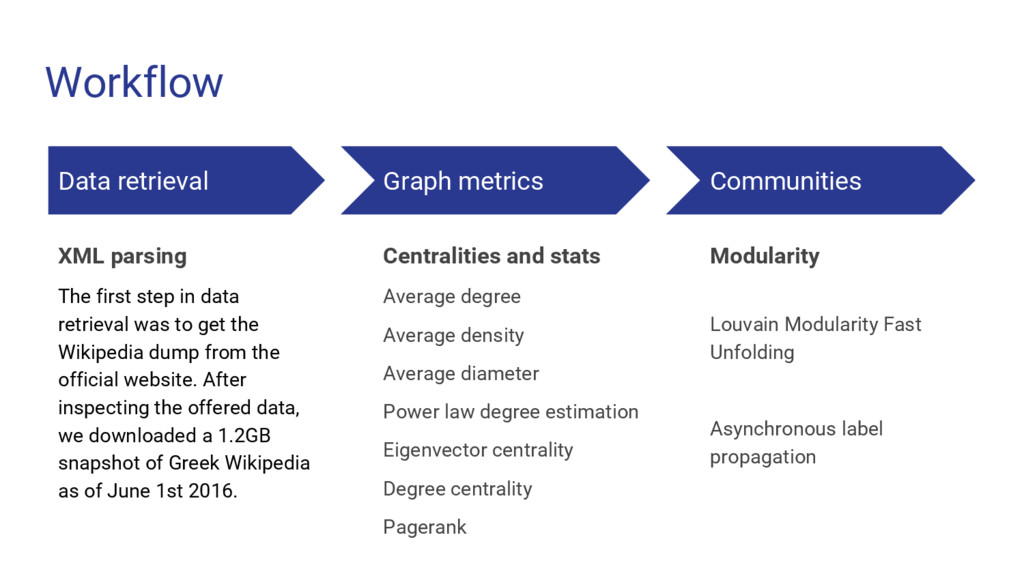
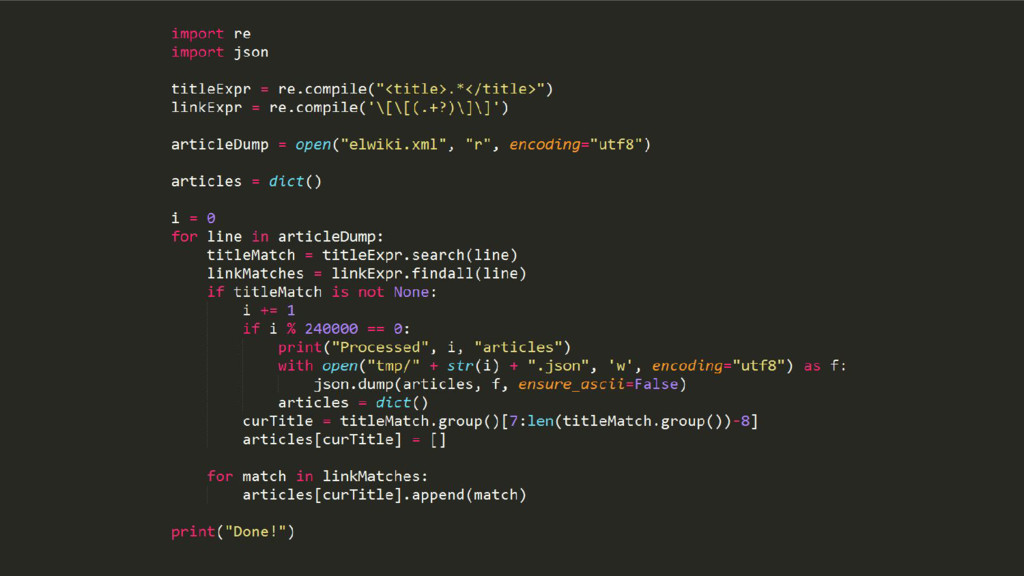
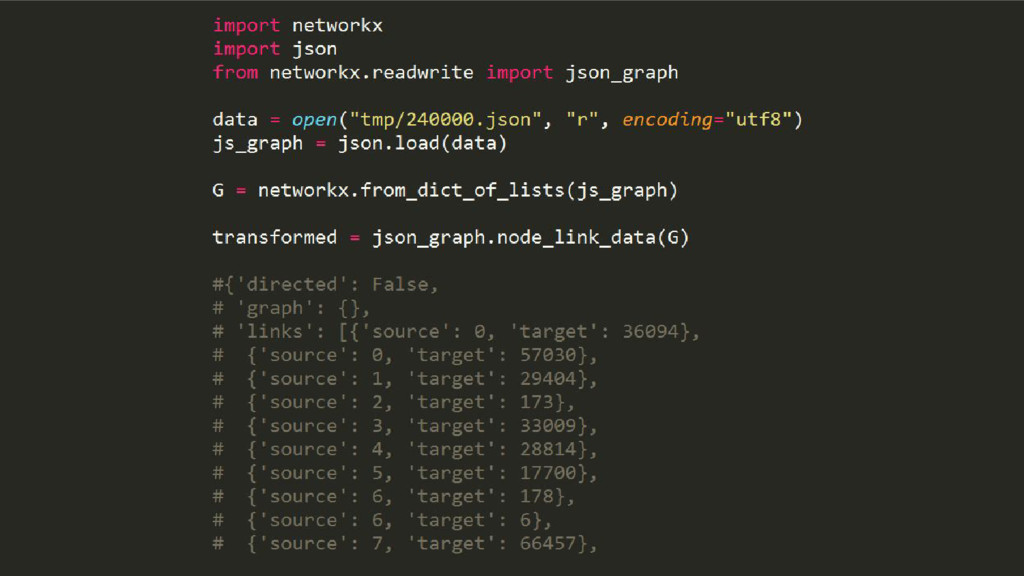
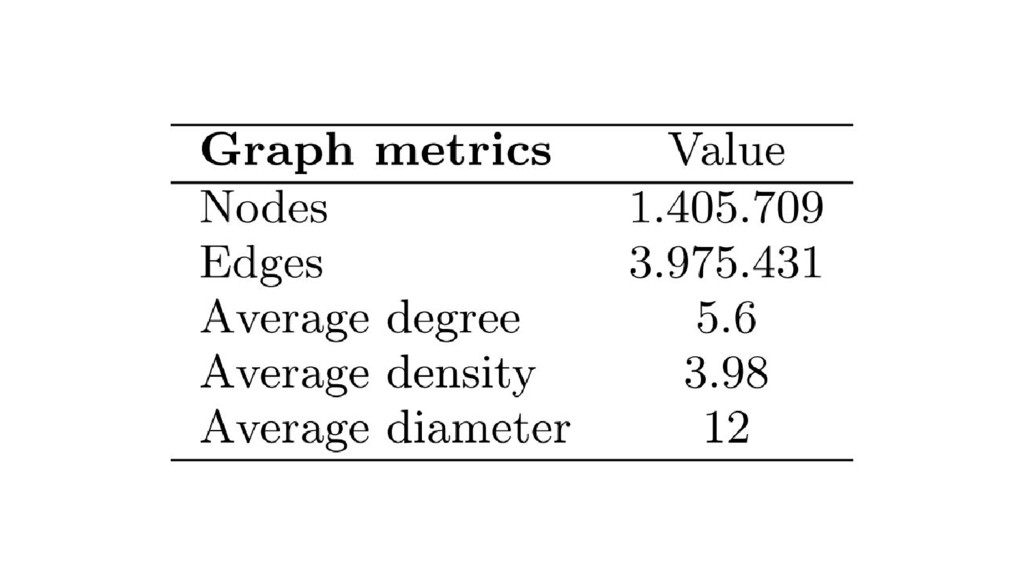
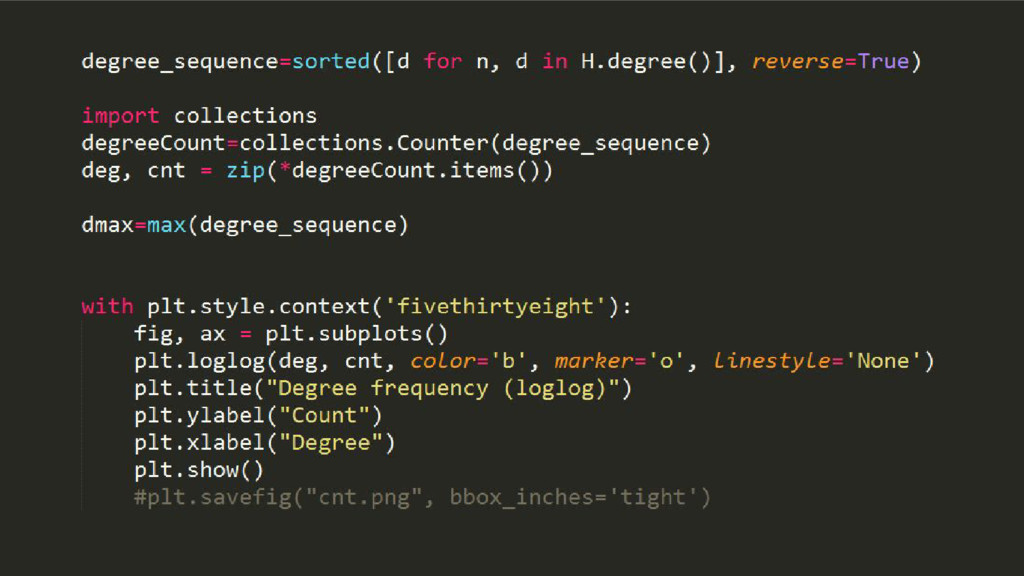
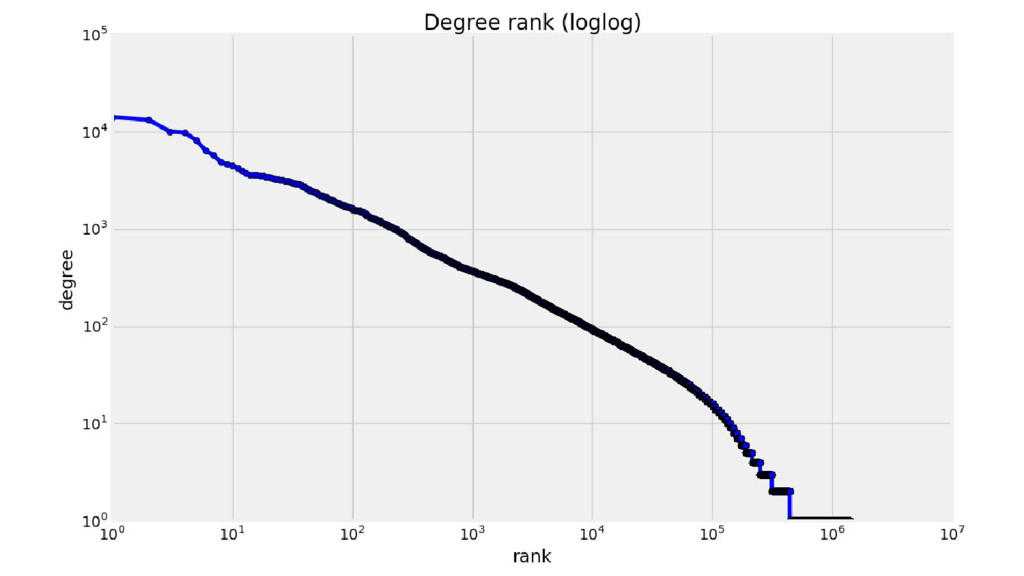
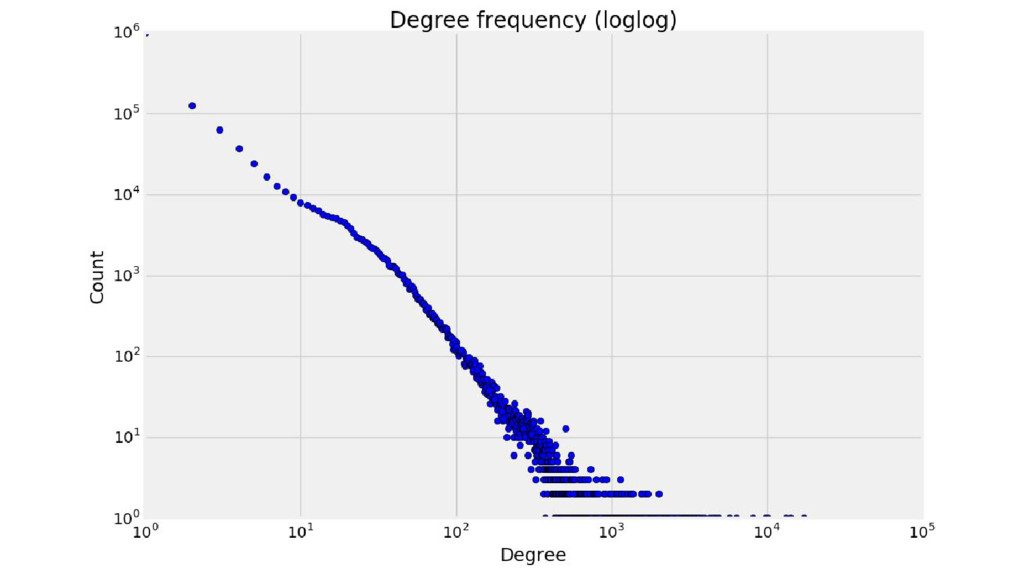
