Public talk presented at the ServerlessDays Cardiff 2020 conference.
Abstract:
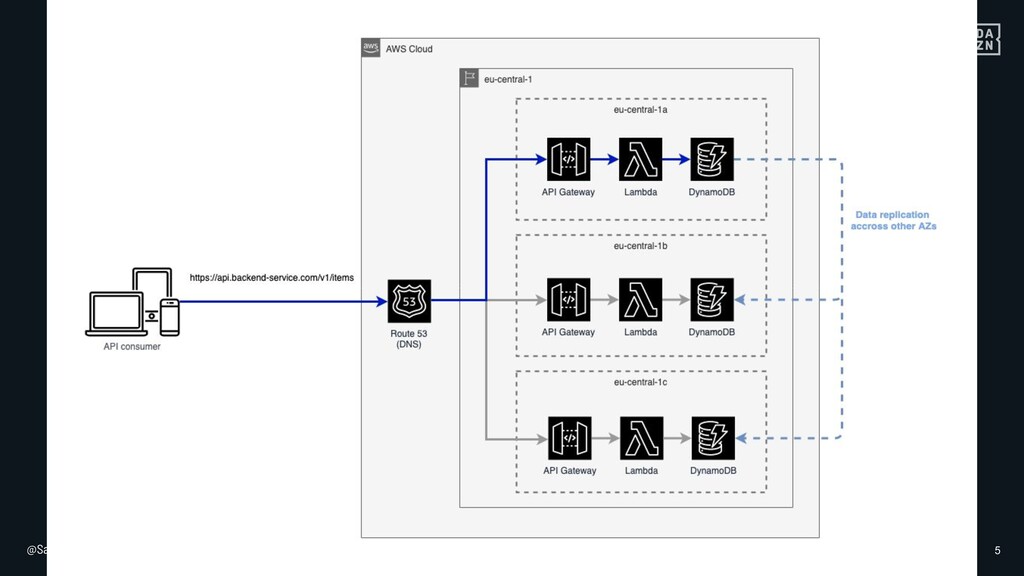
In DAZN, we often rely on AWS serverless services to build a global platform that needs to be highly scalable and highly available. Serverless computing allows developers to focus on the business logic implementation rather than cluster provisioning, maintenance of operative systems and containers orchestration. It also comes with great fault tolerance and reliability. How many times have you heard the phrase: 'You don't need to worry about it, AWS takes care of that for you'. While this is certainly true in some scenarios, it's not always the case.
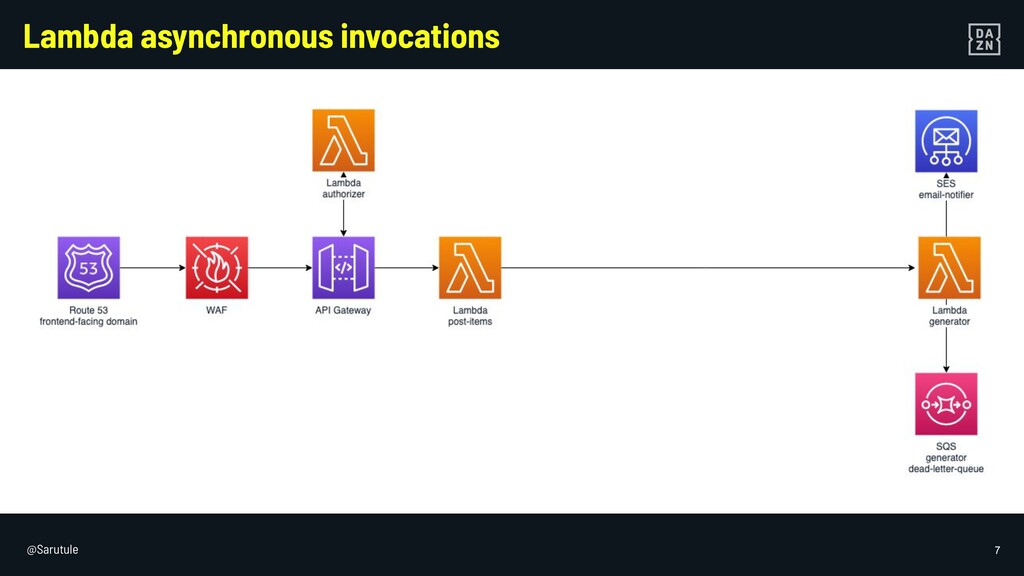
