Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
MySQLやSSDとかの話 前編
Search
Sponsored
·
Ship Features Fearlessly
Turn features on and off without deploys. Used by thousands of Ruby developers.
→
Takanori Sejima
December 15, 2015
Technology
27
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
MySQLやSSDとかの話 前編
MySQLやSSDとかの話です
Takanori Sejima
December 15, 2015
More Decks by Takanori Sejima
See All by Takanori Sejima
(きっとたぶん)人材育成や教育のような何かの話
sejima
0
990
互換性のある(らしい)DBへの移行など考えるにあたってたいへんざっくり
sejima
1
3.8k
NAND Flash から InnoDB にかけての話(仮)
sejima
0
29
InnoDBのすゝめ(仮)
sejima
0
35
さいきんのMySQLに関する取り組み(仮)
sejima
0
26
sysloadや監視などの話(仮)
sejima
0
25
さいきんの InnoDB Adaptive Flushing (仮)
sejima
0
28
TIME_WAITに関する話
sejima
0
37
MySQLやSSDとかの話 その後
sejima
0
27
Other Decks in Technology
See All in Technology
Amazon Bedrock Managed Knowledge Base Dive Deep
ren8k
0
230
AI研修(Day2)【MIXI 26新卒技術研修】
mixi_engineers
PRO
2
1.4k
ソフトウェアアーキテクチャ研修【MIXI 26新卒技術研修】
mixi_engineers
PRO
2
980
最高のシステムプロンプトを作るためにフィードバック機能を導入した話
alchemy1115
0
220
SRENEXT_2026_Chairs__Talks_in_Tamachi.sre.pdf
srenext
1
170
DevOps Agentで運用判断をチーム資産にする ~Agent InstructionsとAgent Skillを継続的に育てる~
fujioka6789
0
170
Oracle Base Database Service 技術詳細
oracle4engineer
PRO
15
110k
実践が先生だった— 新卒サーバーエンジニア1年目のリアル
mixi_engineers
PRO
0
200
それでも、技術なブログを書く理由 #kichijojipm / Why I Still Write Tech Blogs Even Now
shinkufencer
0
1.2k
文字起こし基盤の信頼性
abnoumaru
0
150
データと地図で読む 大井町の「かわるもの、かわらないもの」
