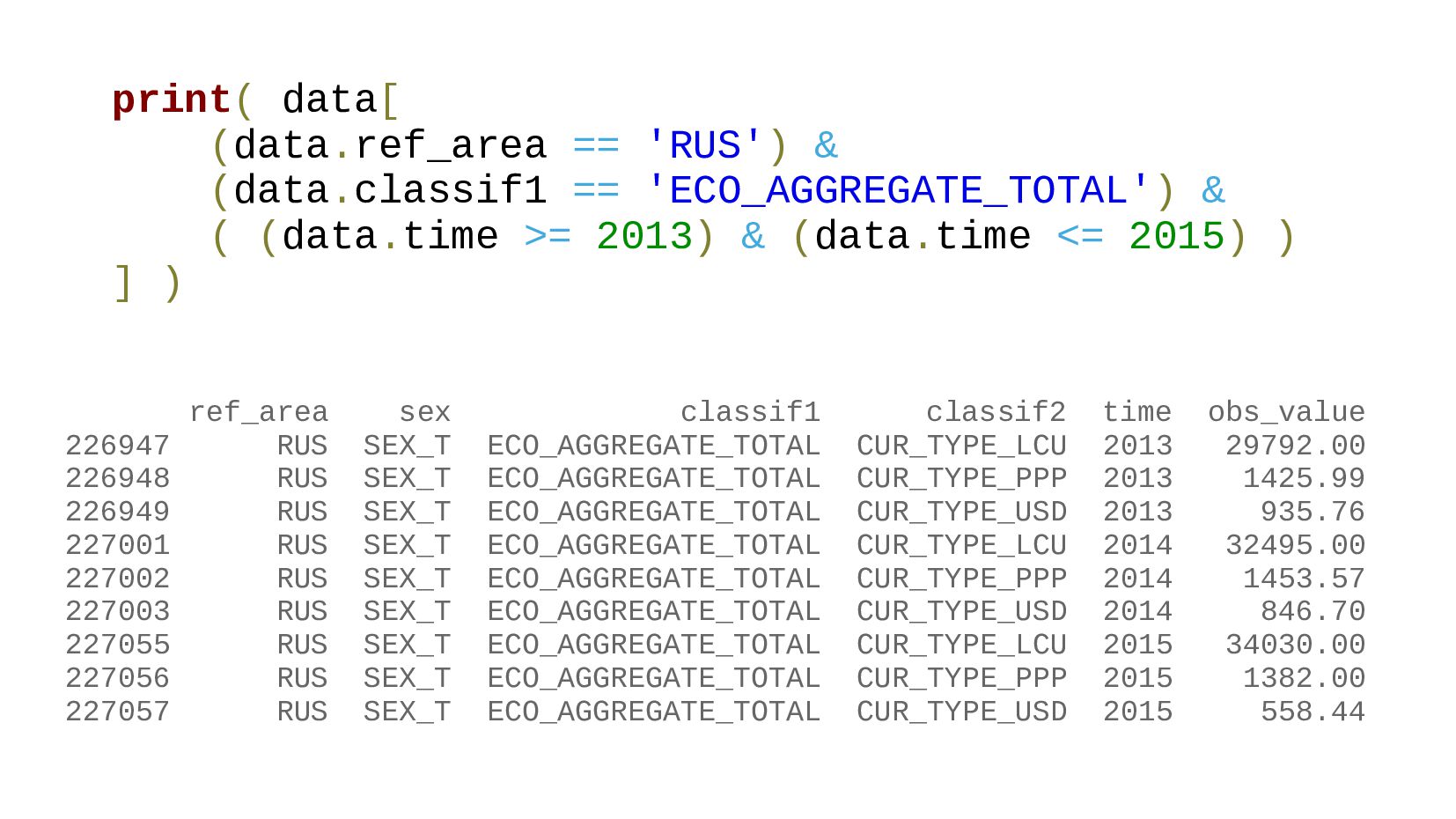{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
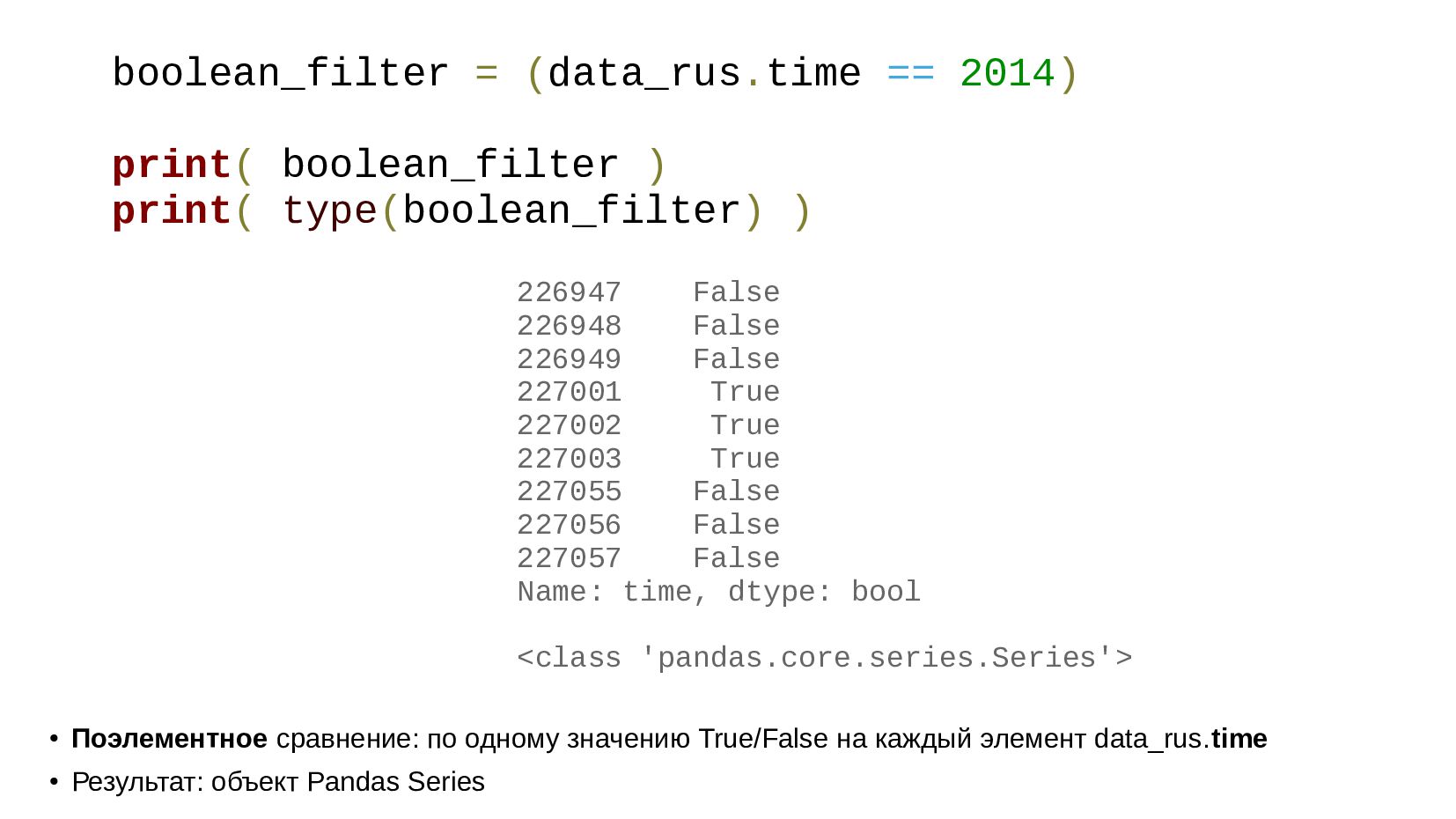{kind=link}
![print( data_rus[boolean_filter] ) ref_area sex classif1 classif2 time obs_value 