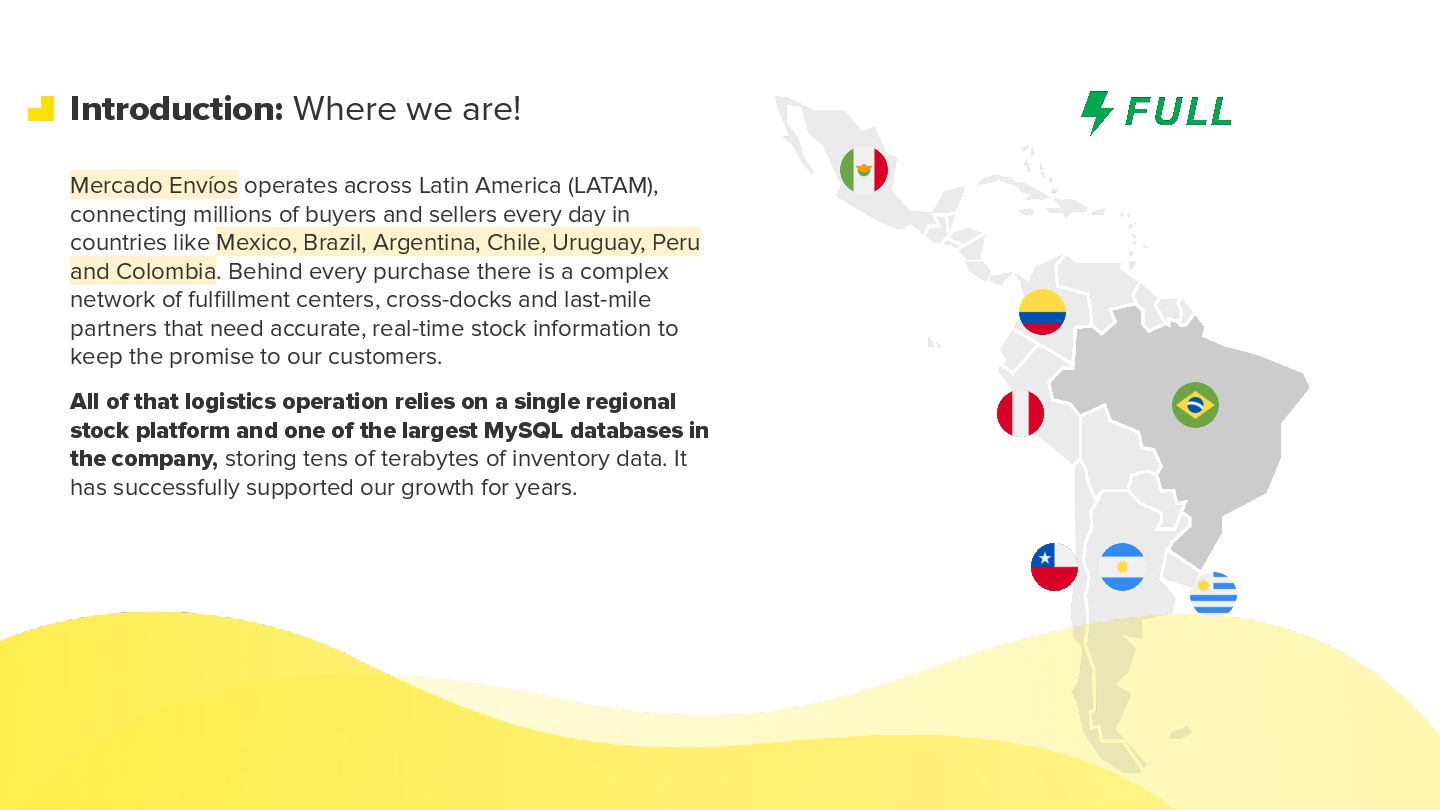
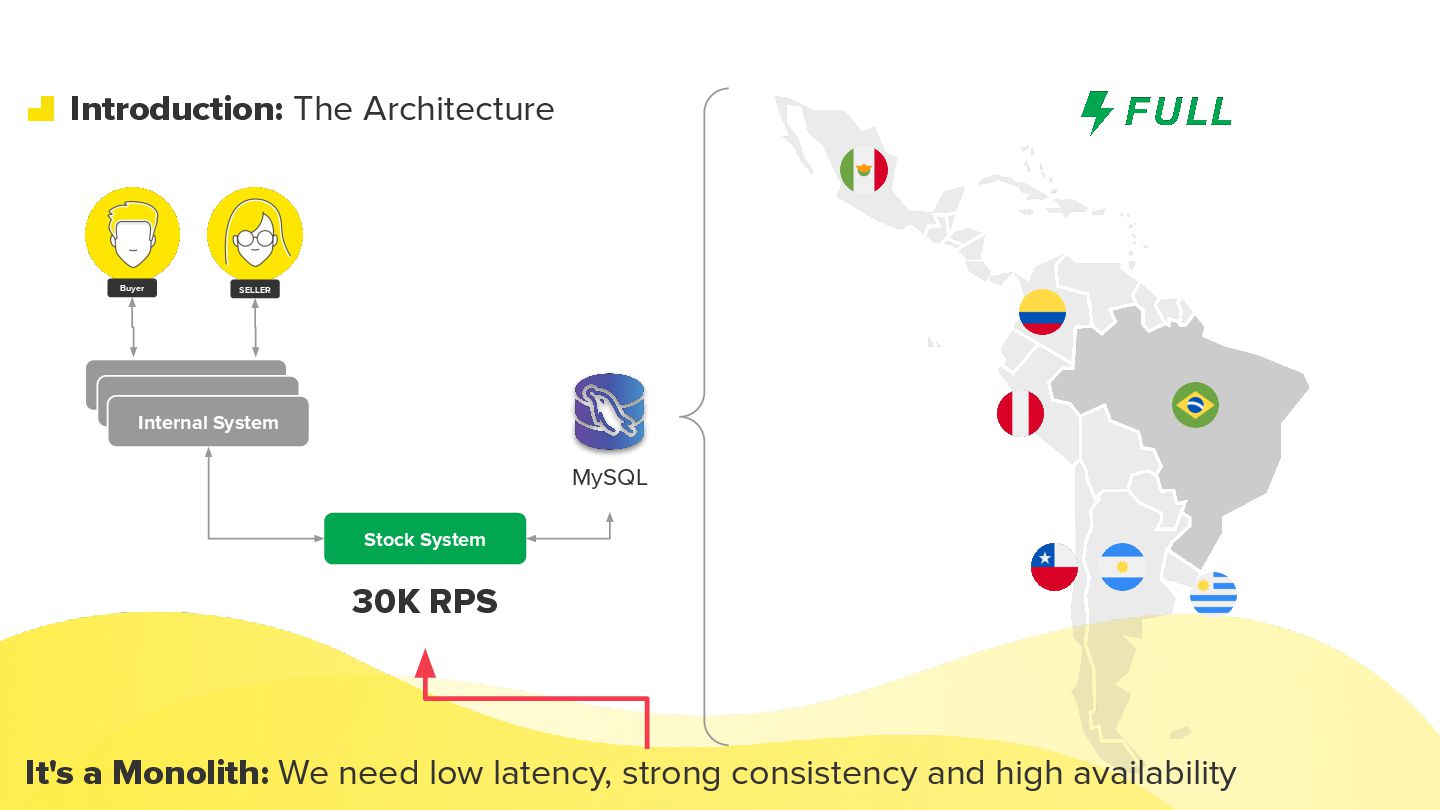
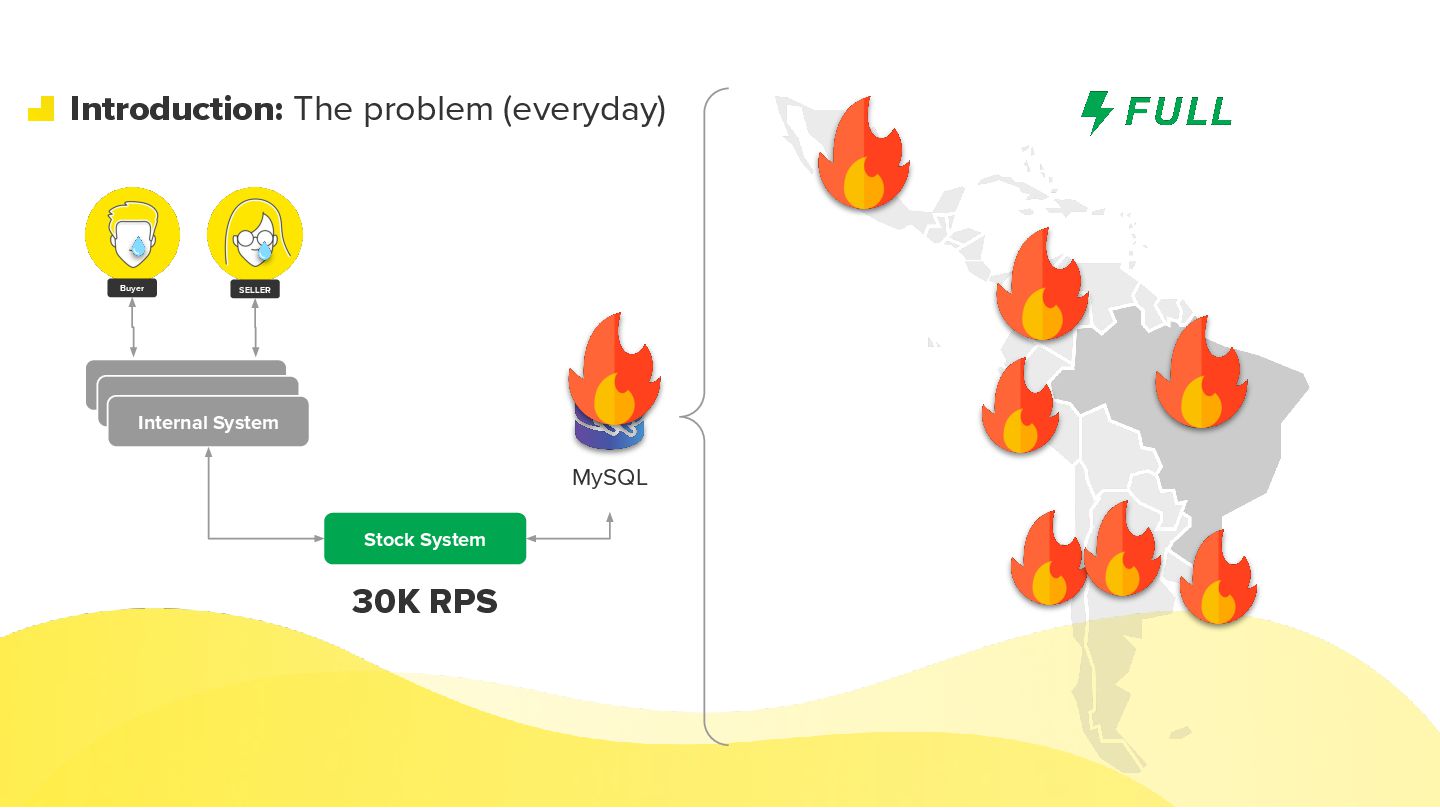
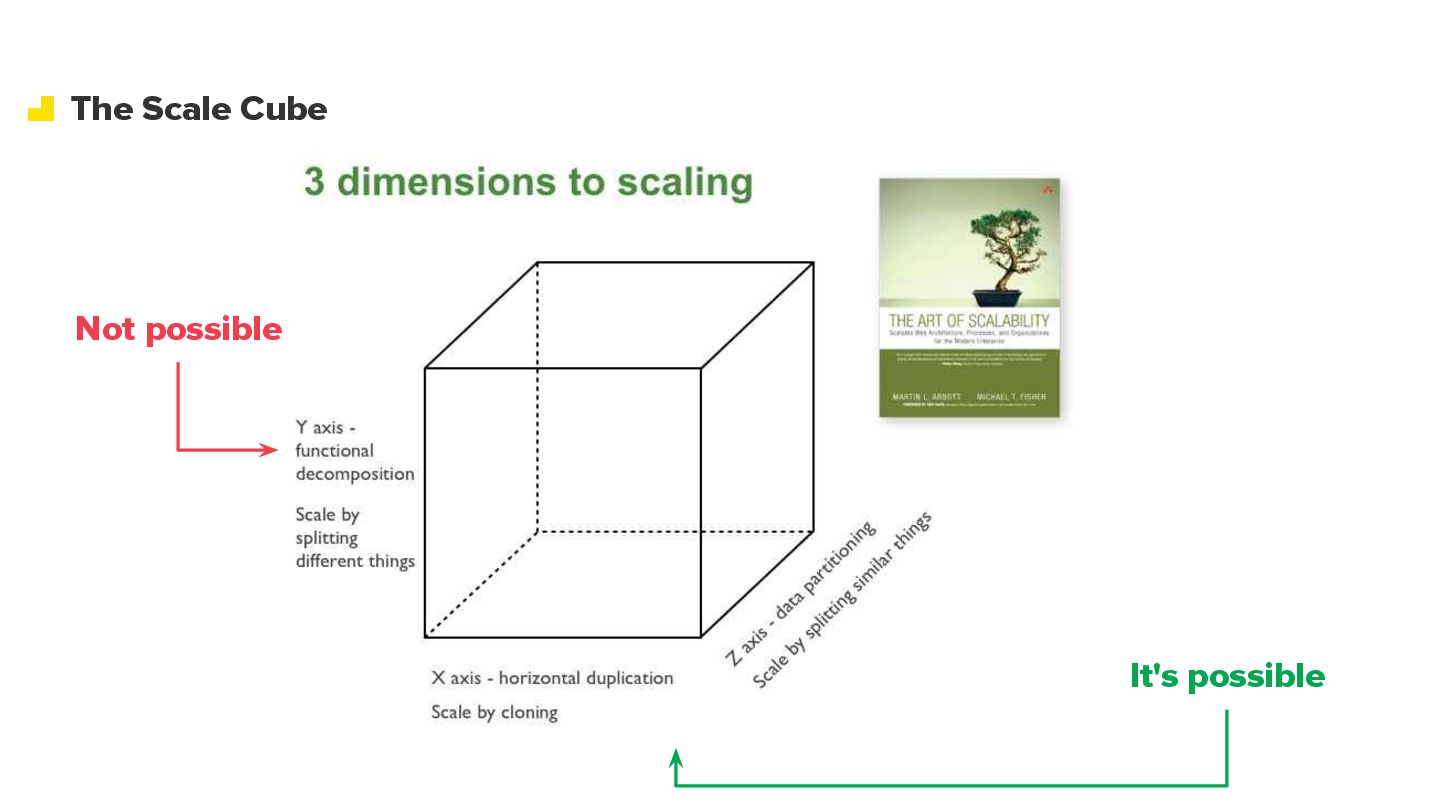
Modern commerce systems are pushed to their limits when a single failure can halt operations across an entire region. In this talk, I share how we evolved Mercado Livre’s stock system from a large MySQL-backed monolith into a cell-based architecture capable of handling more than 30K requests per second across Latin America. We’ll walk through the journey: understanding blast radius and regional impact, defining the right cell boundaries, isolating compute and data per domain, and designing routing strategies that coexist with legacy APIs during the migration. I’ll also cover the operational side: observability, incident containment, and how we approached data migration with minimal downtime. Attendees will leave with practical patterns, trade-offs, and lessons learned for applying cell-based architecture to their own large-scale, business-critical systems.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}