yoshiyama_hana
0
590
ウォーターフォール開発案件のPMとしてAI活用を模索している話
hatahata021
2
200
Featured
See All Featured
Effective software design: The role of men in debugging patriarchy in IT @ Voxxed Days AMS
baasie
0
460
Breaking role norms: Why Content Design is so much more than writing copy - Taylor Woolridge
uxyall
0
350
The Limits of Empathy - UXLibs8
cassininazir
1
560
Java REST API Framework Comparison - PWX 2021
mraible
34
9.6k
Digital Projects Gone Horribly Wrong (And the UX Pros Who Still Save the Day) - Dean Schuster
uxyall
1
2.1k
The State of eCommerce SEO: How to Win in Today's Products SERPs - #SEOweek
aleyda
2
11k
HDC tutorial
michielstock
2
760
16th Malabo Montpellier Forum Presentation
akademiya2063
PRO
0
300
実際に使うSQLの書き方 徹底解説 / pgcon21j-tutorial
soudai
PRO
201
75k
Crafting Experiences
bethany
1
230
Music & Morning Musume
bryan
47
7.3k
We Have a Design System, Now What?
morganepeng
55
8.2k
Transcript
Copyright © GREE, Inc. All Rights Reserved. MySQLやSSDとかの話 前編 Takanori
Sejima
Copyright © GREE, Inc. All Rights Reserved. 自己紹介 • わりとMySQLのひと
• 3.23.58 から使ってる • むかしは Resource Monitoring も力入れてやってた • ganglia & rrdcached の(たぶん)ヘビーユーザ • 5年くらい前から使い始めた • gmond は素のまま使ってる • gmetad は欲しい機能がなかったので patch 書いた • webfrontend はほぼ書き直した • あとはひたすら python module 書いた • ganglia じゃなくても良かったんだけど、とにかく rrdcached を使いたかった • というわけで、自分は Monitoring を大事にする • 一時期は Flare という OSS の bugfix などもやってた
