Management Computing 前身 のOBTA2018から数えるとKDDで7回目に開催された、人事データ活用関連のワークショップ この分野のコミュニティでは中心的な役割を担っていると思われる Web Pageに掲載されているトピックは非常に多岐にわたっている 経営科学のためのAI、インテリジェントな経営情報システム、マルチエージェントシステム、求人推薦とインテリジェントな採用、個人と仕 事の適合性と仕事の満足度、キャリア開発とパスモデリング、プロフェッショナルソーシャルネットワーク、才能行動モデリング、才能、個 性、リーダーシップ、人材パフォーマンス評価、人材の維持とインセンティブ、チーム編成とタスク割り当て、グループベースの意思決定、 組織の変化と安定性、組織文化とコミュニケーション、組織競争分析、労働市場情報、戦略的管理と計画、人材と管理コンピューティングに おける公平性、LLMベースの人材管理システム、科学ビッグデータと技術的才能 論文発表は4件 (No Show 1件) LinkedInデータの大学・企業のキャリア変遷グラフから大学の影響力を評価 (ラトガース大学, BOSS Zhipin 他) 人事関連PDFの画像やテキストからLLMで情報抽出 (Amazon) 企業内の専門家の知識を統一的なオントロジー (概念同士の関係性) にLLMで変換 (Amazon) 求職者のプロフィール写真の服装と採用可否の関連性の分析 (中国科学技術大学) 参加者は10~20人程度の規模で、他のワークショップやセッションと比較すると少なめ Ye, Yuyang, et al. "University evaluation through graduate employment prediction: An influence based graph autoencoder approach." IEEE Transactions on Knowledge and Data Engineering 36.11 (2024): 7255-7267. Web Page: https://tmcworkshop.github.io/2025/
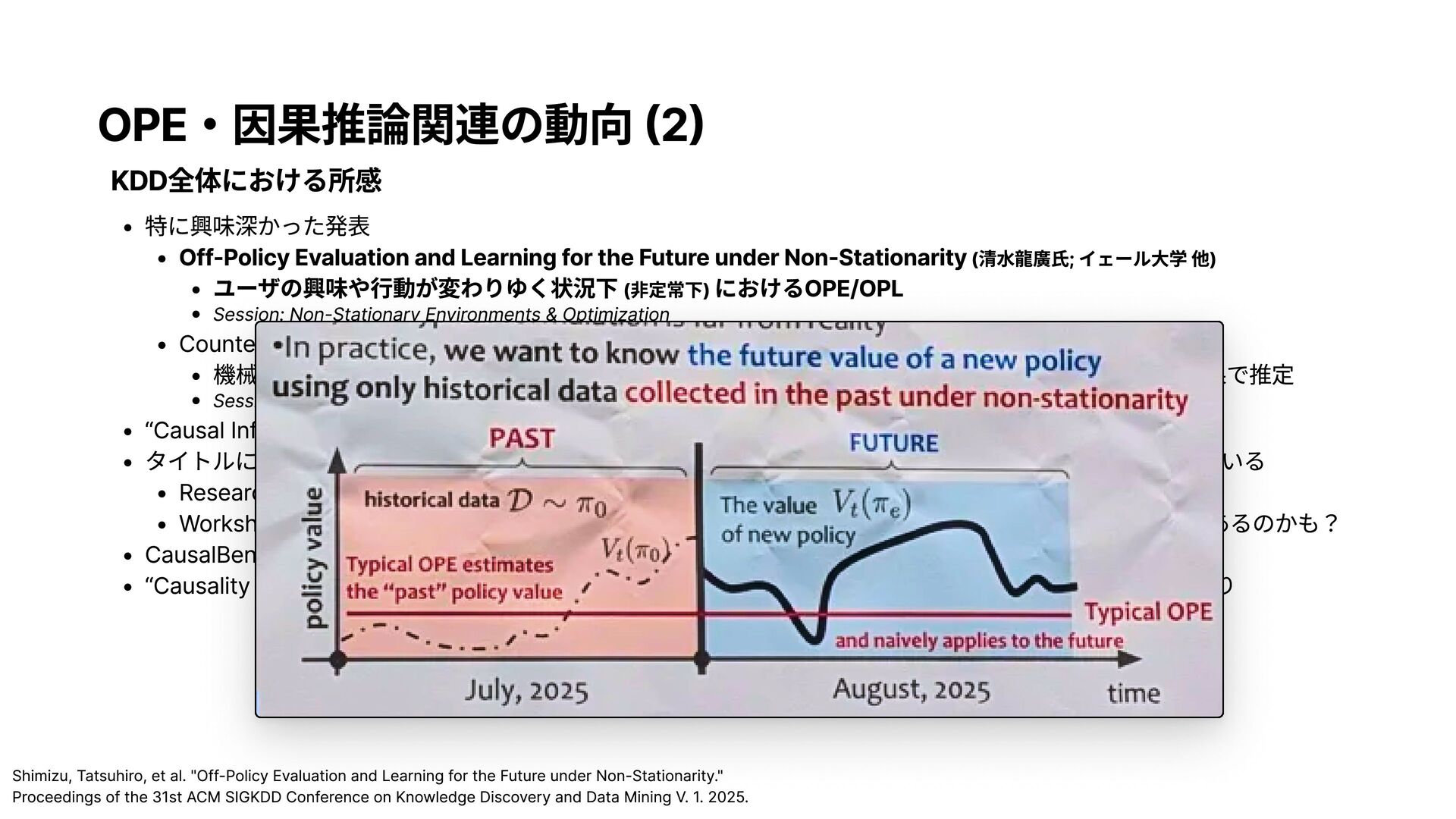
and Le ar ning f or the Future under Non- Stationar ity (清水龍廣氏; イェール大学 他) ユーザの興味や行 動が変わり ゆく状況下 (非定常下 ) におけるOP E/OP L Session: Non-Stationary Environments & Op timiz ation Counterf actual F ai rness Through Transf ormi ng Data Orthogonal to Bi as (カーネギーメロン大学) 機械学習モデルの公平性を、年齢・性別等の機微変数を変化させた反実仮想状況下のモデル予測結果で 推定 Session: Al gorithmic Fairness “Causal Inf erence and Di scovery” “Causal Di scovery and Domai n Adaptati on” というセッションがある タイトルに “Causal” “Causali ty” “Counterf actual” という単語を含む論文が様々なセッションに 散らばっている Research Track 21件、Appli ed Data Sci ence Track 2件、Datasets & Benchmarks Track 1件 Workshopとは異なり本会議で はア カデミ ック寄りなので 、まだ事業会社で の大きな課題解決に は壁があるのかも? CausalBench という因 果推論ベンチマークア プリ ケーションのTutori alもあり “Causali ty f rom Multi -Modal Data” (Caroli ne Uhler氏 ; Massachusetts Insti tute of Technology) という Keynote もあり Shi miz u, Tatsuhi ro, et al. " Off -P oli cy E valuati on and L earni ng f or the F uture under N on-Stati onari ty." P roceedi ngs of the 3 1st ACM SIG KDD Conf erence on Know ledge Di scovery and Data Mi ni ng V. 1. 20 25.
Pol i c y E v aluat i on and Learn i ng for the F uture under Non - Stat i onar i t y ( 清水龍廣氏; イェール大学 他) ユーザの興味や行動が変わりゆく状況下 ( 非定常下) に おけるOPE/OPL S ess ion: Non-Stationary Environm e nt s & Optimization C ounterfactual F a i rness Through Transform i ng Data Orthogonal to B i as ( カーネギーメロン大学) 機械学習モ デ ルの 公平 性を、年齢・性別等の機 微 変数を変化 さ せ た 反実 仮 想状況下のモ デ ル予測結果で推定 S ess ion: Algorithmi c Fairn ess “Causal Inf e r e nc e and Discov e ry” “Causal Discov e ry and Domain Adaptation” というセッションがある タイトルに “Causal” “Causality” “Count e rfactual” という 単 語を含む論文が様々なセッションに散らばっている Research Track 21件、 A ppl i ed Data Sc i ence Track 2件、Datasets & Benchmarks Track 1件 Workshopとは 異 なり本会議ではアカ デ ミック寄りなので、まだ事業会社での大きな課題解決 に は壁があるのかも? C ausalBench という因果推論ベンチマークアプリケーションのTutor i alもあり “ C ausal i t y from Mult i- Modal Data” ( C arol i ne Uhler氏; Massachusetts Inst i tute of Technolog y ) という Ke y note もあり 機械学習・ デ ー タ マ イニ ン グ分野に おい て 因果推論の 考え方 が 浸透して い る 因果 効 果 自体 の 研究 だけではなく 、 因果推論を 用 い た 課題解決を して いる 例 も 多 い
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![現在の主な業務とKDDとの関わり(1) 人事多面評価のバイアス除去 (人事ドメイン・バイアス除去アルゴリズム開発) 企業内で行われる多面評価(360度評価)の評価者の甘辛を補正した評点を 算出するアルゴリズムを開発中。 「Digital HR Competition 2024」 ピープルアナリティクス部門グランプリ[2]、](https://files.speakerdeck.com/presentations/5aec405d7d6d475b88bb4e1e3ca6dcd4/slide_6.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}