for gene regulation. • Learn how to represent the binding preference of a transcription factor. • Learn how to find potential binding sites in DNA sequences.
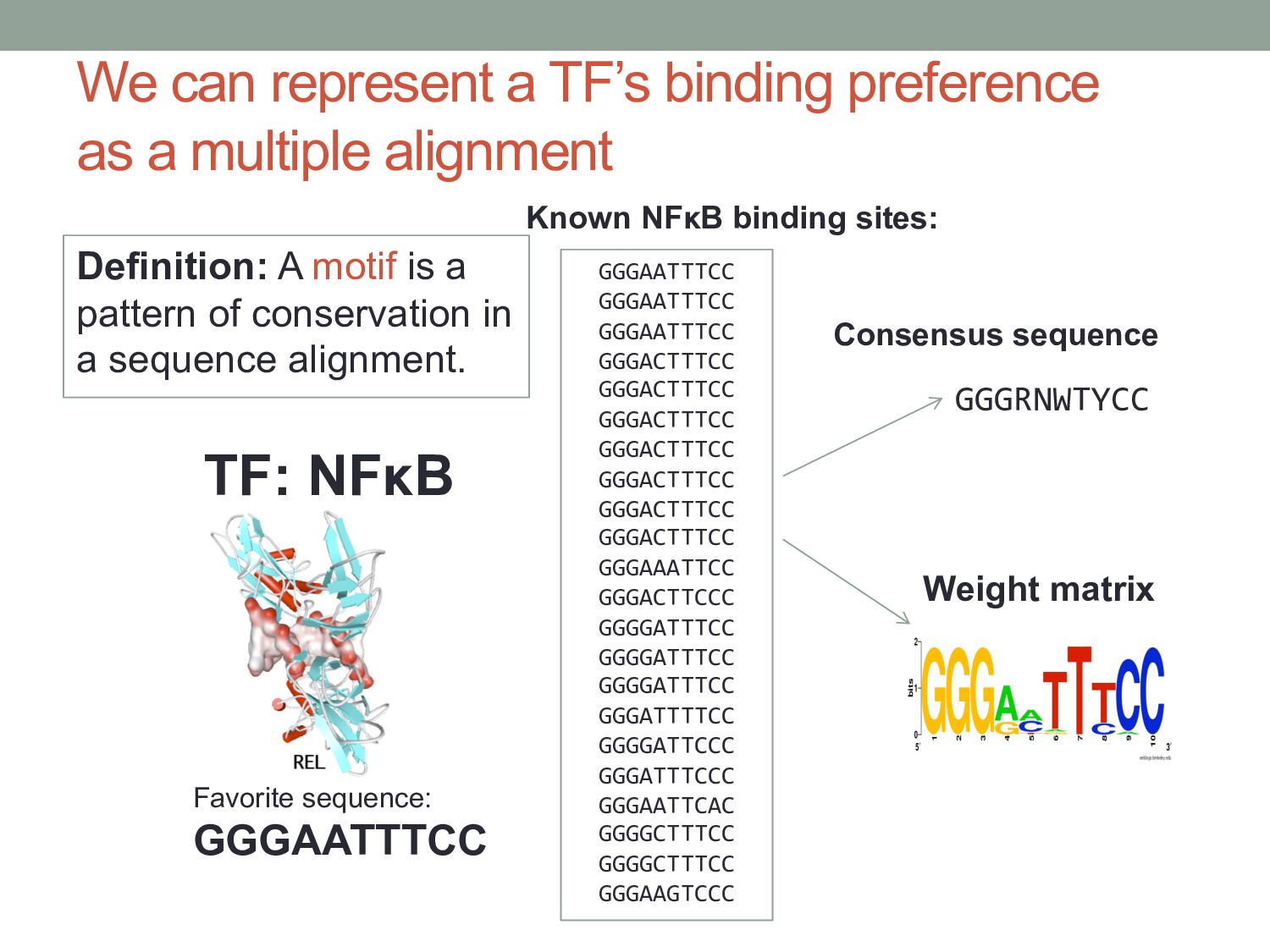
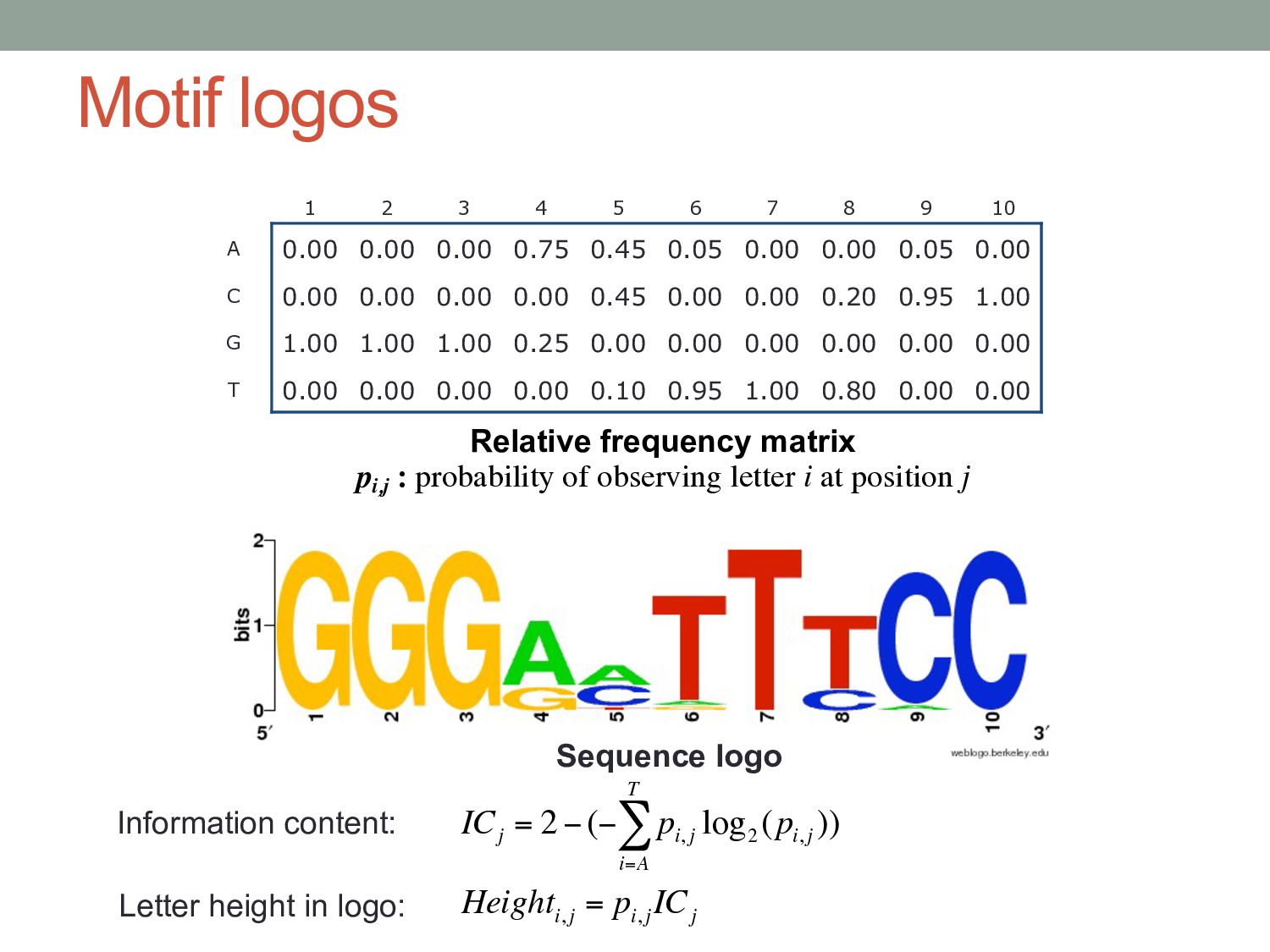
i, j log 2 (p i, j ) i=A T ∑ ) Height i, j = p i, j IC j Information content: Letter height in logo: 1 2 3 4 5 6 7 8 9 10 A 0.00 0.00 0.00 0.75 0.45 0.05 0.00 0.00 0.05 0.00 C 0.00 0.00 0.00 0.00 0.45 0.00 0.00 0.20 0.95 1.00 G 1.00 1.00 1.00 0.25 0.00 0.00 0.00 0.00 0.00 0.00 T 0.00 0.00 0.00 0.00 0.10 0.95 1.00 0.80 0.00 0.00 Relative frequency matrix pi,j : probability of observing letter i at position j
8 9 10 A -4.64 -4.64 -4.64 1.55 0.82 -2.64 -4.64 -4.64 -2.64 -4.64 C -4.64 -4.64 -4.64 -4.64 0.82 -4.64 -4.64 -0.40 1.91 1.96 G 1.96 1.96 1.96 0.00 -4.64 -4.64 -4.64 -4.64 -4.64 -4.64 T -4.64 -4.64 -4.64 -4.64 -1.06 1.91 1.96 1.66 -4.64 -4.64 Position weight matrix: mi,j = log2 (pi,j / bi ) where bi is the background probability of letter i 1 2 3 4 5 6 7 8 9 10 A 0.01 0.01 0.01 0.73 0.44 0.04 0.01 0.01 0.04 0.01 C 0.01 0.01 0.01 0.01 0.44 0.01 0.01 0.19 0.94 0.97 G 0.97 0.97 0.97 0.25 0.01 0.01 0.01 0.01 0.01 0.01 T 0.01 0.01 0.01 0.01 0.12 0.94 0.97 0.79 0.01 0.01 Relative frequency matrix pi,j : probability of observing letter i at position j A 0.25 C 0.25 G 0.25 T 0.25 Background frequencies bi : probability of observing letter i ÷