Copyright © GREE, Inc. All Rights Reserved. • 古いサーバを、新しくて性能の良いサーバに置き換えていく際、いろいろ工 夫して集約していっているのですが
• そのあたりの背景や取り組みなどについて、本日はお話しようと思います • オンプレミス環境の話になっちゃうんですが • 一部は、オンプレミス環境じゃなくても応用が効くと思います • あと、いろいろ変なことやってますが、わたしはだいたい考えただけで • 実働部隊は優秀な若者たちがいて、細かいところは彼らががんばってくれ てます 本日のお話
Copyright © GREE, Inc. All Rights Reserved. • 最近の HW
や InnoDB の I/O 周りについて考えつつ、取り組んでおり まして • さいきん、そのあたりを資料にまとめて slideshare で公開しております • 後日、あわせて読んでいただけると、よりわかりやすいかと思います • 参考: • 5.6以前の InnoDB Flushing • CPUに関する話 • EthernetやCPUなどの話 本日のお話の補足資料
Copyright © GREE, Inc. All Rights Reserved. では はじめます
Copyright © GREE, Inc. All Rights Reserved. • GREEのサービスは歴史が古い •
古いサービスはコードが密結合な部分がある • むかしから動いてるMySQLのサーバは、かなり sharding されていた • 2000年代、GREEは SAS HDD 146GB 15krpm * 4本使ったRAID10の前提で、 データベースを設計してるところが多かった • そういうストレージでも動くように、データベースのサイズは 100-200GB以下のものが多 かった • わたしが入社した2010年のころはよくサービスささっていて、各エンジニア が協力して改善してた • アプリケーションレイヤーでがんばってもらったり、力の限り sharding したり • わたしは、 ganglia で問題切り分けて、チューニングなどに力いれた 背景
Copyright © GREE, Inc. All Rights Reserved. • わたしが入社する前からノウハウがあって、ガンガンshardingして master切り替えてたそうで
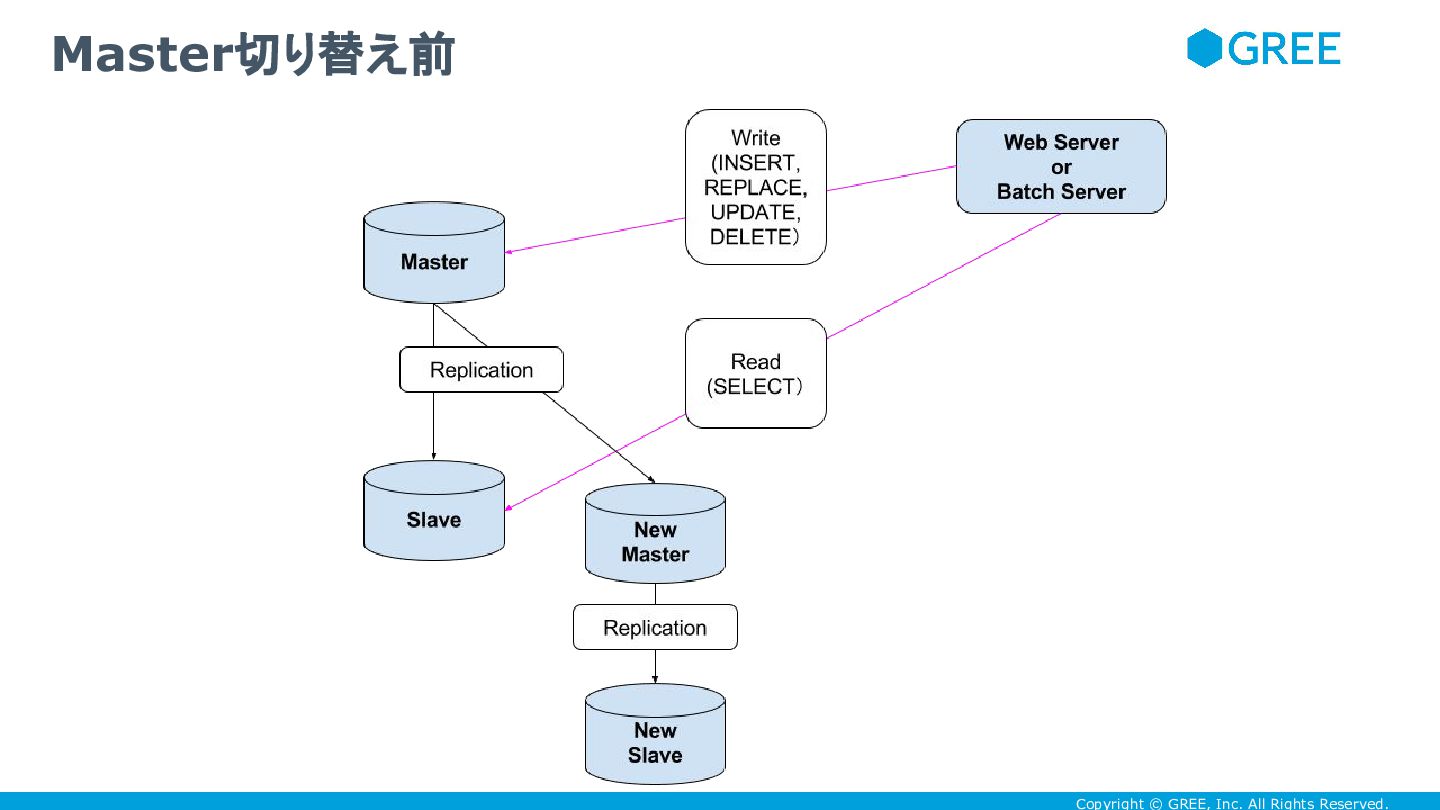
• 具体的には次のように • 先ずはサービス無停止で master 切換する方法から説明します どんなふうに sharding していたかというと
Copyright © GREE, Inc. All Rights Reserved. Master切り替え前
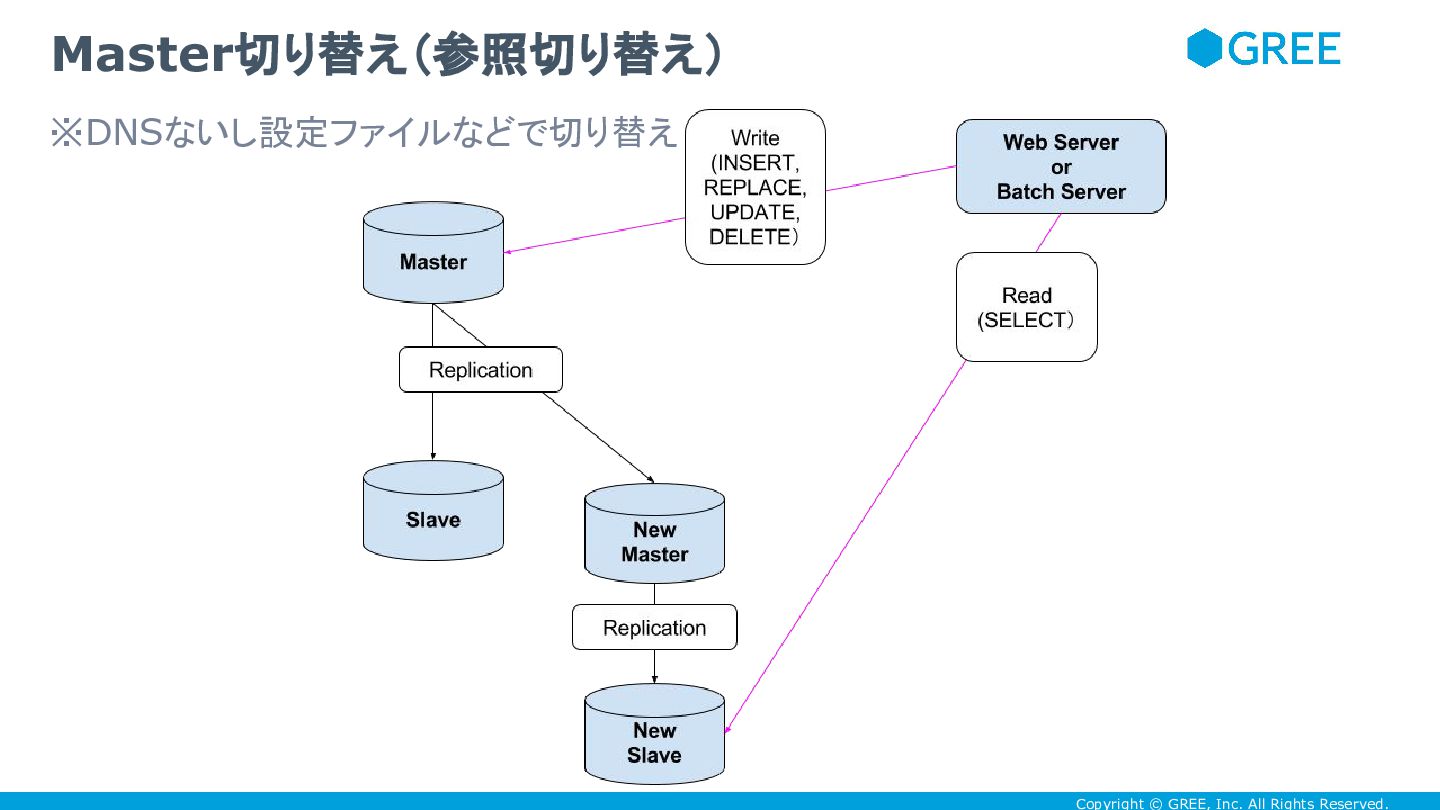
Copyright © GREE, Inc. All Rights Reserved. Master切り替え(参照切り替え) ※DNSないし設定ファイルなどで切り替え
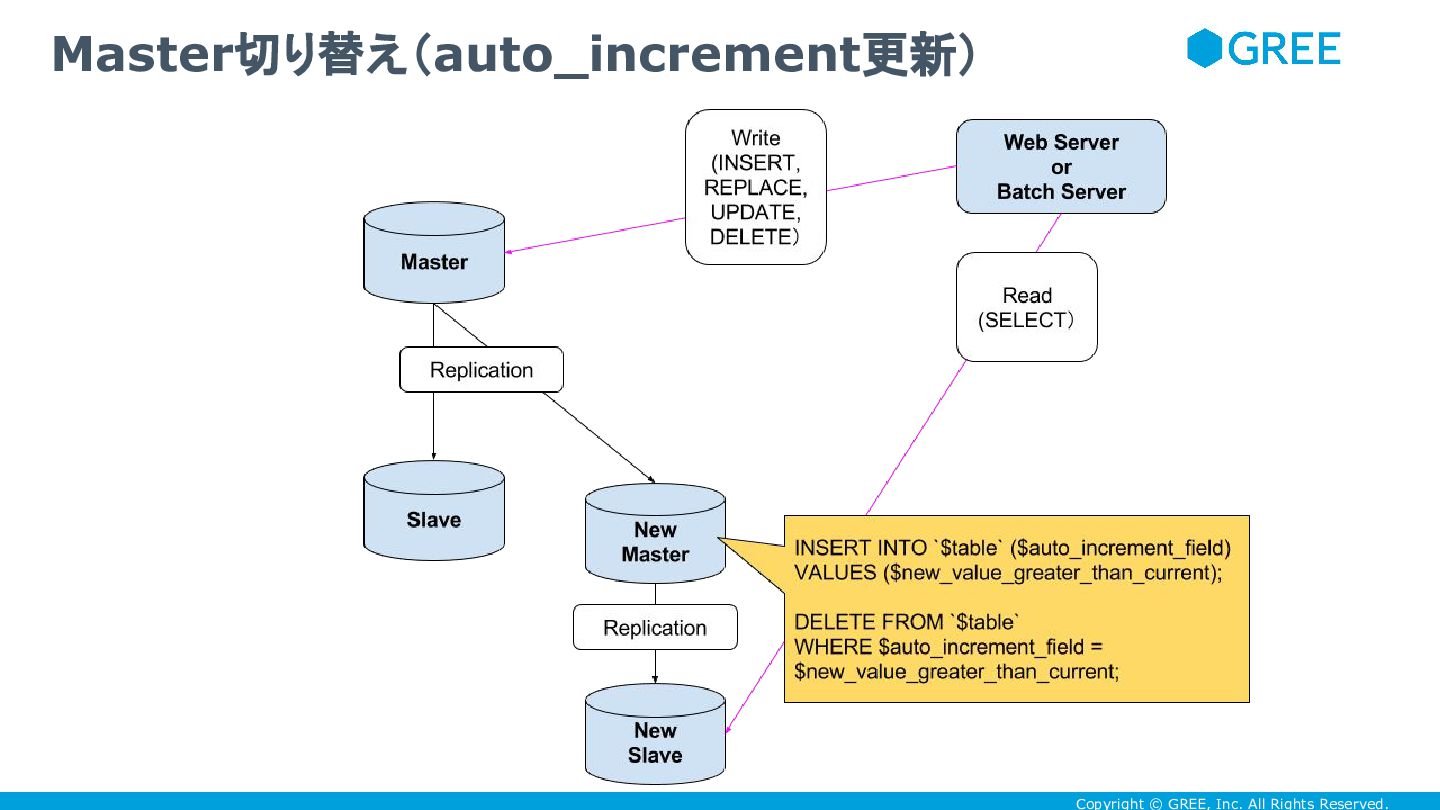
Copyright © GREE, Inc. All Rights Reserved. Master切り替え(auto_increment更新)
