Share
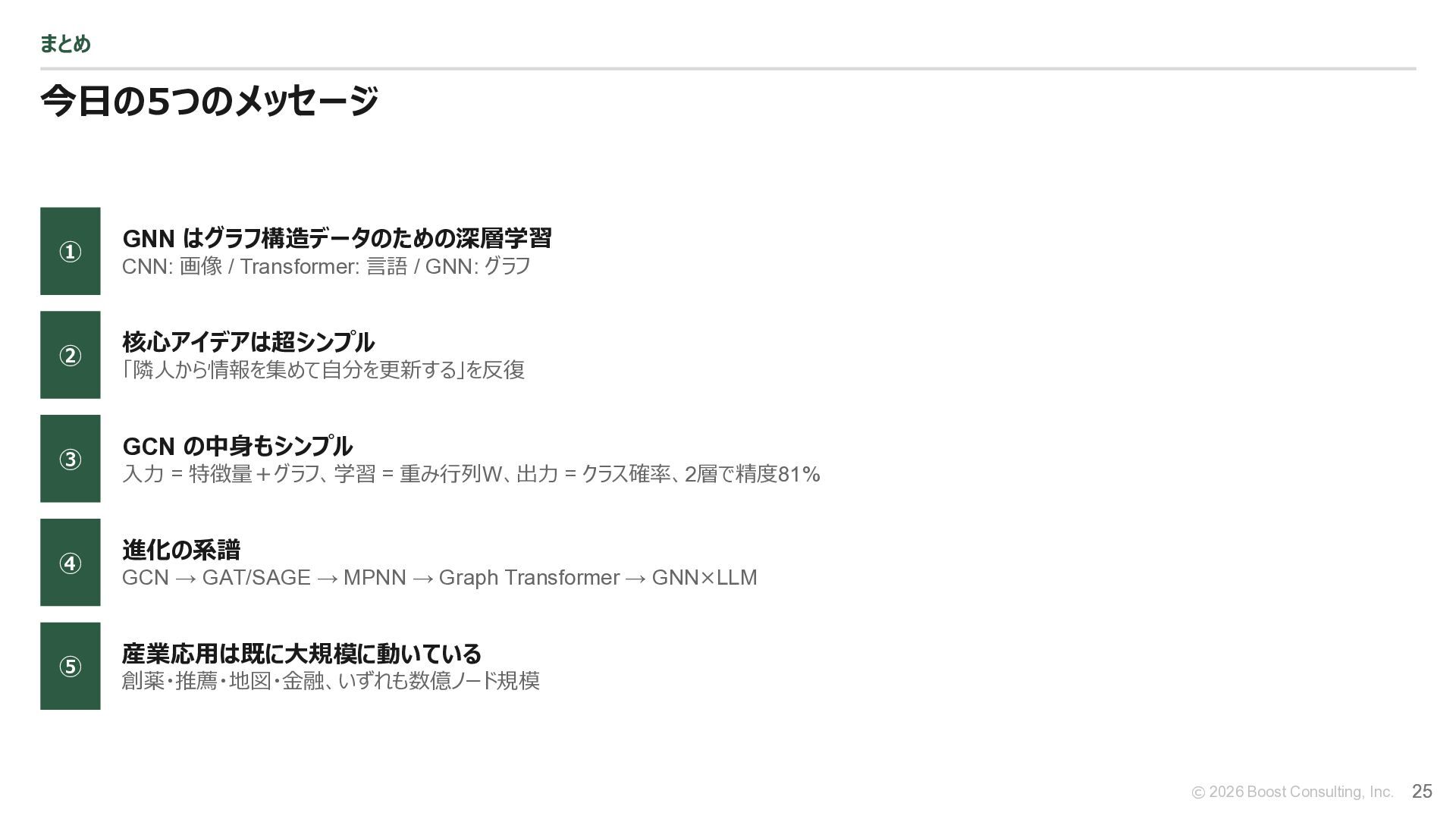
本資料は、グラフ構造データを扱う深層学習モデルであるGNNについて、ノードとエッジによる関係性データの表現、メッセージパッシング、GCNの基本構造と分類タスクでの有効性、GraphSAGEやGATやMPNNによるモデル発展、Graph TransformerおよびGNNとLLMの融合といった近年の研究動向、さらに創薬、推薦システム、交通予測、金融不正検知などの産業応用までを、基礎から実務での活用イメージまで段階的に整理した入門資料です。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
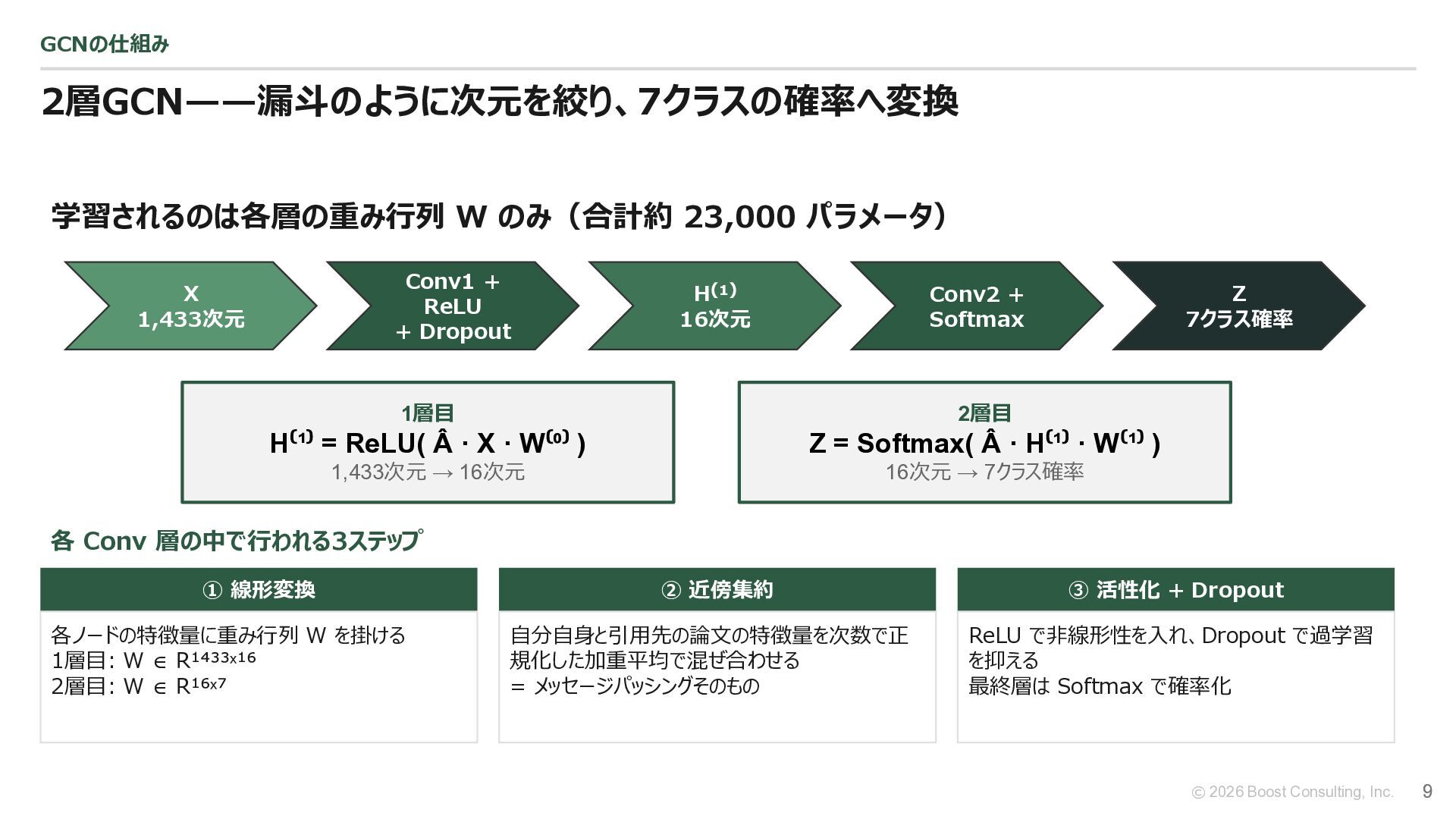{kind=link}
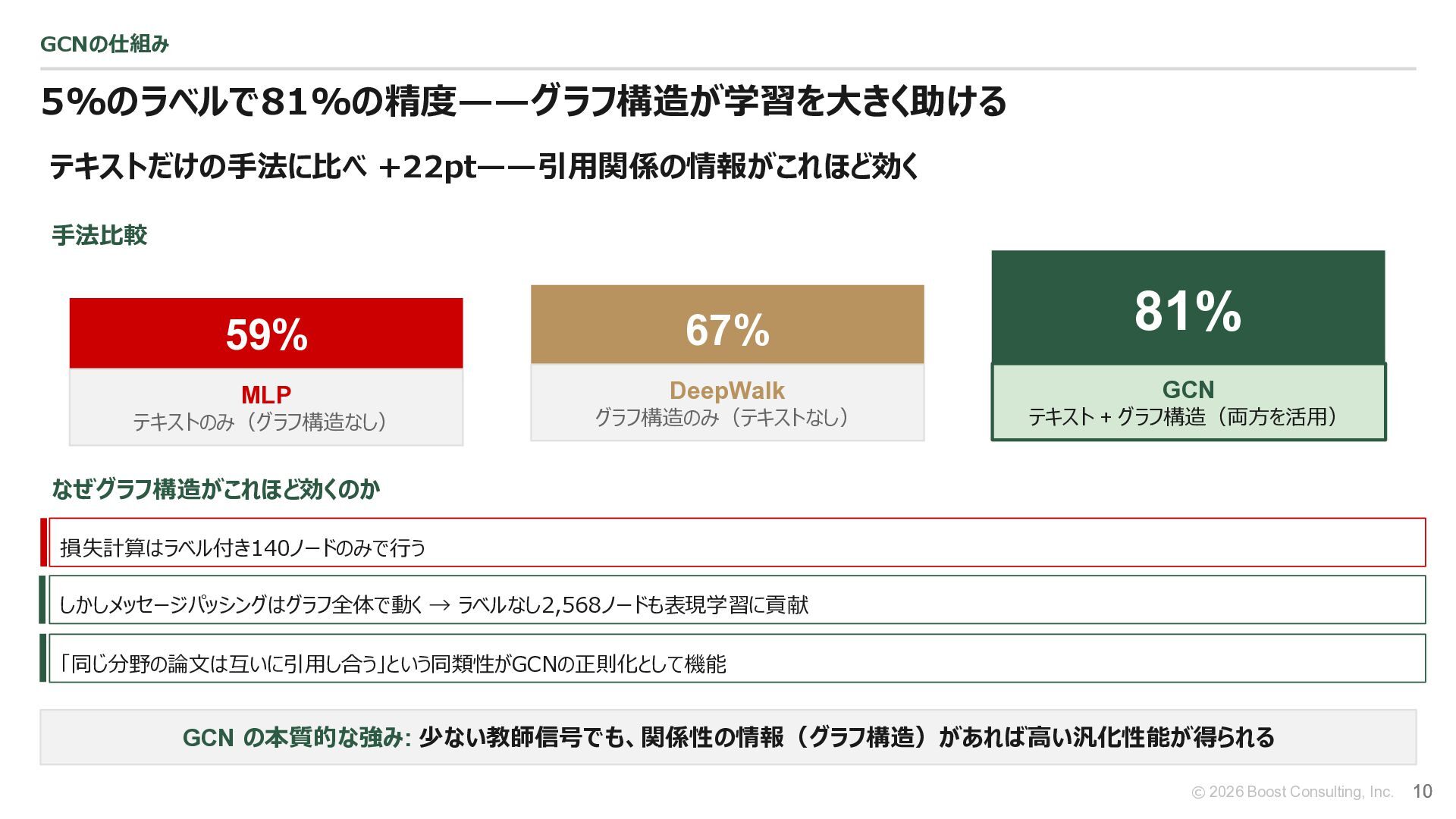{kind=link}
