genomic sample using a high-throughput sequencer, resulting in millions of short reads (30bp – 150bp). • We want to map these reads back to the reference genome (millions to billions of bp). • The reads contain some errors (1 miscalled base per 100bp) • The sequenced genome is different from the reference genome (perhaps 1% single nucleotide polymorphism rate). • Required: efficient algorithm to quickly map millions of reads against a >3 billion bp genome.
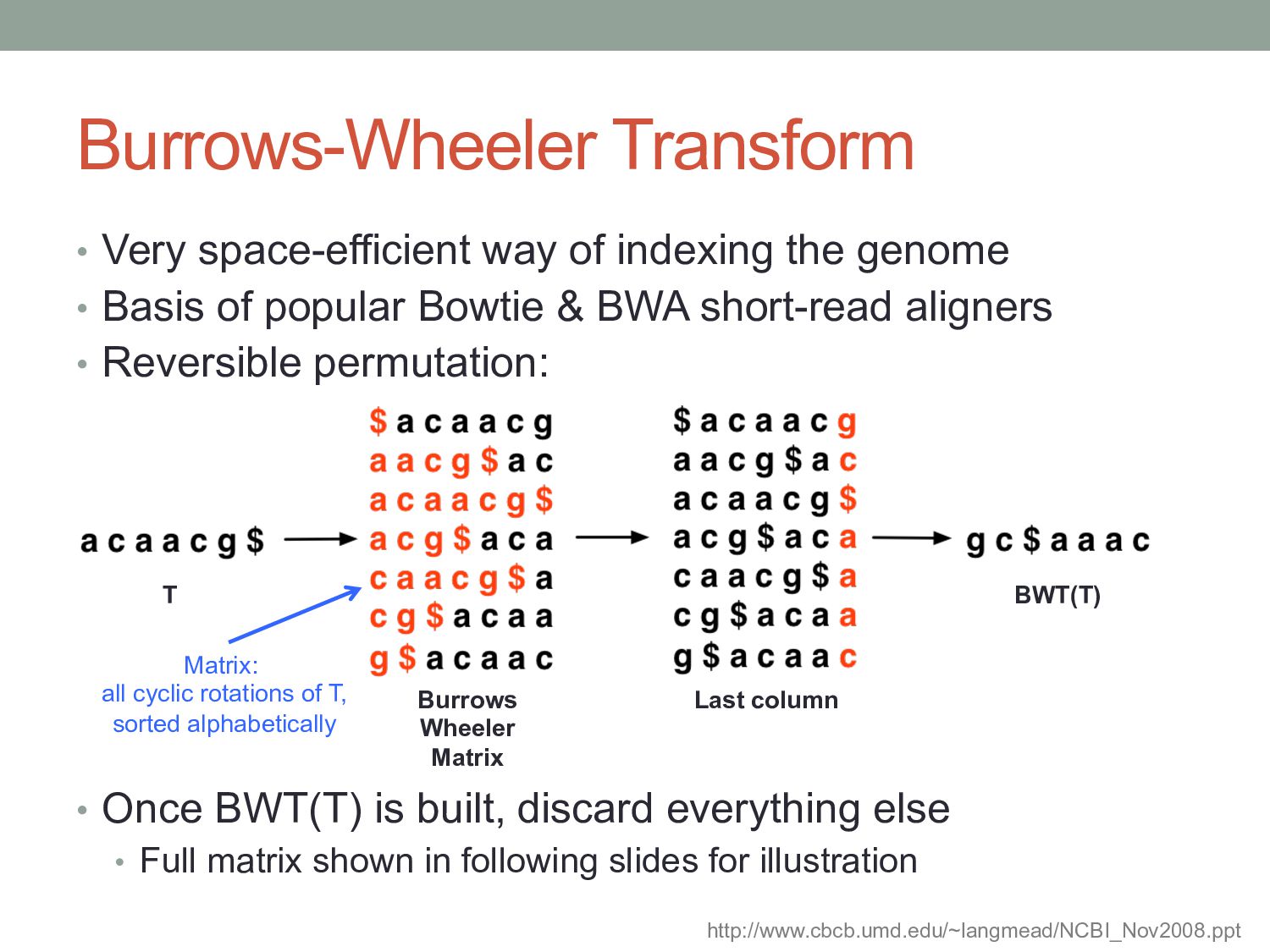
• Basis of popular Bowtie & BWA short-read aligners • Reversible permutation: • Once BWT(T) is built, discard everything else • Full matrix shown in following slides for illustration Burrows Wheeler Matrix Last column BWT(T) T http://www.cbcb.umd.edu/~langmead/NCBI_Nov2008.ppt Matrix: all cyclic rotations of T, sorted alphabetically
