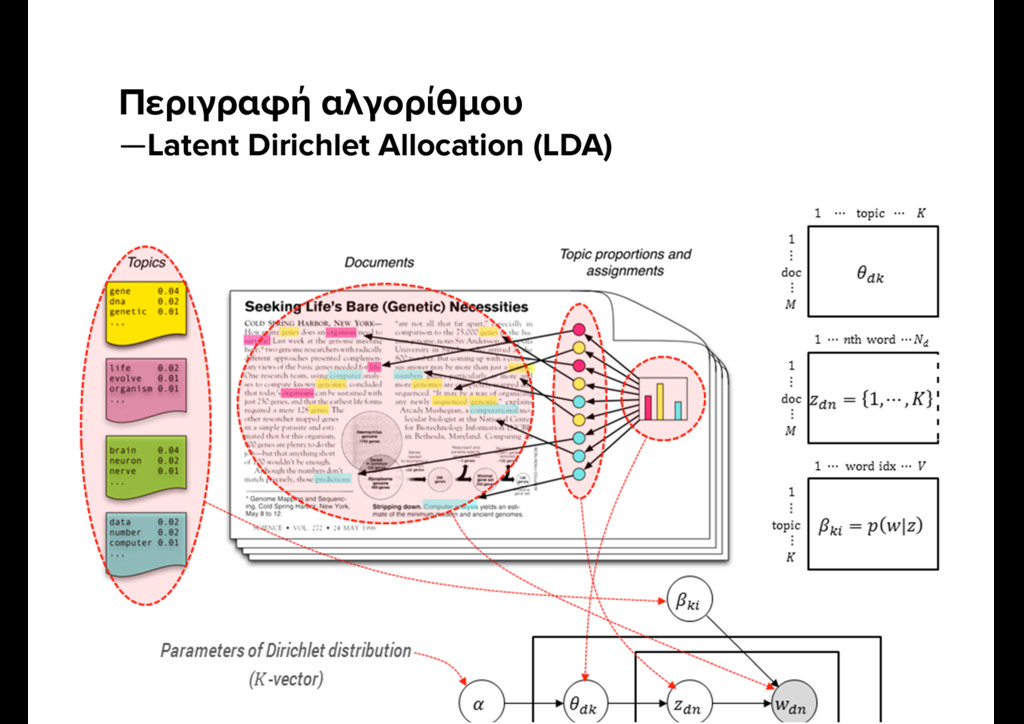
Watching TV is usually accompanied with comments about the content. We tend to address these comments to nearby people or online friends. In this empirical study we retrieved 30k Twitter status updates during popular TV talk