3 4 5 6 7 8 9 10 A -4.70 -4.70 -4.70 1.55 0.82 -2.12 -4.70 -4.70 -2.12 -4.70 C -4.70 -4.70 -4.70 -4.70 0.82 -4.70 -4.70 -0.31 1.88 1.96 G 1.96 1.96 1.96 0.00 -4.70 -4.70 -4.70 -4.70 -4.70 -4.70 T -4.70 -4.70 -4.70 -4.70 -1.24 1.88 1.96 1.64 -4.70 -4.70 >Test Sequence TTACGTTTGTCGATTTATGGGACTTTCCTCTTCGTATTTATTAGGCT 1 2 3 4 5 6 7 8 9 10 A -4.70 -4.70 -4.70 1.55 0.82 -2.12 -4.70 -4.70 -2.12 -4.70 C -4.70 -4.70 -4.70 -4.70 0.82 -4.70 -4.70 -0.31 1.88 1.96 G 1.96 1.96 1.96 0.00 -4.70 -4.70 -4.70 -4.70 -4.70 -4.70 T -4.70 -4.70 -4.70 -4.70 -1.24 1.88 1.96 1.64 -4.70 -4.70 T T A C G T T T G T C G A … A T G G G A C T T T C C T C Score = -27.42 Score = 17.57
MEME suite of motif analysis tools. • MotifViz: http://biowulf.bu.edu/MotifViz/ • Various motif scanning tools included. • MATCH: Kel, et al. Nucleic Acids Res (2003) • TAMO: Gordon, et al. Bioinformatics (2005) • MotifScanner/TOUCAN: Aerts, et al. Nucleic Acids Res (2005)
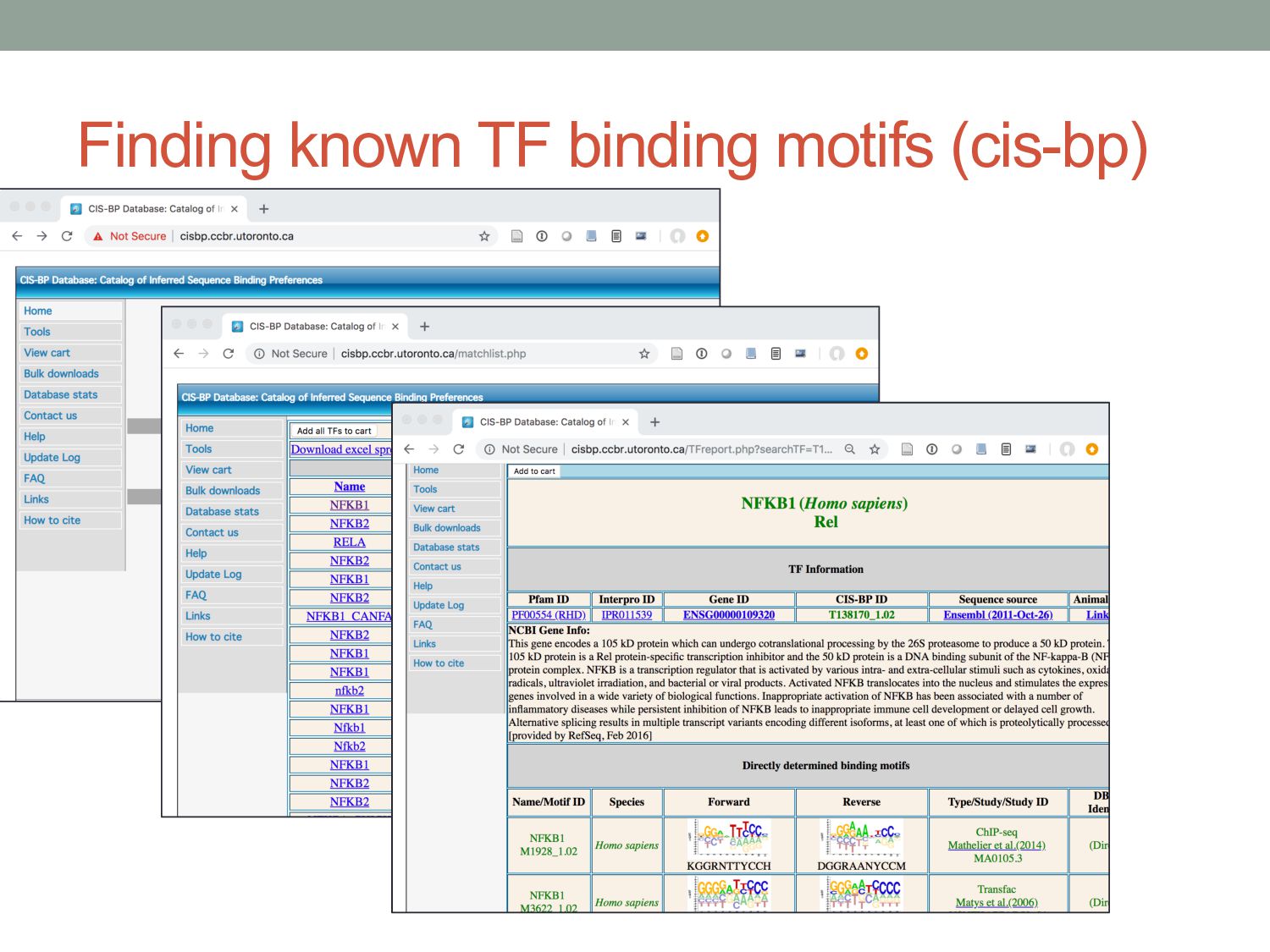
access. • High quality motifs, medium coverage. • cis-bp: • http://cisbp.ccbr.utoronto.ca • Mostly based on in vitro protein binding microarray experiments. • Comprehensive: known or predicted motifs for most human TFs.