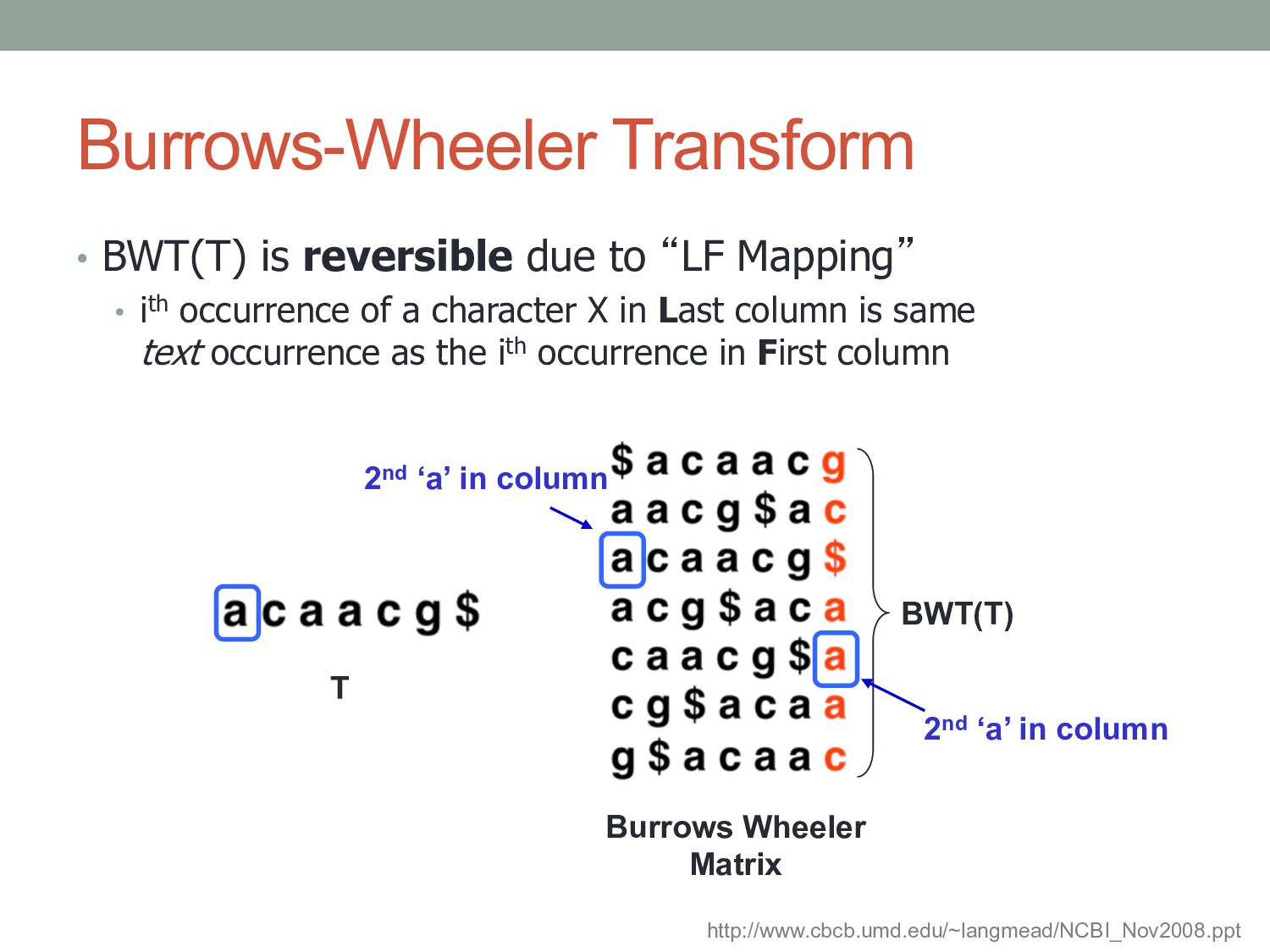
• ith occurrence of a character X in Last column is same text occurrence as the ith occurrence in First column T BWT(T) Burrows Wheeler Matrix 2nd ‘a’ in column http://www.cbcb.umd.edu/~langmead/NCBI_Nov2008.ppt 2nd ‘a’ in column
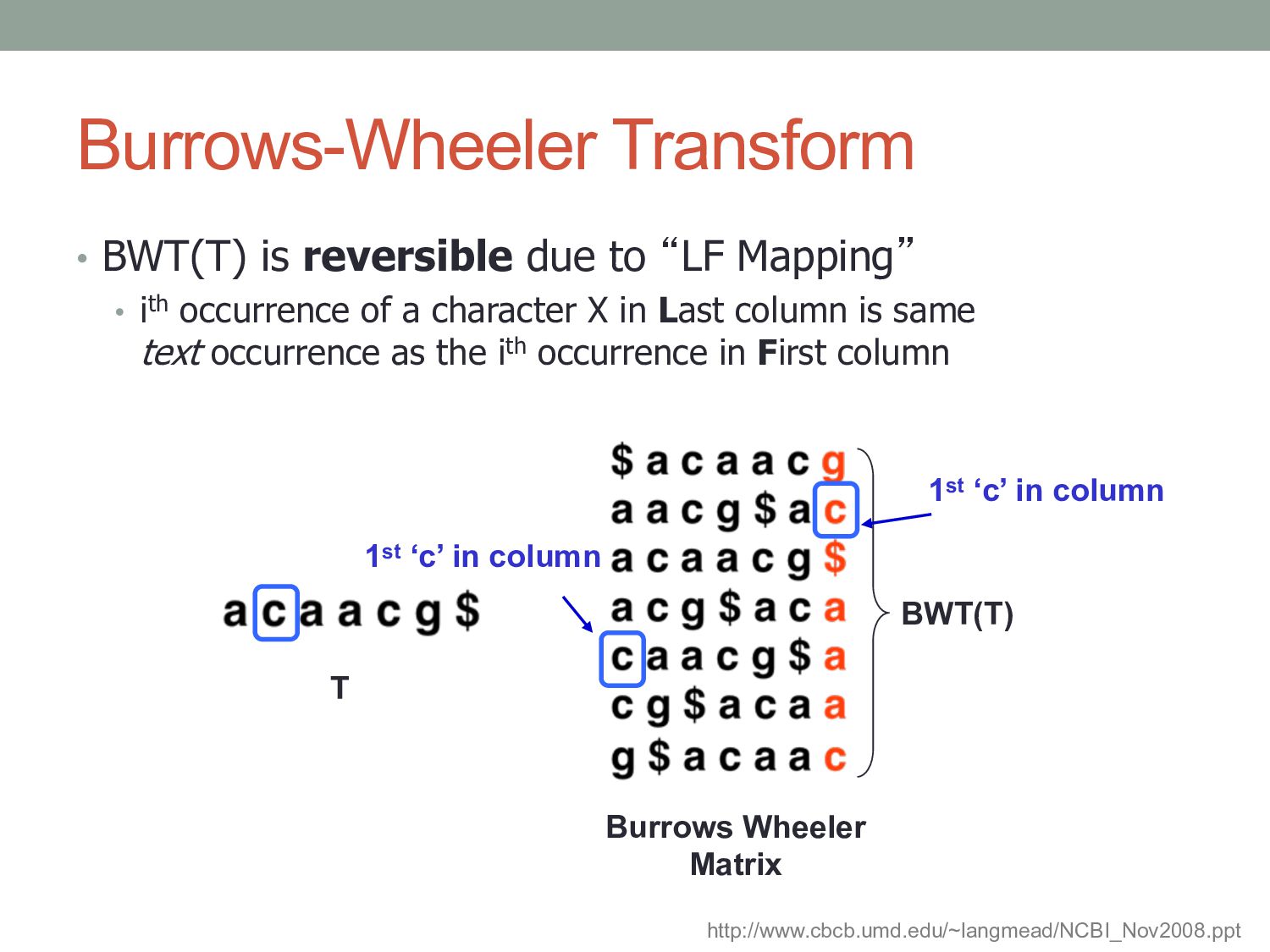
• ith occurrence of a character X in Last column is same text occurrence as the ith occurrence in First column T BWT(T) Burrows Wheeler Matrix http://www.cbcb.umd.edu/~langmead/NCBI_Nov2008.ppt 1st ‘c’ in column 1st ‘c’ in column
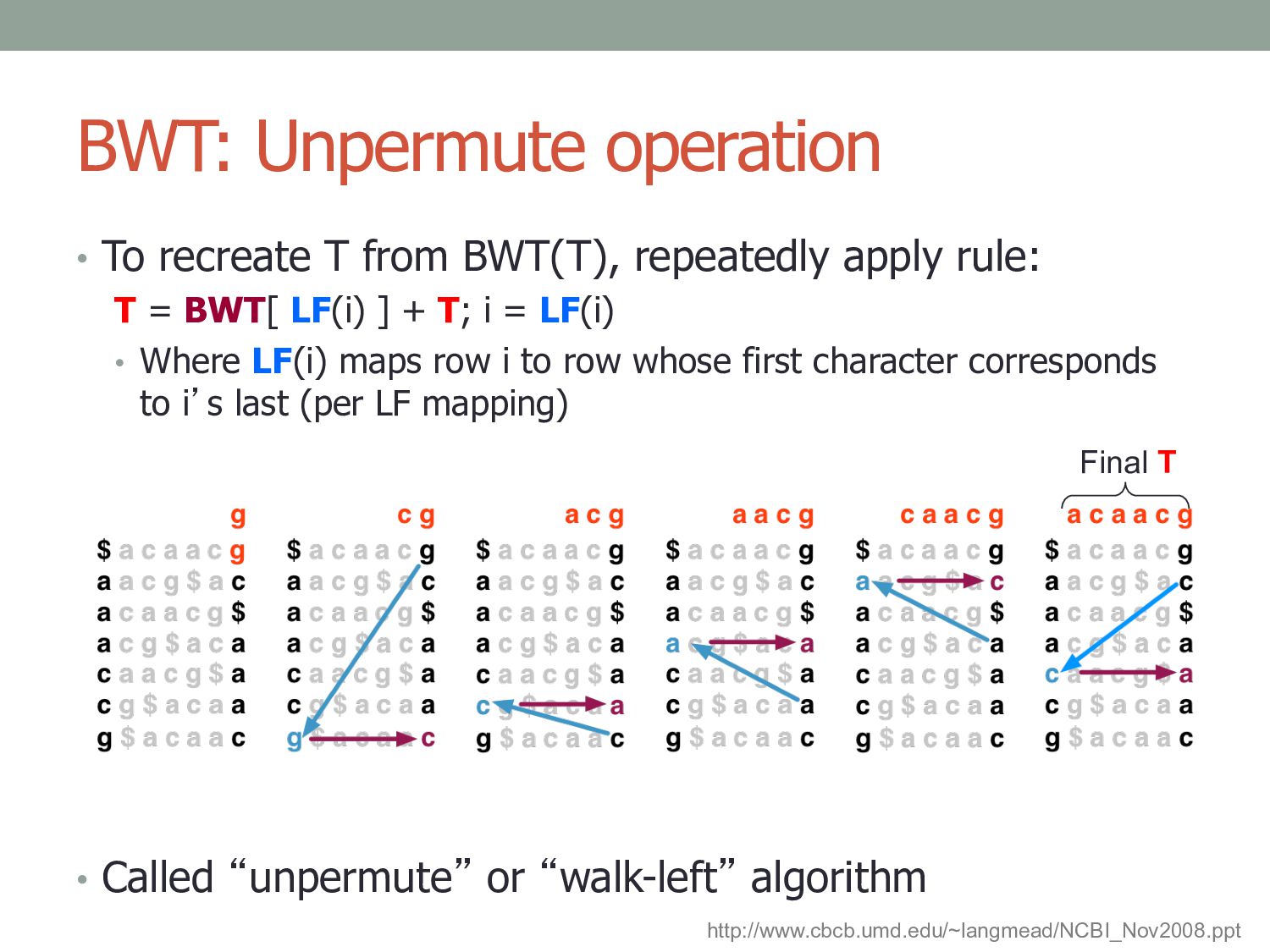