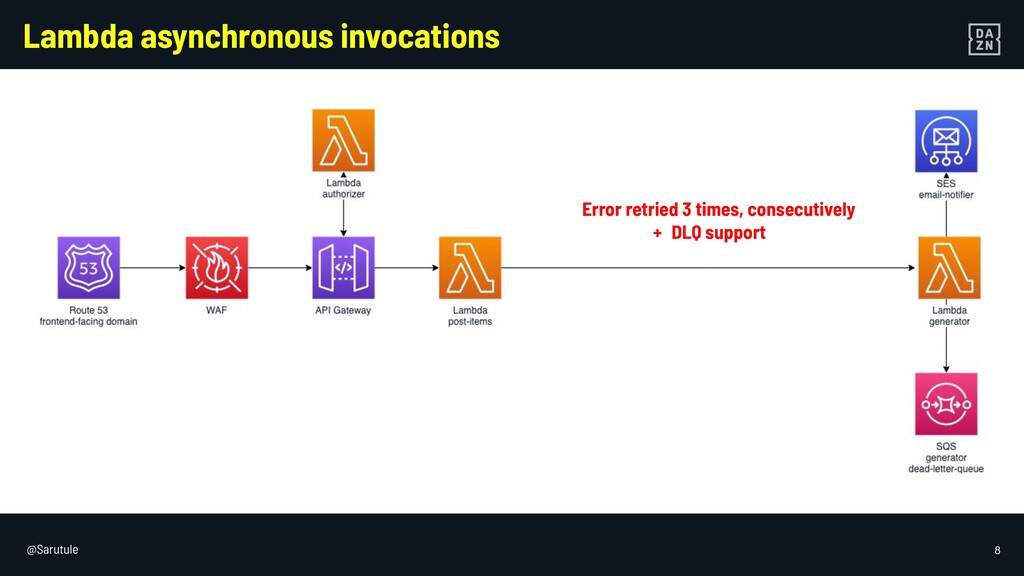
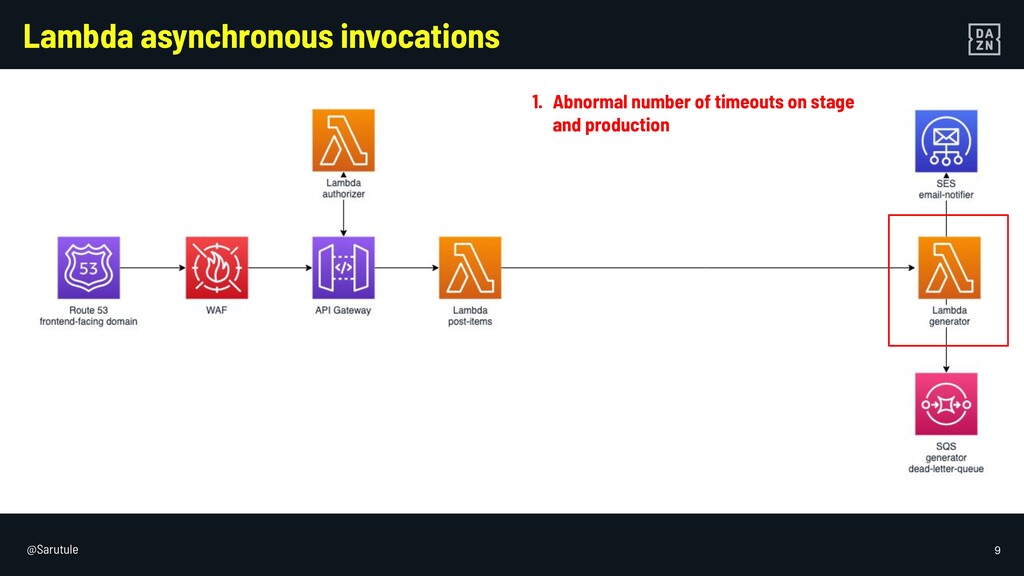
I will go through some examples of not so obvious failure modes of serverless services in AWS, and how to mitigate them, from a backend engineer perspective.