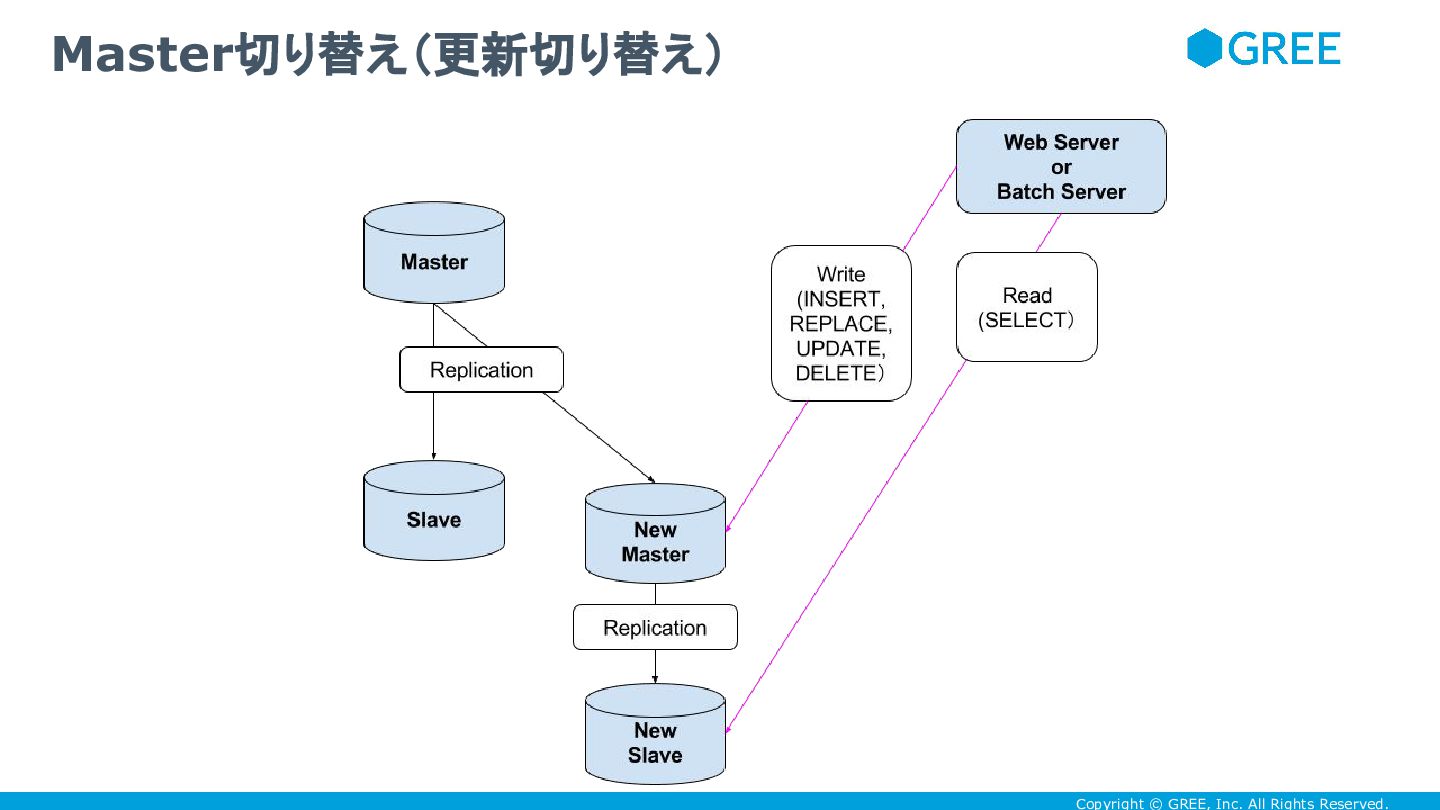
Copyright © GREE, Inc. All Rights Reserved. Master切り替え(更新切り替え)
Copyright © GREE, Inc. All Rights Reserved. • masterを切り替えた後に、古いmasterに対してINSERTが実行されたと きのための対策
• 例えば、次のような状態になっていれば、auto_increment の値は duplicate しない • 旧master にINSERTすると、auto_increment のカラムは101以降の値を発番する • 新master にINSERTすると、auto_increment のカラムは131以降の値を発番する • 新masterには、master切り替えが完了するまでの間、 auto_incrementの値がduplicateしない程度の値を、 INSERT&DELETEし、 auto_increment の値を更新しておく • master切り替えの間、更新を完全にブロックできるなら、やらなくてもいい auto_increment更新する理由
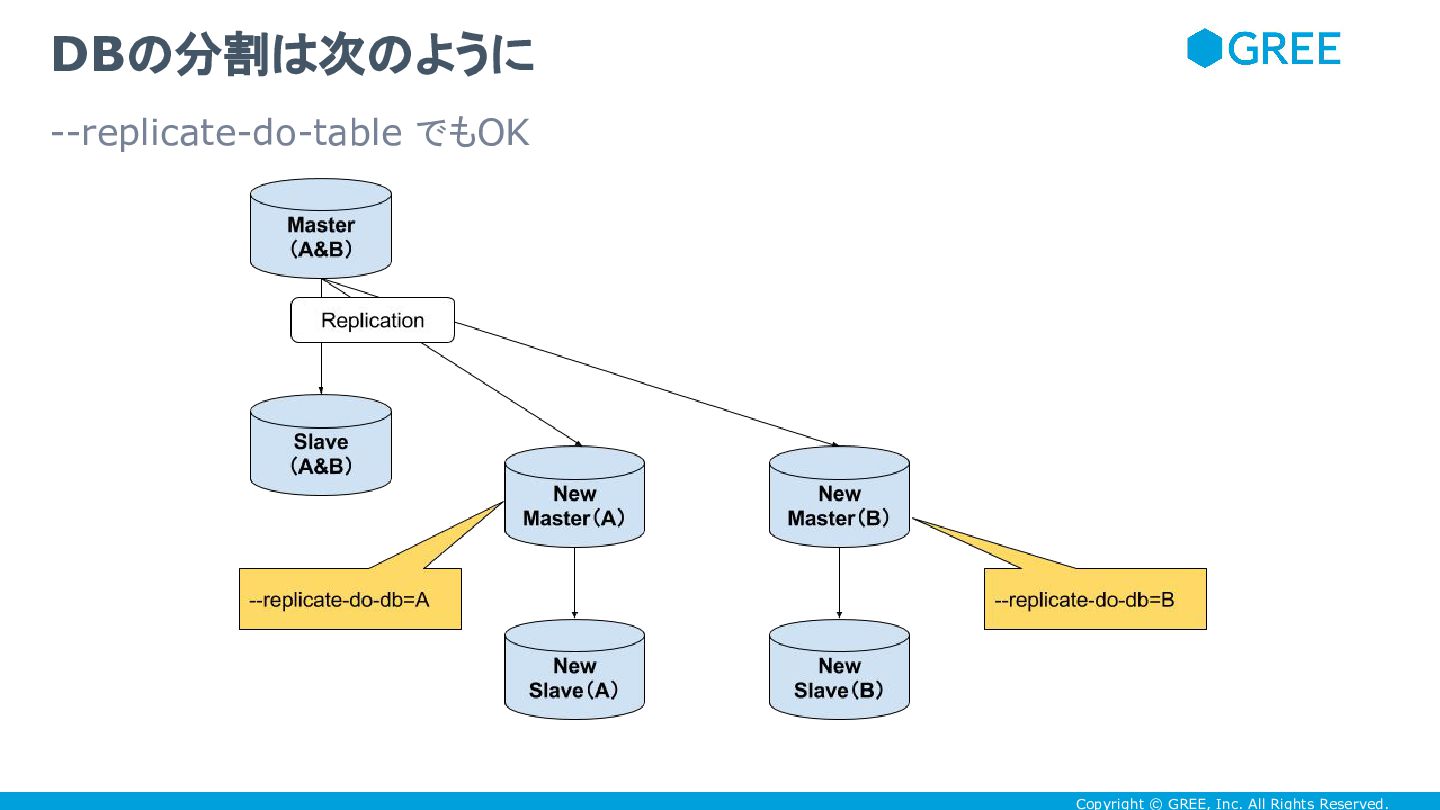
Copyright © GREE, Inc. All Rights Reserved. DBの分割は次のように --replicate-do-table でもOK
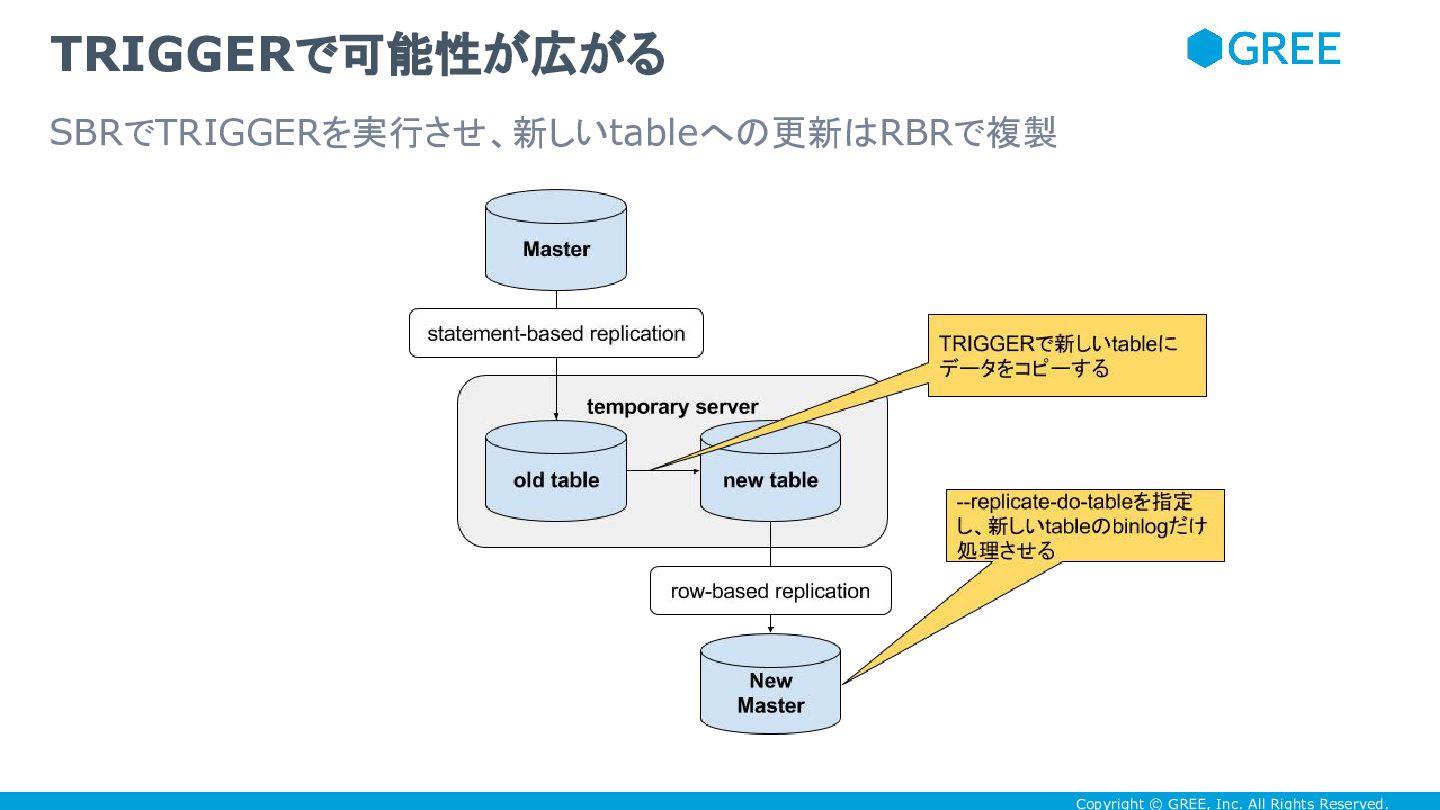
Copyright © GREE, Inc. All Rights Reserved. TRIGGERで可能性が広がる SBRでTRIGGERを実行させ、新しいtableへの更新はRBRで複製
Copyright © GREE, Inc. All Rights Reserved. • database や
table を最初からある程度分割しておいたほうが、 -- replicate-do-db や --replicate-do-table で簡単に分割できるけど • TRIGGER 使って table を分割することもできる • binlog_format=’STATEMENT’ だと、 TRIGGER によって発生した bi は binary log に落ちないけど、 binlog_format=’ROW’ だと binary log に落ち る。それらを組み合わせることによって、 TRIGGER によって更新された table だけ replication することが可能 • サービス無停止で column の追加や削除などにも対応できるので、 statement-based replication (& --log-slave-updates)& TRIGGER の組み合わせは、切り札として有用 sharding は後からでもできる
Copyright © GREE, Inc. All Rights Reserved. • サーバを並べることによって、むかしより安定稼働するようにはなったんだ けど
