from OCT/2019 as a new graduate student. I am in charge of exploiting Sansan’s data through various machine learning methods in an efficient way. Now I am currently focusing on recommendation system and some customized small NLP tasks. 李 星 XING LI
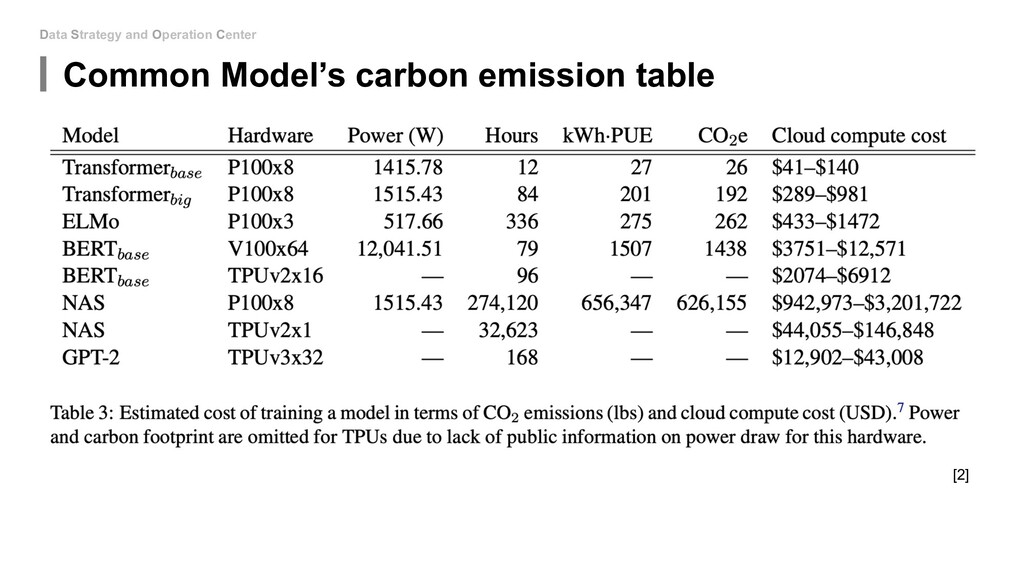
draw (in watts) from all CPU sockets during training p_r: the average power draw from all DRAM (main memory) sockets p_g: the average power draw of a GPU during training g: the number of GPUs used to train t: the total training time 1.58: Power Usage Effectiveness(PUE). [13] 0.954: Average CO2 produced for power consumed in the U.S. [14] [2] [2]
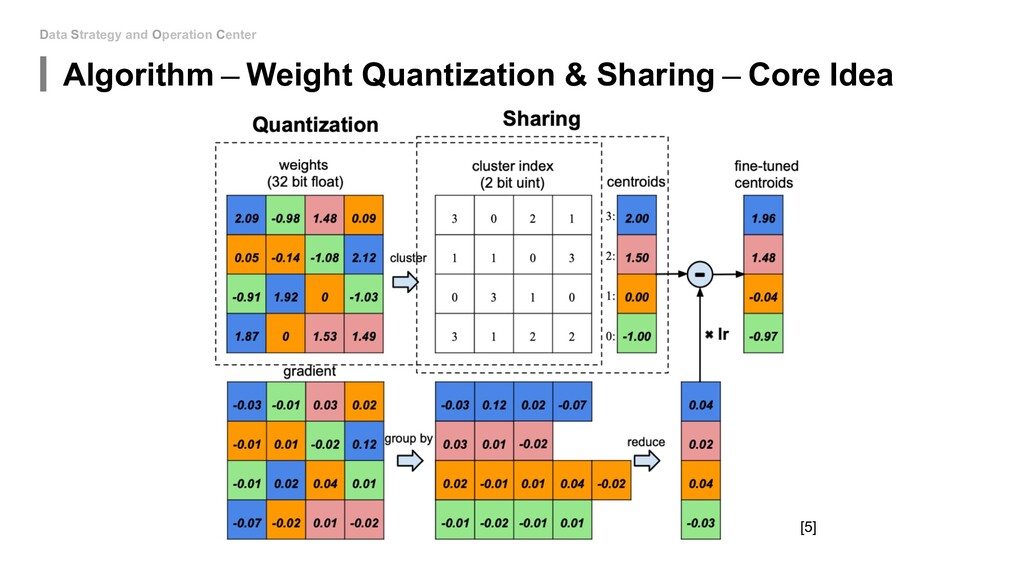