{kind=link}
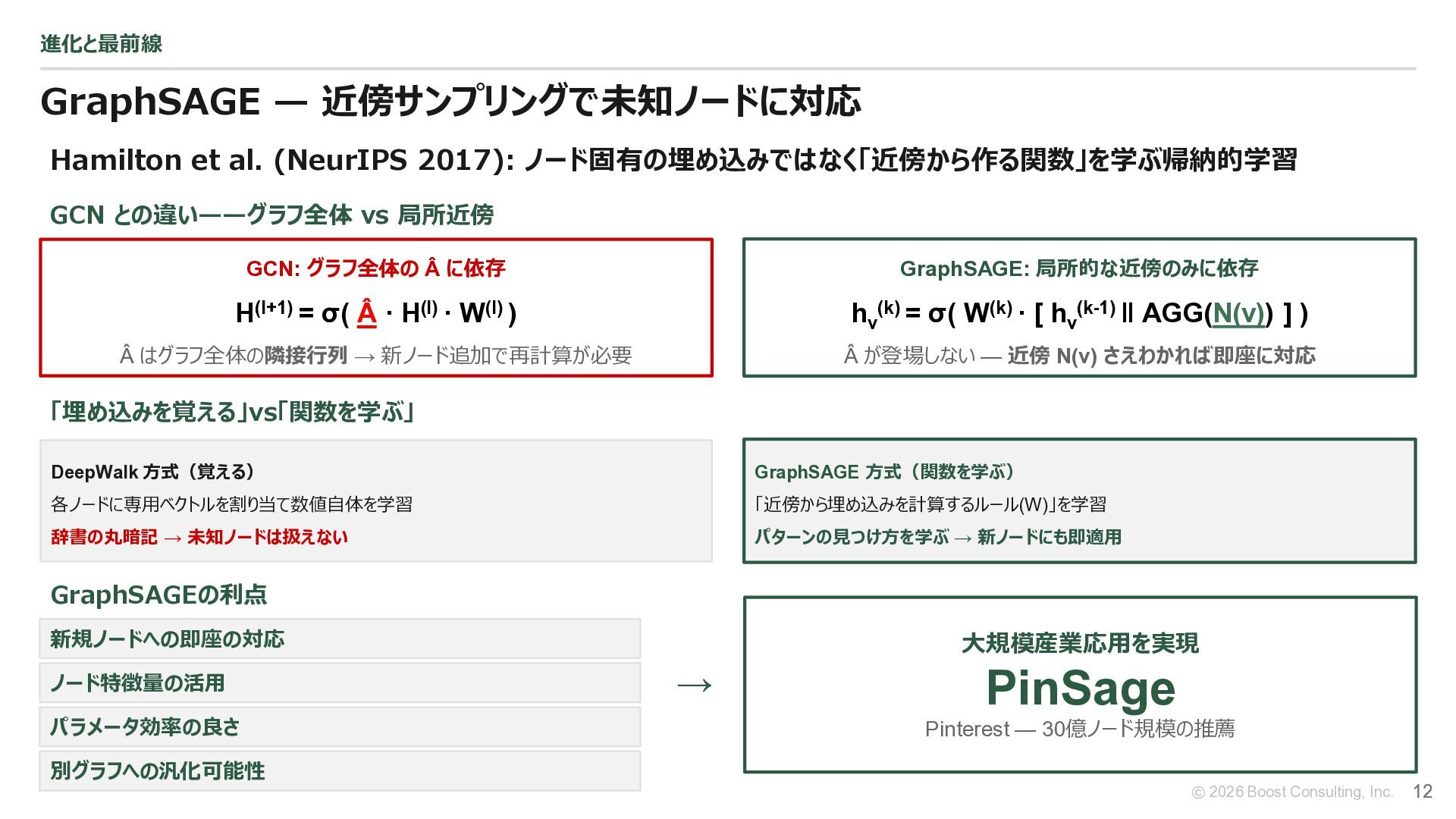{kind=link}
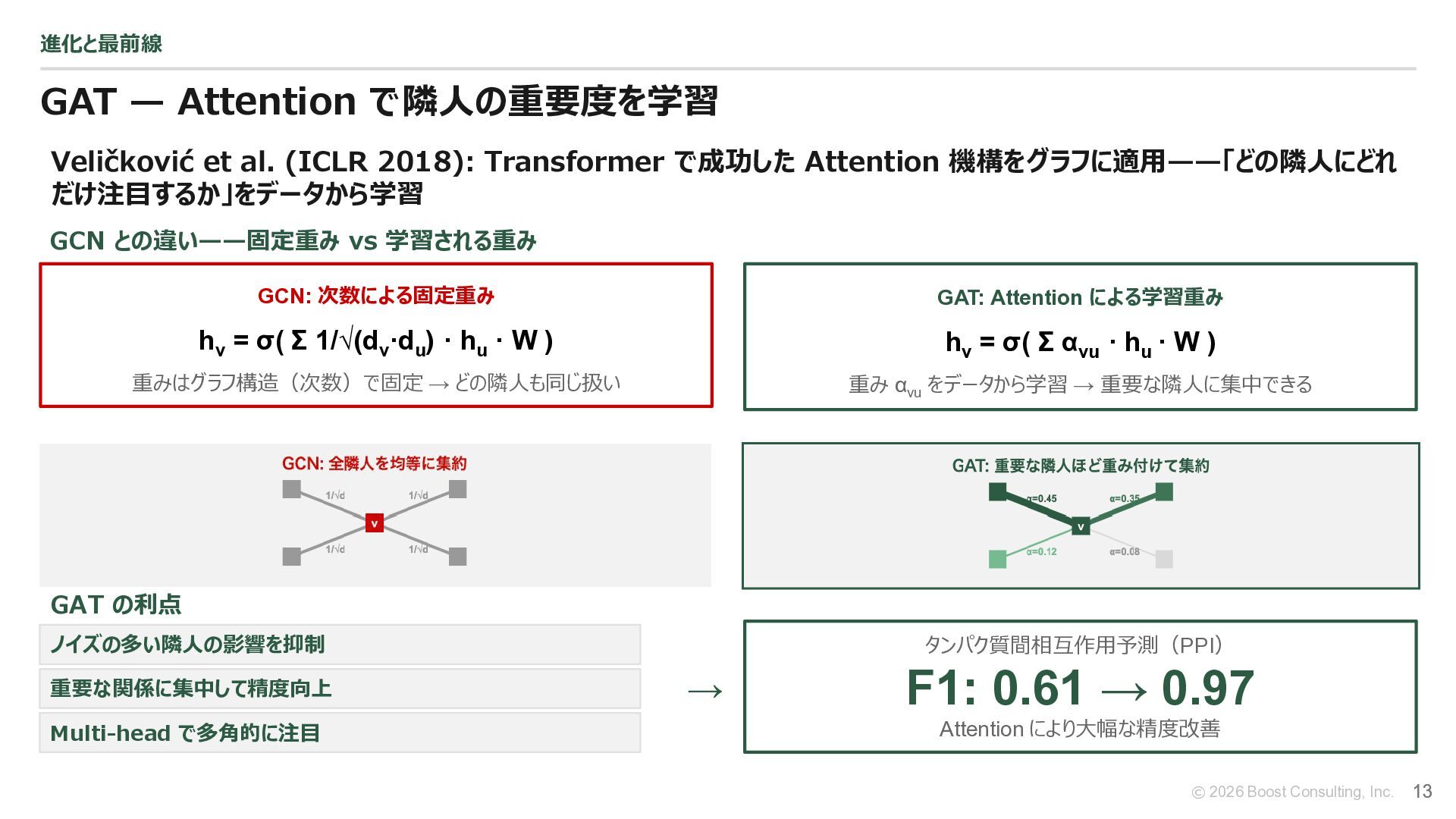