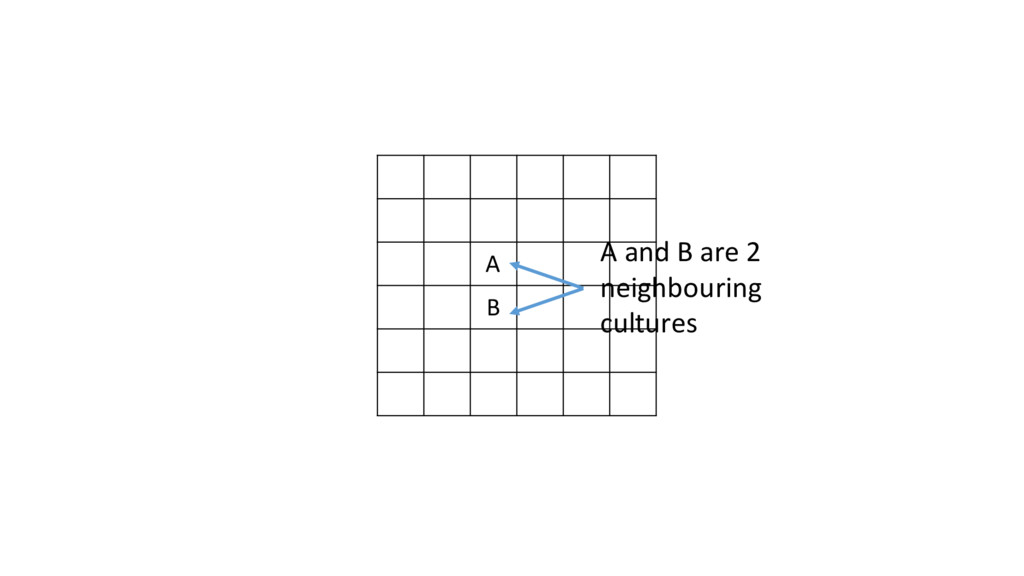
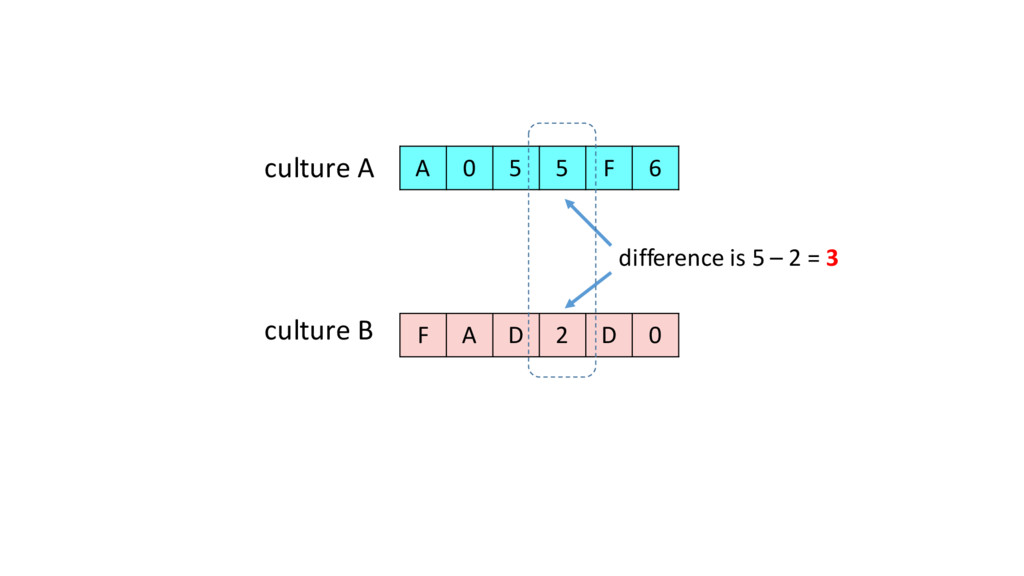
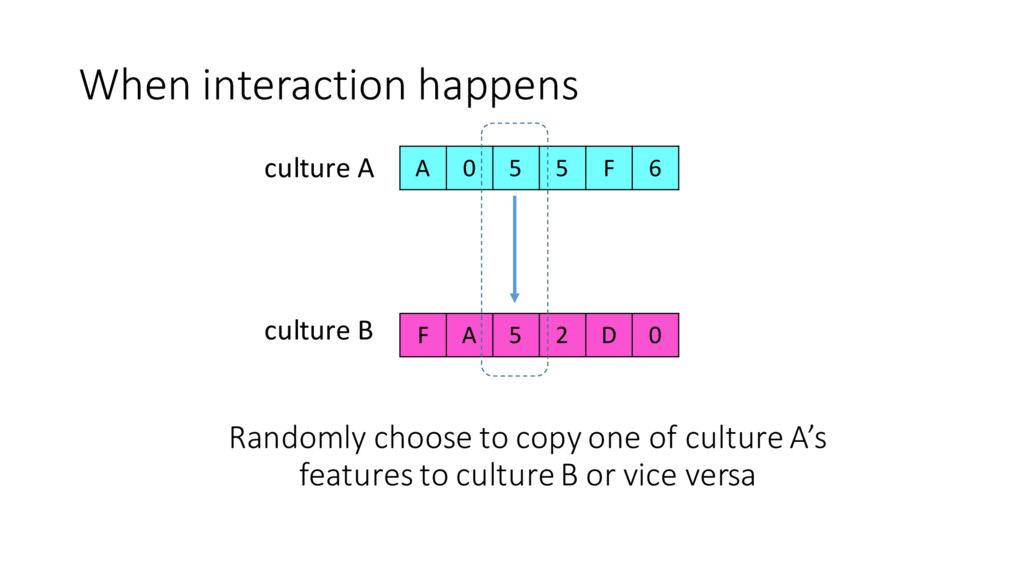
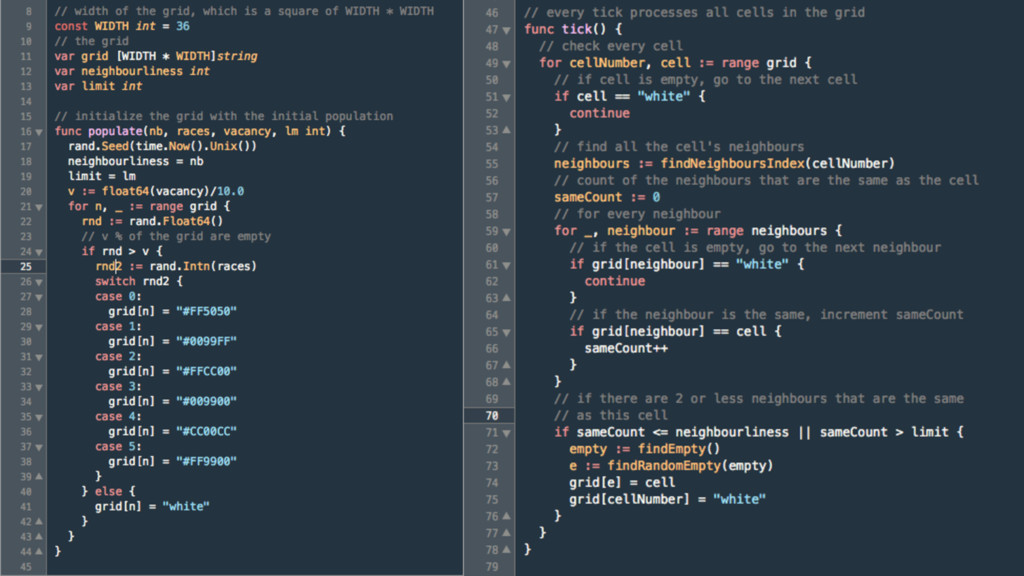
of the culture with each of its neighbours •If the trait difference for the same feature between 2 cultures are < t, randomly select either culture and copy the trait of the feature to the other culture