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
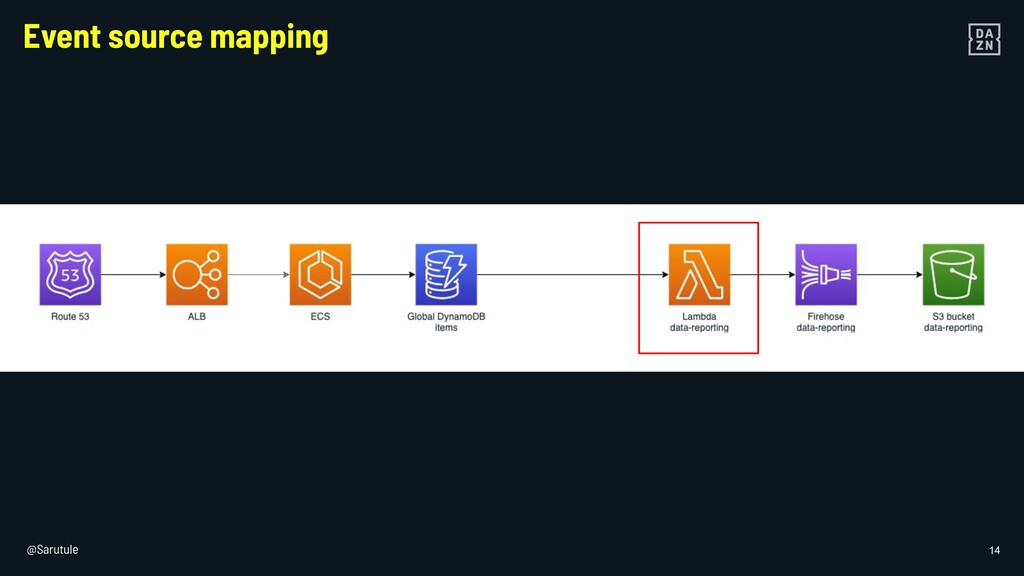{kind=link}
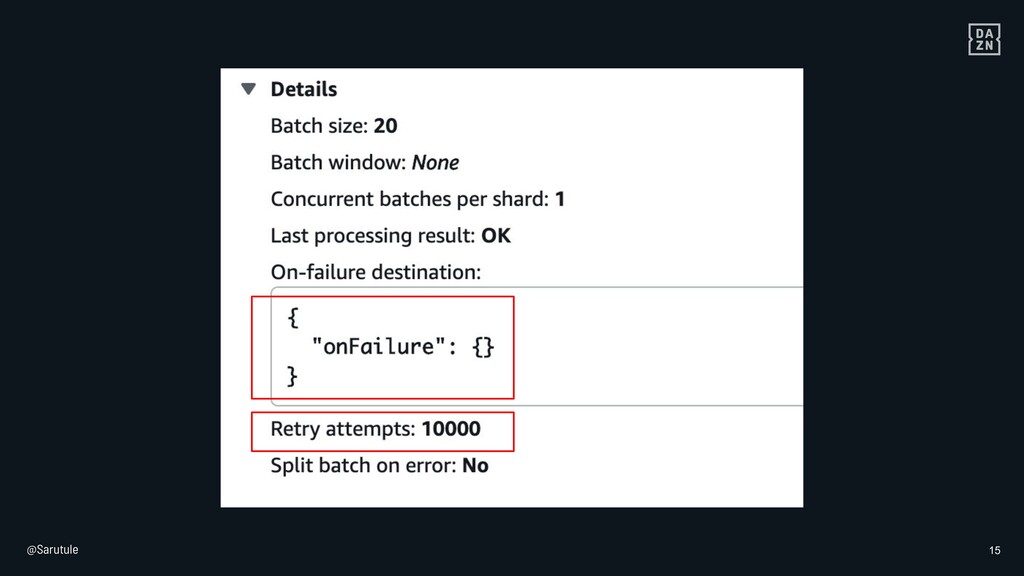{kind=link}
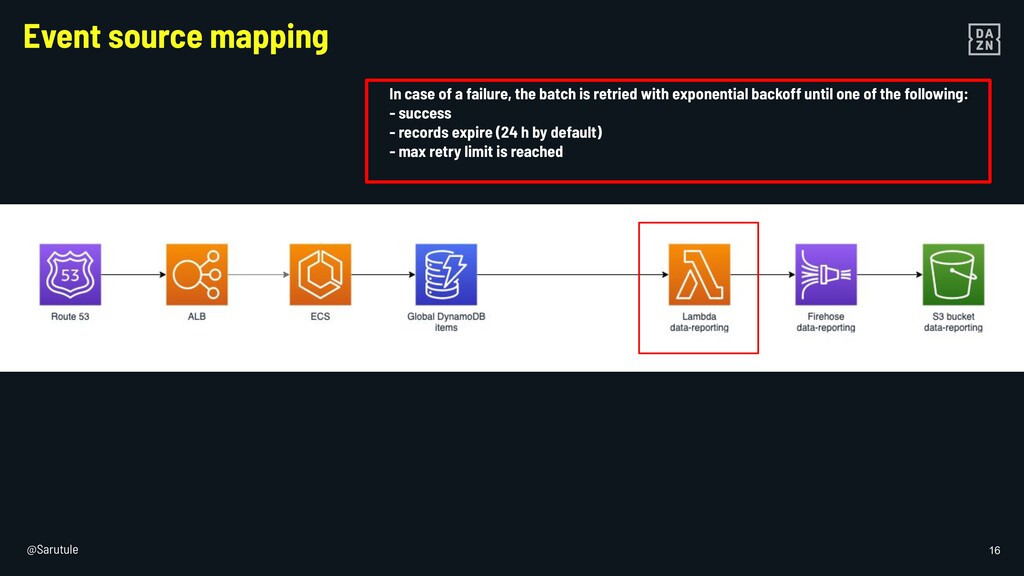{kind=link}
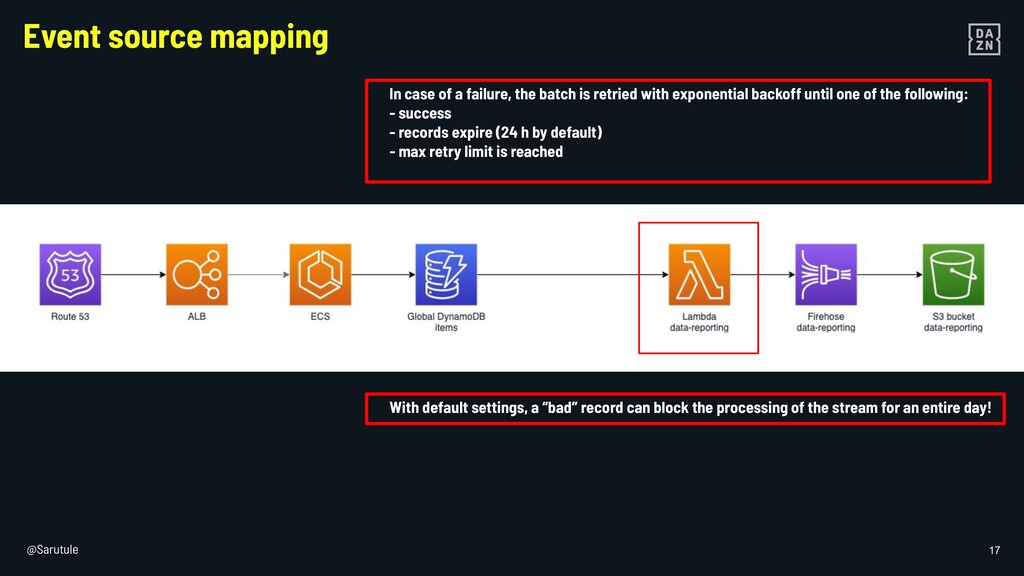{kind=link}