apply rule: T = BWT[ LF(i) ] + T; i = LF(i) • Where LF(i) maps row i to row whose first character corresponds to i’s last (per LF mapping) • Called “unpermute” or “walk-left” algorithm Final T http://www.cbcb.umd.edu/~langmead/NCBI_Nov2008.ppt
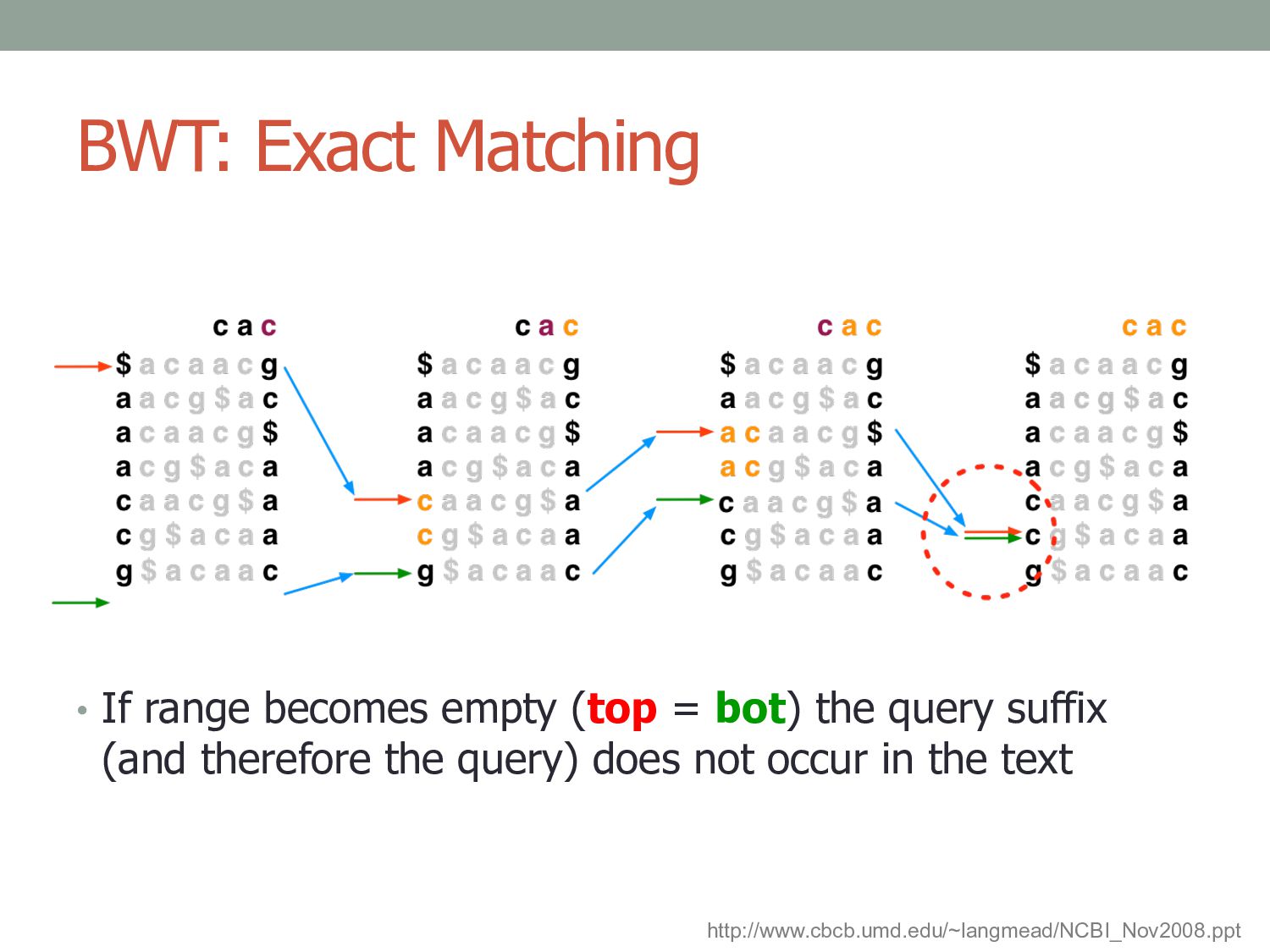
BWT(T), repeatedly apply rule: top = LF(top, qc); bot = LF(bot, qc) • Where qc is the next character in Q (right-to-left) and LF(i, qc) maps row i to the row whose first character corresponds to i’s last character as if it were qc http://www.cbcb.umd.edu/~langmead/NCBI_Nov2008.ppt
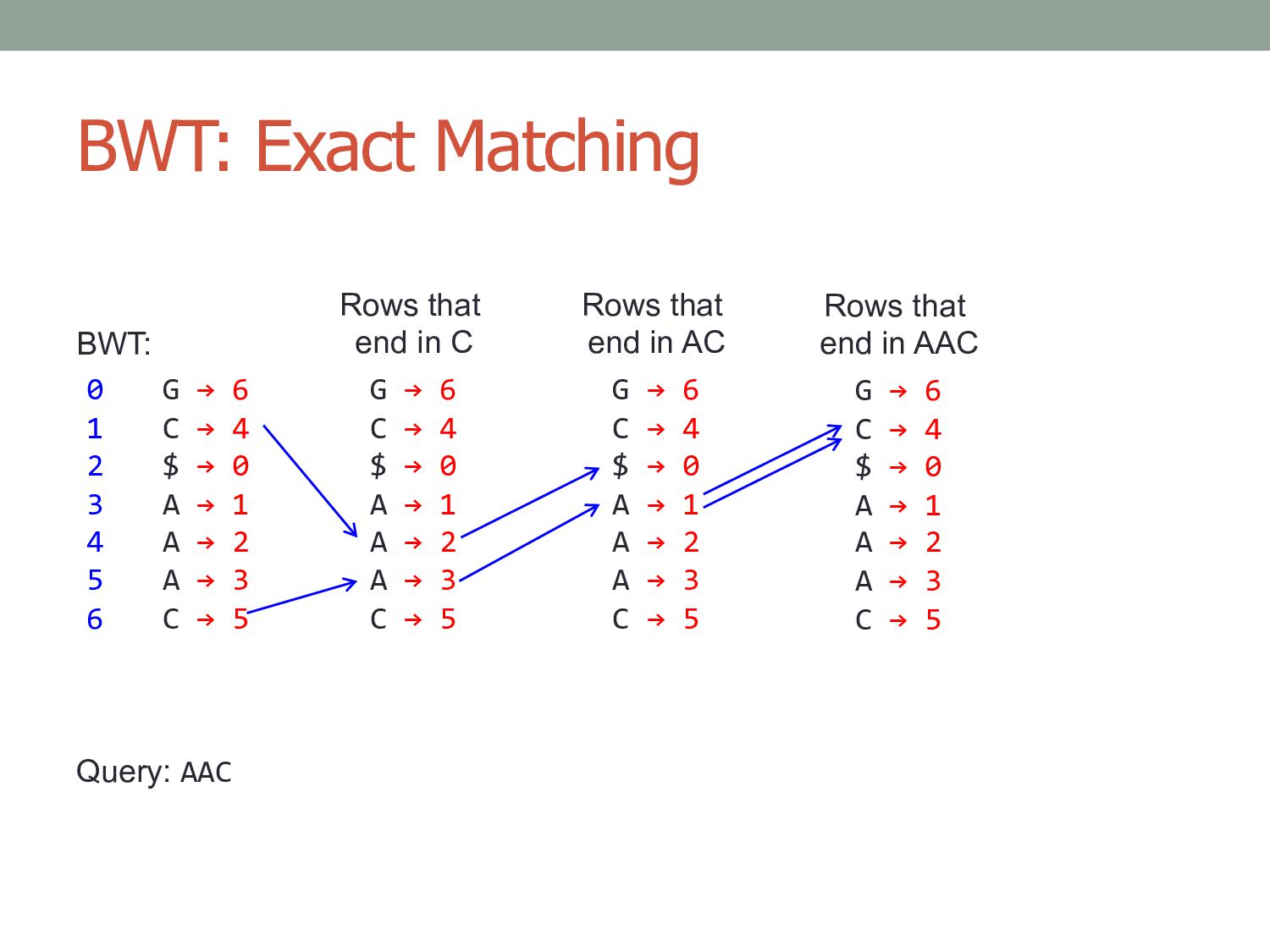
→ 0 A → 1 A → 2 A → 3 C → 5 BWT: Query: AAC 0 1 2 3 4 5 6 Rows that end in C G → 6 C → 4 $ → 0 A → 1 A → 2 A → 3 C → 5 Rows that end in AC G → 6 C → 4 $ → 0 A → 1 A → 2 A → 3 C → 5 Rows that end in AAC G → 6 C → 4 $ → 0 A → 1 A → 2 A → 3 C → 5
