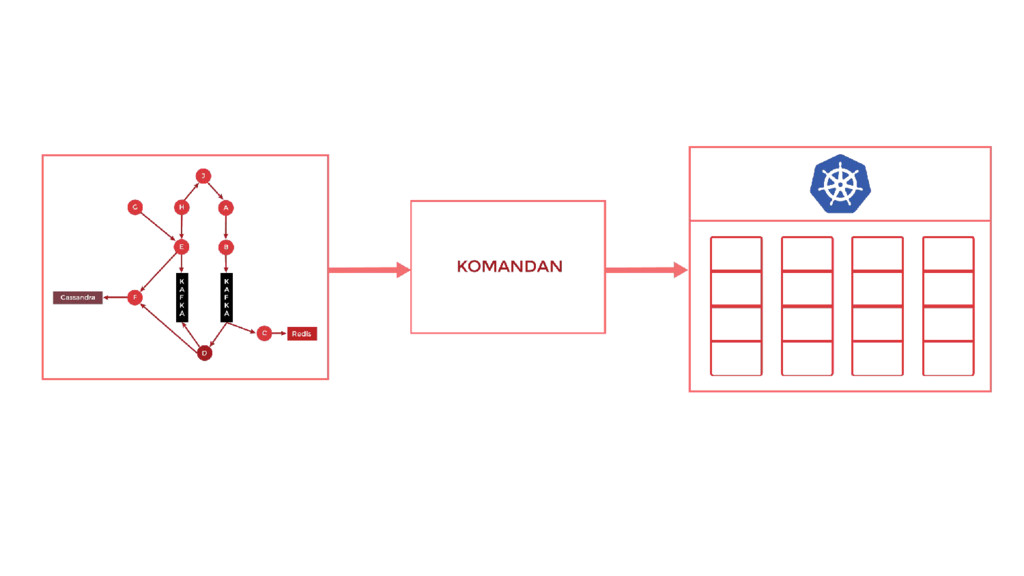
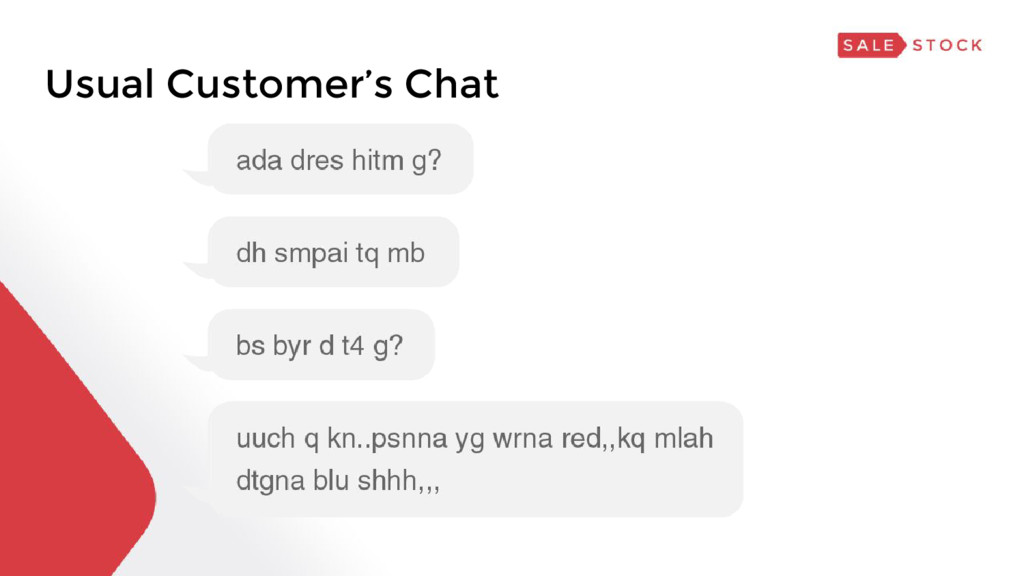
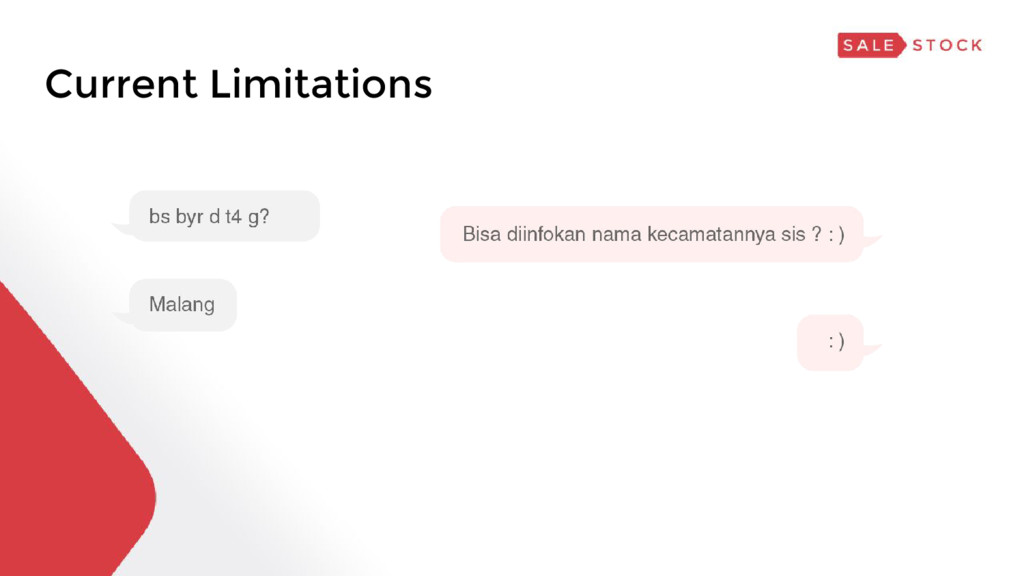
At Sale Stock, we are trying to solve the problem of providing easy access to great quality clothing at an affordable price for everybody. During the past year, we experienced explosive growth on a wide array of metrics: user base, revenue, user traffic, and team size -- to name a few. As an engineering team, it meant we had to scale quickly on all dimensions. In this talk, we will share a technical deep-dive on a wide array of strategies we employ to meet said scalability challenges in our team -- things like backend infrastructure, developer tooling, platform abstractions, deployment workflow, monitoring, data infrastructure, and others that allow our engineers to move quickly and efficiently to solve these challenges.
About the speakers:
Garindra Prahandono
Garindra is the Chief Technology Officer at Sale Stock Indonesia. Previously, he worked at Sony America, working on core products such as the PlayStation 4 and PlayStation Now. His work, used by tens of millions of people around the world, spans from server-side infrastructure, user interface core abstractions, to internal test automation infrastructure.
Thomas Diong
Thomas is the Chief Data Officer at Sale Stock Indonesia. He was previously at Yahoo! where he handled global tech initiatives working on Yahoo! Messenger, Yahoo! Application Platform, Yahoo! Games and the likes. He then went on to Apple where he worked on business process improvements and streamlining with automation, and subsequently Spuul (a movie streaming company), where he led growth and data efforts before moving to Veritrans.
Wilson Lauw
Wilson is a Data Engineer at Sale Stock Indonesia, working on data infrastructure for analytics and machine learning. Previously, he worked at Healint, a big data analytics in healthcare industry, as data scientist, working both on data analysis as well data infrastructure.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Reach us at: [email protected]](https://files.speakerdeck.com/presentations/fca8080ae1004b64a232df64ef8168aa/slide_84.jpg){kind=link}
{kind=link}