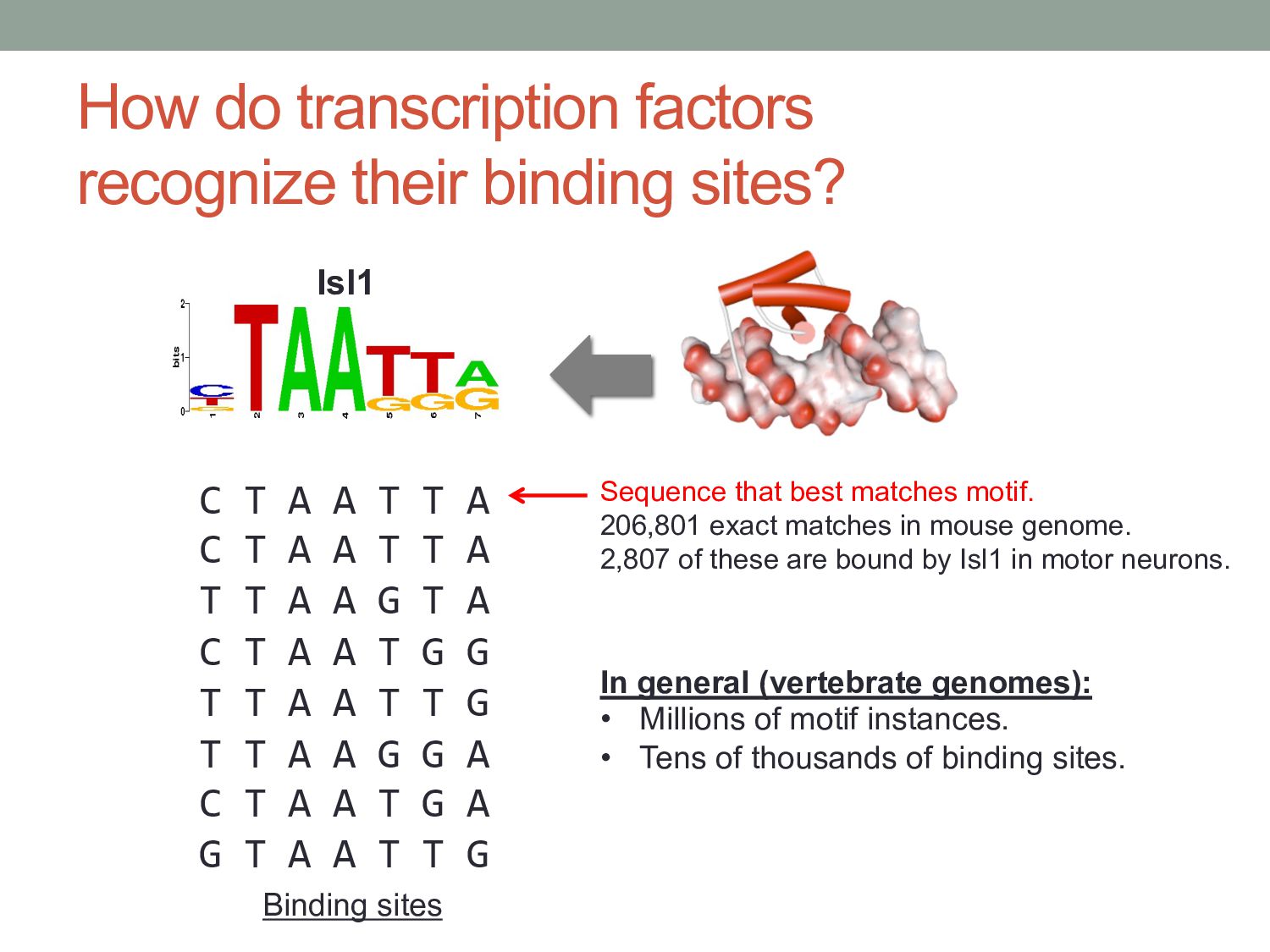
A A T T A C T A A T T A T T A A G T A C T A A T G G T T A A T T G T T A A G G A C T A A T G A G T A A T T G Binding sites Sequence that best matches motif. 206,801 exact matches in mouse genome. 2,807 of these are bound by Isl1 in motor neurons. In general (vertebrate genomes): • Millions of motif instances. • Tens of thousands of binding sites. Isl1
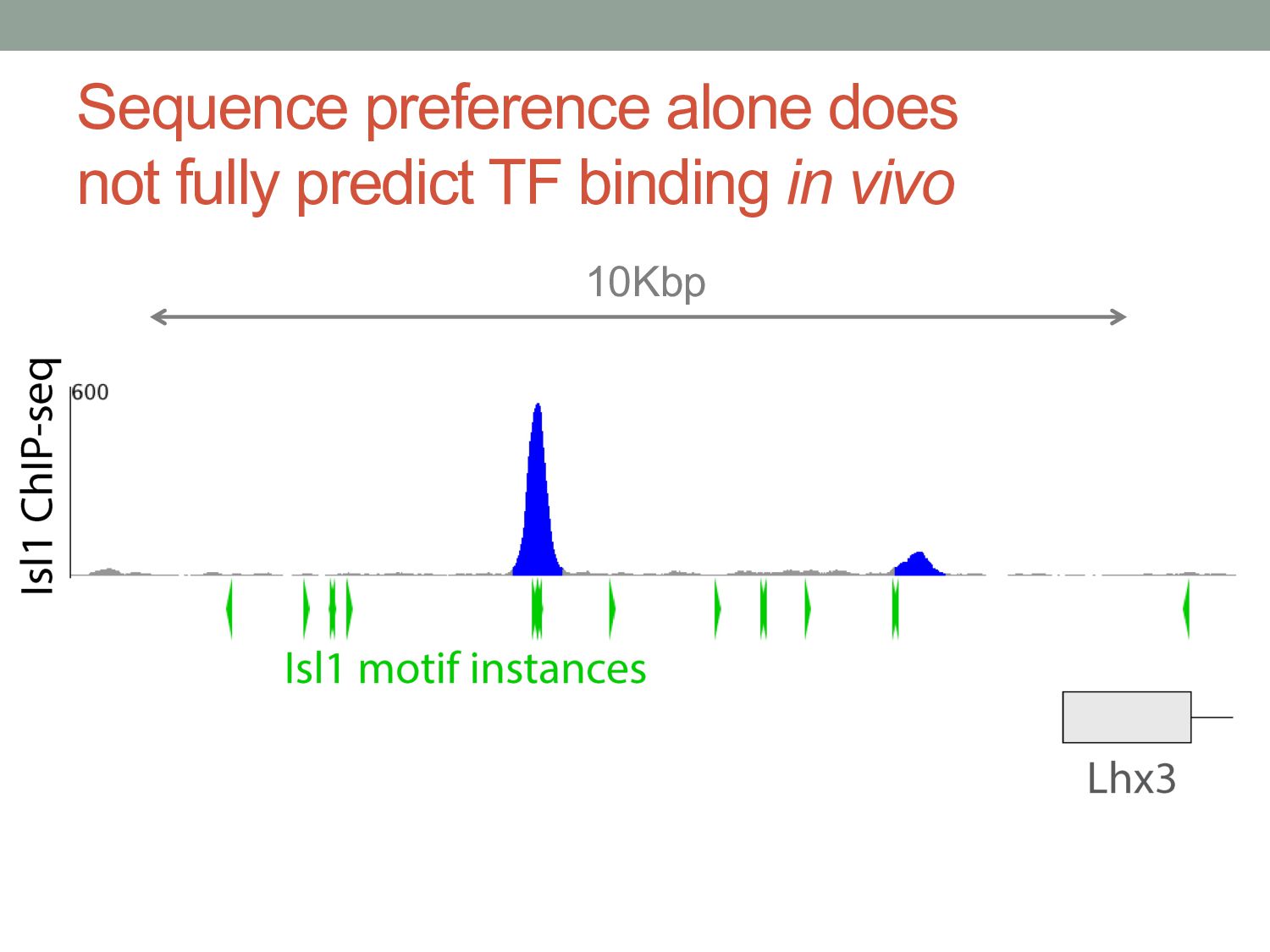