{kind=link}
{kind=link}
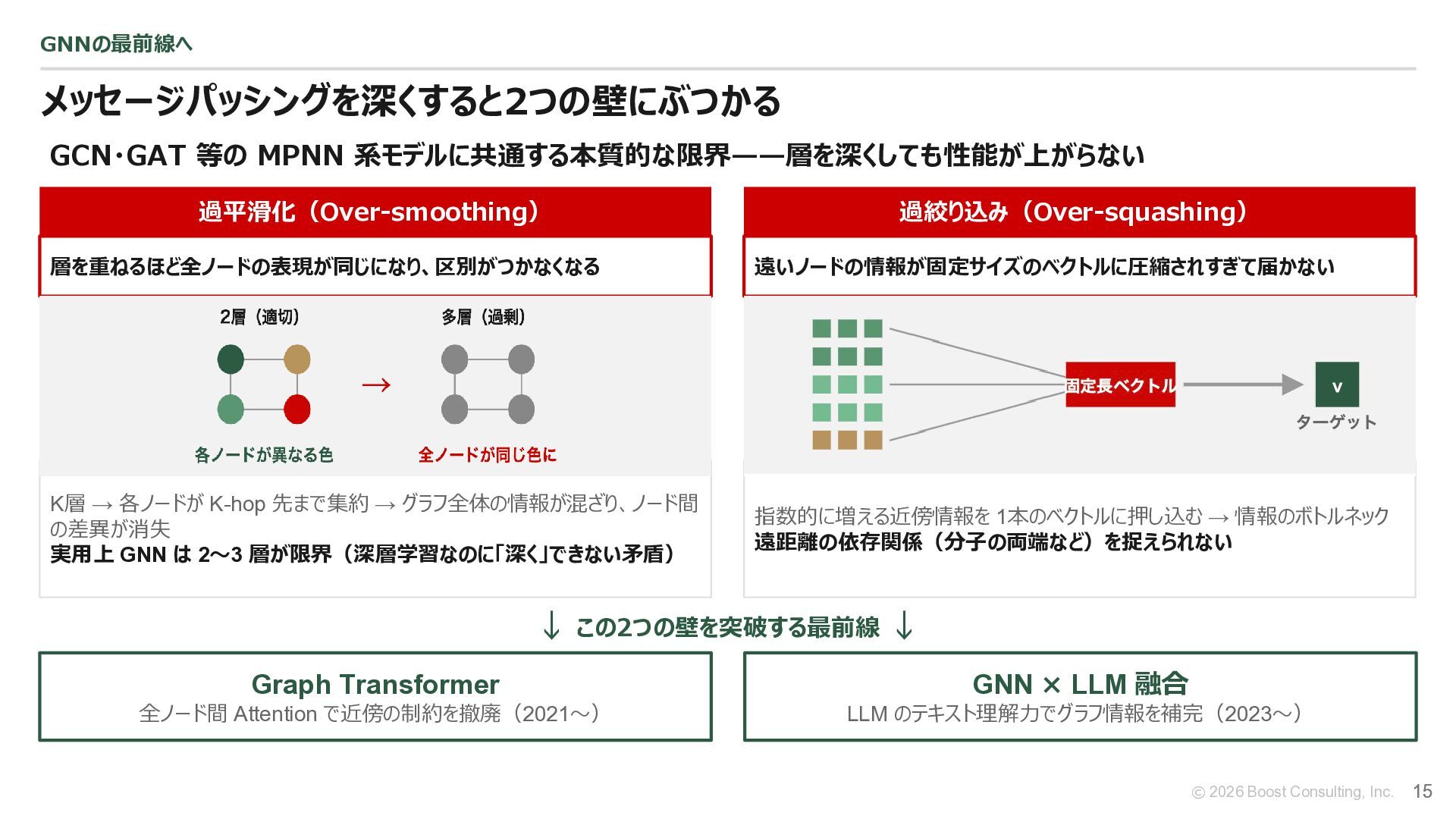{kind=link}