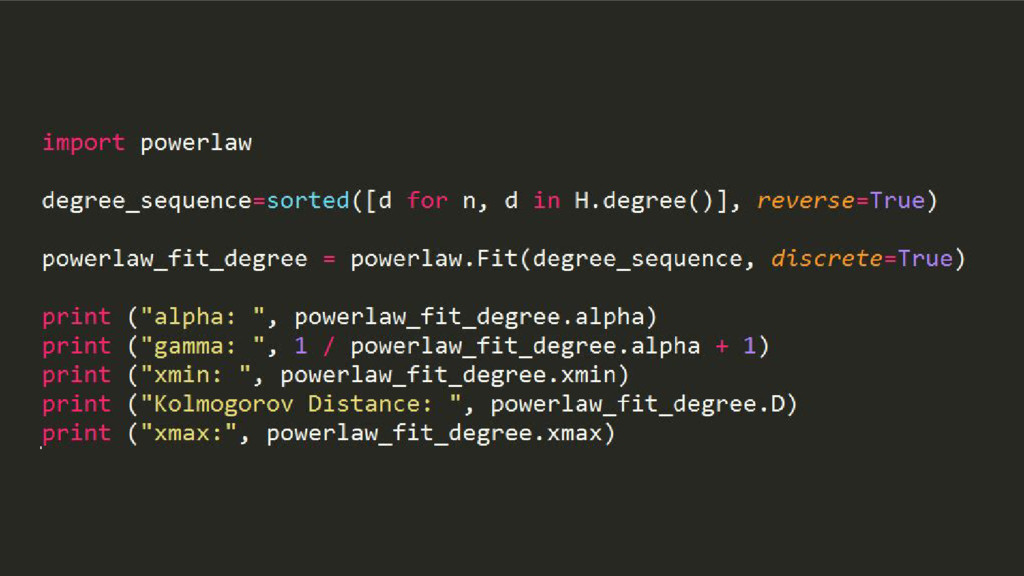
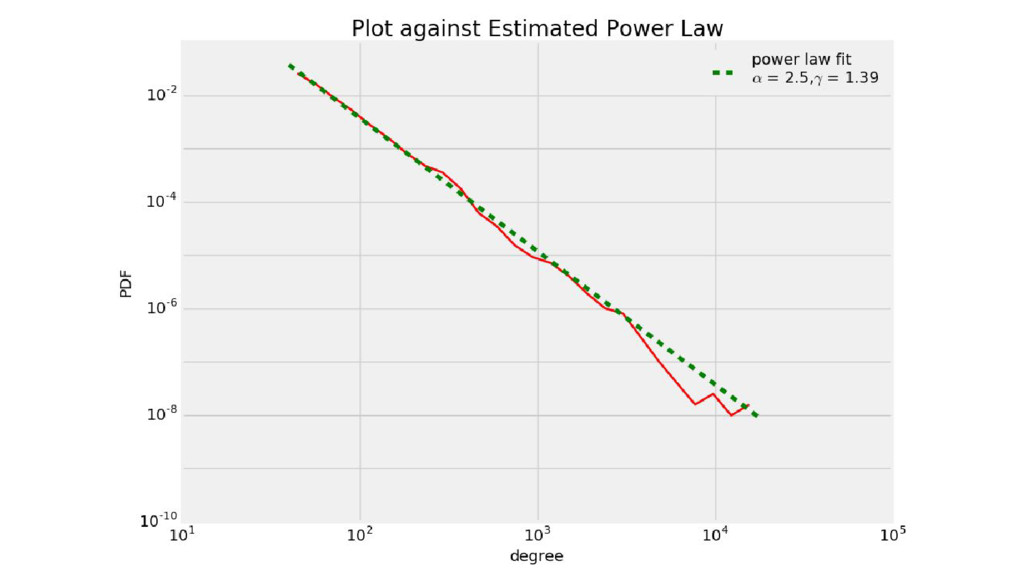
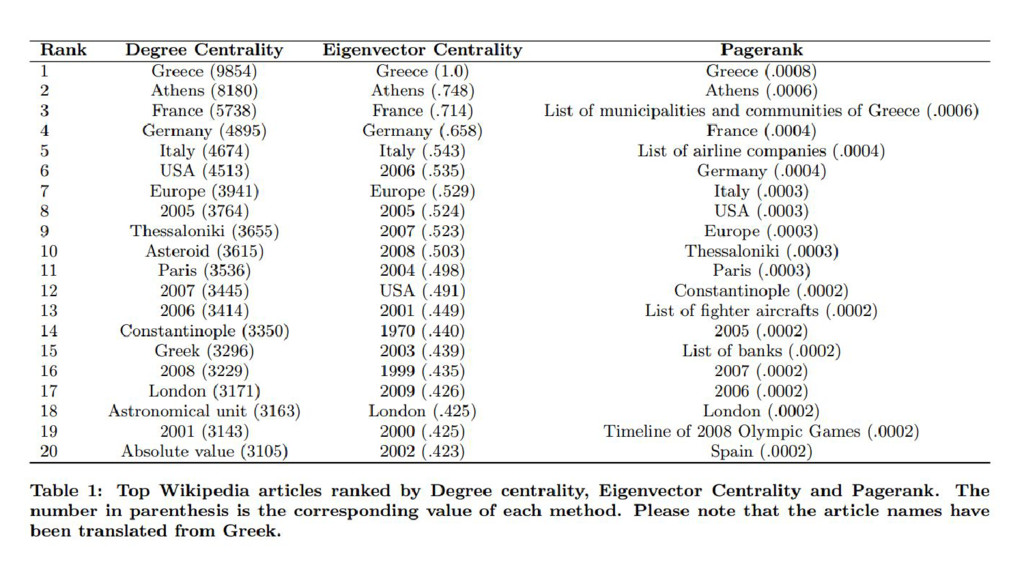
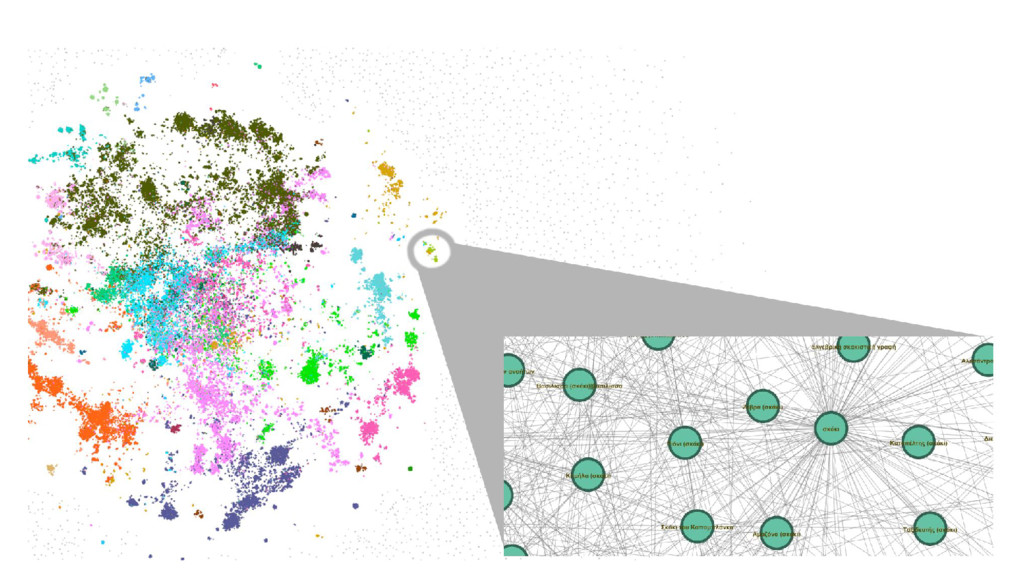
Wikipedia is the largest, most carefully indexed collection of human knowledge ever amassed. More than information about a topic, Wikipedia is a web of naturally emerging relationships. By retrieving the hyperlinks inside each article, we algorithmically construct an undirected network of all 240.000 articles of the Greek edition of Wikipedia. We show that the resulting network graph of 1.405.709 nodes (articles) and 3.975.431 edges (links) follows a power law degree distribution. An empirical comparison of centrality measures (eigenvector, degree and Pagerank) unveils the top-k articles. We find semantically related subgraphs via community detection by evaluating the Louvain Method and Asynchronous Label Propagation. We discuss the leverage of graph structure of local Wikipedias for augmenting NLP tasks in underrepresented languages.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}