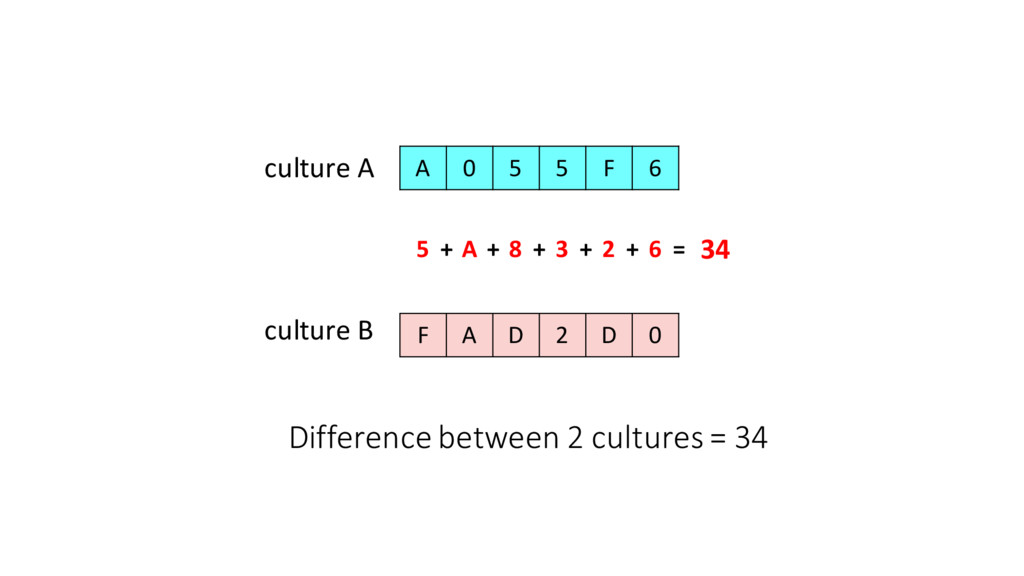
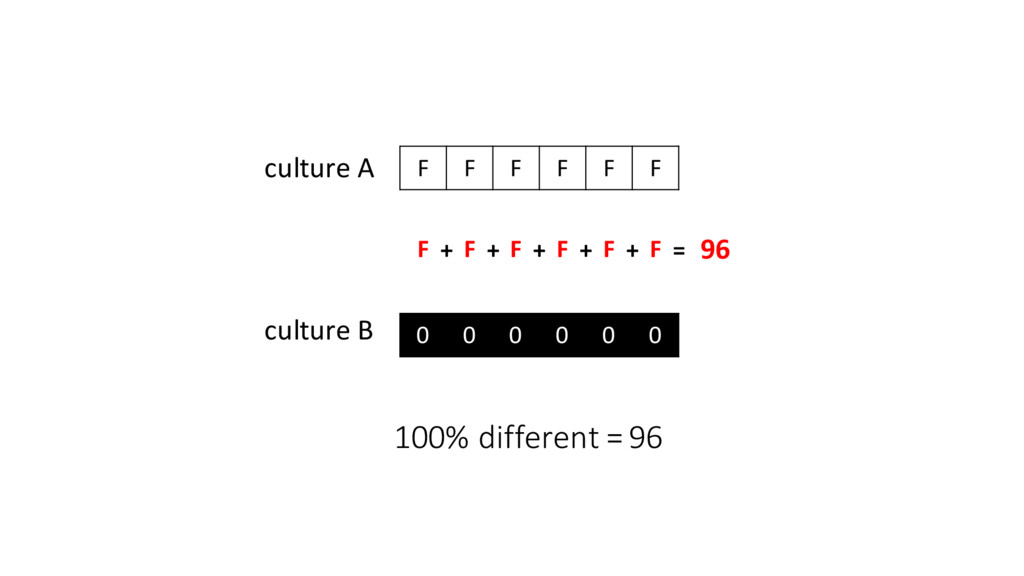
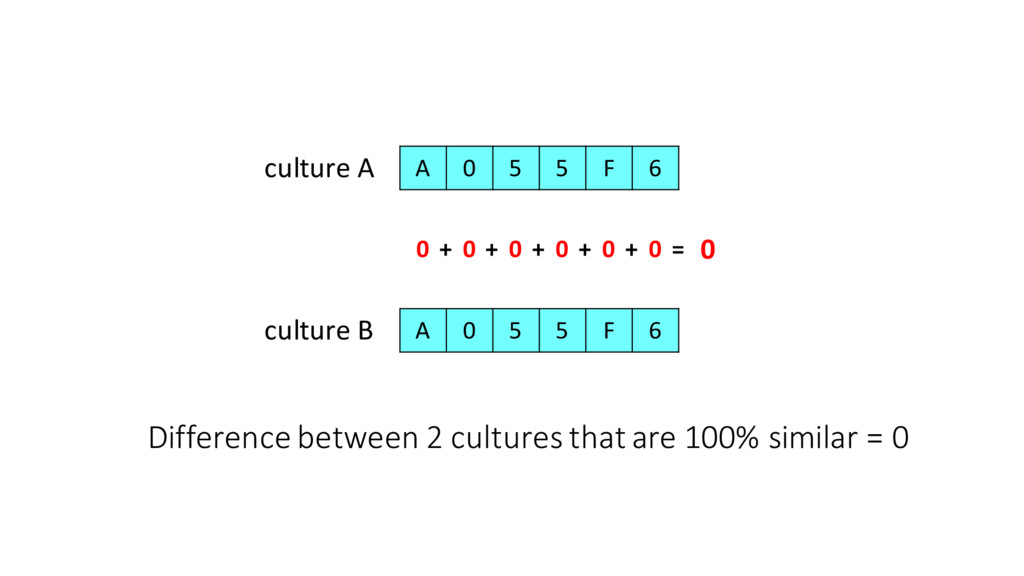
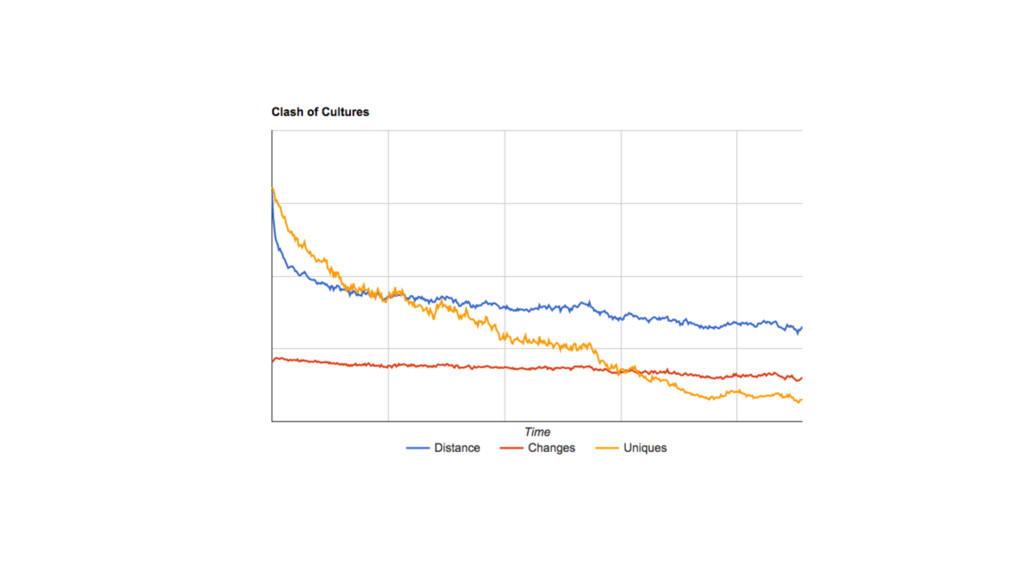
us how far apart (different) the cultures are •Uniques tells us the number of unique cultures at any given point in time •Changes tells us how vibrant the cultural exchanges are