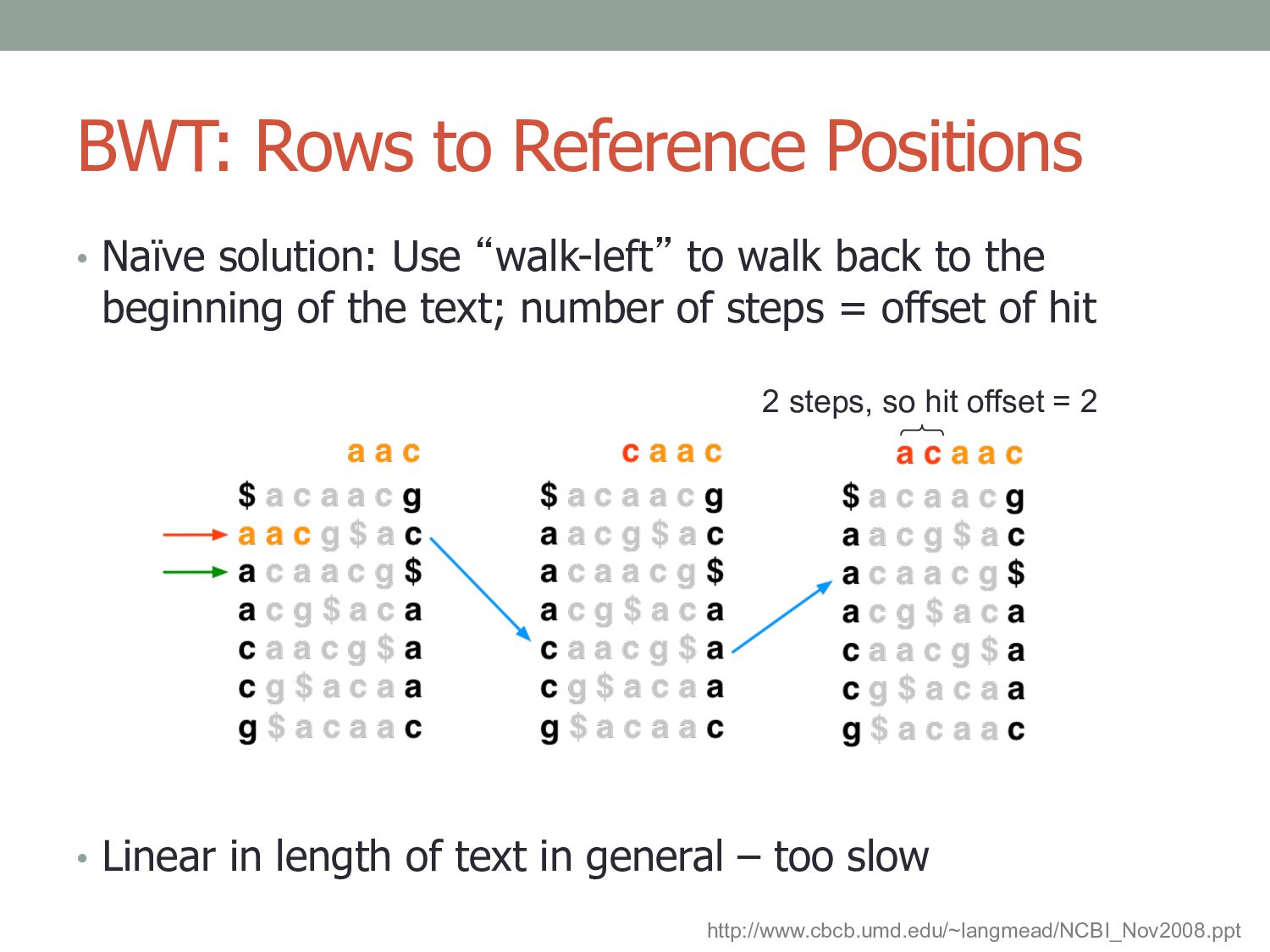
to walk back to the beginning of the text; number of steps = offset of hit • Linear in length of text in general – too slow 2 steps, so hit offset = 2 http://www.cbcb.umd.edu/~langmead/NCBI_Nov2008.ppt
• “walk left” to next marked row to the left • Bowtie marks every 32nd row by default (configurable) Rows to Reference Positions 1 step offset = 1 Hit offset = 1 + 1 = 2 http://www.cbcb.umd.edu/~langmead/NCBI_Nov2008.ppt
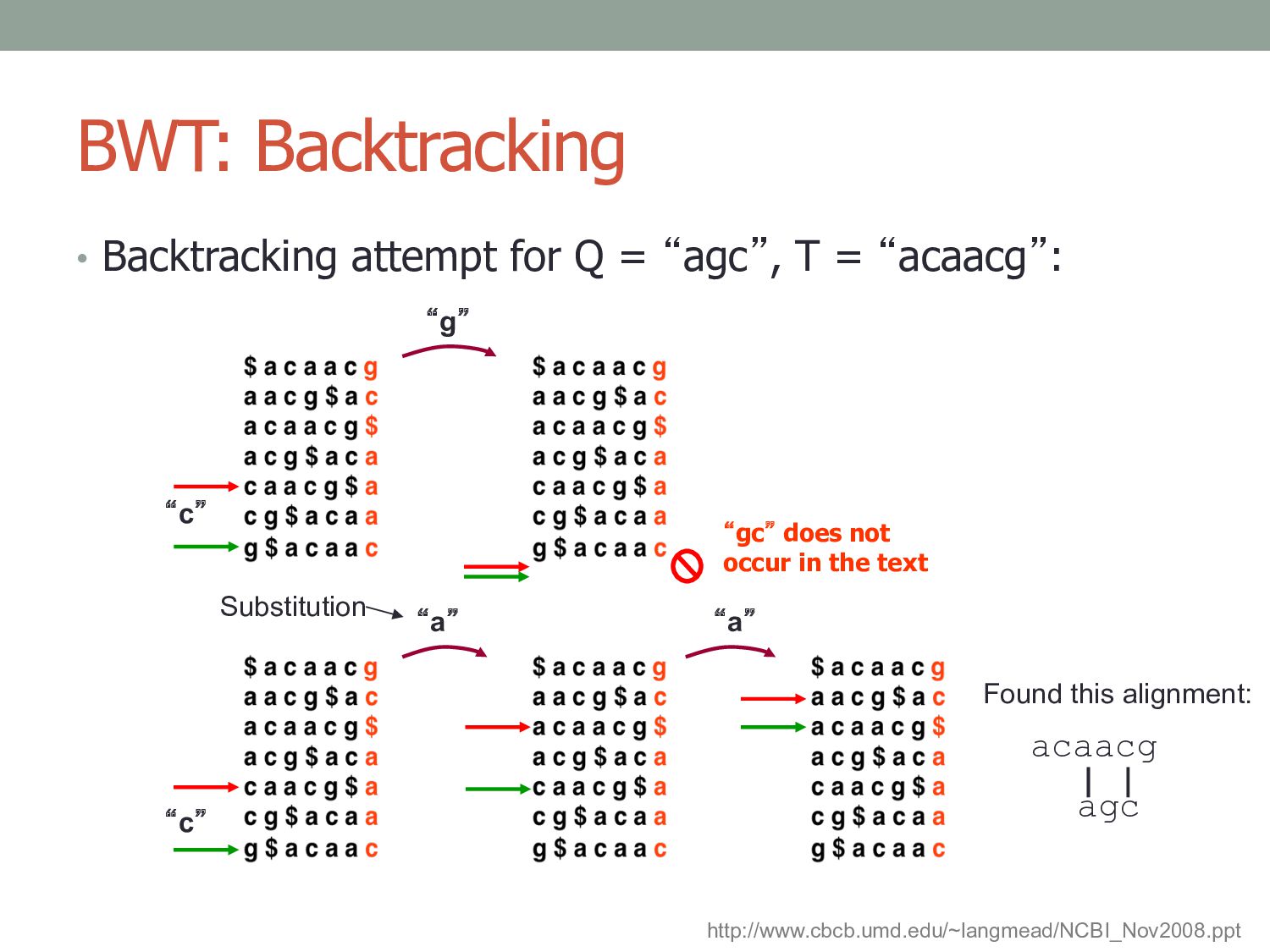
= “agc” in T = “acaacg”: • Instead of giving up, try to “backtrack” to a previous position and try a different base “gc” does not occur in the text “g” “c” http://www.cbcb.umd.edu/~langmead/NCBI_Nov2008.ppt