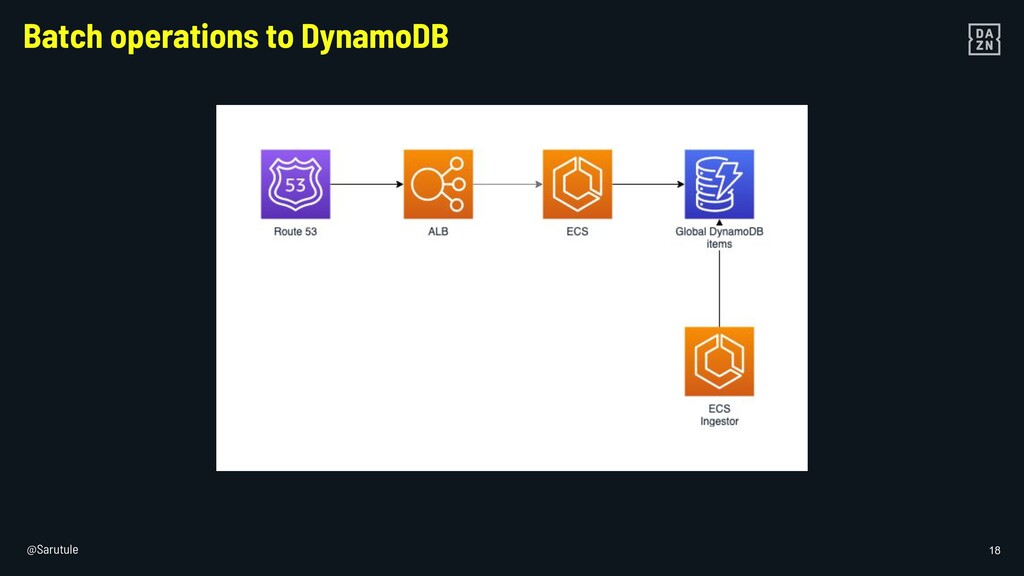{kind=link}
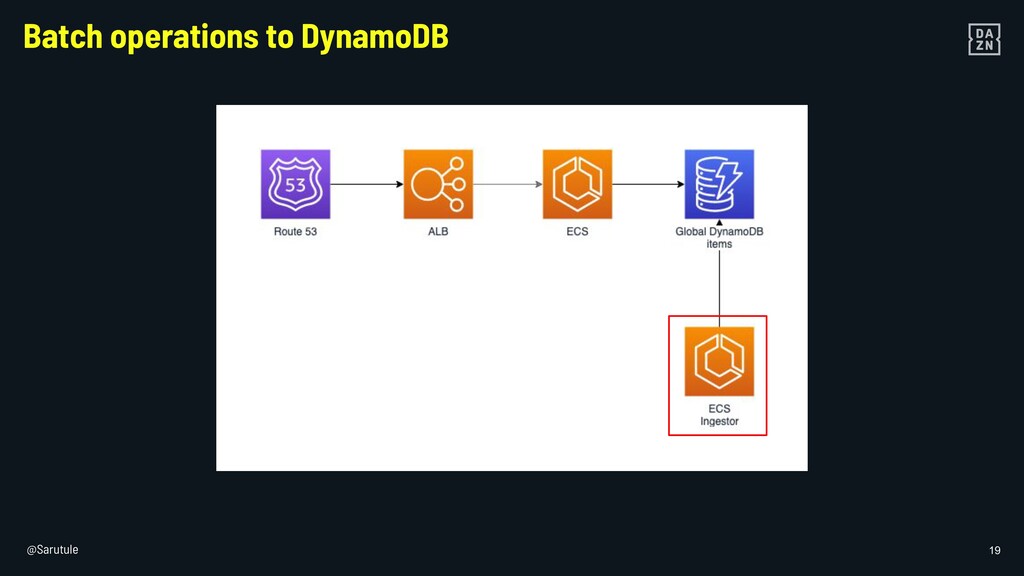{kind=link}
{kind=link}
{kind=link}
{kind=link}
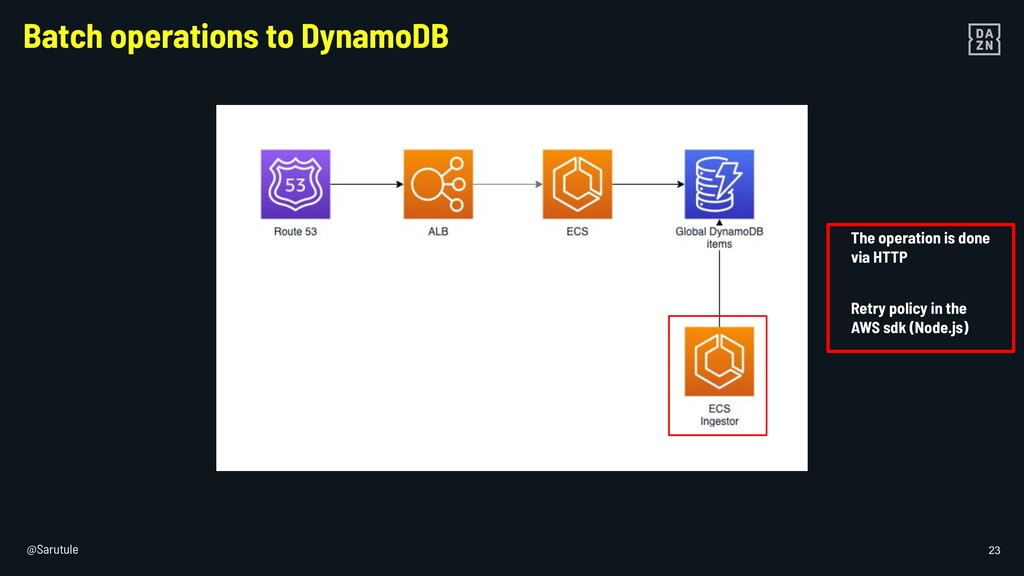{kind=link}
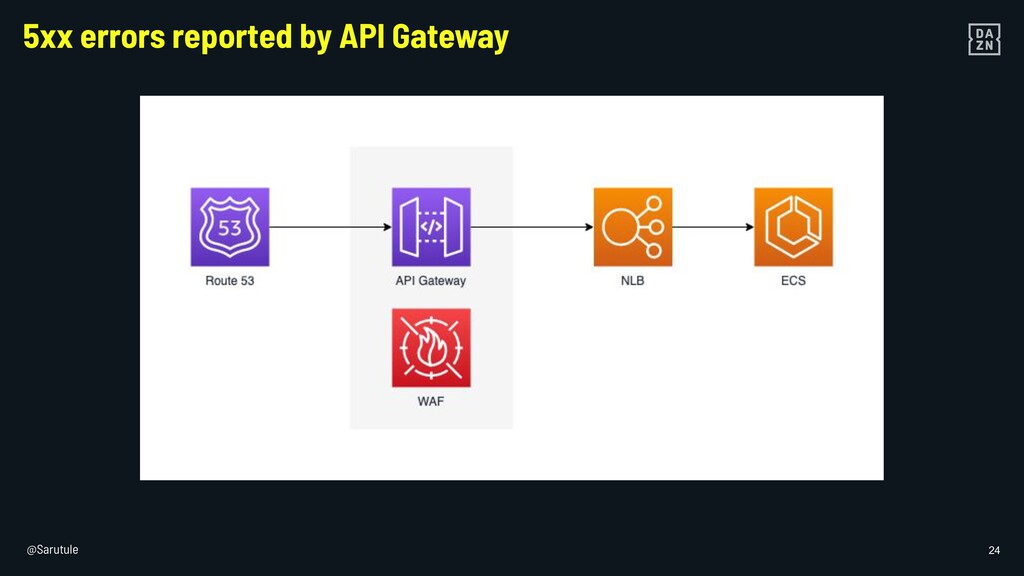{kind=link}