227001](https://files.speakerdeck.com/presentations/30dc1bc54b89458499caef6fba37df7b/slide_105.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
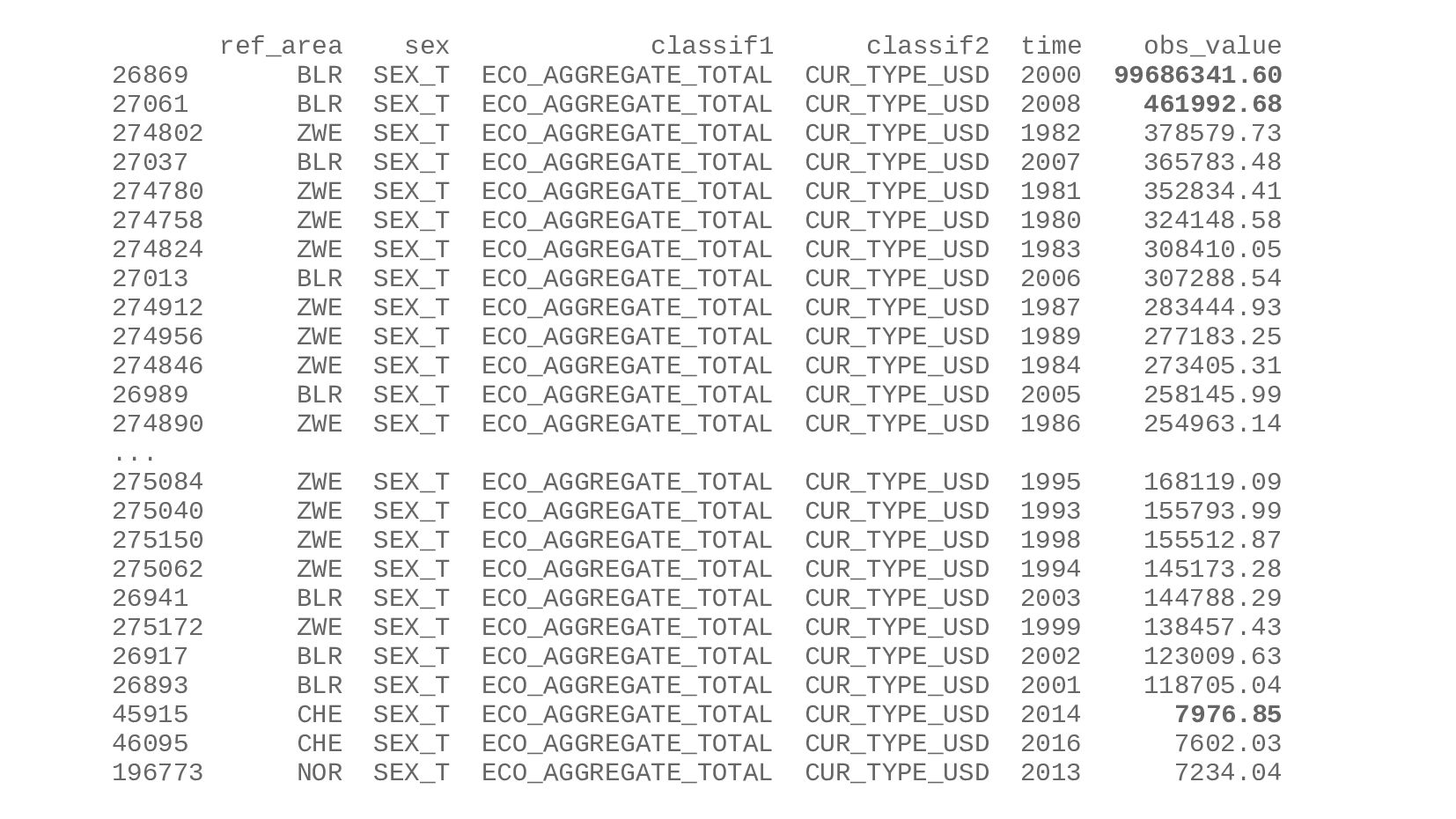{kind=link}
{kind=link}
{kind=link}
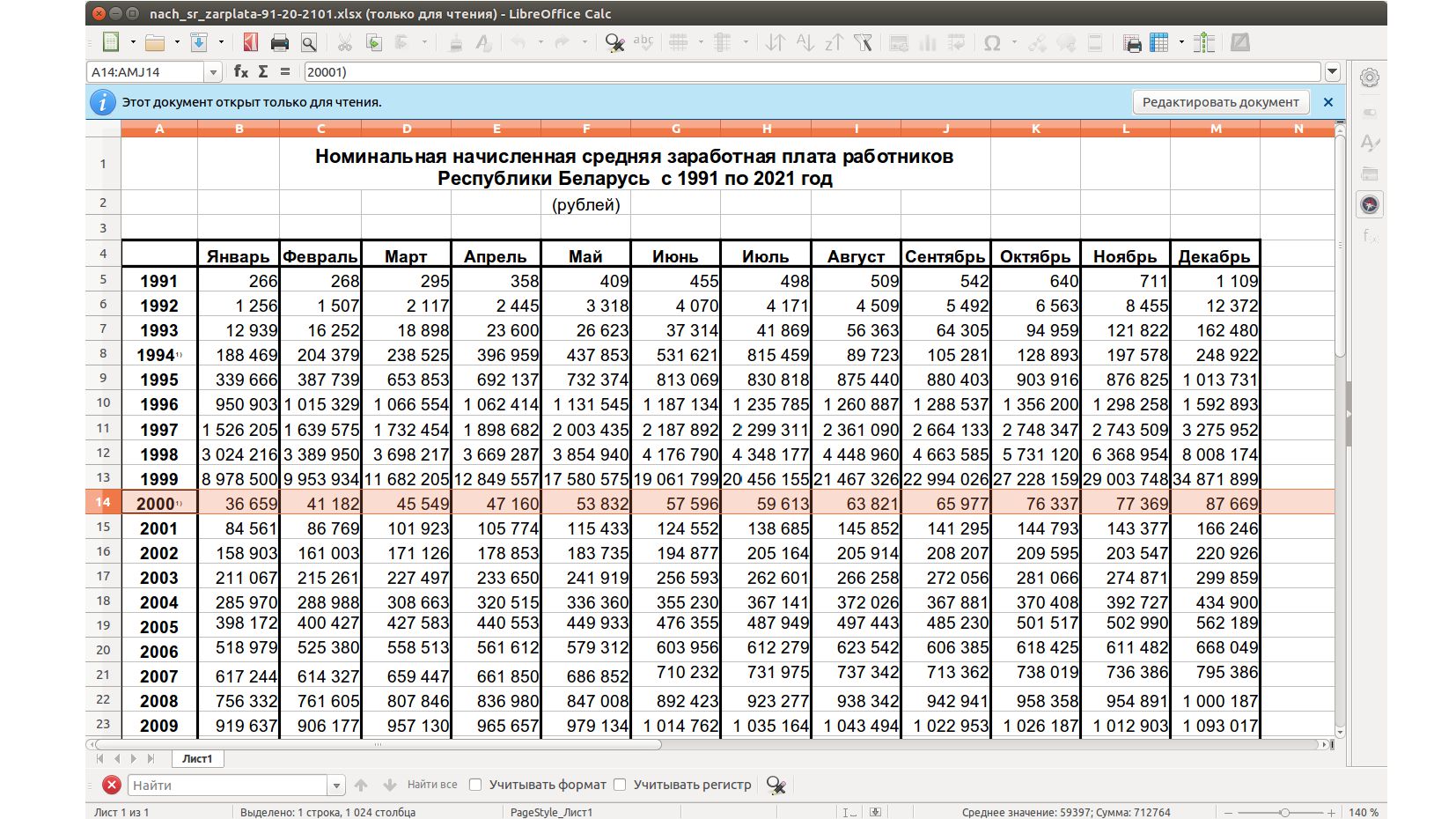{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
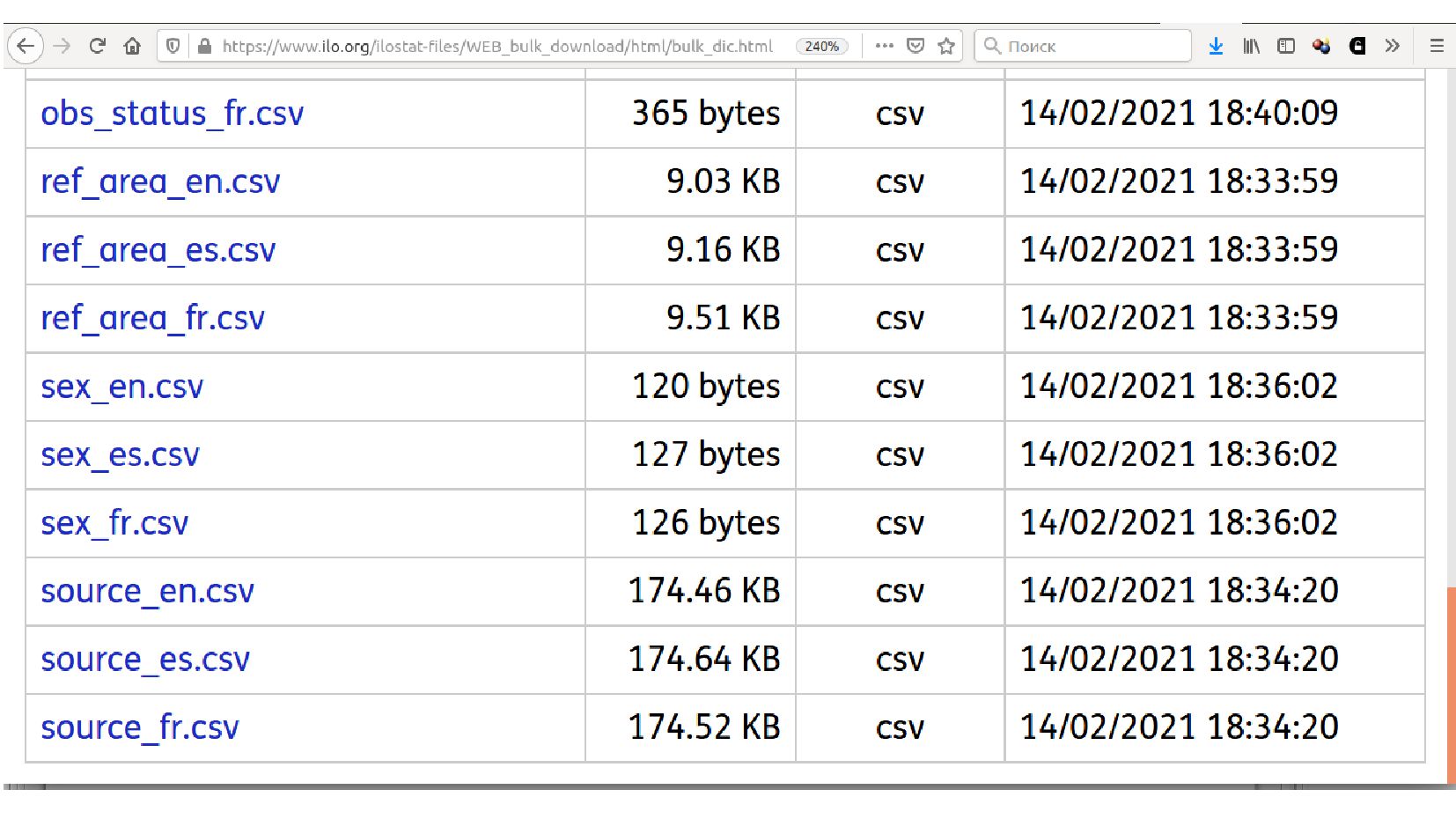
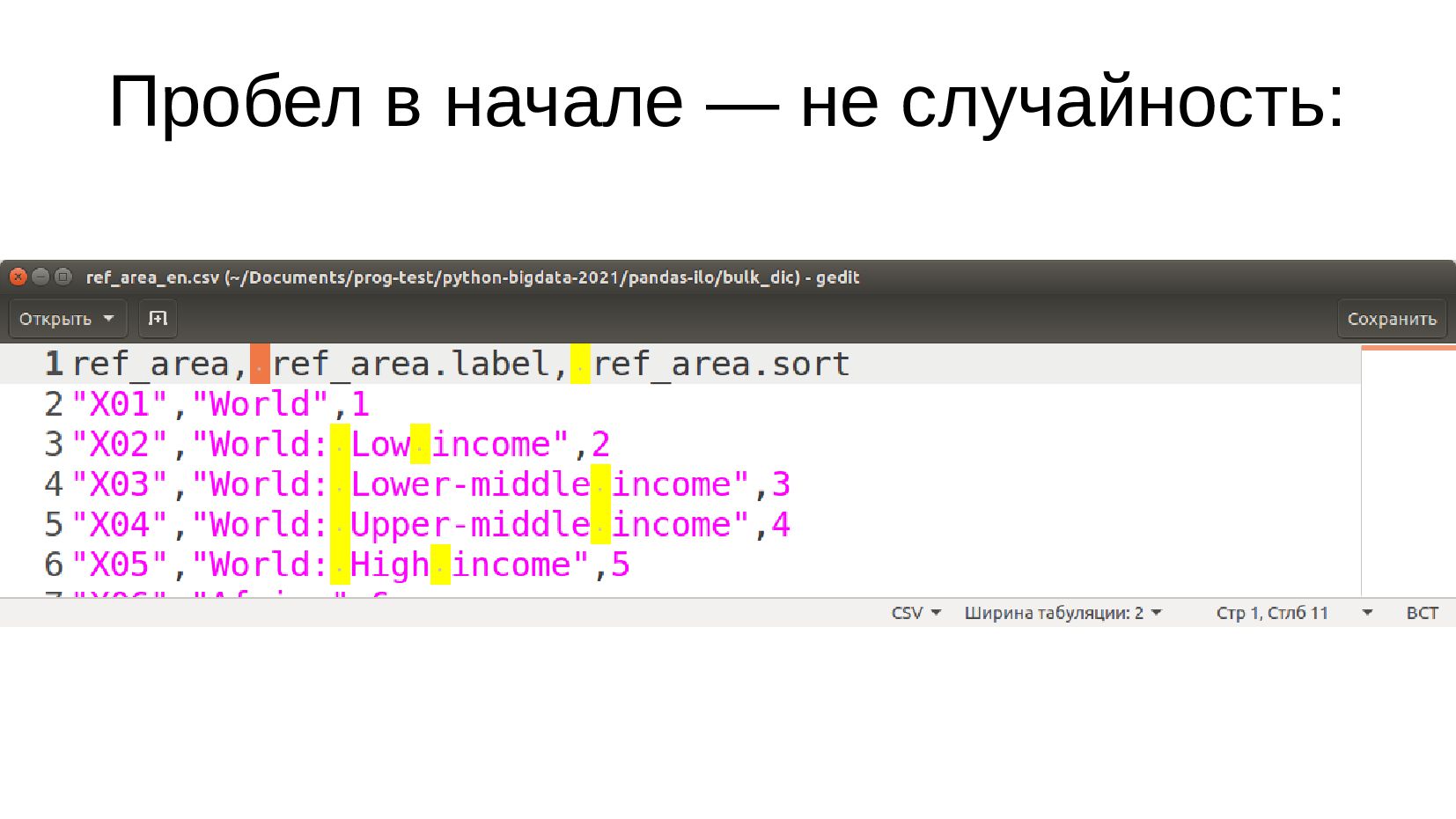
![data_ref_area = pandas.read_csv( 'bulk_dic/ref_area_en.csv', index_col='ref_area') print( data_ref_area[:10] ) Загрузим