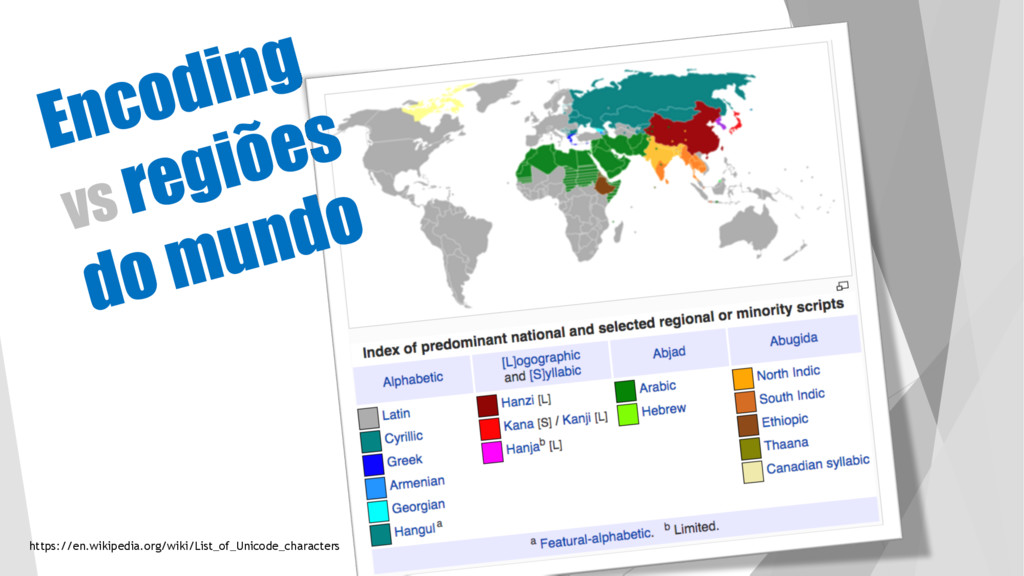
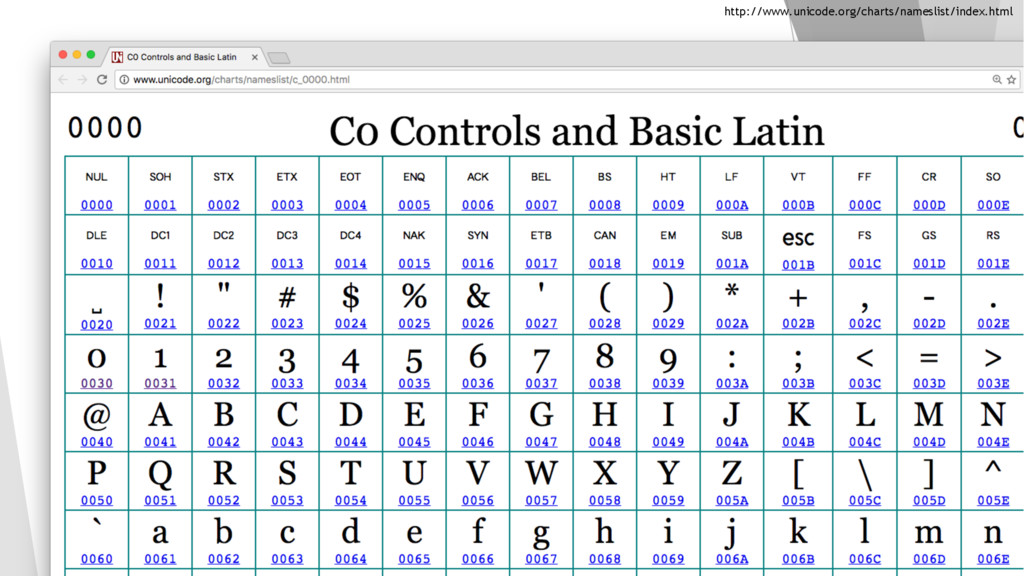
é um padrão de relacionamento entre um conjunto de caracteres com um conjunto de outra coisa, como por exemplo números ou pulsos elétricos com o objetivo de facilitar o armazenamento de texto em computadores... u …Ou uma forma de representar letras, números ou simbulos através de numeros ou outros artificios.