& Sharing ─ Initialization of K-means Three different methods for centroids initialization. Distribution of weights (◼blue) and distribution of codebook before (×green cross) and after fine-tuning (•red dot)
them involve the redesign to original network architectures) • Special designed network architectures: • ShuffleNet, MobileNet, BottleNet, SqueezeNet[6] and etc…. • Winograd Transformation • Low Rank Approximation • Binary/Ternary Net • …
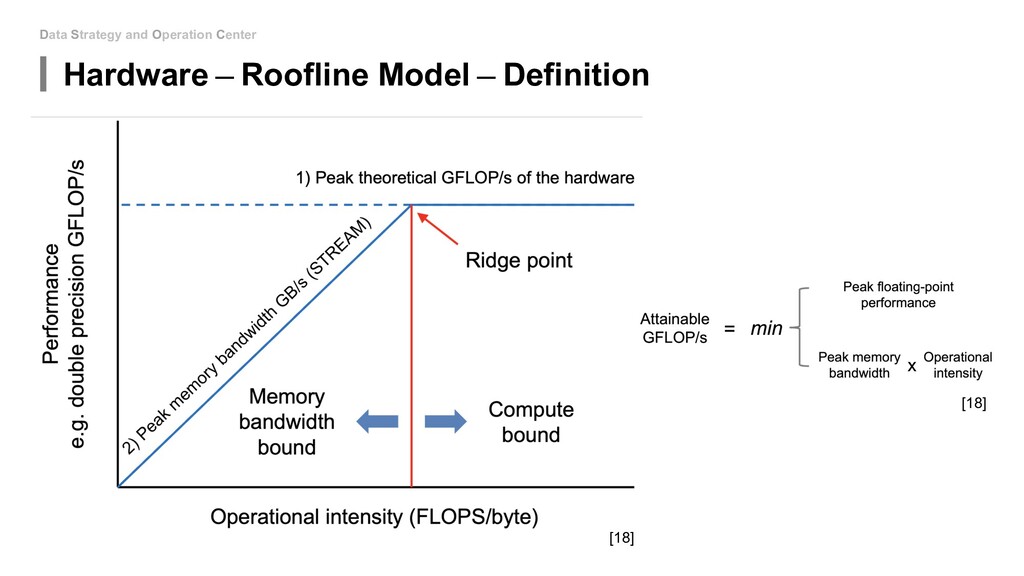
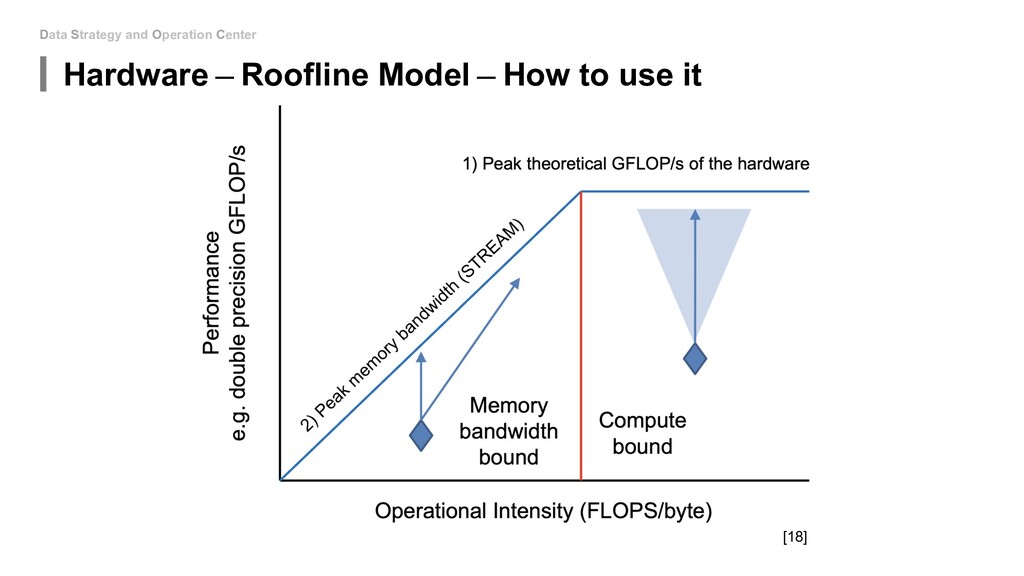
to minimize the memory access! Actually, I am neither going to nor able to discuss how to design the chips~(TT) But we could know how good our models run on a specific hardware platform so that we can decide to continue optimising our algorithm or buy a better x(C/G/T)PU.