shows. Topic modeling analysis allows us to separate themes and, eventually, summarize long TV broadcasts automatically.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Περιγραφή αλγορίθμου — Transform time zone to GMT+2 tweets['created_at'] =](https://files.speakerdeck.com/presentations/2058684d99e54291b6ba1358efee3d01/slide_6.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
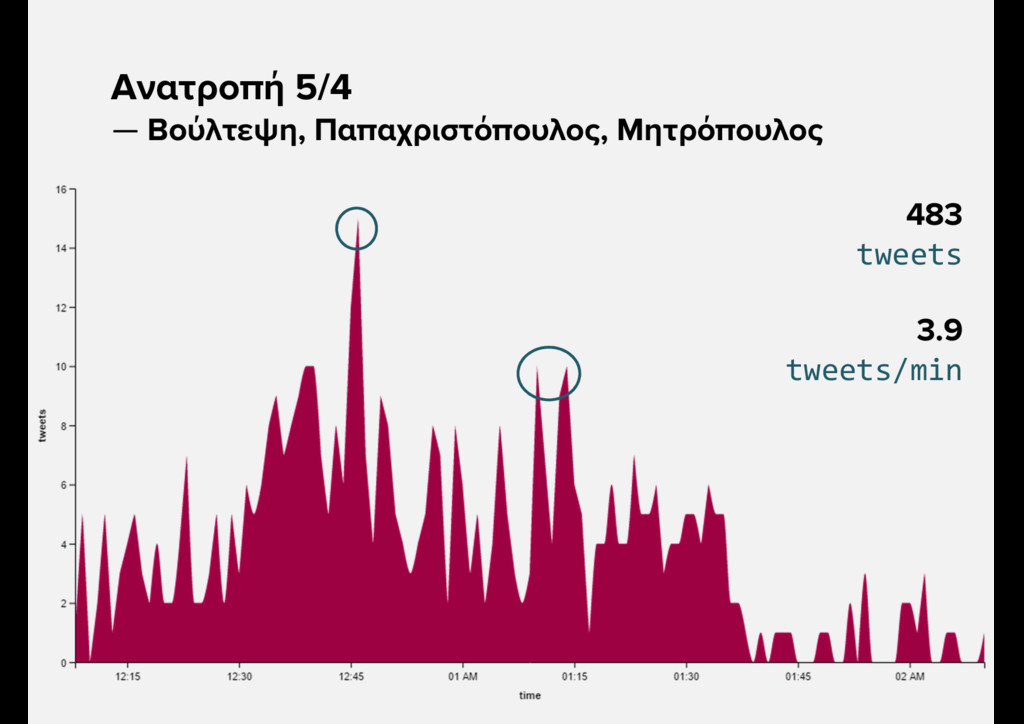{kind=link}
{kind=link}
{kind=link}
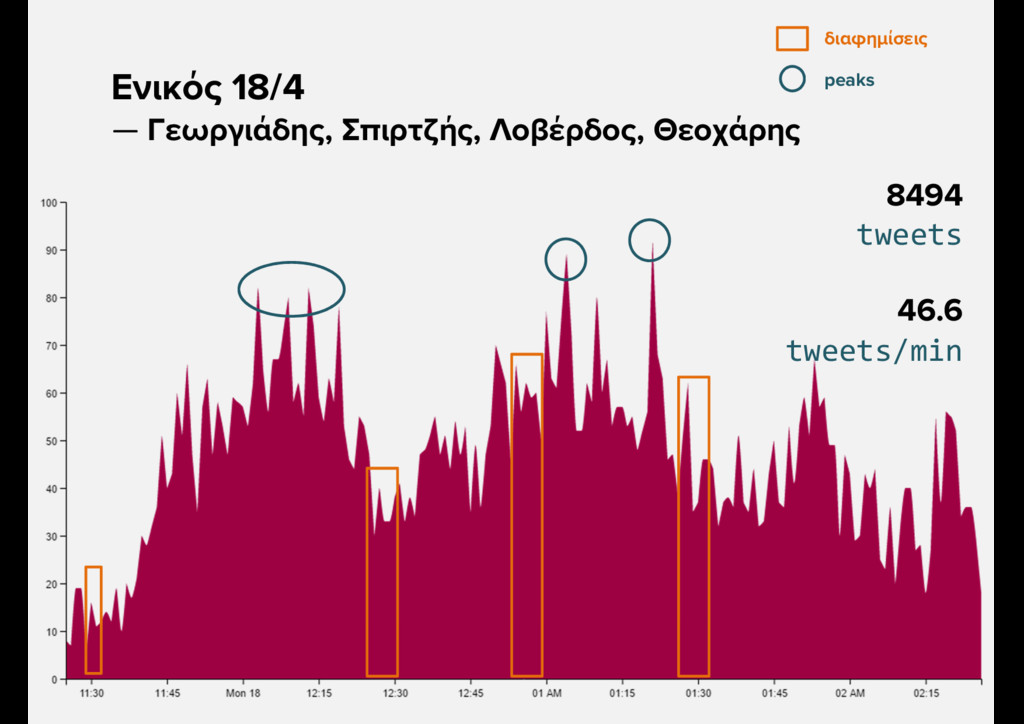{kind=link}
