Ms.c Computer Science Bs.c Software and Computer Engineering Universidad Nacional de Colombia Passionate on building software applications, researching and playing video games
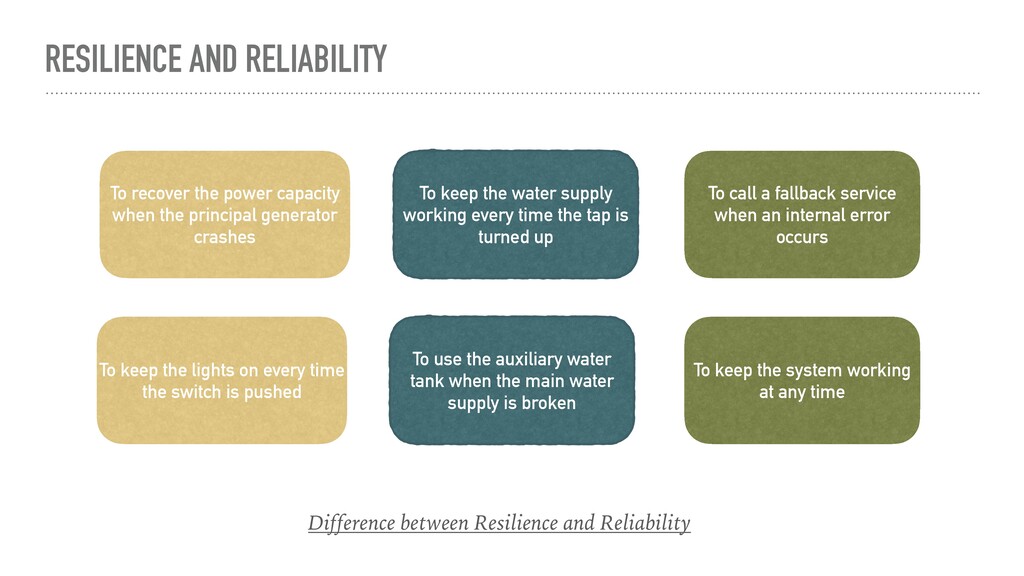
time the tap is turned up To keep the system working at any time To recover the power capacity when the principal generator crashes To call a fallback service when an internal error occurs Difference between Resilience and Reliability To use the auxiliary water tank when the main water supply is broken To keep the lights on every time the switch is pushed
operation for a specified period of time in a specified environment” Resilience is “the ability of a cloud-based service to withstand certain types of failures and yet remain functional from the customer perspective” Every system needs to be RESILIENT in order to be RELIABLE. But one concept per se, does not imply the other
and we cannot remove the complexity, then what is supposed to be done? Embrace complexity rather than avoid it, trying to optimize for simplicity leads to frustration Learn to navigate complexity. Find tools to move quickly with confidence.
a software system in production in order to build confidence in the system's capability to withstand turbulent and unexpected conditions.” How much confidence we can have in the complex systems that we put into production? “Unpredictable outcomes, compounded by rare but disruptive real-world events that affect production environments, make distributed systems inherently chaotic.” Chaos engineering is a form of experimentation, rather than a form of testing It is about making the chaos inherent in the system visible