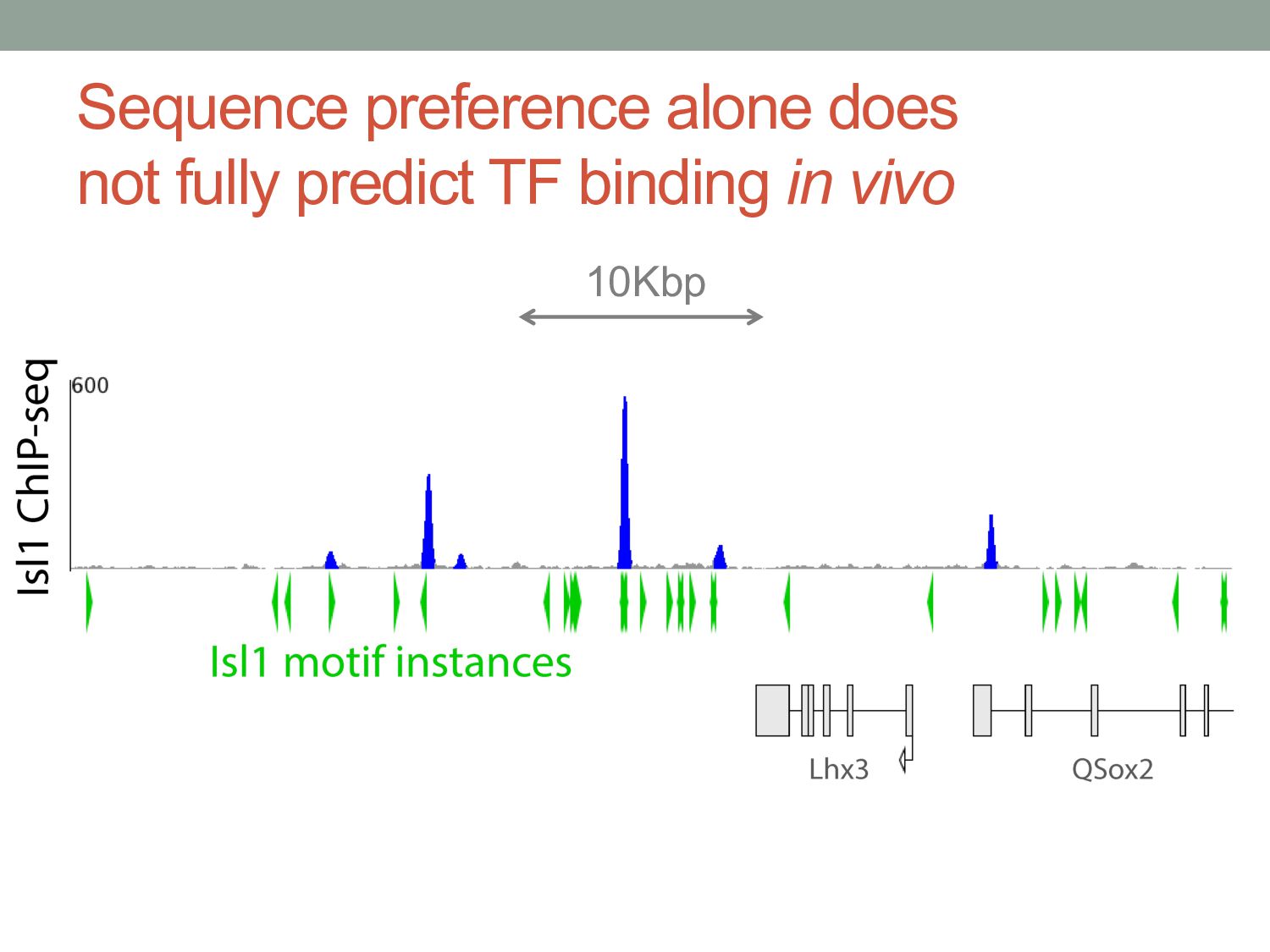
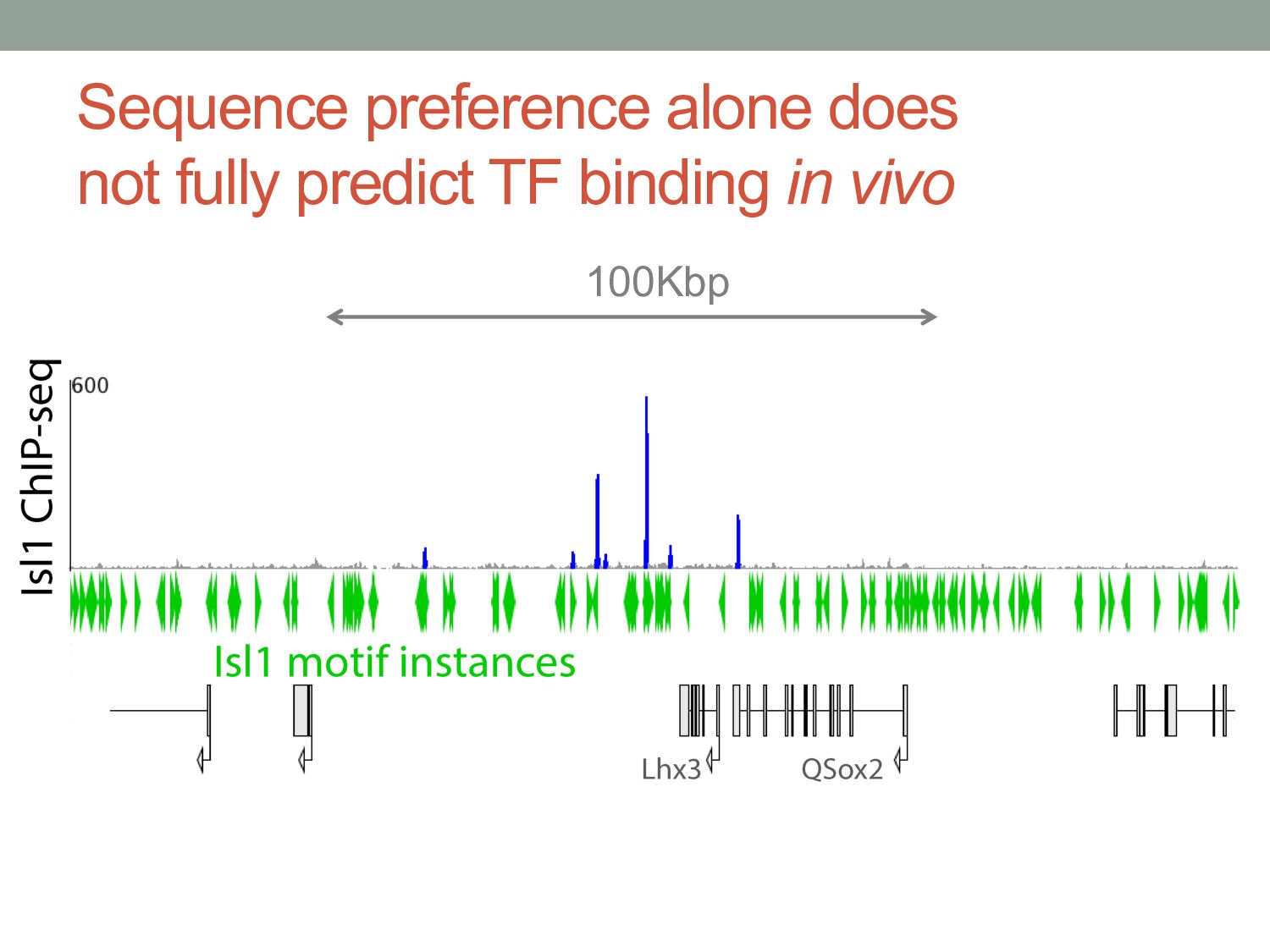
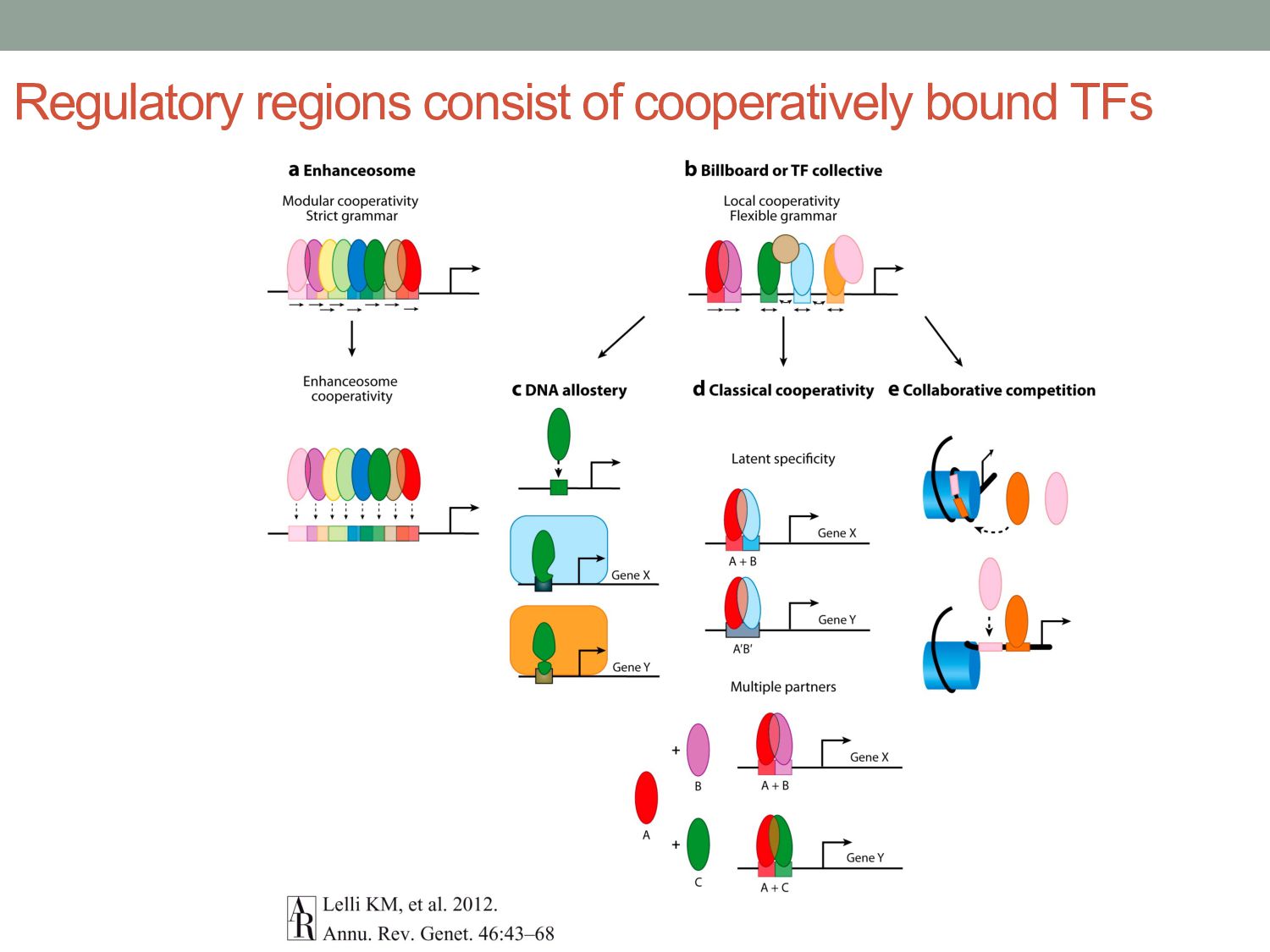
TF binding motif occurrences will have no function in a given cell type*. • How can we focus on motif instances that are more likely to be bound & functional? • Conservation • Cis-regulatory modules (i.e. clusters of sites) • Measuring TF binding (ChIP-seq) • Accessibility (DNaseI