BITS e isso permitia que todo o alfabeto e simbolos comuns fossem representados através de códigos númericos… Estava tudo certo pra quem falava inglês. u Aí o resto do mundo passou a comprar IBM PC fora da américa e pra cada região, caracteres diferentes da lingua inglesa eram tratadas no 8º BIT u Code Pages foram criados para definir o escopo de cada lingua. Na pratica todo e qualquer abaixo de 127 era igual, mas as diferenças eram tradadas acima dele. u Linguas asiaticas precisaram mais de 1 byte para a representação de seus ideogramas ou simbolos especificos
de acordo com a região e lingua mas a danada da Microsoft criou a sua versão dos encodings para o ambiente Windows. u Isso quer dizer que encondings como LATIN1 (ISO 8859-1) e LATIN-9(ISO 8859-15) são equivalentes ao WIN1251.
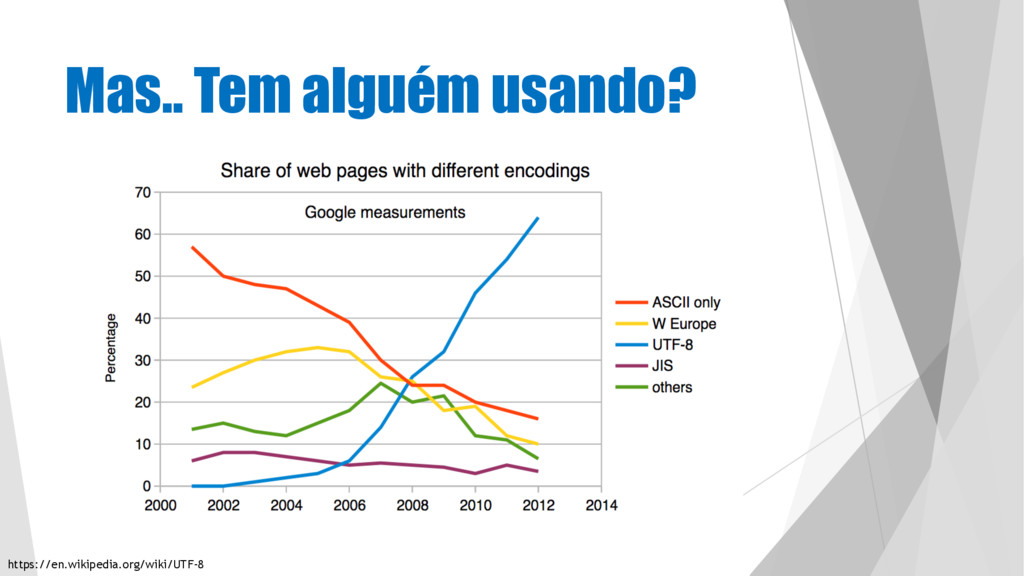
um encoding universal é muito mais fácil u Por que é um jeito fácil de não esquentar mais a cabeça com encoding u Por que você já usa e não sabe (seu SO deve estar usando). u E por que você não quer mais erros como esse na sua aplicação:
o default, é necessário fazer isso via initdb u Na criação da database. Seja no createdb: u ..Ou no CREATE DATABASE: initdb -E EUC_JP createdb -E EUC_KR -T template0 korean_db CREATE DATABASE korean_db WITH ENCODING 'EUC_KR' TEMPLATE 'template0';
como alfabetos, ordenação, formatação numerica, etc. u O PostgreSQL usa o padrão ISO C e POSIX do sistema operacional u O suporte a locales é automaticamente na inicialização do cluster (criado apartir do initdb)
SQL: u Ordem de ordenação de caracteres utilizando a clausula ORDER BY ou a comparação de operações em campos do tipo texto (text, varchar, etc). u Nas funções UPPER, LOWER e INITCAP u Operadores de comparação de padrões (LIKE, SIMILAR TO e expressões regulares POSIX) u As funções to_char u A possibilidade de utilizar indexes com o operador LIKE
utilizar regras de collate em inglês (en_US) e exibir mensagens em espanhol (es_AR). u Para permitir esse tipo de combinação de vários locales, as variaveis abaixo permitem a configuração específica: LC_COLLATE Ordenação de caracteres LC_CTYPE Classificação de caracteres (o que é uma letra? É equivalente a uma letra maiuscula?) LC_MESSAGES Linguagem para exibir as mesas do servidor LC_MONETARY Exibição de moedas LC_NUMERIC Exibição de números LC_TIME Exibição de datas e horários
de caracteres (LC_CTYPE) a nível de colunas ou por operação. u Isso facilita a sua vida por permite que você utilizar um locale diferente do criado no banco de dados. Collation
https://annevankesteren.nl/2009/09/utf-8-reasons u http://htmlpurifier.org/docs/enduser-utf8.html u http://www.postgresql.org/docs/current/static/multibyte.html
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}