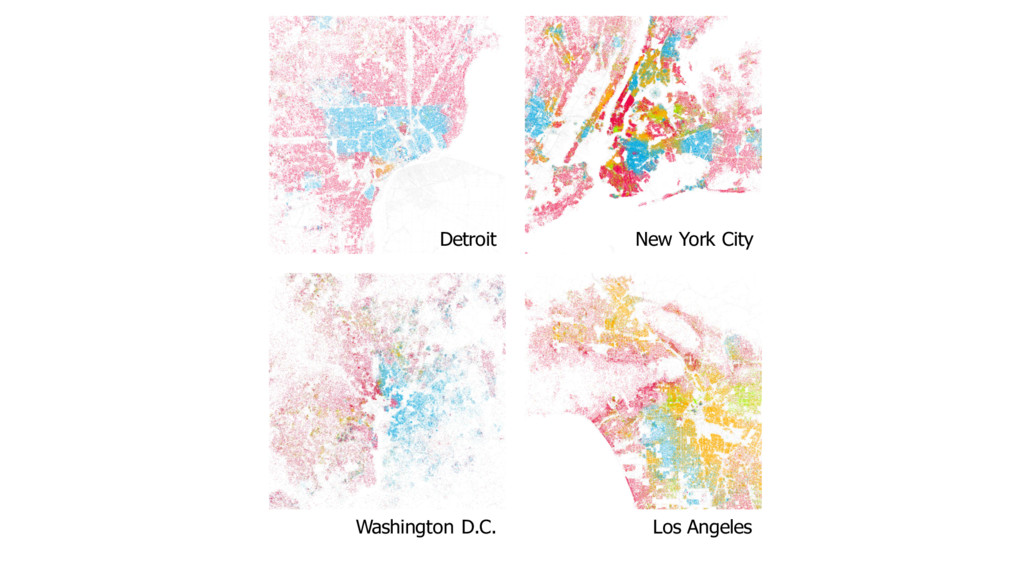
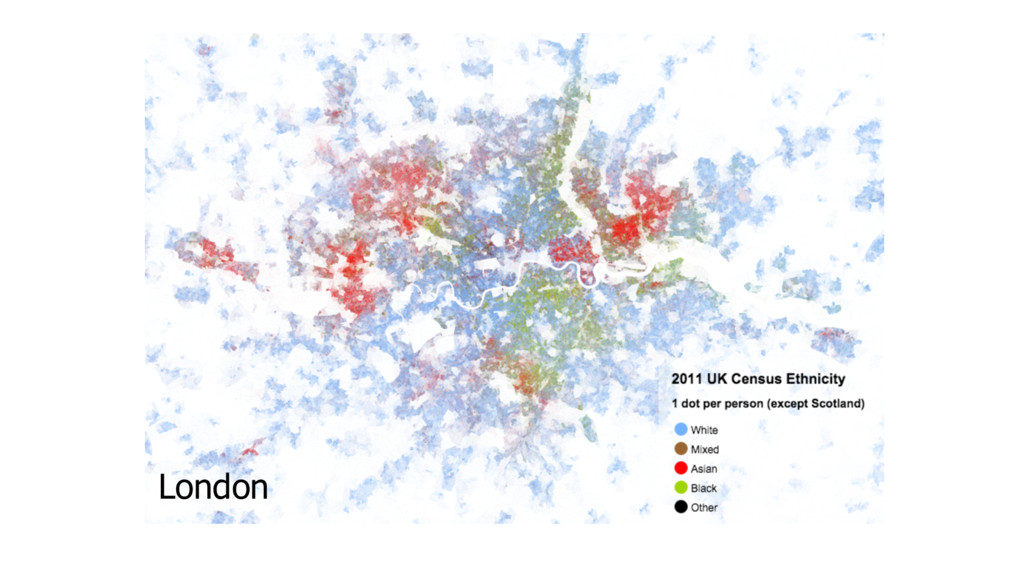
cultures can be quite different from each other •Smaller areas results in faster equilibrium and smaller number of dominant cultures •A culture that is more dominant at a point in time doesn’t mean it will be dominant in the end
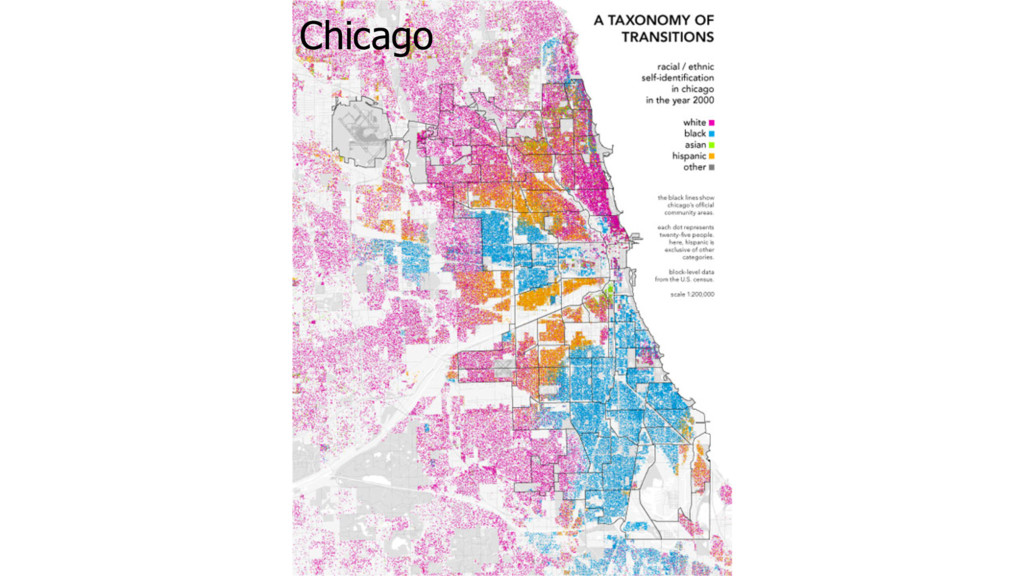