hypersensitivity) • Chromatin marks (H3K4me1, H3K27ac) * Wasserman & Sandelin, Nature Reviews Genetics (2004) Cell type dependent: we would need experimental data
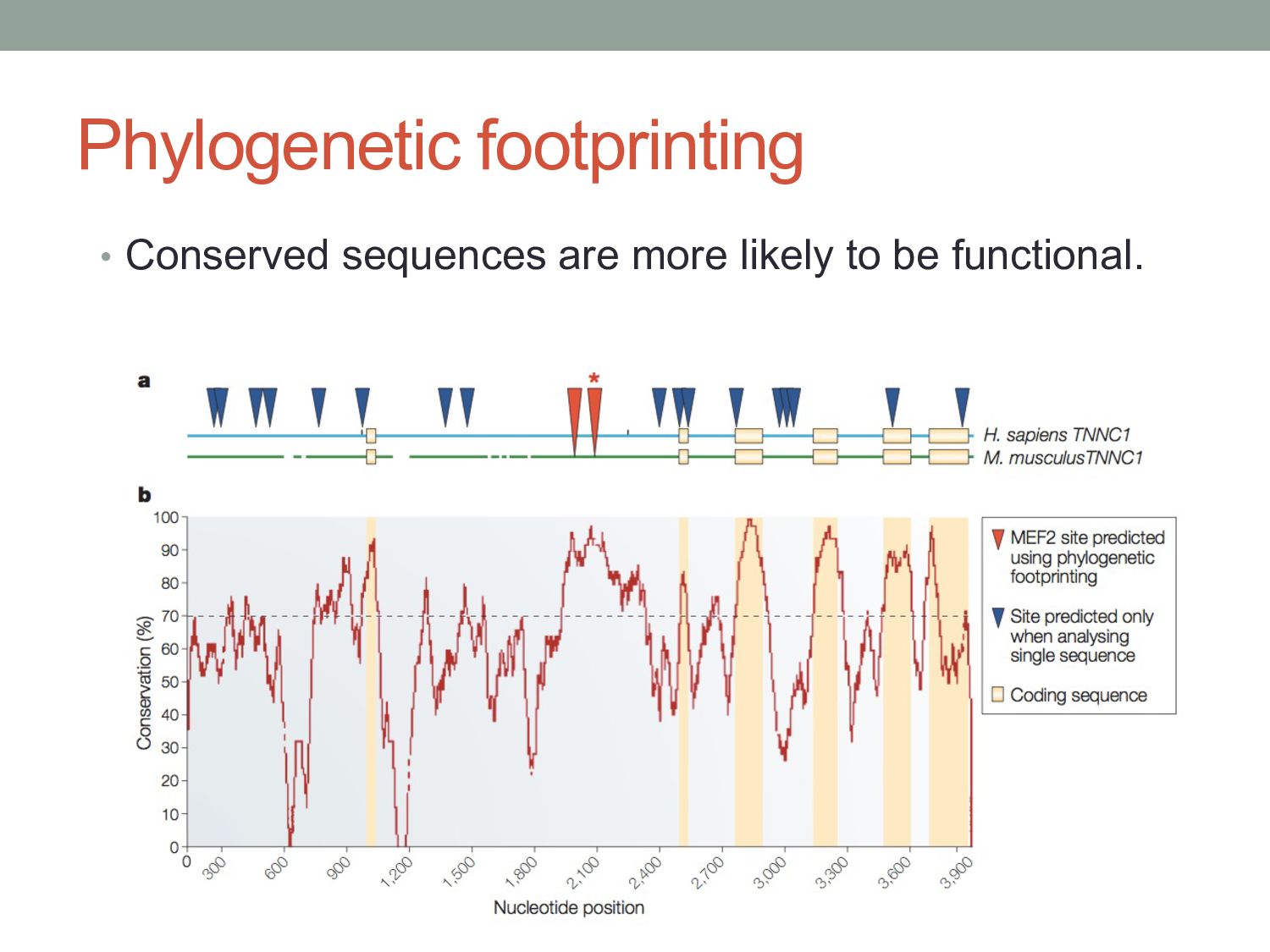
sites are directly conserved between human & mouse. • Perhaps even fewer TF binding sites are functionally conserved. • Phylogenetic shadowing approaches allows conservation analysis of binding sites across more closely related species.
