Денис Силаков
Старший системный архитектор, Virtuozzo
SECR 2019
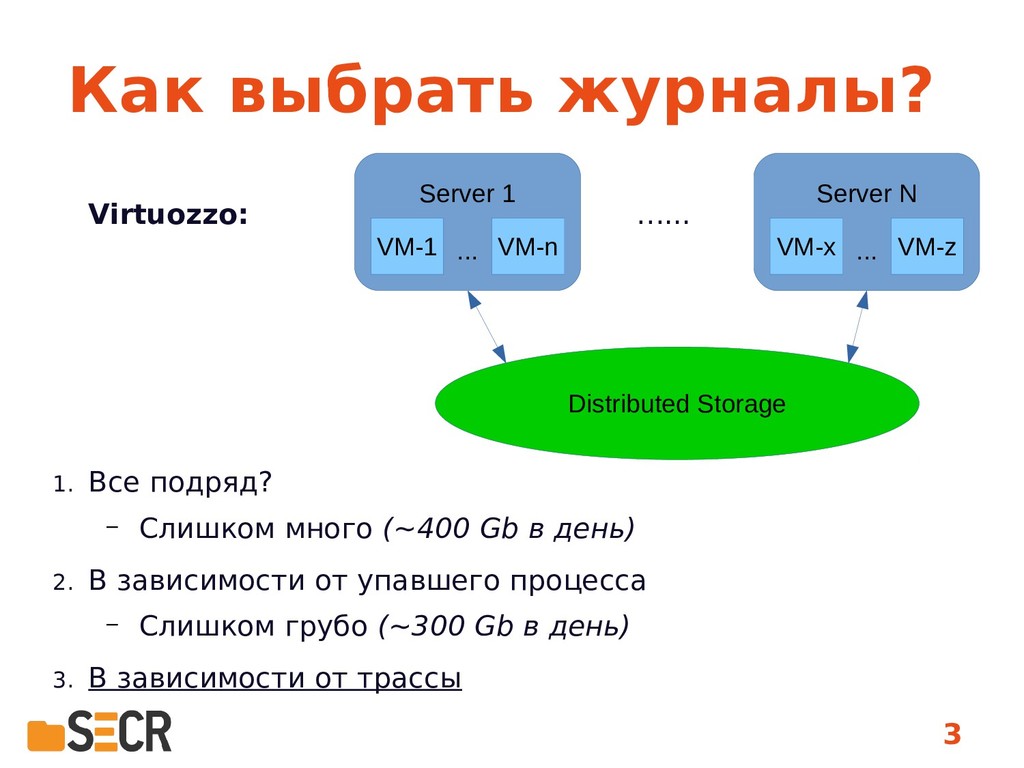
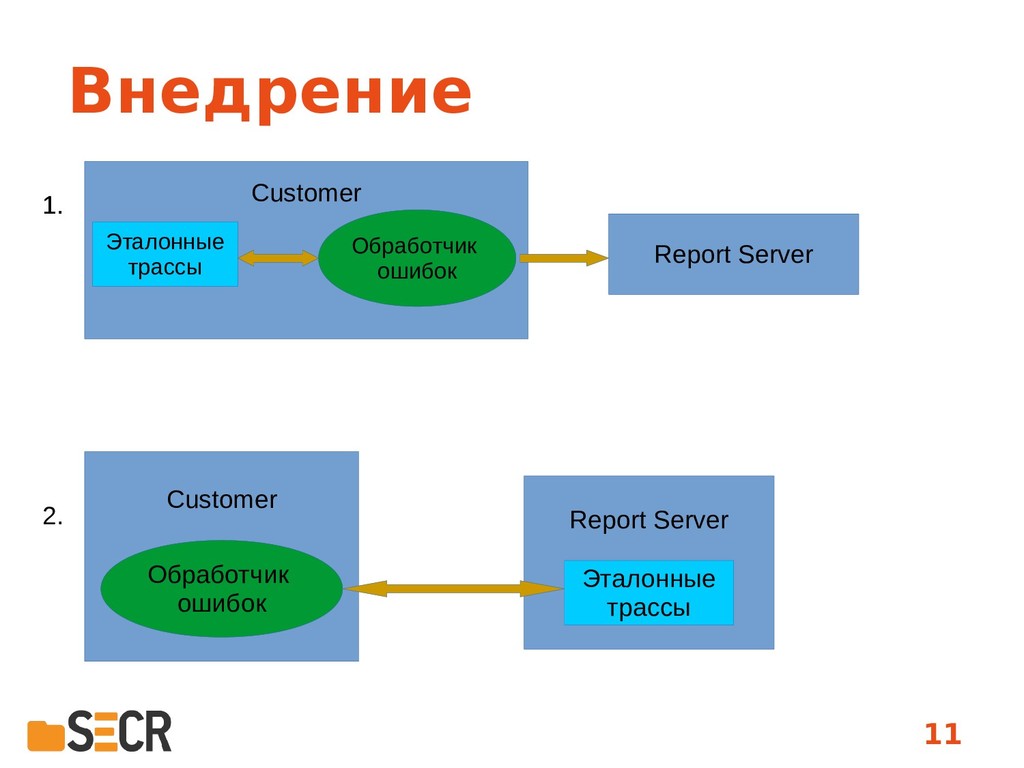
В данной работе рассматривается использование машинного обучения в целях оптимизации отчетов об ошибках и включения в них только тех журналов и файлов, которые реально понадобятся для анализа конкретной ошибки. Выбор файлов осуществляется на основе анализа схожести последовательности функций, приведших к падению, с эталонным набором. Предложенный метод прошел успешную апробацию в продуктах нашей компании и может быть полезен всем разработчикам, сталкивающимся с проблемой чрезмерного количества информации, которую хочется поместить в отчет для ошибки «на всякий случай». Доклад будет интересен как исследователям в области машинного обучения, так и инженерам, занимающихся анализом падений программ и сталкивающихся как с задачей сравнения различных падений, так и с отбором лог-файлов для их анализа.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![12 Денис Силаков Virtuozzo [email protected] Контакты](https://files.speakerdeck.com/presentations/0e64460deb214c95a2a41c19d956280d/slide_11.jpg){kind=link}