for neighbours of same type • The weaker the preference, the less segregated (smaller clusters) • The stronger the preference, the more segregated (larger clusters) • At a threshold, stronger preference results in an unstable but non-‐ segregated state (occupants always moving to another cell) • Number of races have no impact of segregation • Number of vacant cells have no impact on segregation • Policy enforcement has limited impact on segregation (stronger policies result in unstable state)
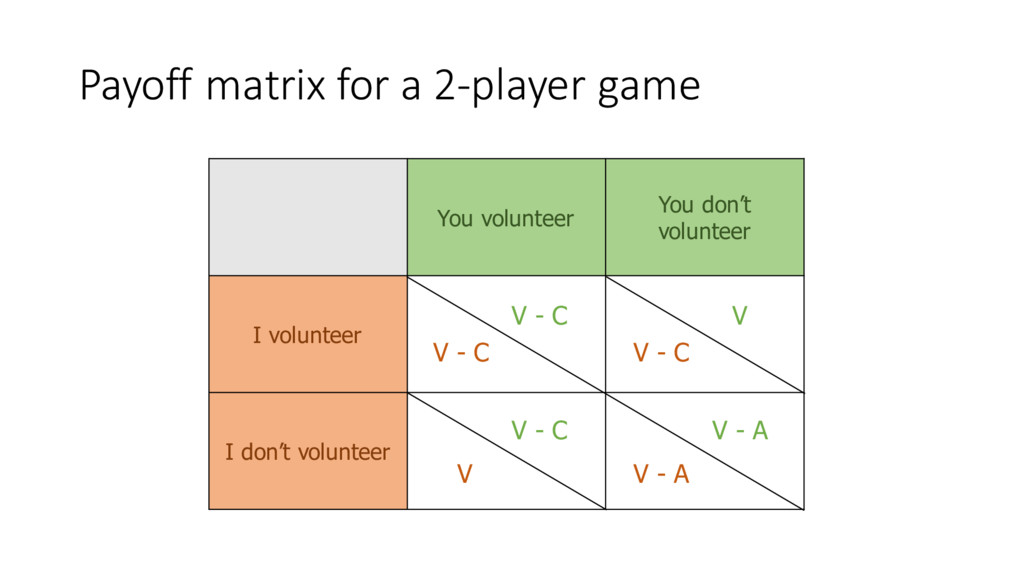
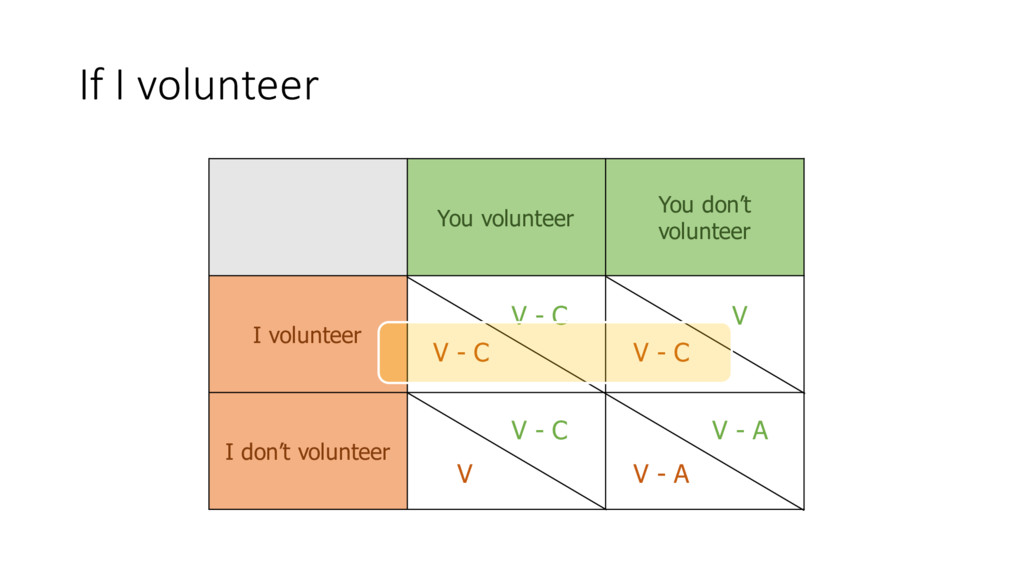
individual cost of volunteering A = overall cost if no volunteers N = number of people involved p = probability of getting at least 1 