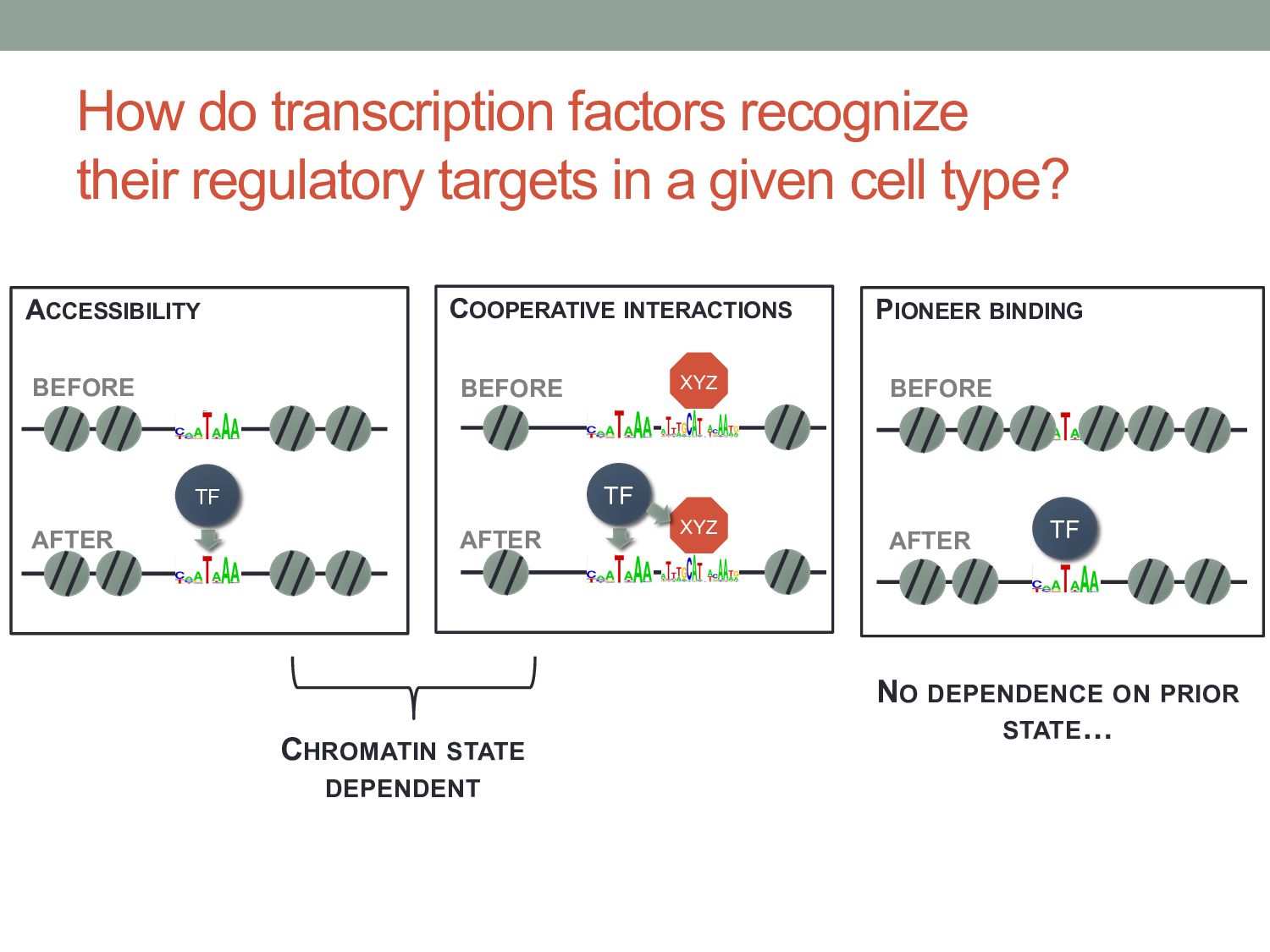
given cell type? CHROMATIN STATE DEPENDENT ACCESSIBILITY TF XYZ COOPERATIVE INTERACTIONS TF XYZ PIONEER BINDING TF BEFORE AFTER BEFORE AFTER BEFORE AFTER NO DEPENDENCE ON PRIOR STATE…
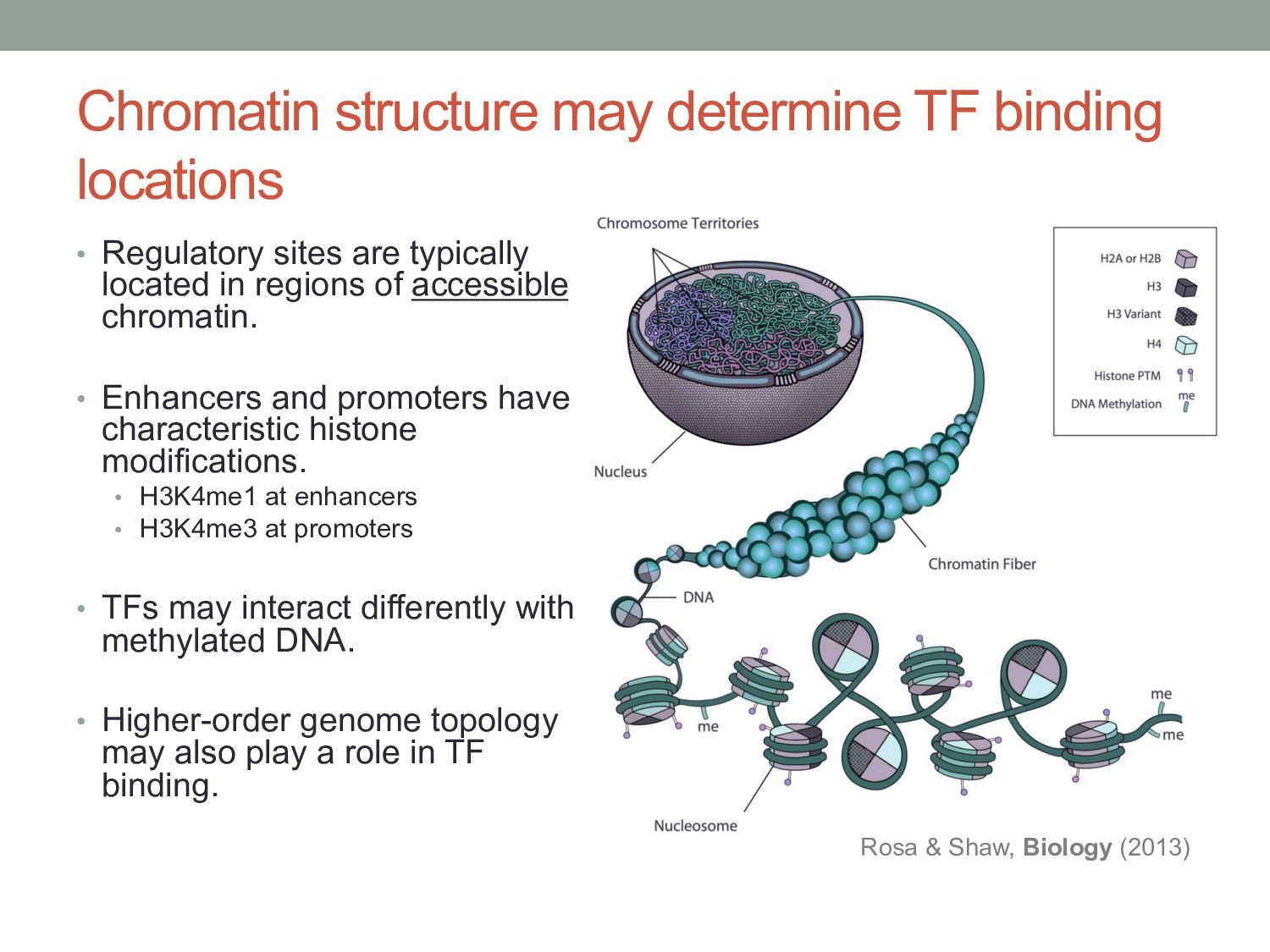
are typically located in regions of accessible chromatin. • Enhancers and promoters have characteristic histone modifications. • H3K4me1 at