• SSDを導入して活用したいという機運があった • 個人的には、MySQLのボトルネックを、 CPU とメモリの問題にできるようにしていきたい 気持ちがあった。ストレージ速くなったし、 Xeon は Core の数増え続けてたし、MySQL はバージョン上がるごとに、CPUスケーラビリティを改善し続けていたので。 そんな感じで、サービスとしては改善したんだけど
Copyright © GREE, Inc. All Rights Reserved. • 「MySQLのバージョンが上がってN倍性能が良くなった」というのは •
(ほとんどの場合)MySQLがたくさんのCPUを活用できるようになって、ス ループットが改善していってるという話だと • InnoDB Adaptive Flushing などの改善もありますけどね • MySQL5.5あたりから強く意識するようになった • それまでは、とにかくHDDが圧倒的に遅かったけど • SSDの登場により、CPUとメモリがボトルネックになるケースを、強く意識し 始めた 強く意識したのは、 MySQL5.5 あたりから
Copyright © GREE, Inc. All Rights Reserved. • Fusion-IO 流行し始めたころ、調達できたのは
ioDrive MLC 320GB • 先ずは KVS に投入したり、 sharding が困難だったDBに投入したけど • ほとんどのDBはHDDでも動くように sharding したり、アプリケーション 工夫したりしていたから、 320GB という容量は使いドコロが難しかった • また、当時はHDDのサーバが大量にあったので、 ioDrive に依存した設 計にしてしまうと、今後どれだけリプレースすればいいの、という恐れもあっ た • 他社のワークロードとGREEのワークロード違うから、他社の事例は参考 にしにくかった 先ずは ioDrive 導入した
Copyright © GREE, Inc. All Rights Reserved. • 当時、GREEで使ってたHDDのサーバと比較して、 ioDrive
のサーバは コスト的に三倍くらいだったので、三倍以上の成果を挙げさせたいという前 提のもと • 他のサーバの三倍以上のqueryを受けさせるために • GREEのDBサーバに求められる要件を分析し、考えていった 三倍の仕事をさせるために
Copyright © GREE, Inc. All Rights Reserved. そして ひらめいた
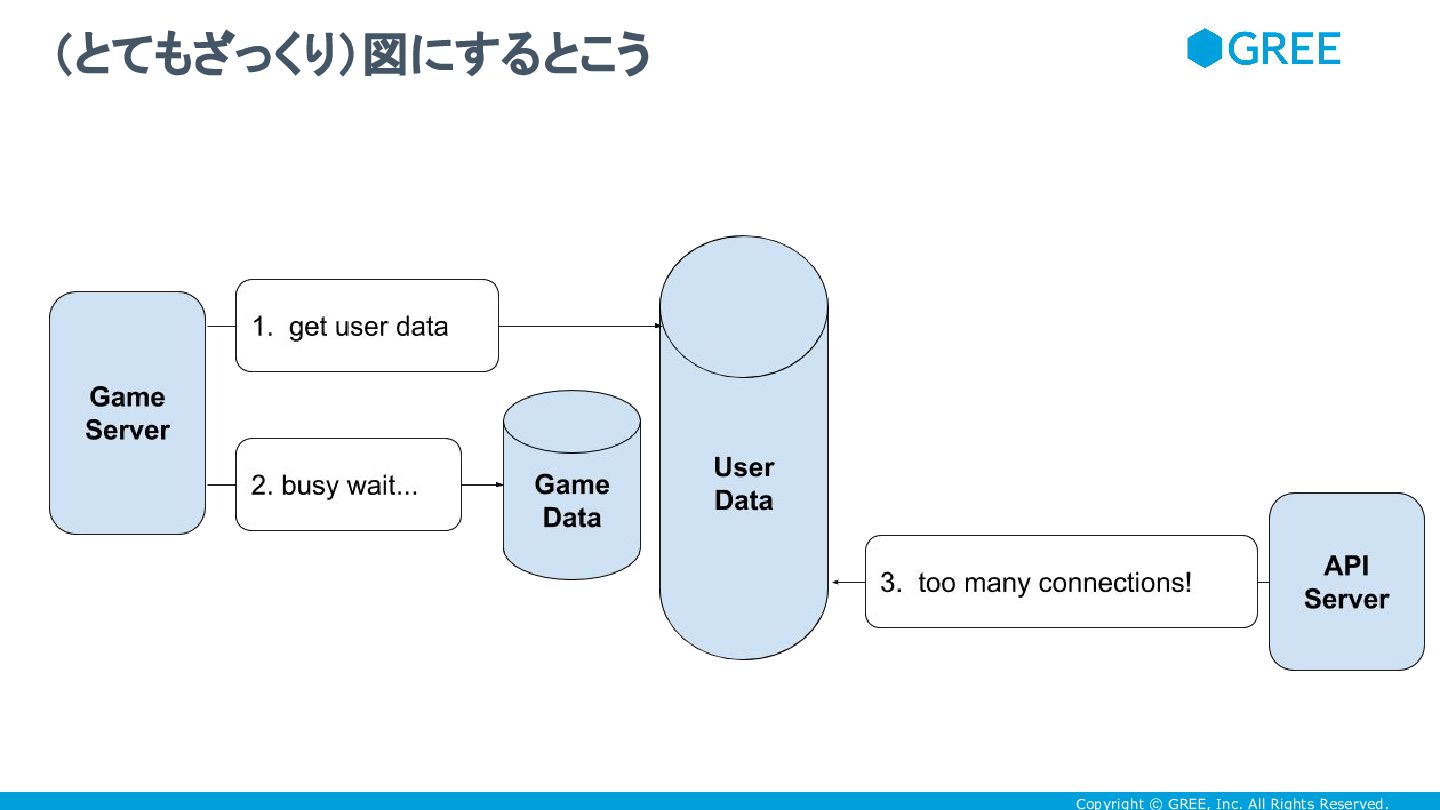
Copyright © GREE, Inc. All Rights Reserved. • GREEのアプリケーションサーバはコネクションプーリングをしておらず、リ クエストが来るごとにコネクションを張り、レスポンスを返すごとにコネクショ
ン切っていて • これは当時そこまで珍しくない実装だと思うけど • 不幸なことに、共通系のDBなるものが存在して • 特定のサービスでDBがささると、共通系のDBへのコネクションが溜まって いって、 too many connections が発生し • 他のサービスが巻き込まれてしまうという負の連鎖 密結合ゆえの問題を軽減しよう
Copyright © GREE, Inc. All Rights Reserved. (とてもざっくり)図にするとこう