= “acaacg”: Found this alignment: acaacg agc “g” “a” “a” “c” “c” “gc” does not occur in the text Substitution http://www.cbcb.umd.edu/~langmead/NCBI_Nov2008.ppt
C T $ L-F Row à 4 à 5 à 8 à 9 à 1 à 6 à 2 à 3 à 7 à 10 à 0 0 1 2 3 4 5 6 7 8 9 10 C C G T A C A A C T $ L-F à 4 à 5 à 8 à 9 à 1 à 6 à 2 à 3 à 7 à 10 à 0 C C G T A C A A C T $ L-F à 4 à 5 à 8 à 9 à 1 à 6 à 2 à 3 à 7 à 10 à 0 C C G T A C A A C T $ L-F à 4 à 5 à 8 à 9 à 1 à 6 à 2 à 3 à 7 à 10 à 0 C C G T A C A A C T $ L-F à 4 à 5 à 8 à 9 à 1 à 6 à 2 à 3 à 7 à 10 à 0 C C G T A C A A C T $ L-F à 4 à 5 à 8 à 9 à 1 à 6 à 2 à 3 à 7 à 10 à 0 C C G T A C A A C T $ L-F à 4 à 5 à 8 à 9 à 1 à 6 à 2 à 3 à 7 à 10 à 0 C C G T A C A A C T $ L-F à 4 à 5 à 8 à 9 à 1 à 6 à 2 à 3 à 7 à 10 à 0 C C G T A C A