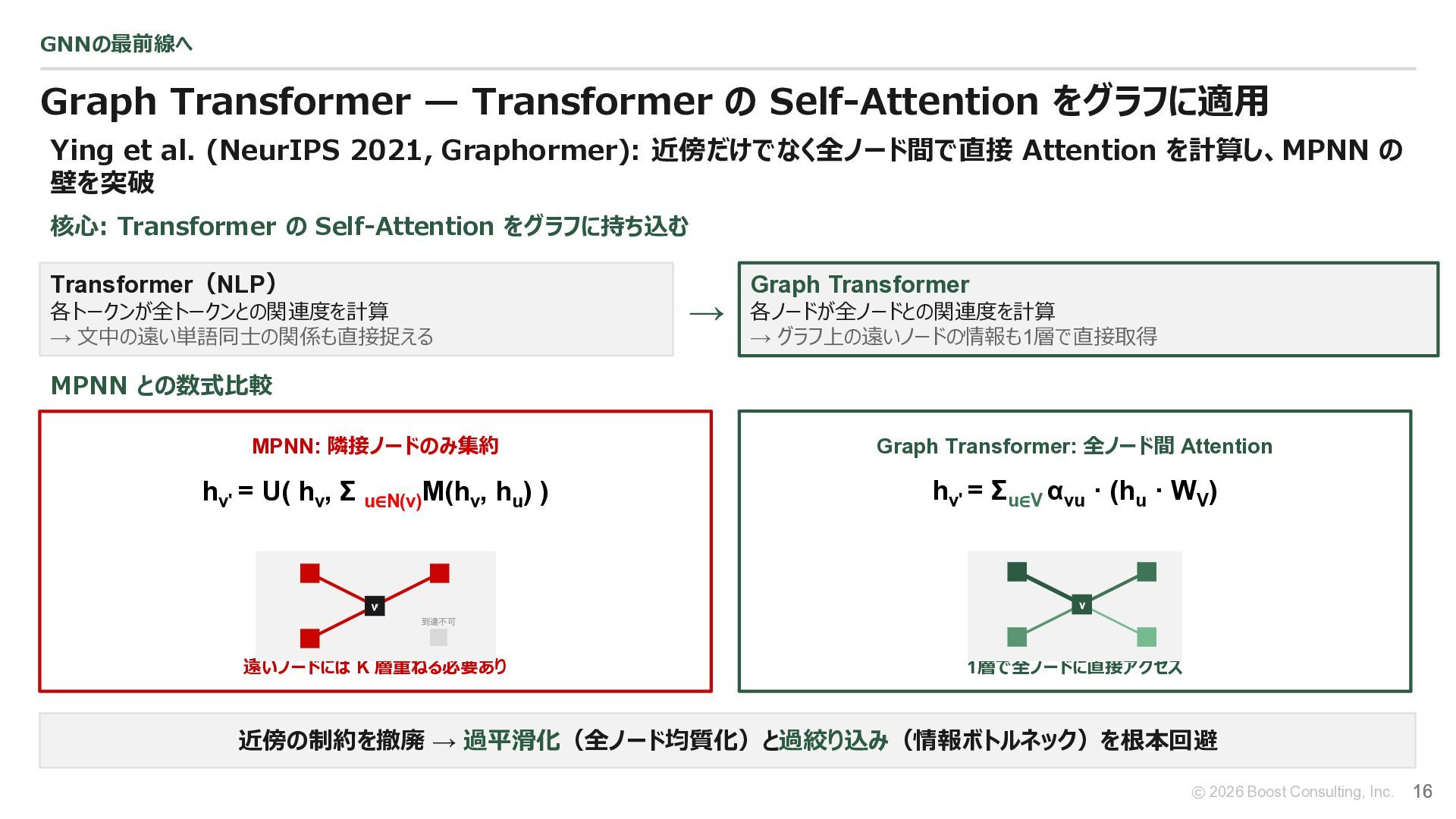{kind=link}
{kind=link}
{kind=link}
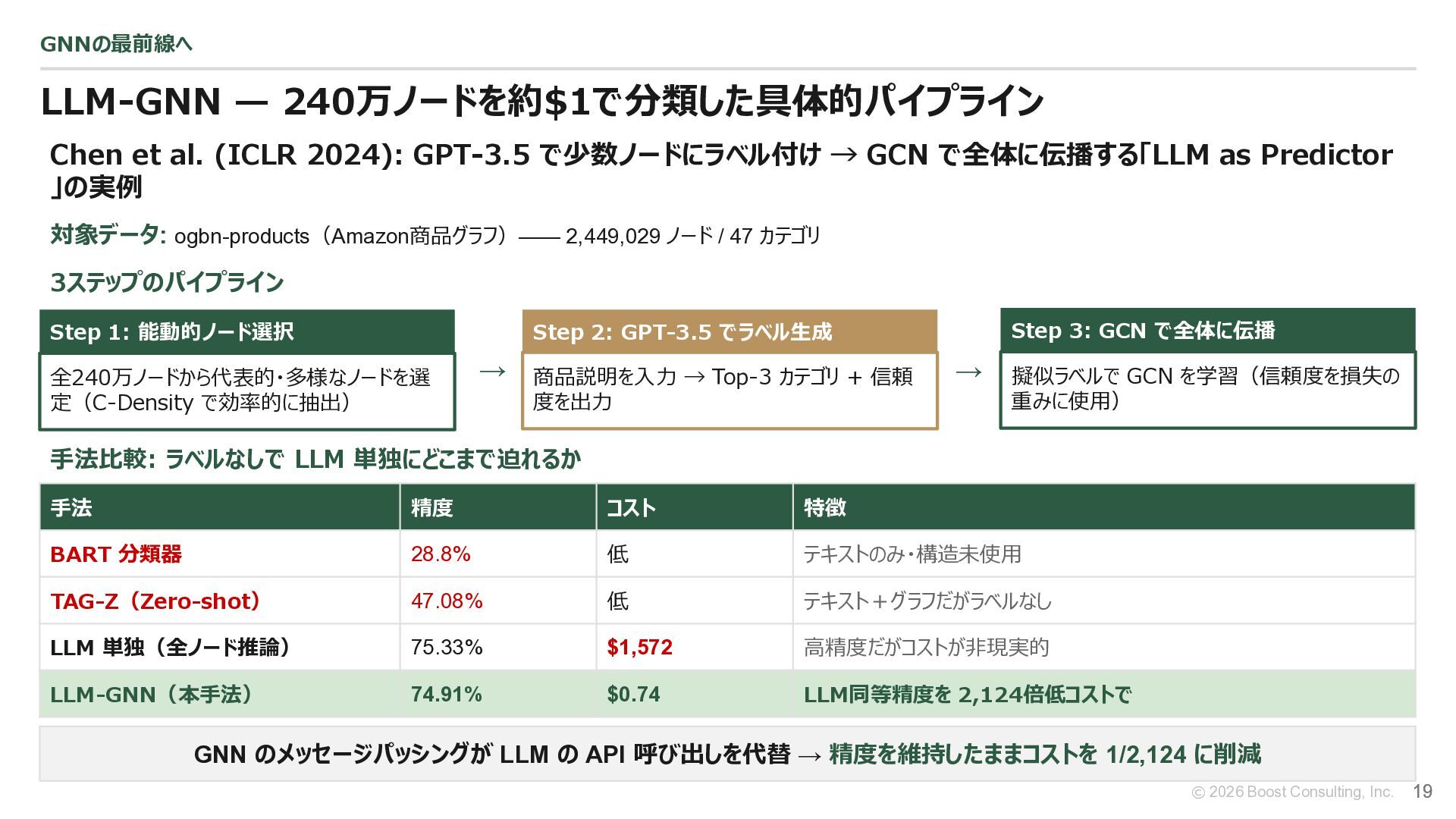{kind=link}