Copyright © GREE, Inc. All Rights Reserved. • too many
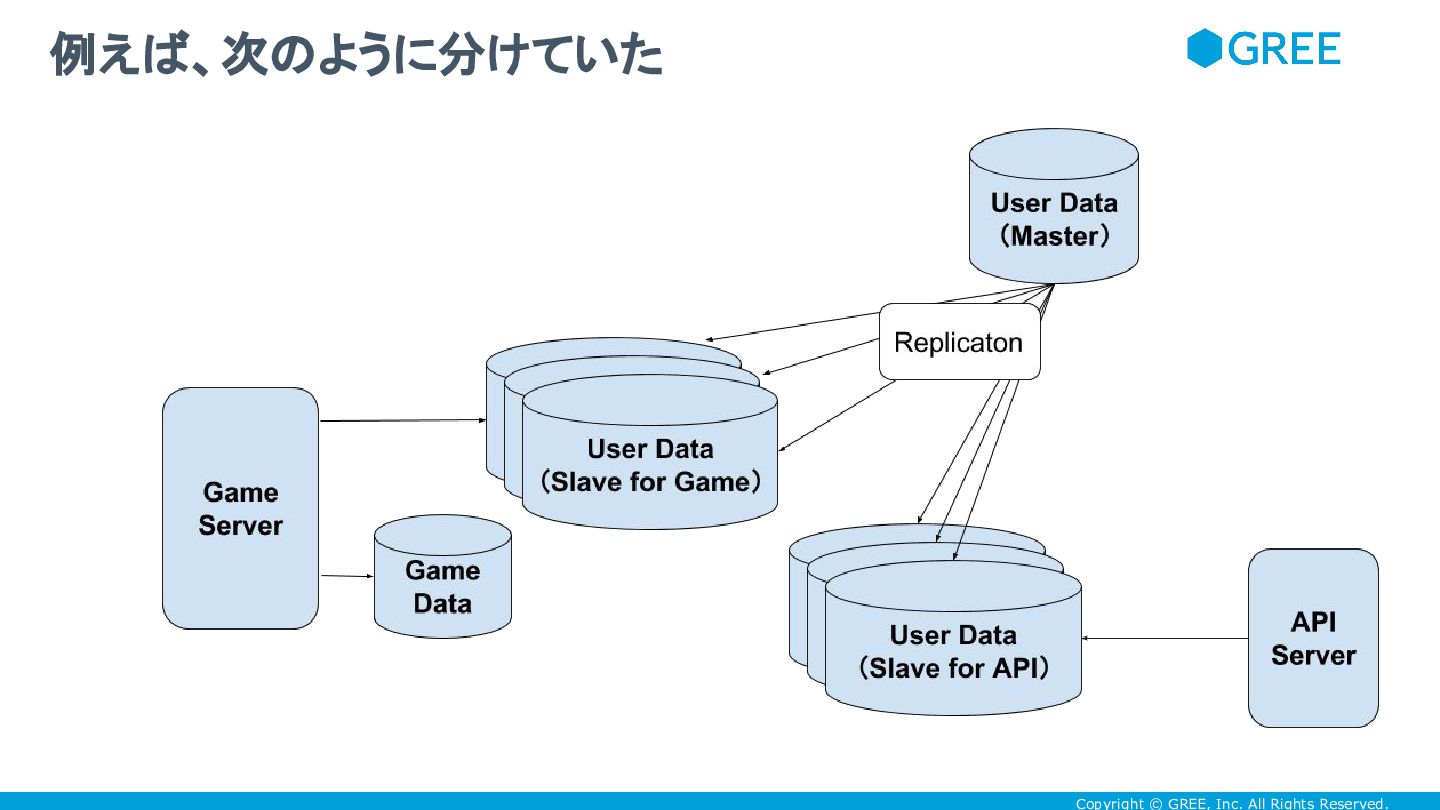
connections を避けるため、HDDのサーバをたくさん並べ て、たくさんの connection 受けられるようにするとか • 重要なサービスと内製ゲームで、slaveのクラスタを分けるとかして • 数の暴力で解決してたんだけど かつては富豪的に解決してた
Copyright © GREE, Inc. All Rights Reserved. 例えば、次のように分けていた
Copyright © GREE, Inc. All Rights Reserved. この状況を ioDriveの低latencyで なんとかする
Copyright © GREE, Inc. All Rights Reserved. • ioDrive や一般的な
PCI-e SSD は、 latency が異常によい • これは現代においても言える、オンプレミス環境のメリット • ストレージというより、「ちょっと遅いメモリ」と考える • ちょっと遅いメモリなので、 buffer pool のヒット率を少し下げても大丈夫 • ピークタイムに、ユーザのデータの大半がヒットするなら、性能あまり変わらない • buffer pool の割当を意図的に減らして、そのぶん max_connections を増やす。具体的にはHDDのサーバの三倍以上に上げる • (高価だから)それほど多くないDRAM、 latency のすぐれた ioDrive と いう組み合わせで、HDDのサーバの三倍以上のqueryを受けさせて、 MySQLのCPU利用率引き上げる buffer pool のヒット率をうまく下げる
Copyright © GREE, Inc. All Rights Reserved. • slave は
O_DIRECT 使えばメモリあけられるけど • master は binlog が page cache に乗り続けてしまう • そこで、 buffer pool の割当減らしてる master では、 cron で posix_fadvise(2) たたいて、古い binlog は page cache からちょっ とずつ落とすようにしてます。 • (言語はなんでもいいんですけど) いまのところ ruby で IO#advise つ かって :dontneed 叩いてます。 ちょっと一工夫
Copyright © GREE, Inc. All Rights Reserved. • ioDriveのサーバ1台と、HDDのサーバ三台程度を等価交換できるように した
• どうしても I/O の性能が必要になった場合、 ioDrive のサーバを、大量 にある HDD のサーバ三台で置き換えることによって確保できるように • むかしからあるHDDなサーバの在庫も活用できるように • これで、 ioDrive のサーバの稼働台数を増やすことが可能になった • ioDrive たくさん使うことによって、どんなふうに故障するのかがわかって きた • ハードウェアは故障するまで使わないと、次のステージに踏み込めない HDDのサーバとの互換性