A C T $ L-F à 4 à 5 à 8 à 9 à 1 à 6 à 2 à 3 à 7 à 10 à 0 C C G T A C A A C T $ L-F à 4 à 5 à 8 à 9 à 1 à 6 à 2 à 3 à 7 à 10 à 0 Map: CGAC
C T $ L-F Row à 4 à 5 à 8 à 9 à 1 à 6 à 2 à 3 à 7 à 10 à 0 0 1 2 3 4 5 6 7 8 9 10 C C G T A C A A C T $ L-F à 4 à 5 à 8 à 9 à 1 à 6 à 2 à 3 à 7 à 10 à 0 C C G T A C A A C T $ L-F à 4 à 5 à 8 à 9 à 1 à 6 à 2 à 3 à 7 à 10 à 0 C C G T A C A A C T $ L-F à 4 à 5 à 8 à 9 à 1 à 6 à 2 à 3 à 7 à 10 à 0 C C G T A C A A C T $ L-F à 4 à 5 à 8 à 9 à 1 à 6 à 2 à 3 à 7 à 10 à 0 C C G T A C A A C T $ L-F à 4 à 5 à 8 à 9 à 1 à 6 à 2 à 3 à 7 à 10 à 0 C C G T A C A A C T $ L-F à 4 à 5 à 8 à 9 à 1 à 6 à 2 à 3 à 7 à 10 à 0 C C G T A C A A C T $ L-F à 4 à 5 à 8 à 9 à 1 à 6 à 2 à 3 à 7 à 10 à 0 C C G T A C A A C T $ L-F à 4 