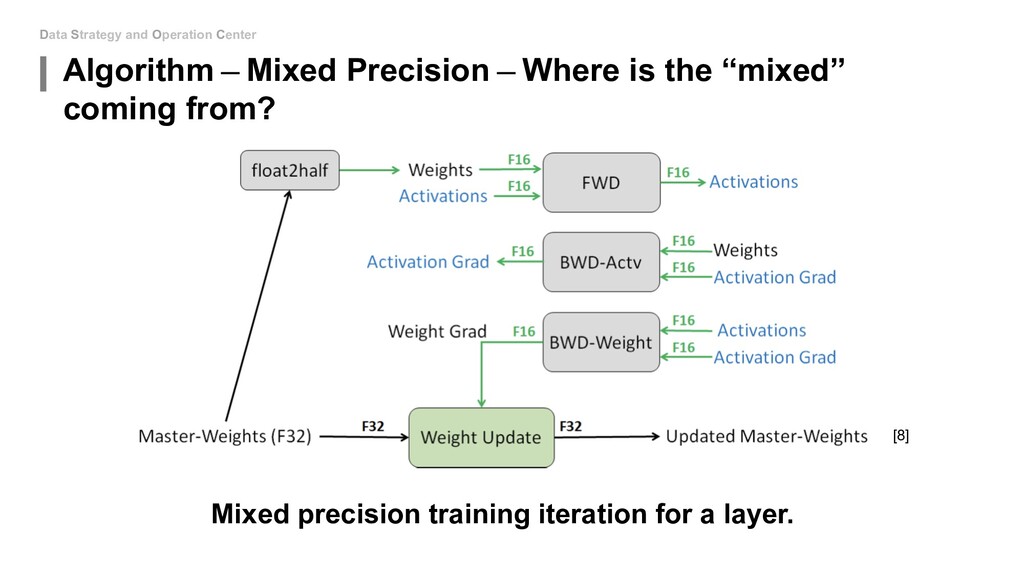
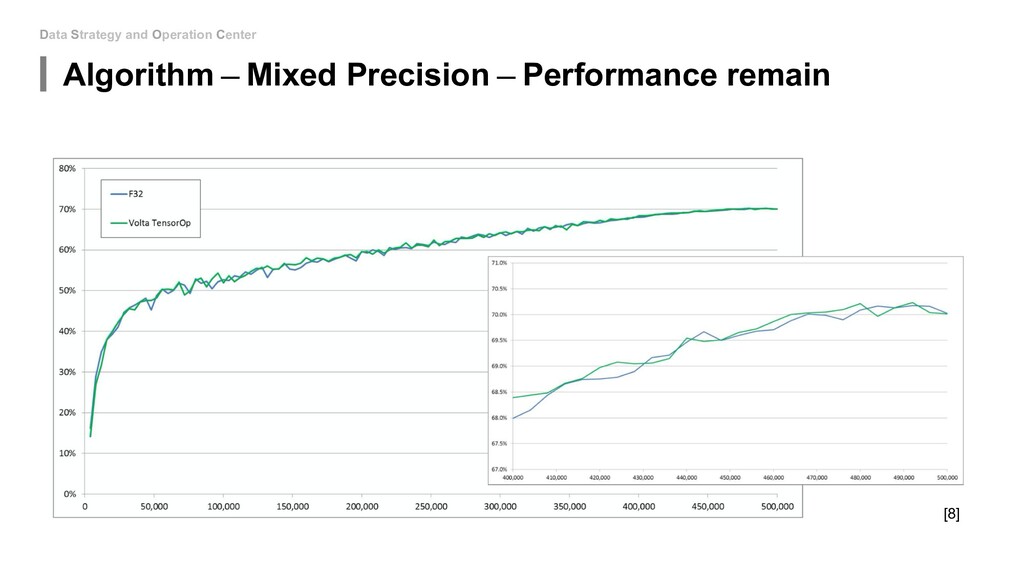
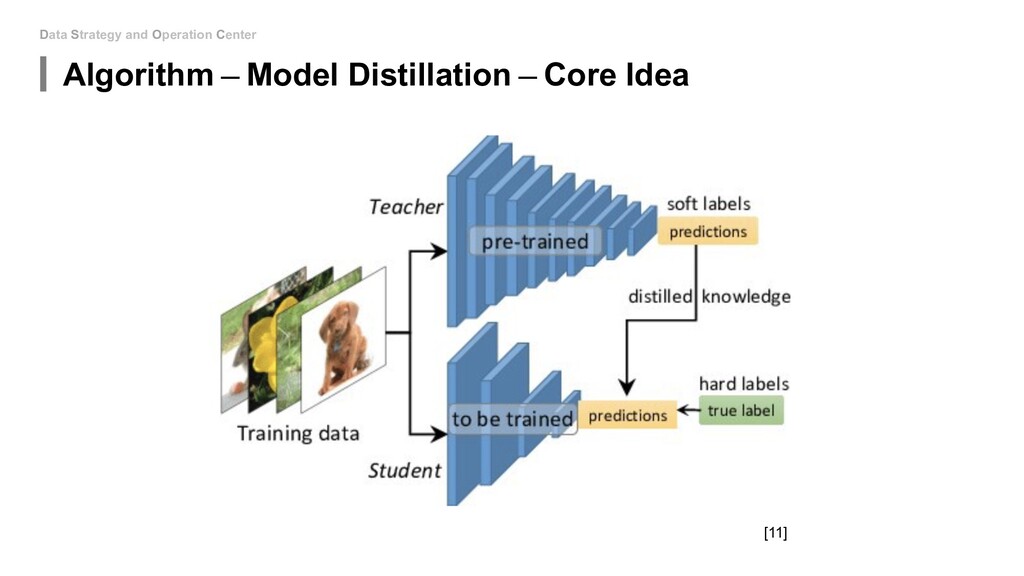
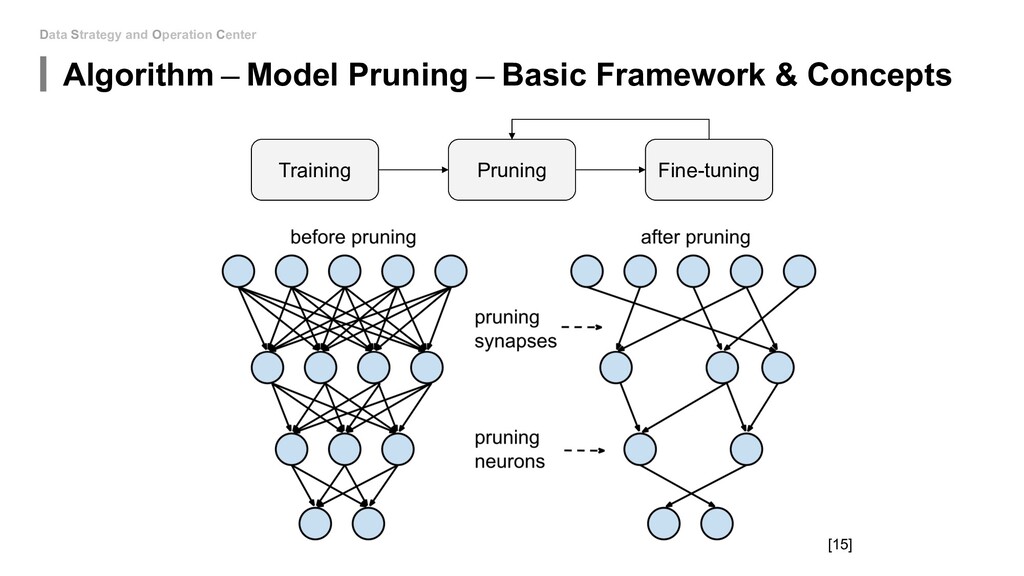
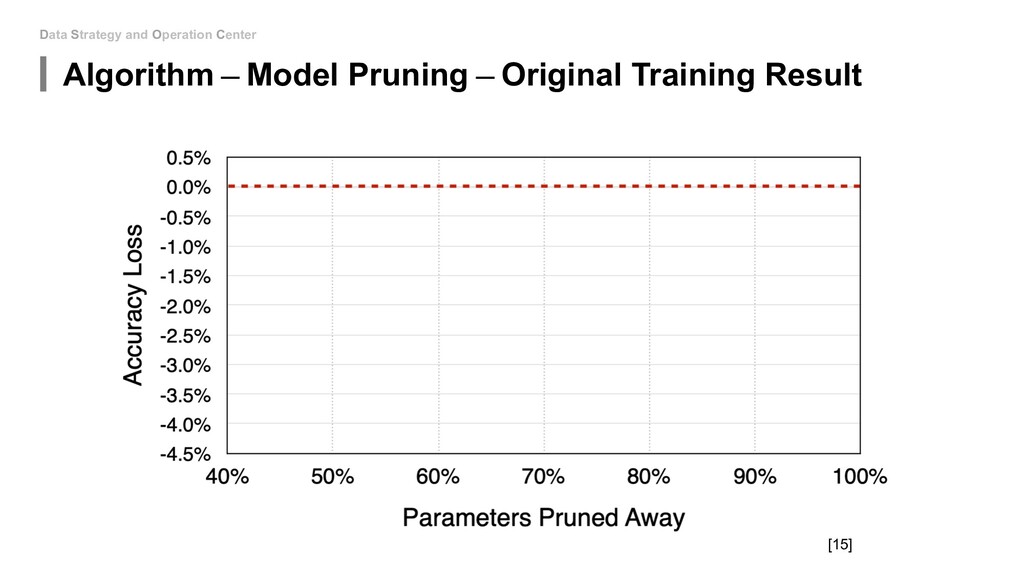