enhancers • H3K4me3 at promoters • TFs may interact differently with methylated DNA. • Higher-order genome topology may also play a role in TF binding. Rosa & Shaw, Biology (2013)
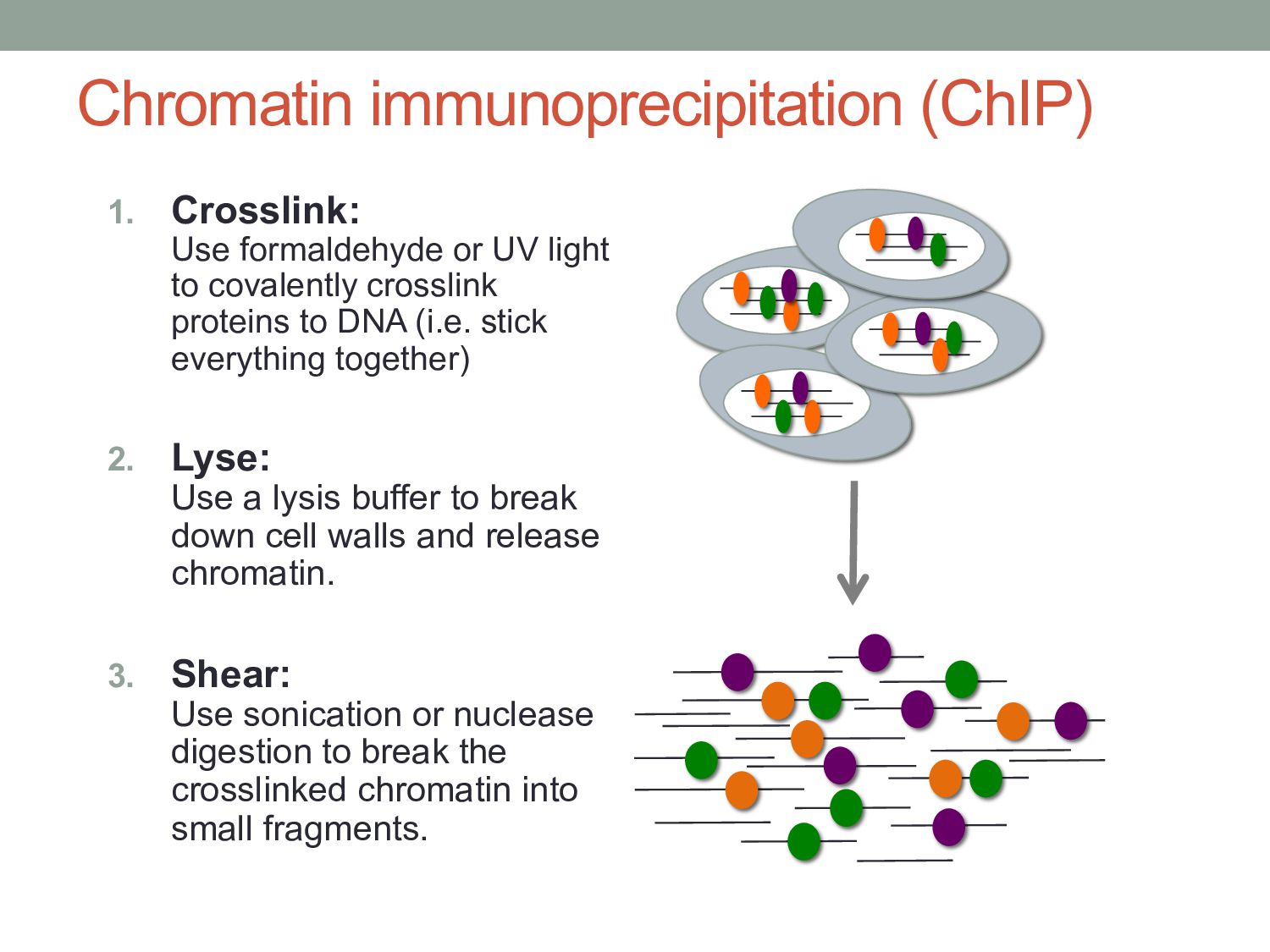
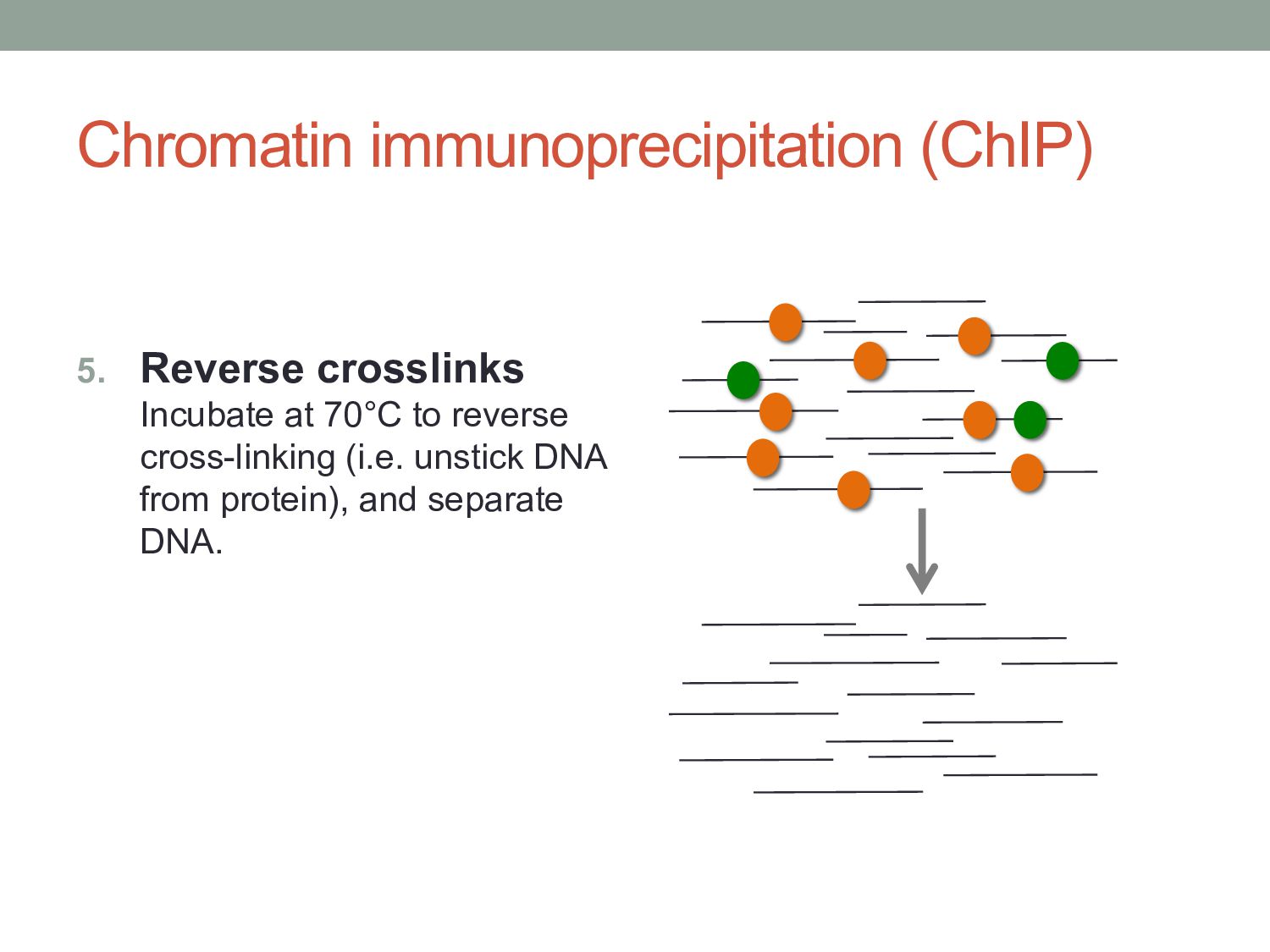
to covalently crosslink proteins to DNA (i.e. stick everything together) 2. Lyse: Use a lysis buffer to break down cell walls and release chromatin. 