volunteer 1-‐ p = probability of getting no volunteers V – C = (pN-‐1)V + (1 – p) N-‐1(V – A)
individual cost of volunteering A = overall cost if no volunteers N = number of people involved p = probability of getting at least 1 volunteer 1-‐ p = probability of getting no volunteers p =1− C A " # $ % & ' 1 N−1
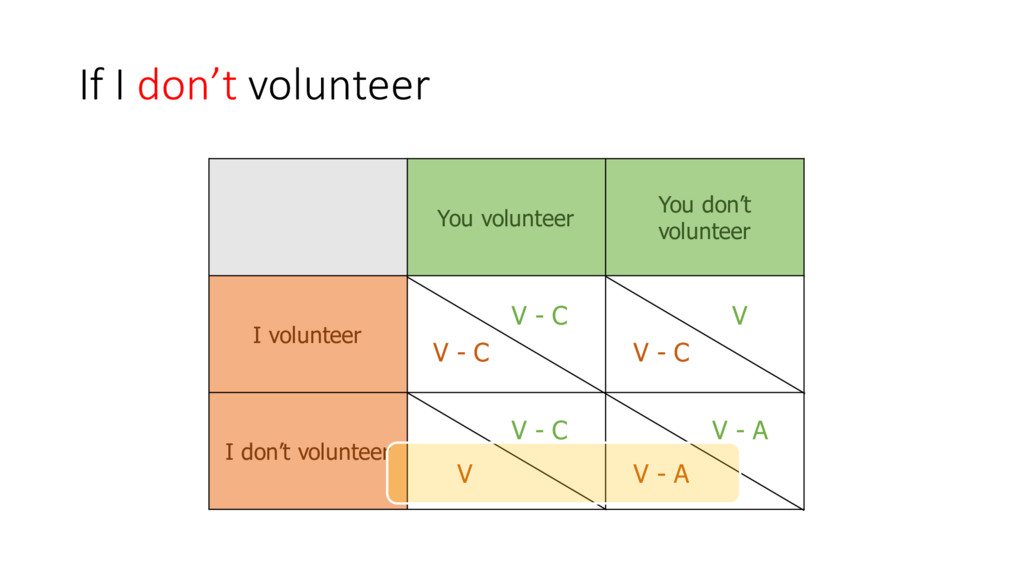