Copyright © GREE, Inc. All Rights Reserved. よし、壊したから、 次のことを考えよう
Copyright © GREE, Inc. All Rights Reserved. • 時は流れ、NAND Flash
の価格が下がり、大容量化が進んでいった • 800GB以上のエンタープライズ仕様のSSDが普通に買えるようになった • これは使いたい • 当時、容量大きいSSD使ってる他社事例それほど多くは聞かなかったので、使ってやり たい • いまは珍しく無いと思いますけど • 他社が活用できてないものを活用することによって、サービスの競争力を向上させる • かつて、masterはHDD、slaveは一台の物理サーバに複数mysqld起 動してSSDで集約するという他社事例あったけど、それだと運用の手間が 増えるし、 Monitoring が難しくなるなと思った NAND Flash の価格が下がってきた
Copyright © GREE, Inc. All Rights Reserved. • 高い random
I/O 性能というのもあるけれど • HDDと比べて消費電力が低く、熱にも強い • 消費電力が少ないので、それだけ一つのラックにたくさんのサーバ積める ようになるし • TurboBoost 使って clock あげて、CPUぶん回してやることもやりやすく なる • かつてHDDのために使っていた電力を、より多くのCPUのために使う • ラック単位で電力を考えたとき、ストレージよりもCPUに多くの電力を回す ようにする そもそも、NAND Flash は何がうれしいか
Copyright © GREE, Inc. All Rights Reserved. • GREEは力の限り sharding
してしまっている • SSDにリプレースしなくても動かせるDBが大量にある • 100-200GB程度しかないDBでは、800GBのSSDは無用の長物ではな かろうか? だがしかし
Copyright © GREE, Inc. All Rights Reserved. こんなことも あろうかと
Copyright © GREE, Inc. All Rights Reserved. ずいぶん 前から
Copyright © GREE, Inc. All Rights Reserved. 考えていたこと があった
Copyright © GREE, Inc. All Rights Reserved. そうだ
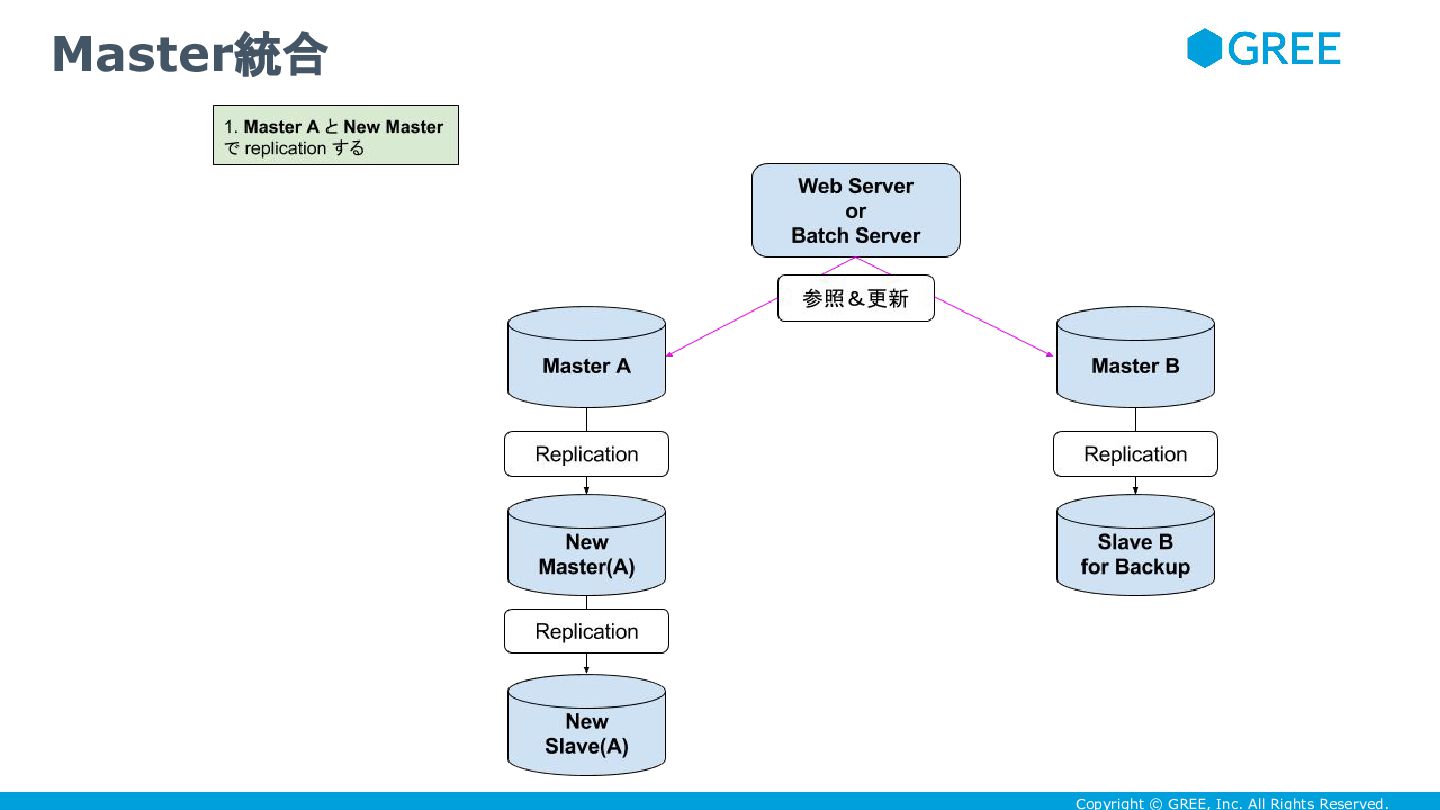
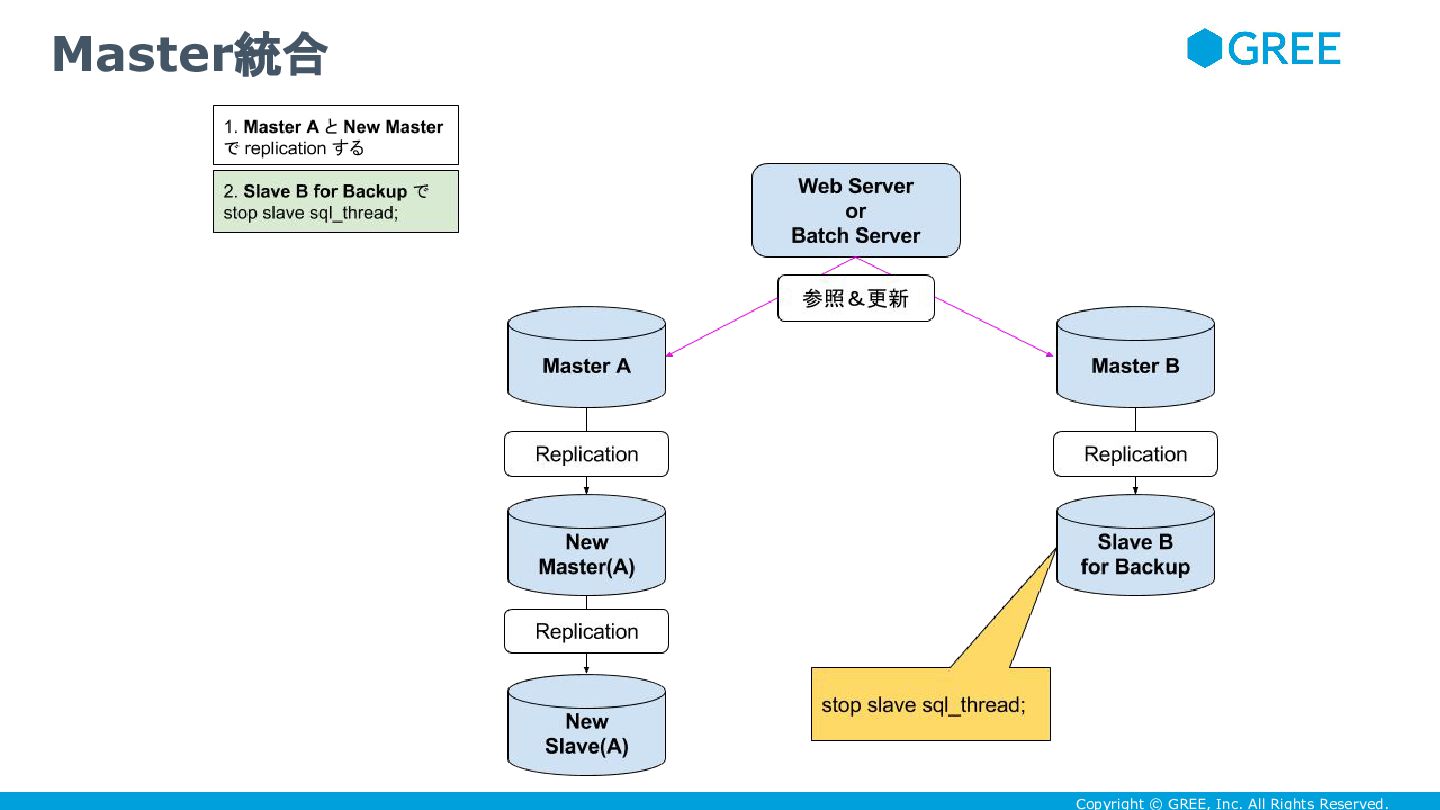
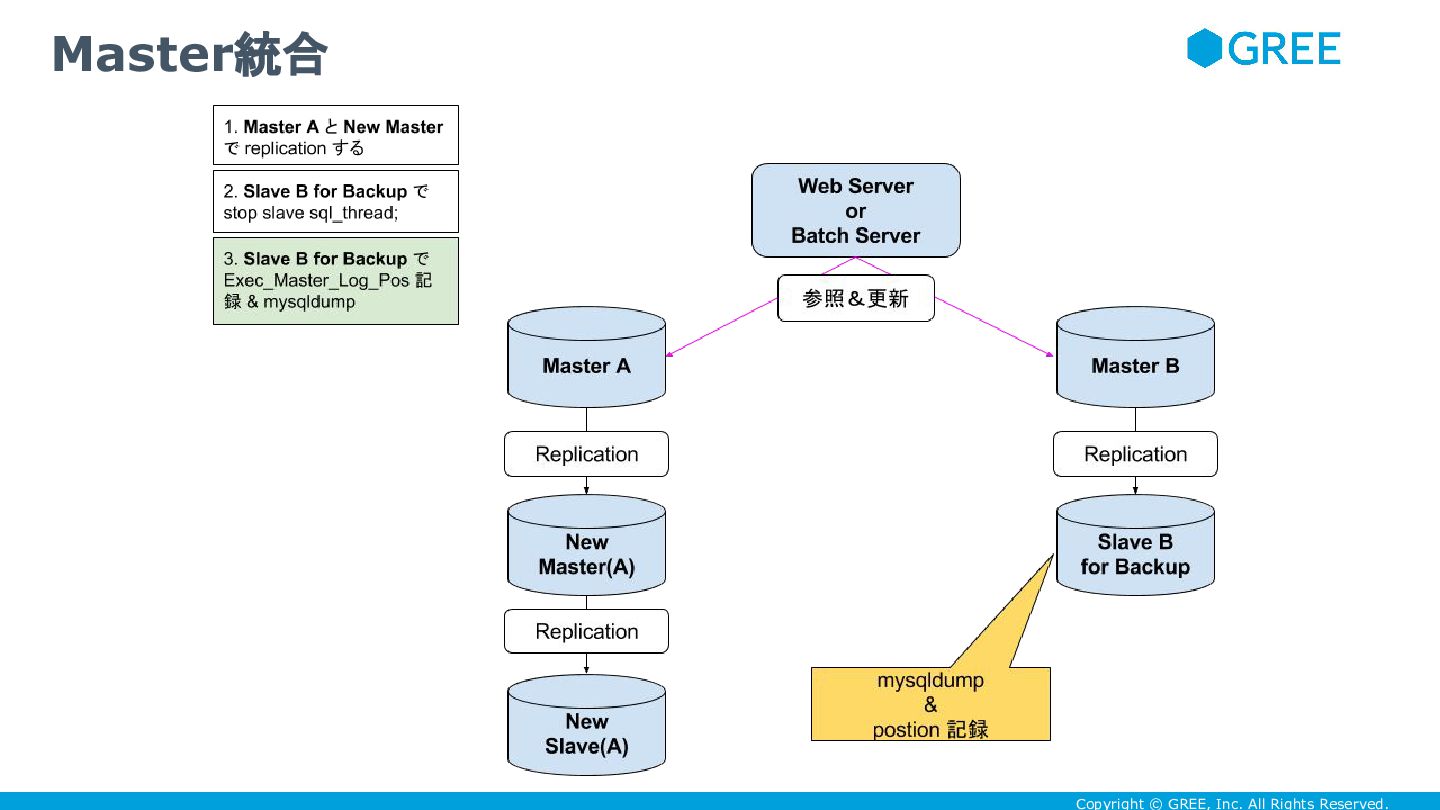
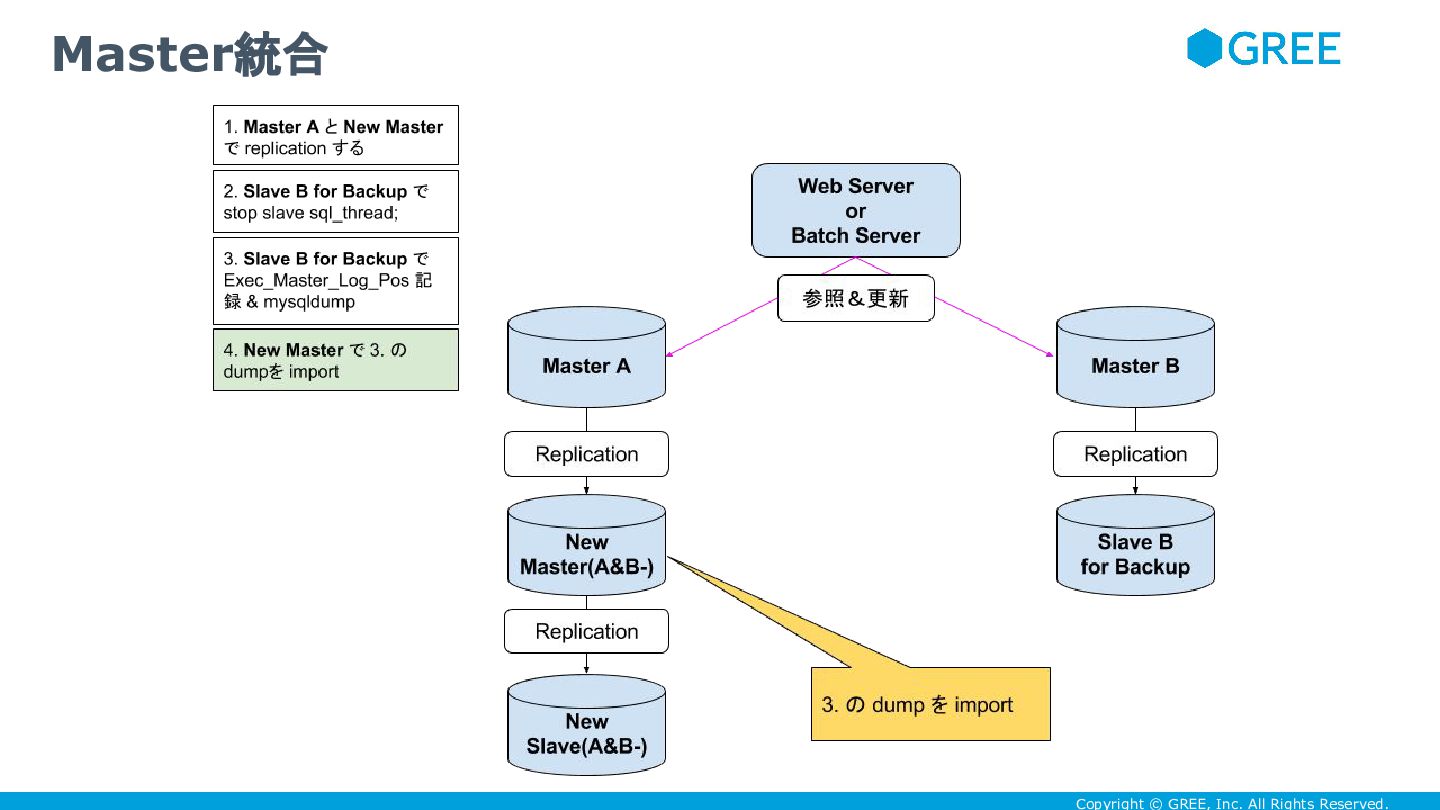
Copyright © GREE, Inc. All Rights Reserved. サービス無停止で master統合しよう
Copyright © GREE, Inc. All Rights Reserved. • DBが100-200GB程度しかないなら、統合して400GB以上にしてしまえ ばいい
• 具体的には次のように master切り替えの手法を踏まえて