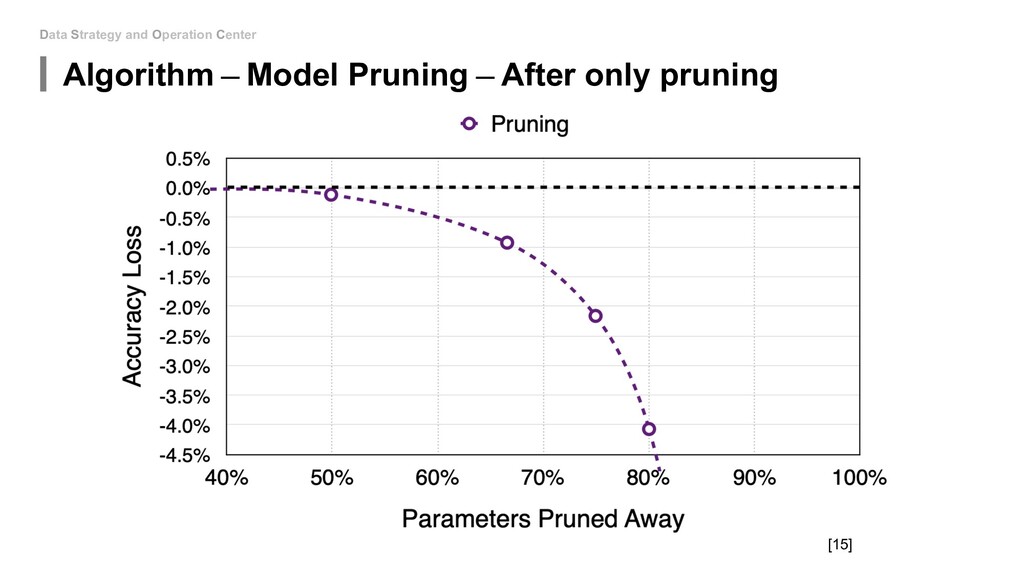
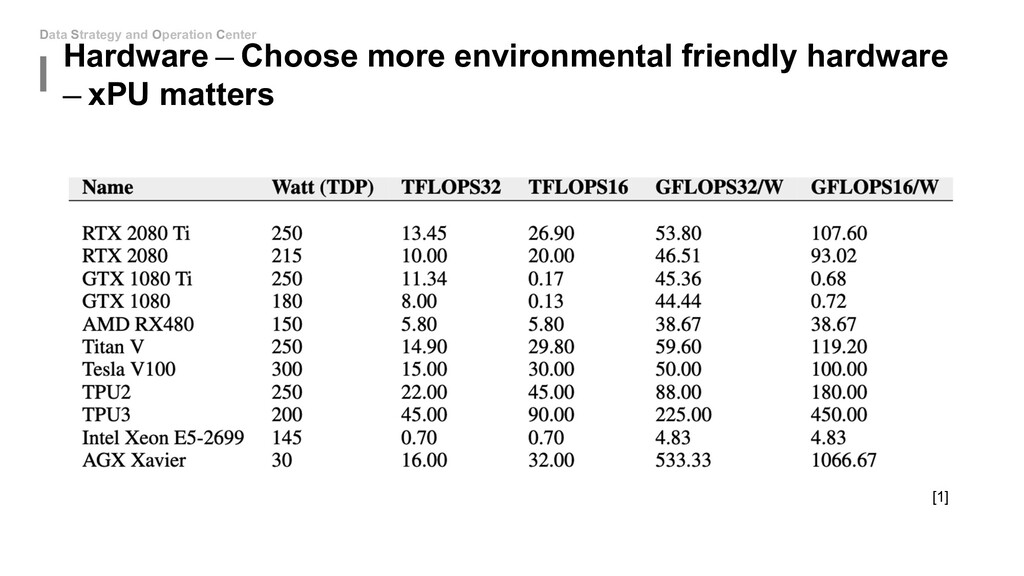
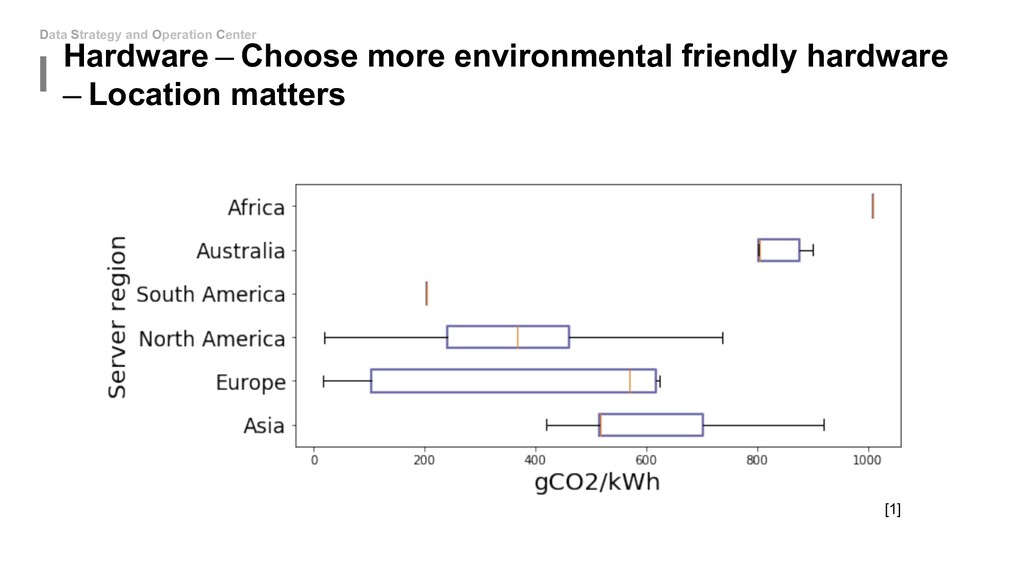
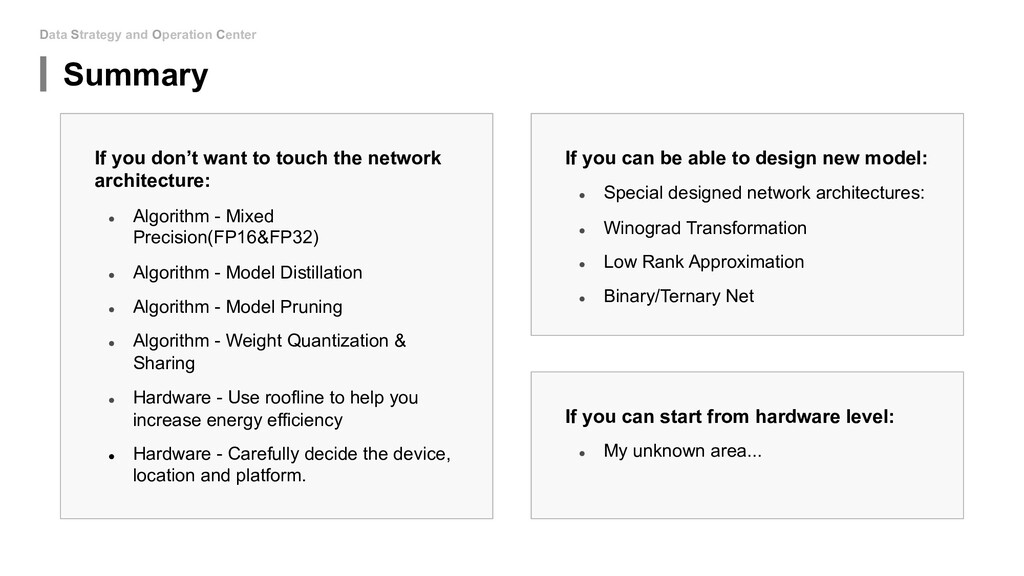
to touch the network architecture: • Algorithm - Mixed Precision(FP16&FP32) • Algorithm - Model Distillation • Algorithm - Model Pruning • Algorithm - Weight Quantization & Sharing • Hardware - Use roofline to help you increase energy efficiency • Hardware - Carefully decide the device, location and platform. If you can be able to design new model: • Special designed network architectures: • Winograd Transformation • Low Rank Approximation • Binary/Ternary Net If you can start from hardware level: • My unknown area...
