Share
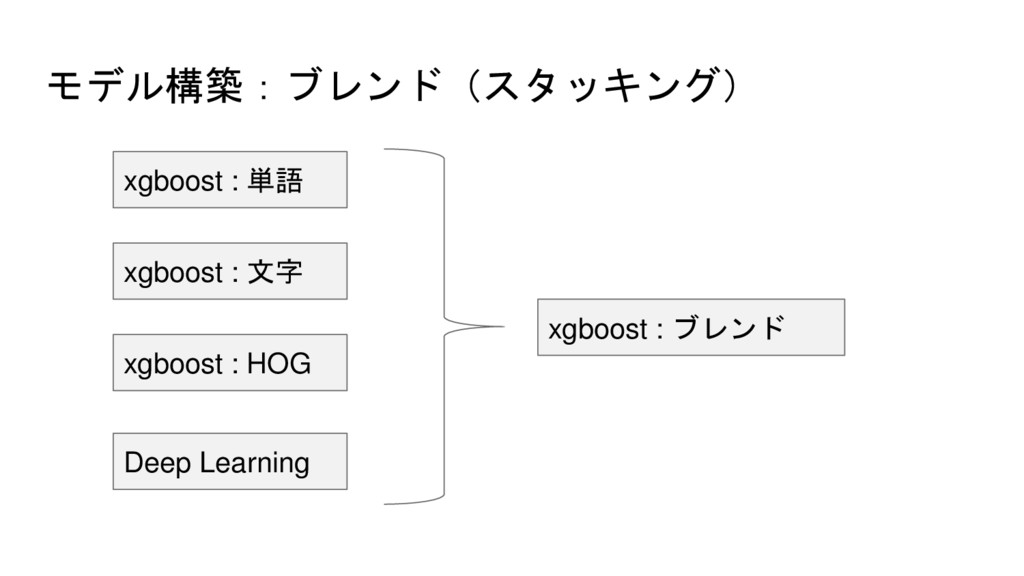
『人工知能は名刺をどこまで解読できるのか』 2016年8月8日~9月30日まで行われた、データ分析コンテスト第2位を獲得されたkanosuke様の手法です。
http://jp.corp-sansan.com/lp/data-sientist-c.html
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}