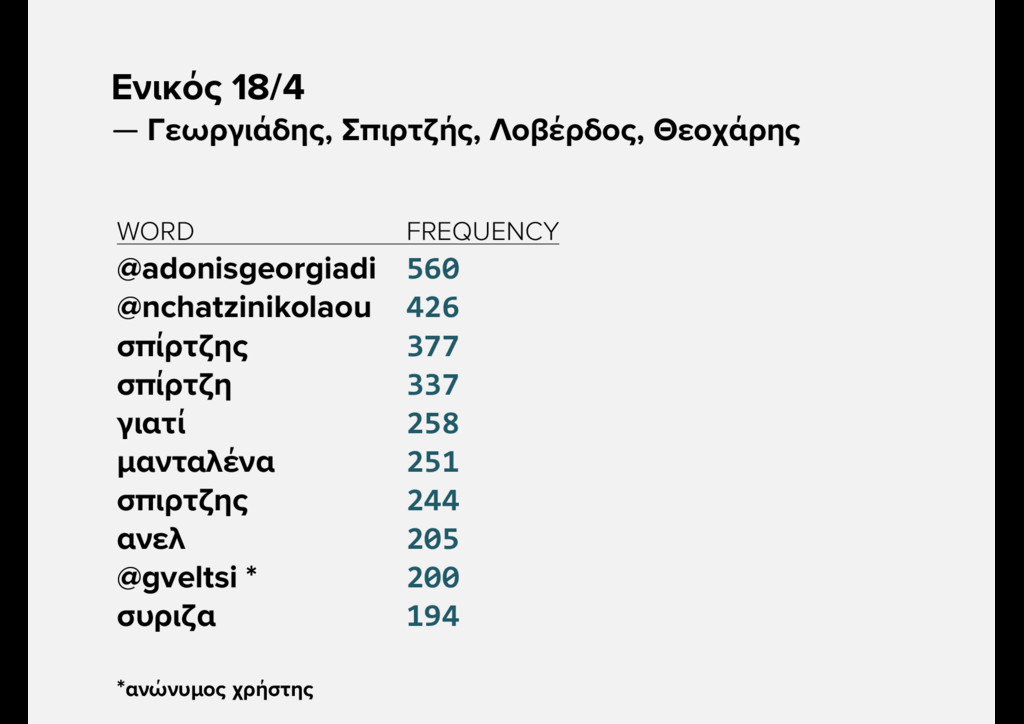{kind=link}
{kind=link}
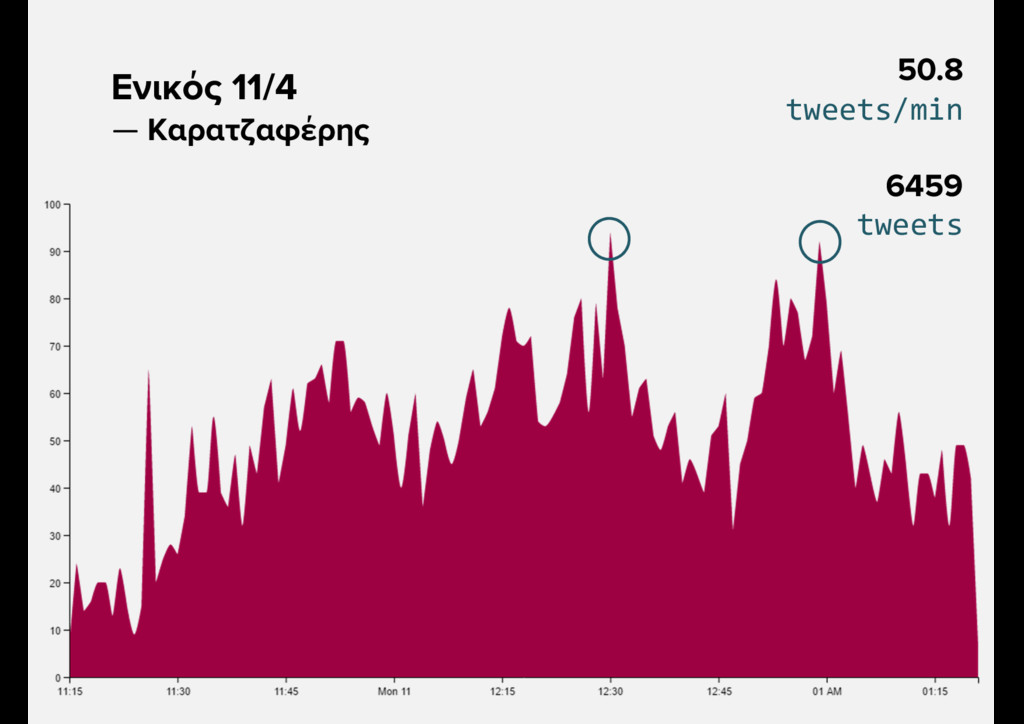{kind=link}
{kind=link}
{kind=link}
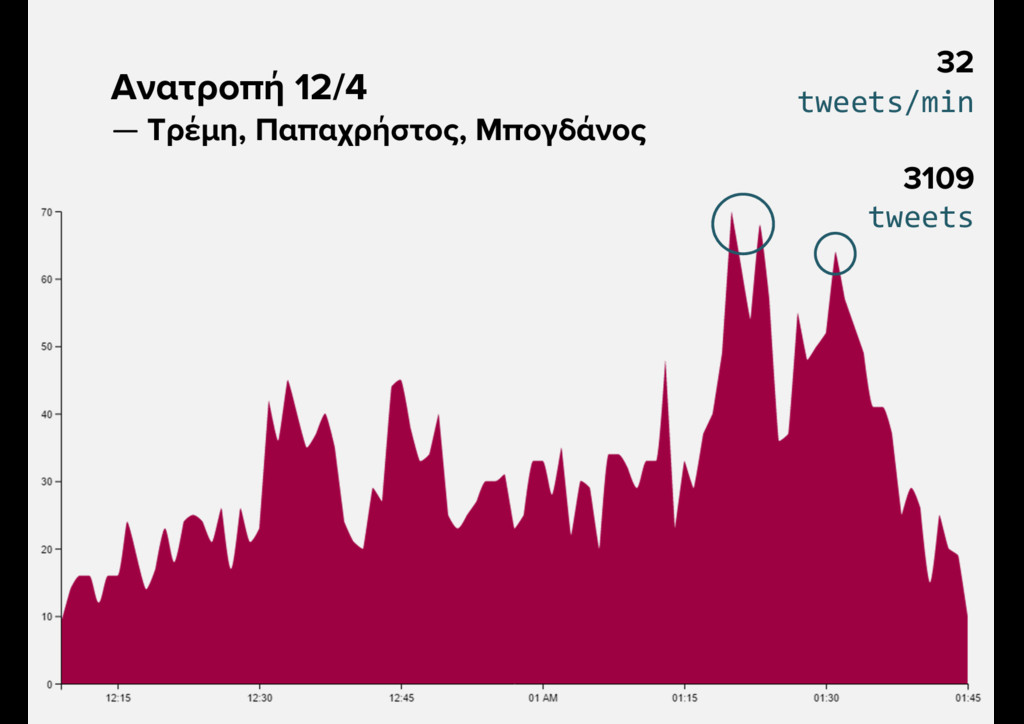{kind=link}
{kind=link}
{kind=link}
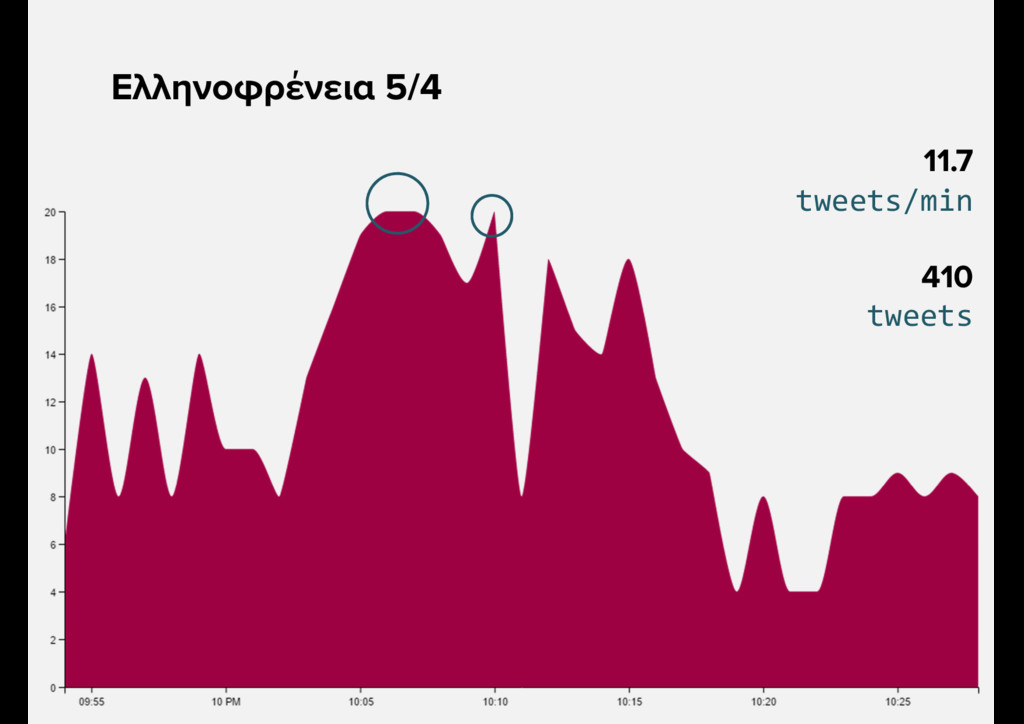{kind=link}
{kind=link}
{kind=link}