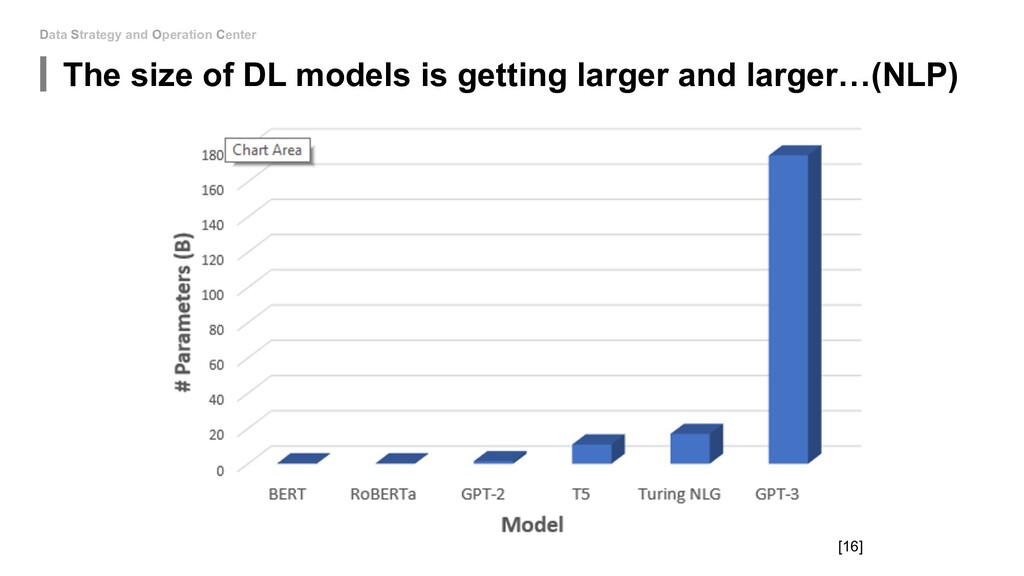
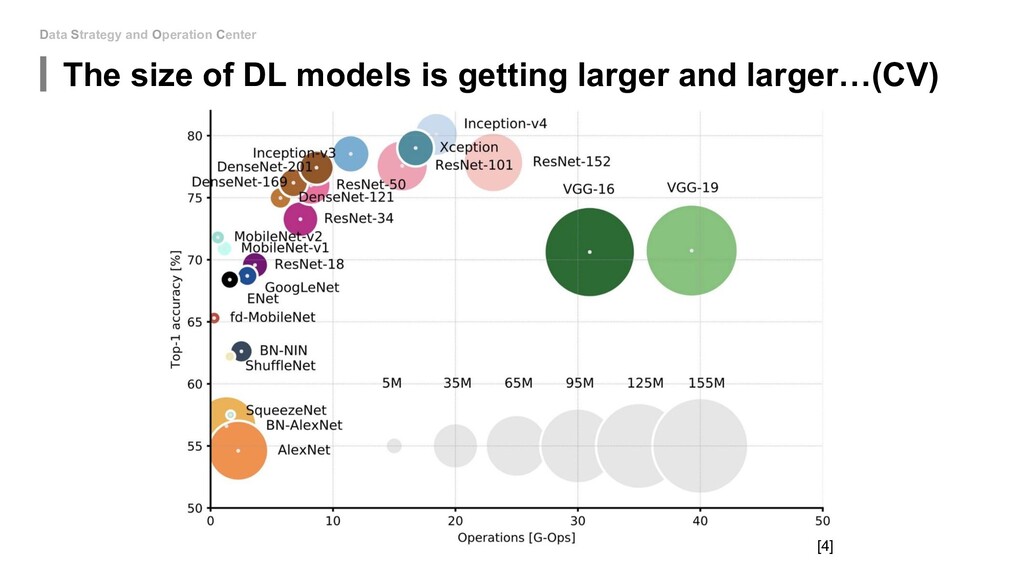
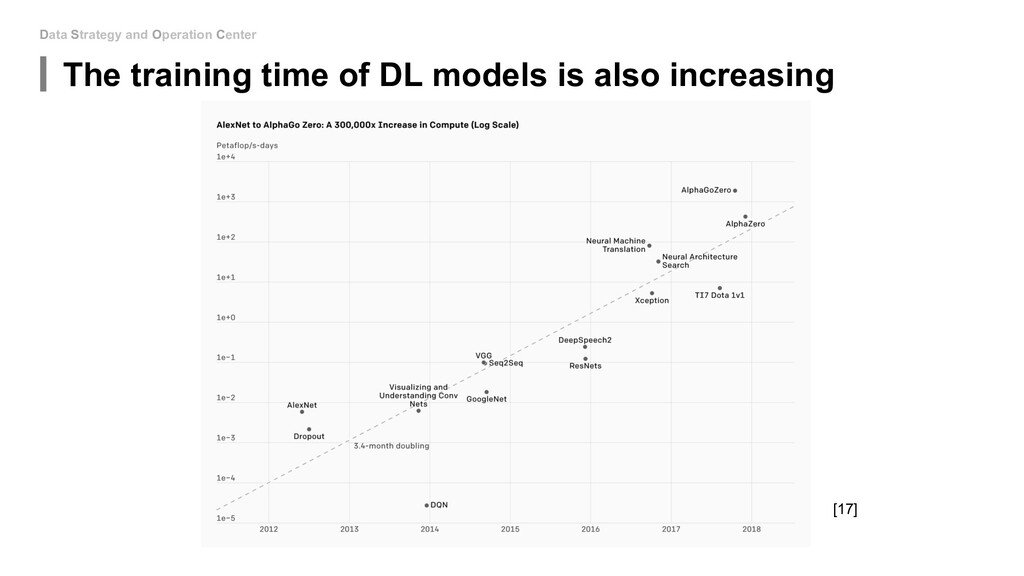
Emissions of Machine Learning (https://arxiv.org/pdf/1910.09700.pdf) 2. Energy and Policy Considerations for Deep Learning in NLP (https://arxiv.org/pdf/1906.02243.pdf) 3. DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter (https://arxiv.org/pdf/1910.01108.pdf) 4. Neural Network Architectures(https://towardsdatascience.com/neural-network-architectures-156e5bad51ba) 5. DEEP COMPRESSION: COMPRESSING DEEP NEURAL NETWORKS WITH PRUNING, TRAINED QUANTIZATION AND HUFFMAN CODING(https://arxiv.org/pdf/1510.00149.pdf) 6. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5MB model size(https://arxiv.org/pdf/1602.07360.pdf) 7. Deep Learning Performance Documentation Nvidia (https://docs.nvidia.com/deeplearning/performance/mixed-precision- training/index.html#mptrain__fig1) 8. MIXED PRECISION TRAINING (https://arxiv.org/pdf/1710.03740.pdf) 9. Distilling the Knowledge in a Neural Network(https://arxiv.org/pdf/1503.02531.pdf) 10. Distilling Task-Specific Knowledge from BERT into Simple Neural Networks(https://arxiv.org/pdf/1903.12136.pdf) 11. Knowledge Distillation: Simplified (https://towardsdatascience.com/knowledge-distillation-simplified-dd4973dbc764) 12. ML CO2 IMPACT: https://mlco2.github.io/impact/#home 13. Rhonda Ascierto. 