файл](https://files.speakerdeck.com/presentations/30dc1bc54b89458499caef6fba37df7b/slide_144.jpg){kind=link}
![print( data_ref_area.columns.values.tolist() ) Точные названия колонок [' ref_area.label', ' ref_area.sort']](https://files.speakerdeck.com/presentations/30dc1bc54b89458499caef6fba37df7b/slide_145.jpg){kind=link}
{kind=link}
{kind=link}
![data_ref_area = data_ref_area.rename( columns={' ref_area.label': 'ref_area_label'}) data_ref_area = data_ref_area[['ref_area_label']] print(](https://files.speakerdeck.com/presentations/30dc1bc54b89458499caef6fba37df7b/slide_148.jpg){kind=link}
![data = data.join(data_ref_area, on=['ref_area']) print( data[:5] ) Подклеим таблицу data_ref_area](https://files.speakerdeck.com/presentations/30dc1bc54b89458499caef6fba37df7b/slide_149.jpg){kind=link}
{kind=link}
![data = data[ ['ref_area', 'ref_area_label', 'sex', 'classif1', 'classif2', 'time', 'obs_value']]](https://files.speakerdeck.com/presentations/30dc1bc54b89458499caef6fba37df7b/slide_151.jpg){kind=link}
{kind=link}
{kind=link}
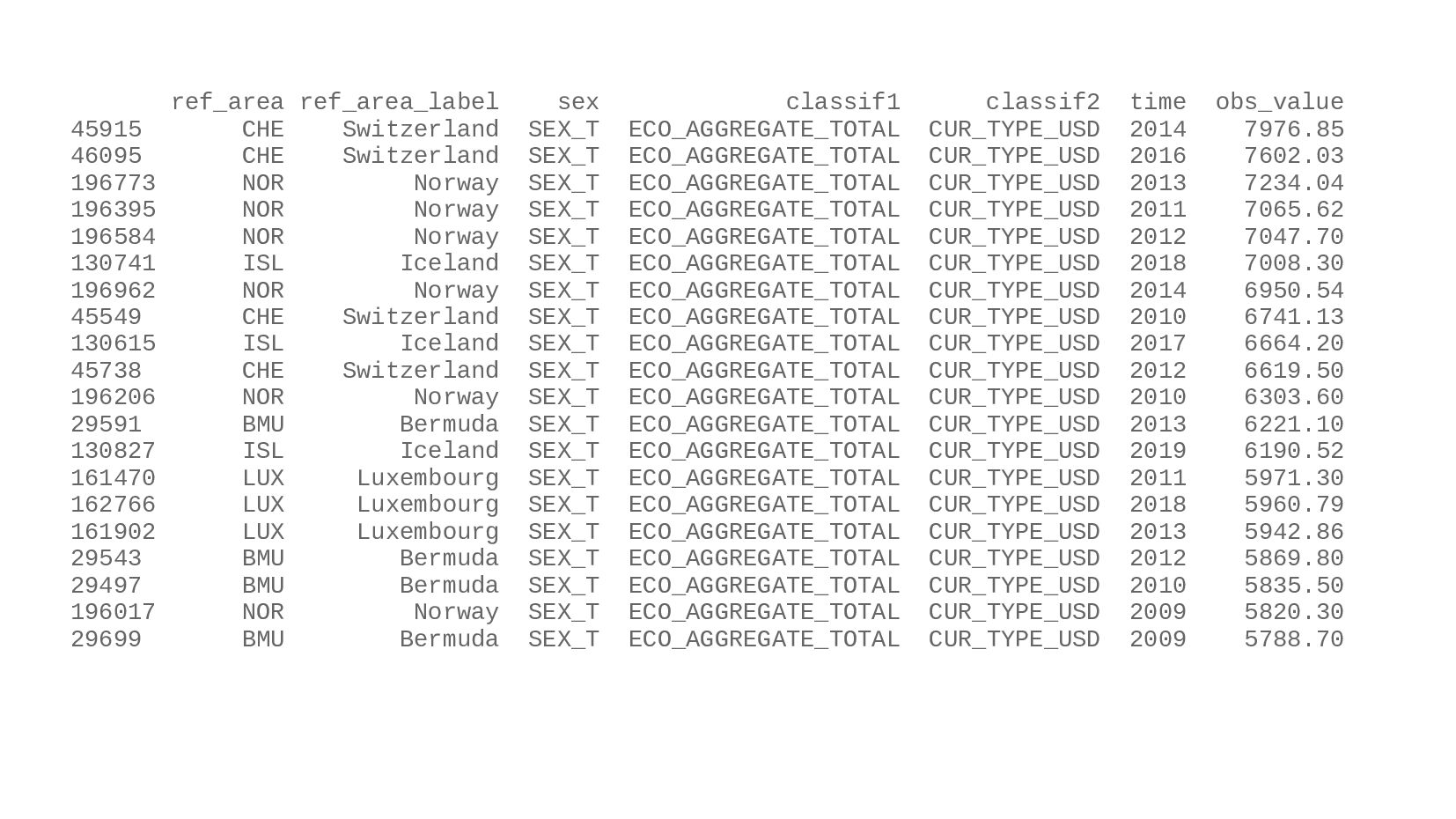{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
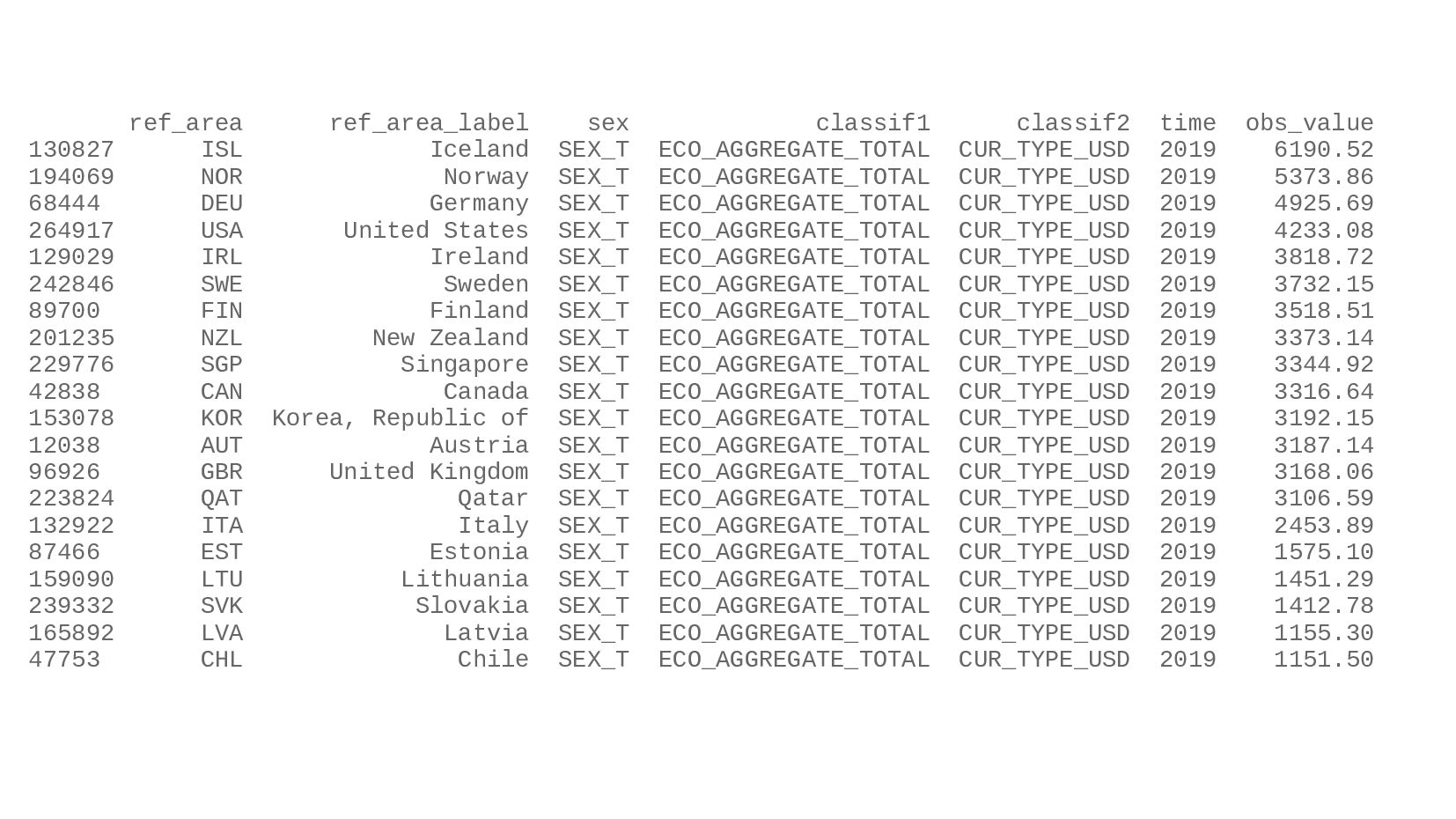{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}