à 5 à 8 à 9 à 1 à 6 à 2 à 3 à 7 à 10 à 0 C C G T A C A A C T $ L-F à 4 à 5 à 8 à 9 à 1 à 6 à 2 à 3 à 7 à 10 à 0 Map: TTGA
C T $ L-F Row à 4 à 5 à 8 à 9 à 1 à 6 à 2 à 3 à 7 à 10 à 0 0 1 2 3 4 5 6 7 8 9 10 C C G T A C A A C T $ L-F à 4 à 5 à 8 à 9 à 1 à 6 à 2 à 3 à 7 à 10 à 0 C C G T A C A A C T $ L-F à 4 à 5 à 8 à 9 à 1 à 6 à 2 à 3 à 7 à 10 à 0 C C G T A C A A C T $ L-F à 4 à 5 à 8 à 9 à 1 à 6 à 2 à 3 à 7 à 10 à 0 C C G T A C A A C T $ L-F à 4 à 5 à 8 à 9 à 1 à 6 à 2 à 3 à 7 à 10 à 0 C C G T A C A A C T $ L-F à 4 à 5 à 8 à 9 à 1 à 6 à 2 à 3 à 7 à 10 à 0 C C G T A C A A C T $ L-F à 4 à 5 à 8 à 9 à 1 à 6 à 2 à 3 à 7 à 10 à 0 C C G T A C A A C T $ L-F à 4 à 5 à 8 à 9 à 1 à 6 à 2 à 3 à 7 à 10 à 0 C C G T A C A A C T $ L-F à 4 à 5 à 8 à 9 à 1 à 