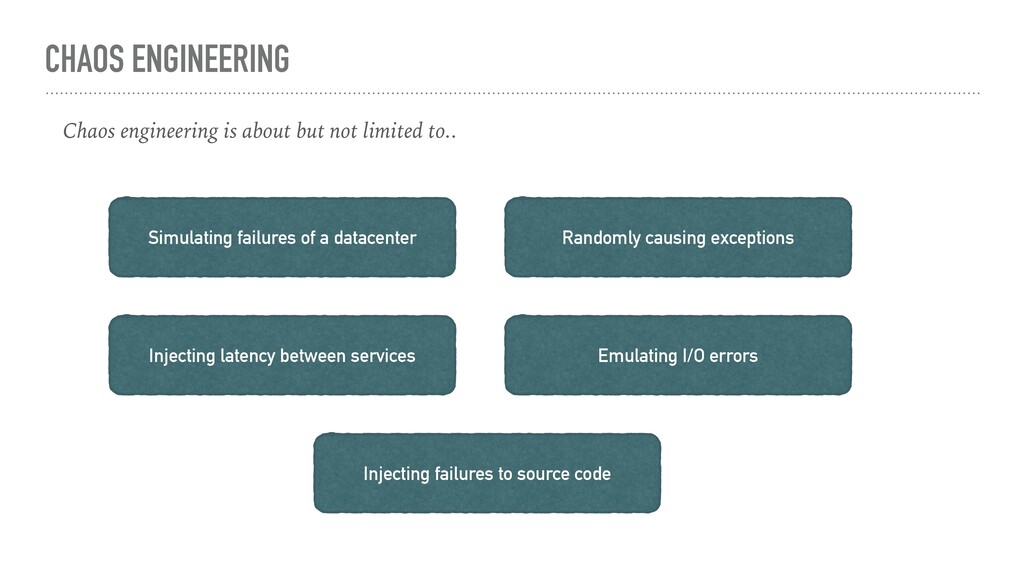
Simulating failures of a datacenter Injecting latency between services Randomly causing exceptions Emulating I/O errors Injecting failures to source code
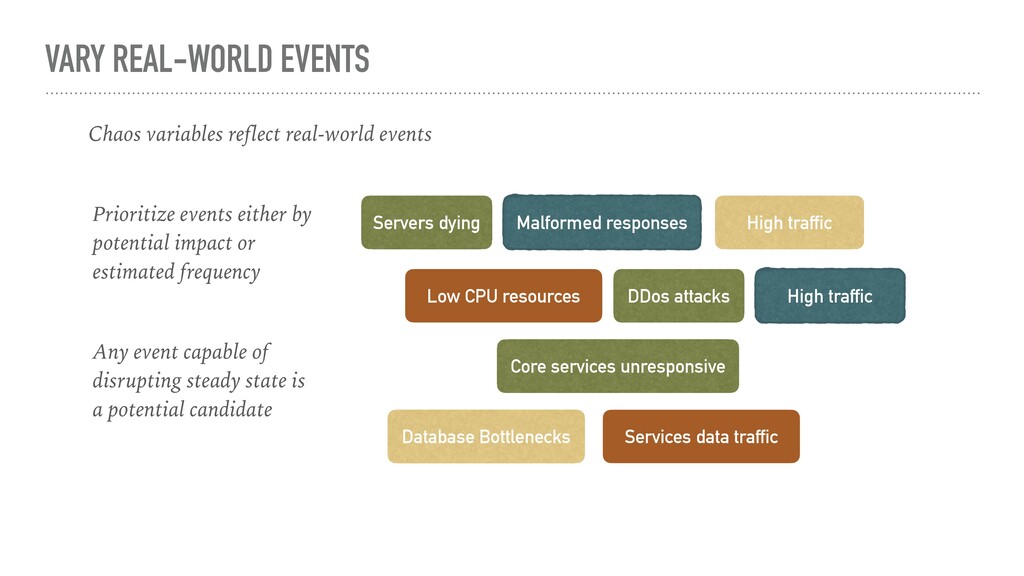
Malformed responses High traffic Low CPU resources DDos attacks High traffic Core services unresponsive Database Bottlenecks Services data traffic Prioritize events either by potential impact or estimated frequency Any event capable of disrupting steady state is a potential candidate
environment and traffic patterns Sampling real traffic is the only way to reliably capture the request path Chaos strongly prefers to experiment directly on production Keep a detailed tracking of each experiment Application name Hypothesis Environment Duration Load Observability Results Actions
at Amazon and was responsible for availability. Jesse created GameDays with the goal of increasing reliability by purposefully creating major failures on a regular basis” Engineering Teams Support Teams Management Teams Target Time and Place Goals Have Fun Whiteboarding
in-person attendance ➤ Dial-in information (conference link) Things to include ➤ Start ➤ Whiteboarding ➤ Test cases and scoping ➤ Execution ➤ Recap ➤ Key people in attendance Agenda items
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}