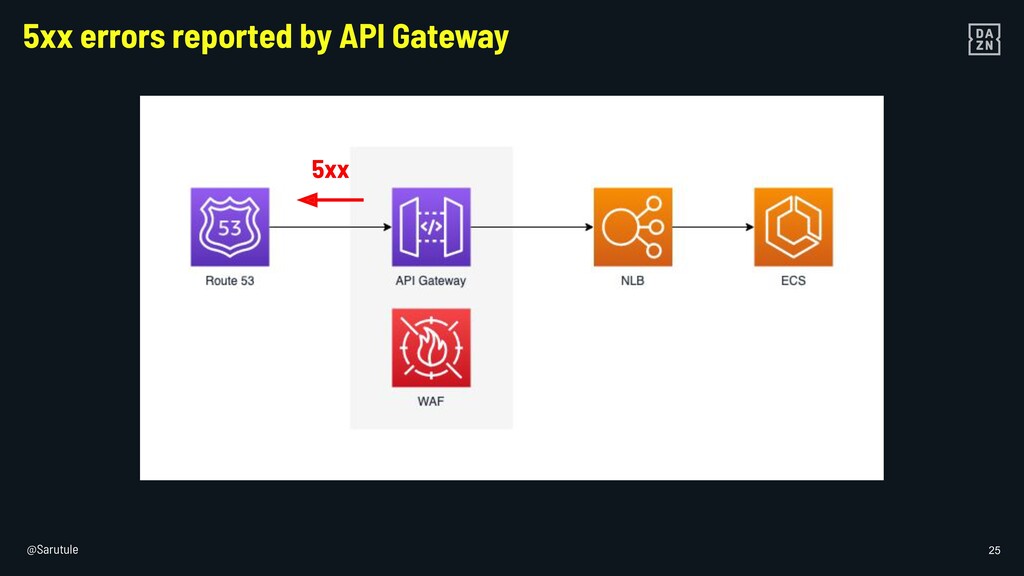{kind=link}
{kind=link}
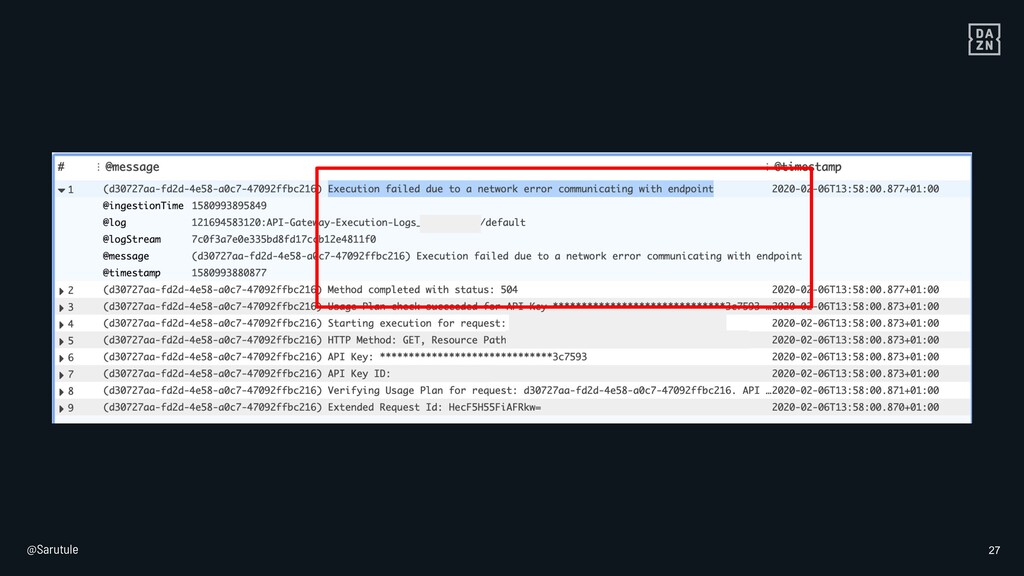{kind=link}
{kind=link}
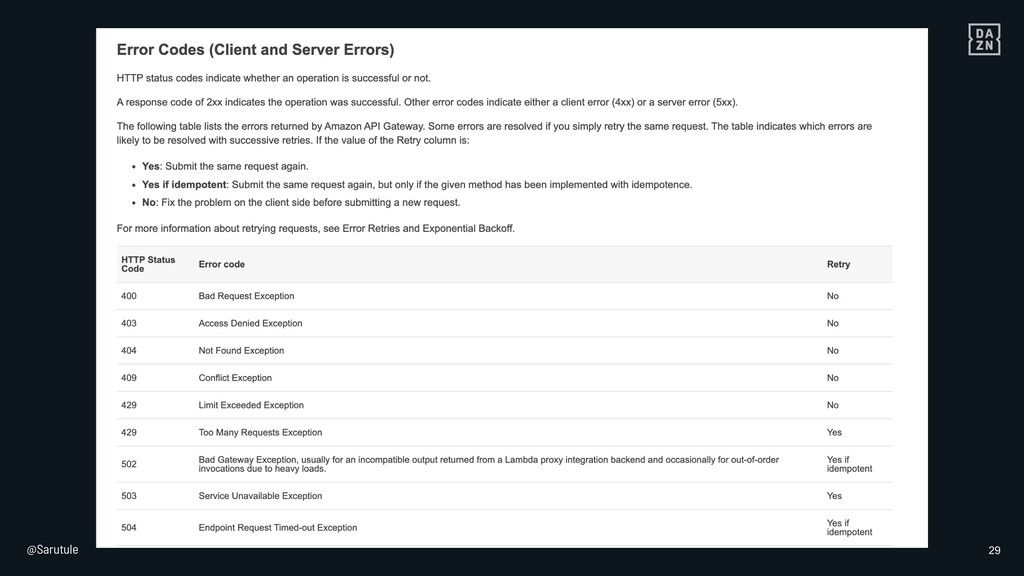{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}