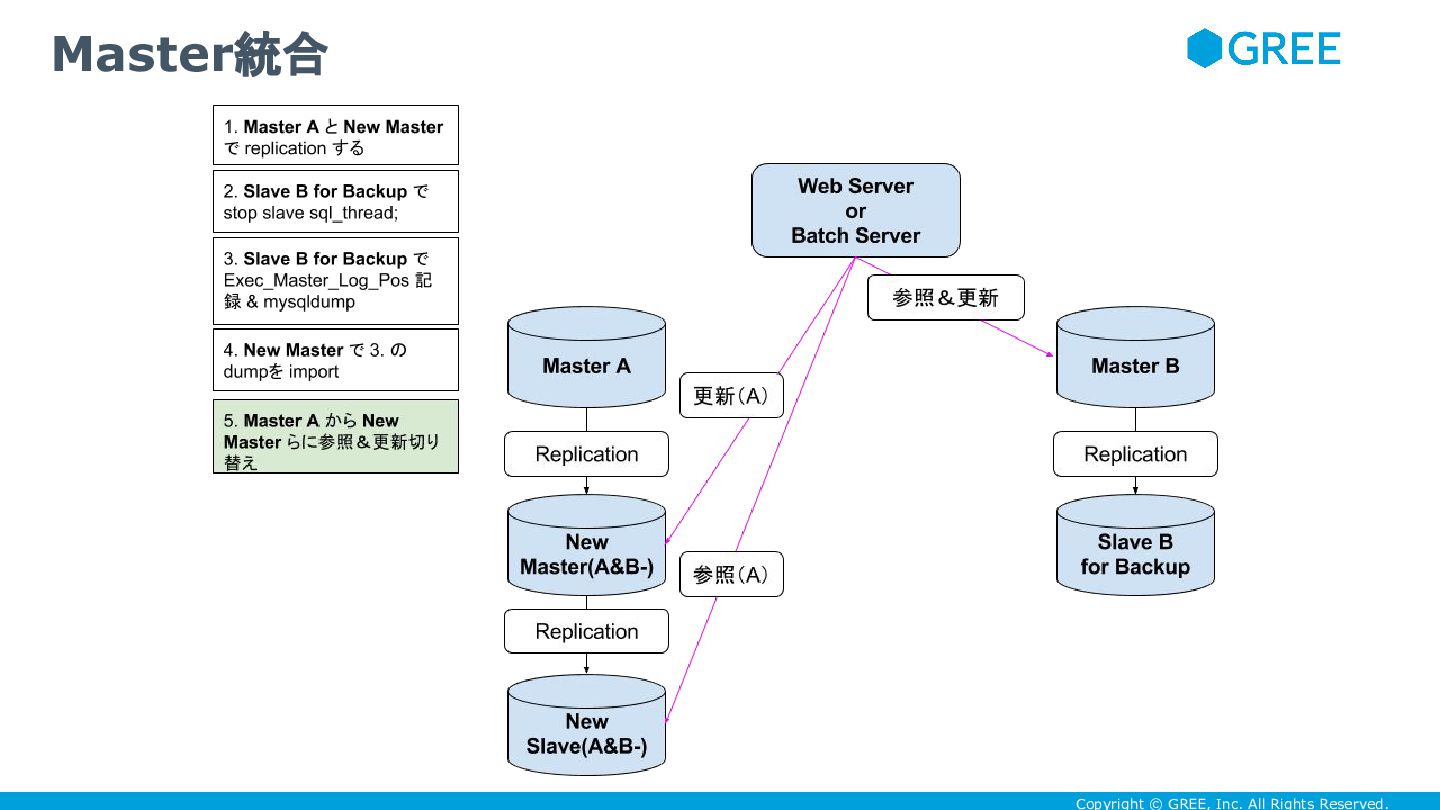
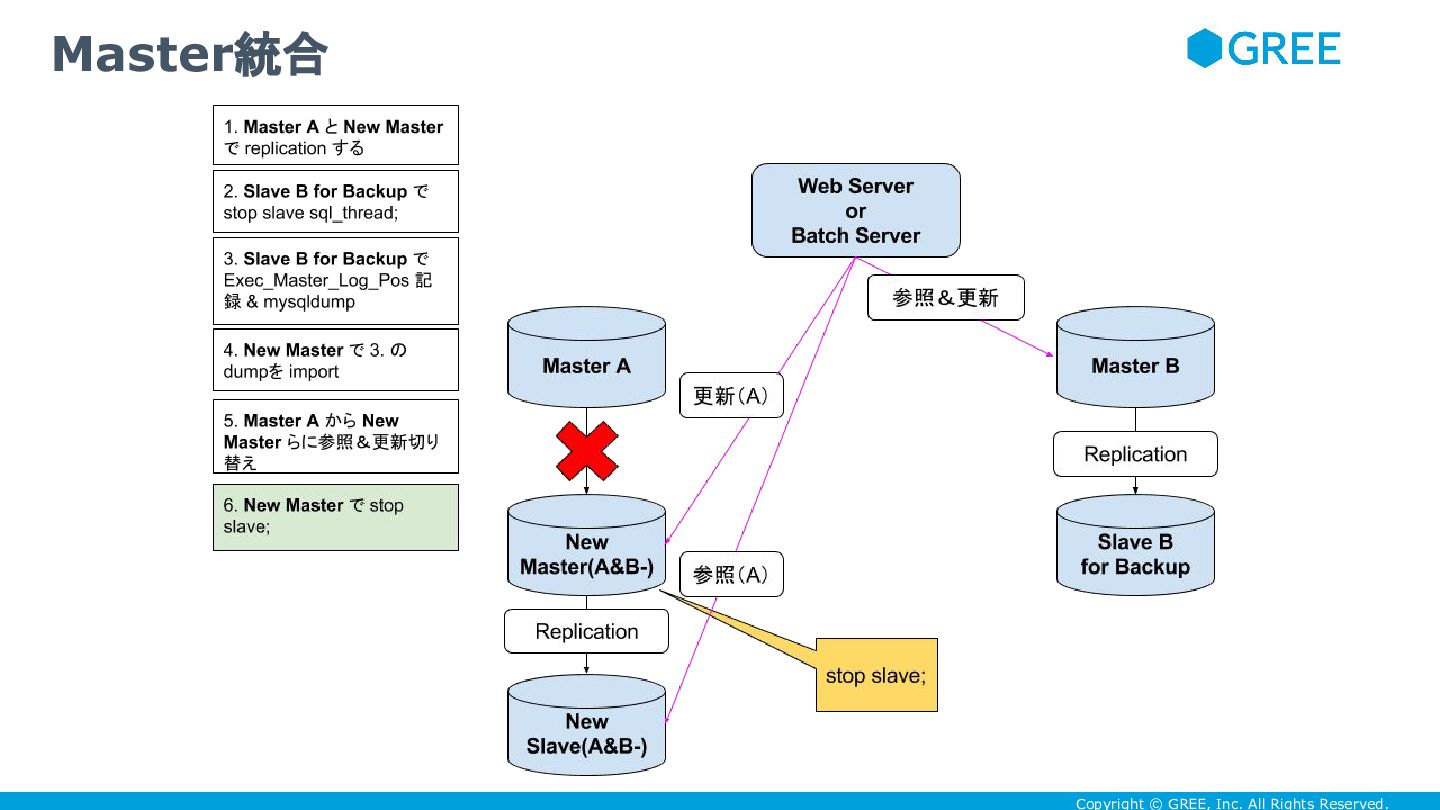
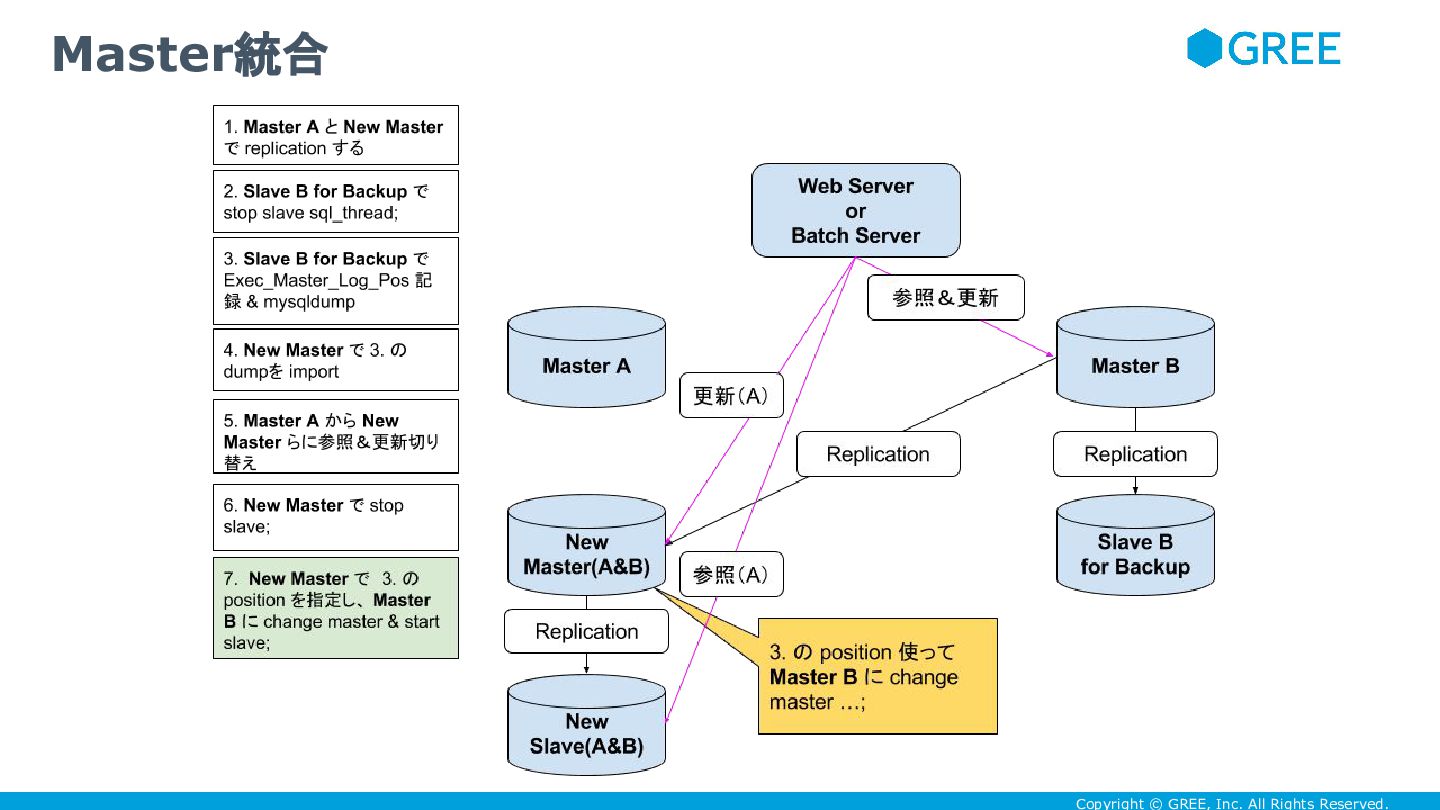
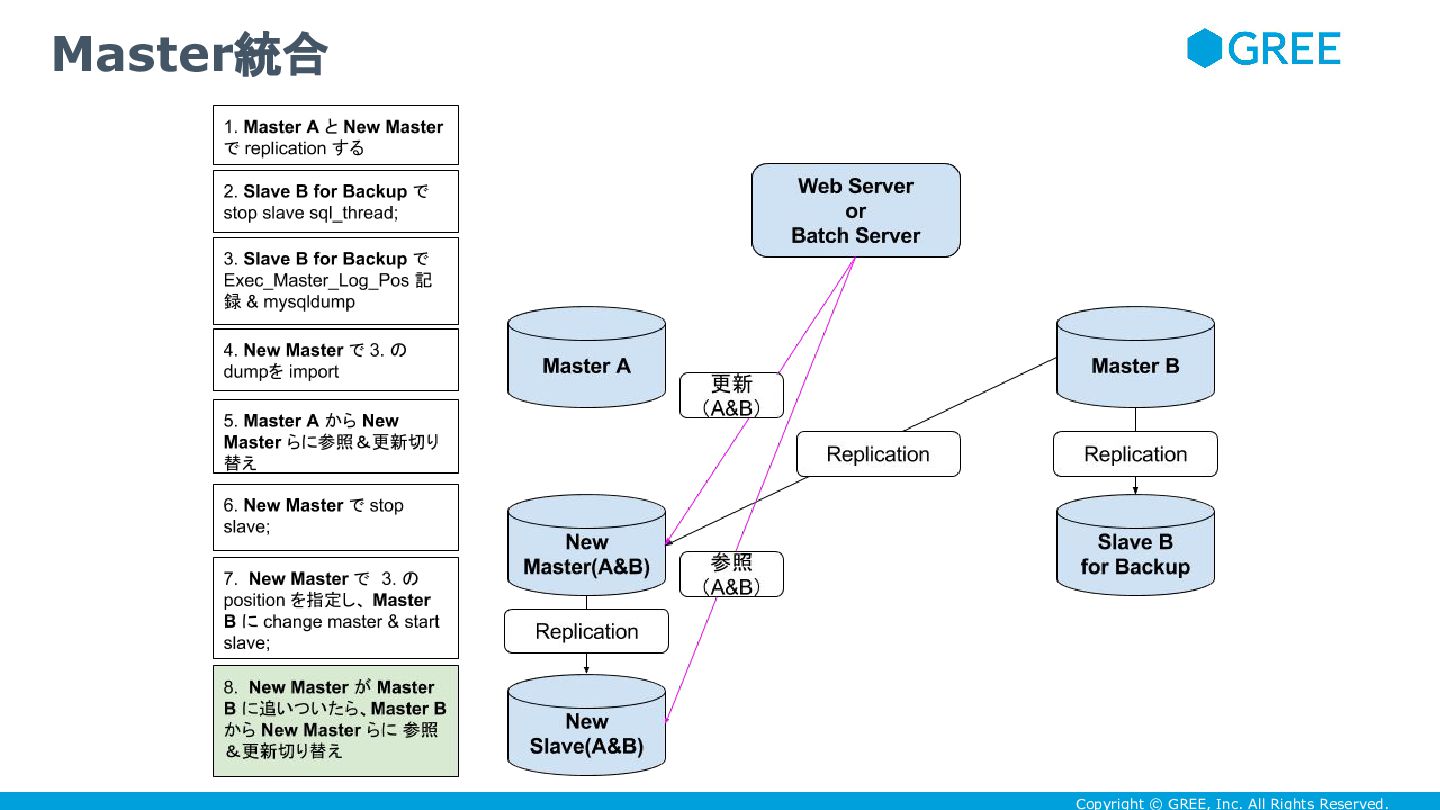
Copyright © GREE, Inc. All Rights Reserved. Master統合
Copyright © GREE, Inc. All Rights Reserved. Master統合
Copyright © GREE, Inc. All Rights Reserved. Master統合
Copyright © GREE, Inc. All Rights Reserved. Master統合
Copyright © GREE, Inc. All Rights Reserved. Master統合
Copyright © GREE, Inc. All Rights Reserved. Master統合
Copyright © GREE, Inc. All Rights Reserved. Master統合
Copyright © GREE, Inc. All Rights Reserved. Master統合
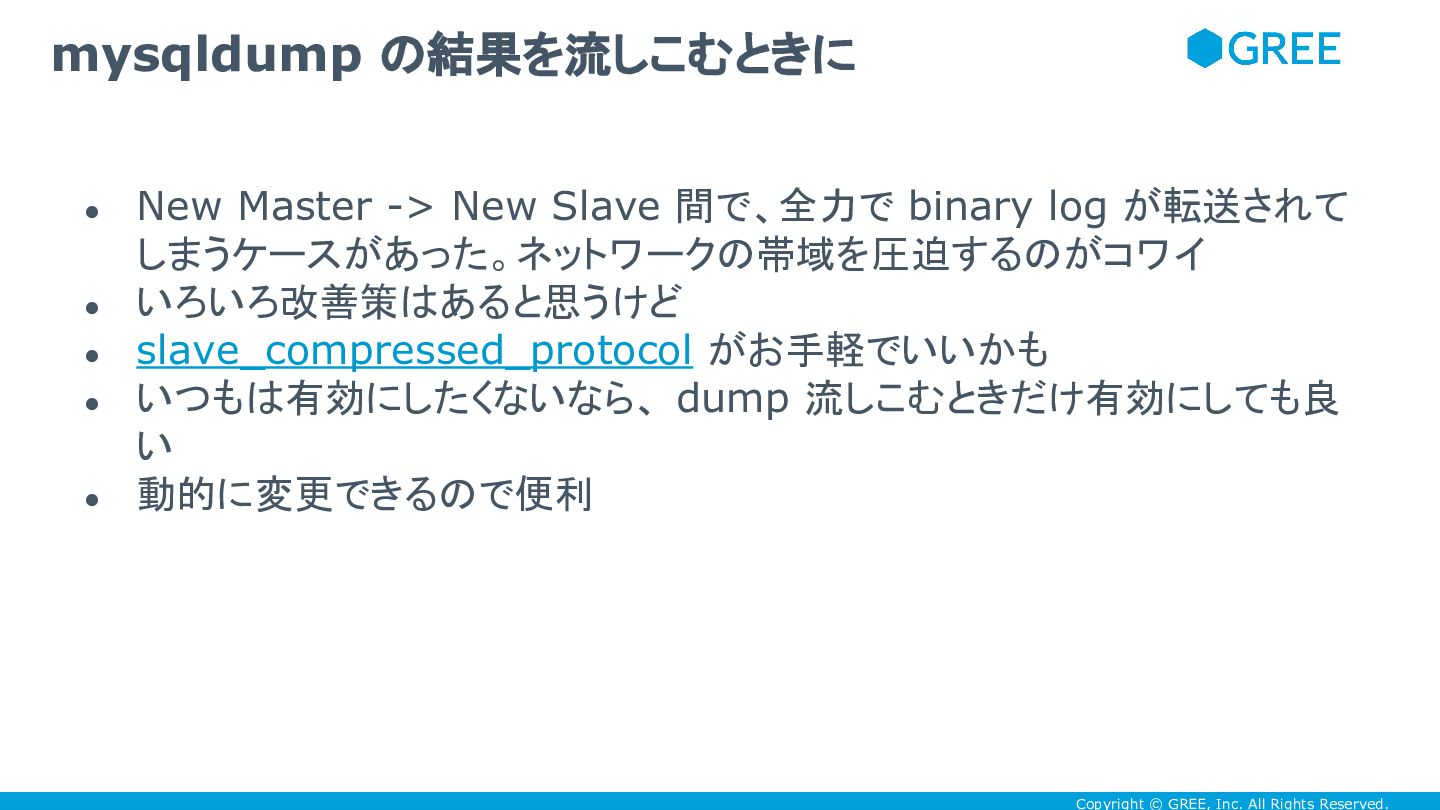
Copyright © GREE, Inc. All Rights Reserved. • New Master
-> New Slave 間で、全力で binary log が転送されて しまうケースがあった。ネットワークの帯域を圧迫するのがコワイ • いろいろ改善策はあると思うけど • slave_compressed_protocol がお手軽でいいかも • いつもは有効にしたくないなら、 dump 流しこむときだけ有効にしても良 い • 動的に変更できるので便利 mysqldump の結果を流しこむときに
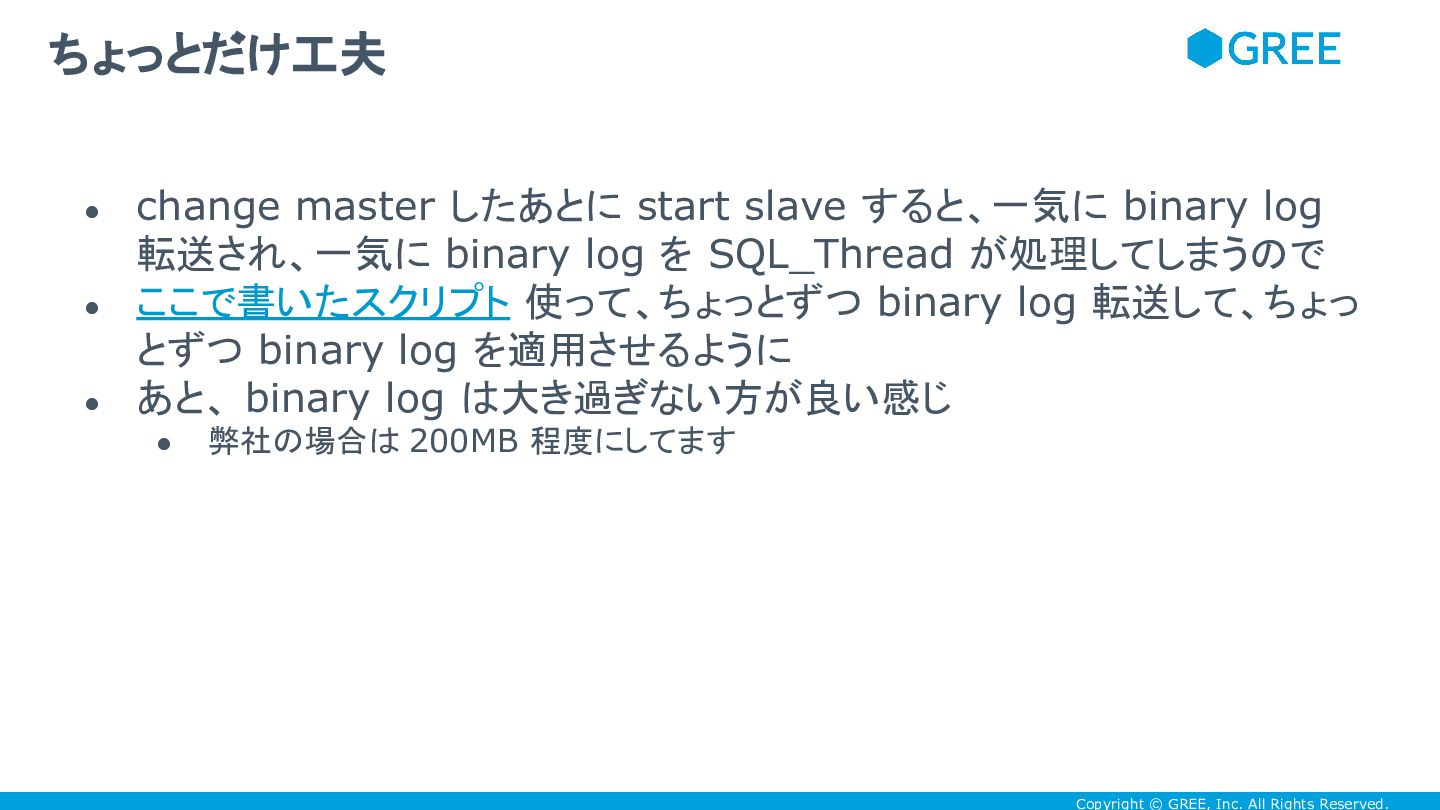
Copyright © GREE, Inc. All Rights Reserved. • change master
したあとに start slave すると、一気に binary log 転送され、一気に binary log を SQL_Thread が処理してしまうので • ここで書いたスクリプト 使って、ちょっとずつ binary log 転送して、ちょっ とずつ binary log を適用させるように • あと、 binary log は大き過ぎない方が良い感じ • 弊社の場合は 200MB 程度にしてます ちょっとだけ工夫
Copyright © GREE, Inc. All Rights Reserved. • 次の課題が見えてきた これでいいかと思いきや
Copyright © GREE, Inc. All Rights Reserved. 続きは 後編で
Copyright © GREE, Inc. All Rights Reserved. つづく
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}