2018. Uptime Institute Global Data Center Survey. Technical report, Uptime Institute. 14. EPA. 2018. Emissions & Generation Resource Integrated Database (eGRID). Technical report, U.S. Environmental Protection Agency. 15. Learning both Weights and Connections for Efficient Neural Networks(https://papers.nips.cc/paper/5784-learning-both-weights- and-connections-for-efficient-neural-network.pdf) 16. GPT-3: The New Mighty Language Model from OpenAI(https://mc.ai/gpt-3-the-new-mighty-language-model-from-openai-2/) 17. AI and Compute(https://openai.com/blog/ai-and-compute/) 18. Performance Analysis(HPC Course, University of Bristol) 19. Reduce your carbon footprint by Planting a tree(https://co2living.com/reduce-your-carbon-footprint-by-planting-a-tree/) 20. EIE: Efficient Inference Engine on Compressed Deep Neural Network(https://arxiv.org/pdf/1602.01528.pdf)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
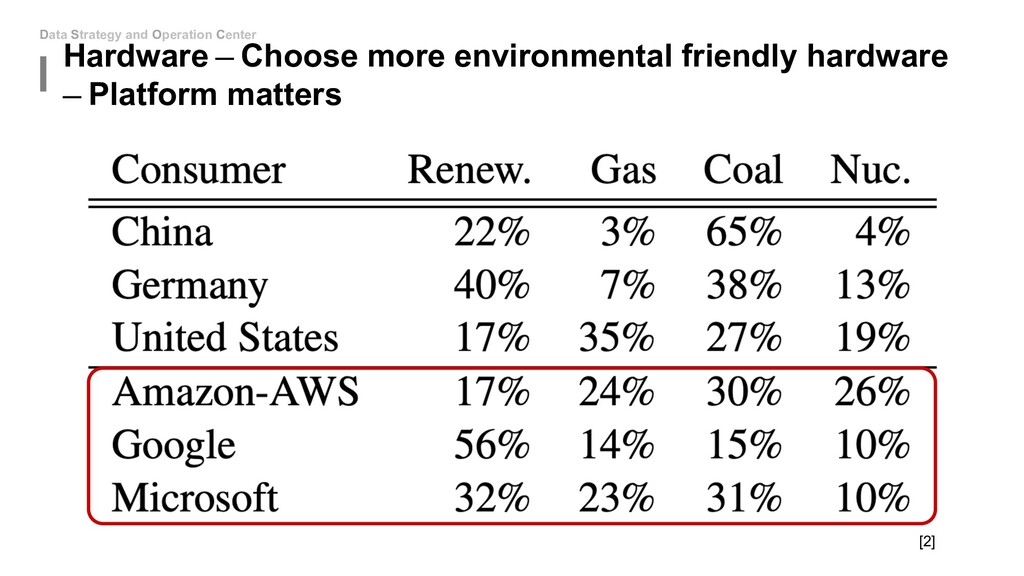
![Data Strategy and Operation Center A vivid comparison [2]](https://files.speakerdeck.com/presentations/43f49df724804249adea97f1dbcea1e2/slide_8.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Data Strategy and Operation Center [5] Algorithm ─ Weight Quantization](https://files.speakerdeck.com/presentations/43f49df724804249adea97f1dbcea1e2/slide_26.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}