3. Shear: Use sonication or nuclease digestion to break the crosslinked chromatin into small fragments.
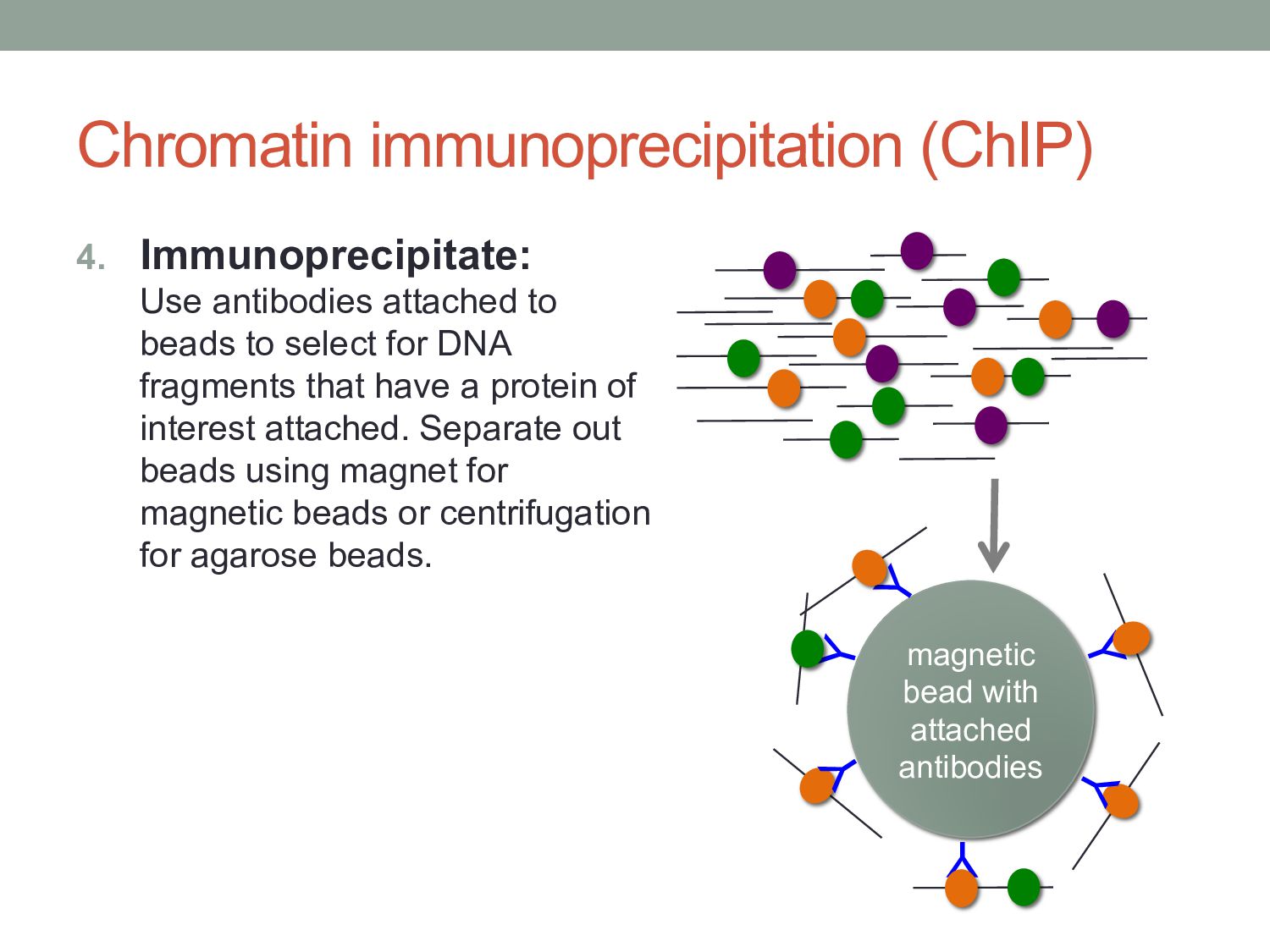
to select for DNA fragments that have a protein of interest attached. Separate out beads using magnet for magnetic beads or centrifugation for agarose beads. Y Y Y Y Y magnetic bead with attached antibodies Y
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}