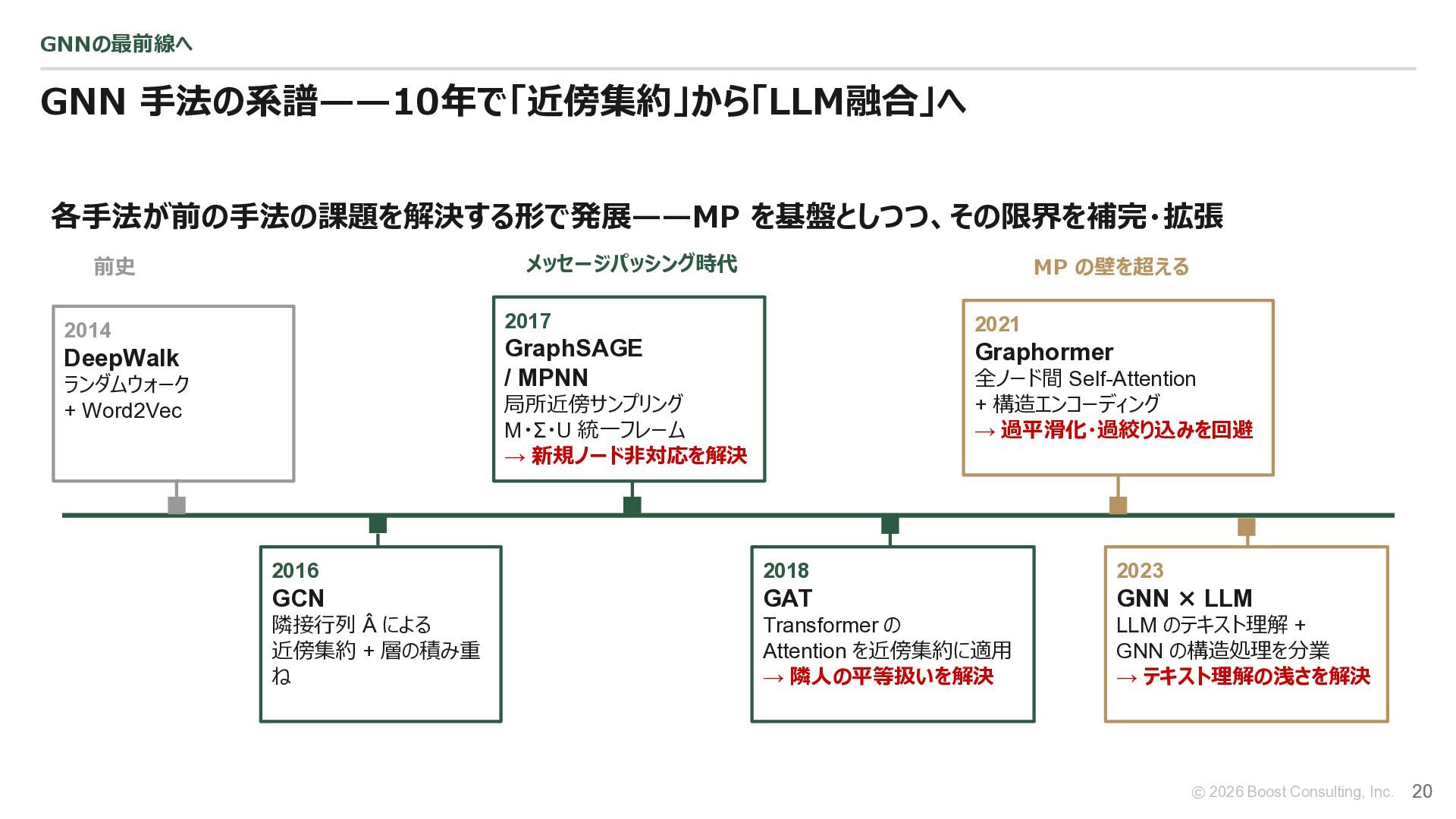{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}