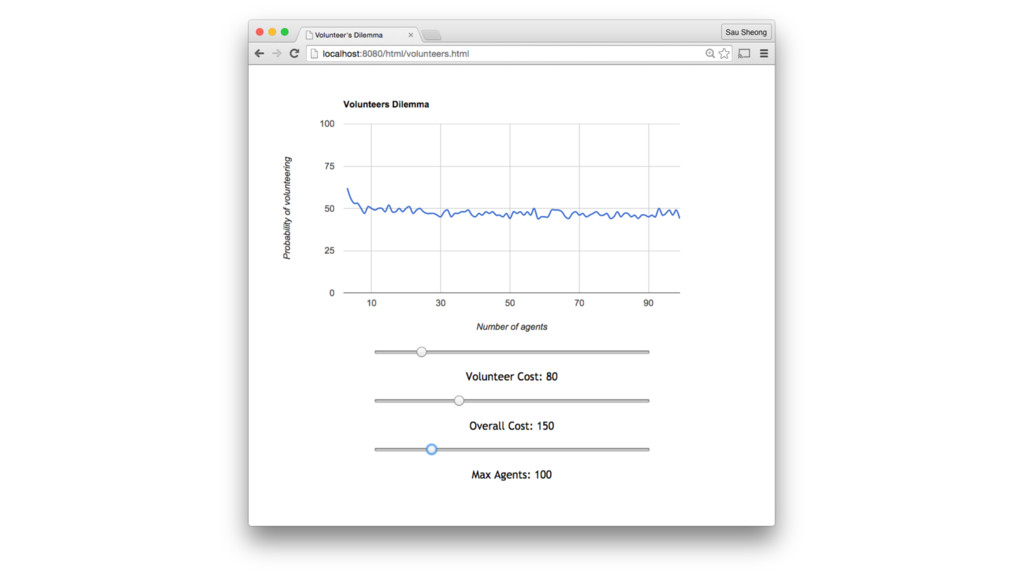
of not volunteering (??) •Increase difference between individual cost and overall costs •Reduce number of ‘players’ •Increasing number of players have negative or no impact
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
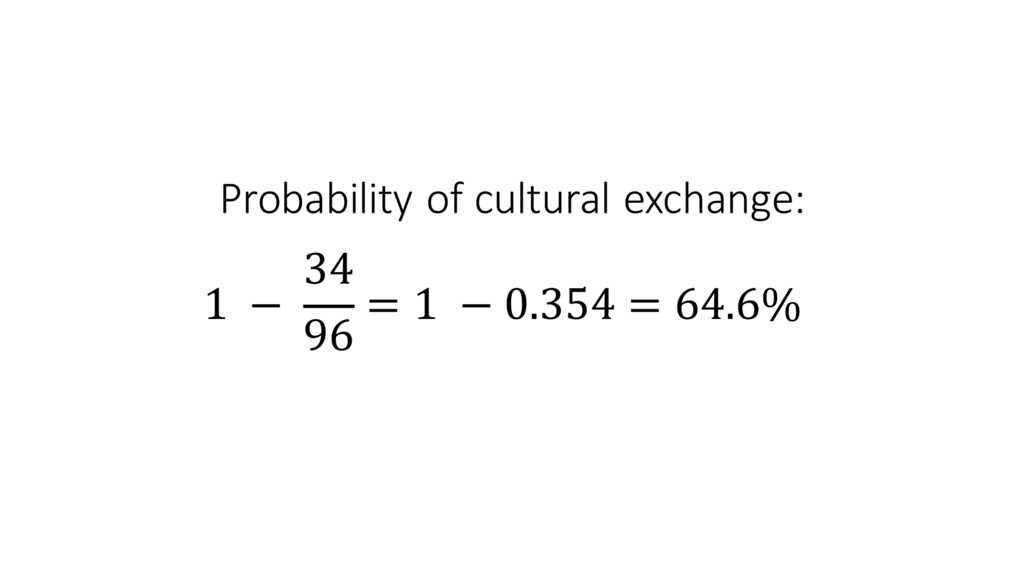{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
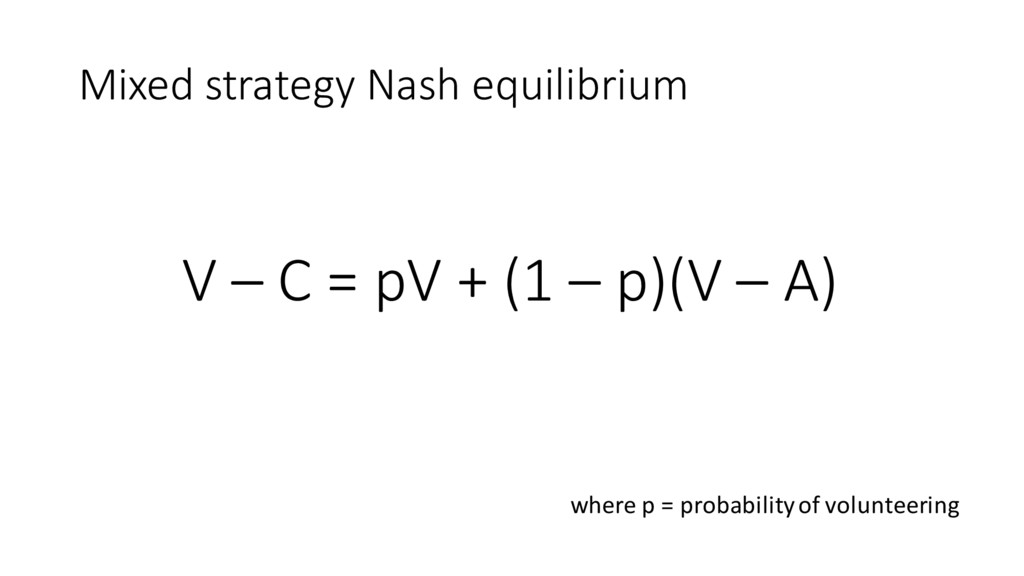{kind=link}
{kind=link}
{kind=link}
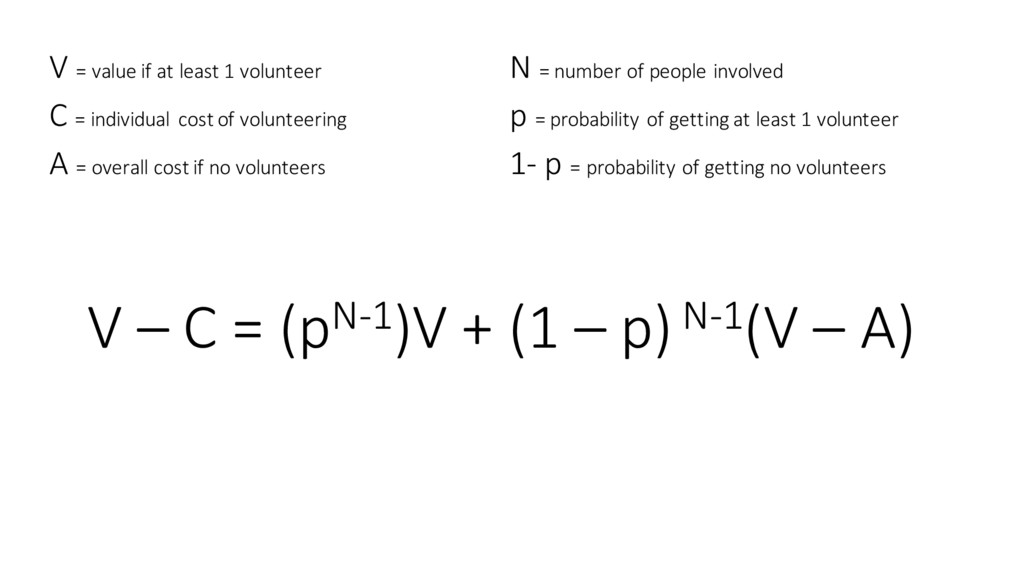{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![@sausheong [email protected] http://blog.saush.com http://github.com/sausheong](https://files.speakerdeck.com/presentations/0d4b2cd0e1e441d18eba03aed2a96138/slide_64.jpg){kind=link}