6 à 2 à 3 à 7 à 10 à 0 Reconstruct Genome C C G T A C A A C T $ L-F à 4 à 5 à 8 à 9 à 1 à 6 à 2 à 3 à 7 à 10 à 0 C C G T A C A A C T $ L-F à 4 à 5 à 8 à 9 à 1 à 6 à 2 à 3 à 7 à 10 à 0 C C G T A C A A C T $ L-F à 4 à 5 à 8 à 9 à 1 à 6 à 2 à 3 à 7 à 10 à 0 C C G T A C A A C T $ L-F à 4 à 5 à 8 à 9 à 1 à 6 à 2 à 3 à 7 à 10 à 0 C C G T A C A A C T $ L-F à 4 à 5 à 8 à 9 à 1 à 6 à 2 à 3 à 7 à 10 à 0 C C G T A C A A C T $ L-F à 4 à 5 à 8 à 9 à 1 à 6 à 2 à 3 à 7 à 10 à 0 Row 0 1 2 3 4 5 6 7 8 9 10
Sort & run length encoding? TACGTAACGATACGAT à AAAAAACCCGGGTTTT à 6A3C3G4T Compressible, but not reversible! • Genomes don’t contain many runs, but they do contain repeats. Can we convert a repeat-rich genome into a (reversible) string with many runs?
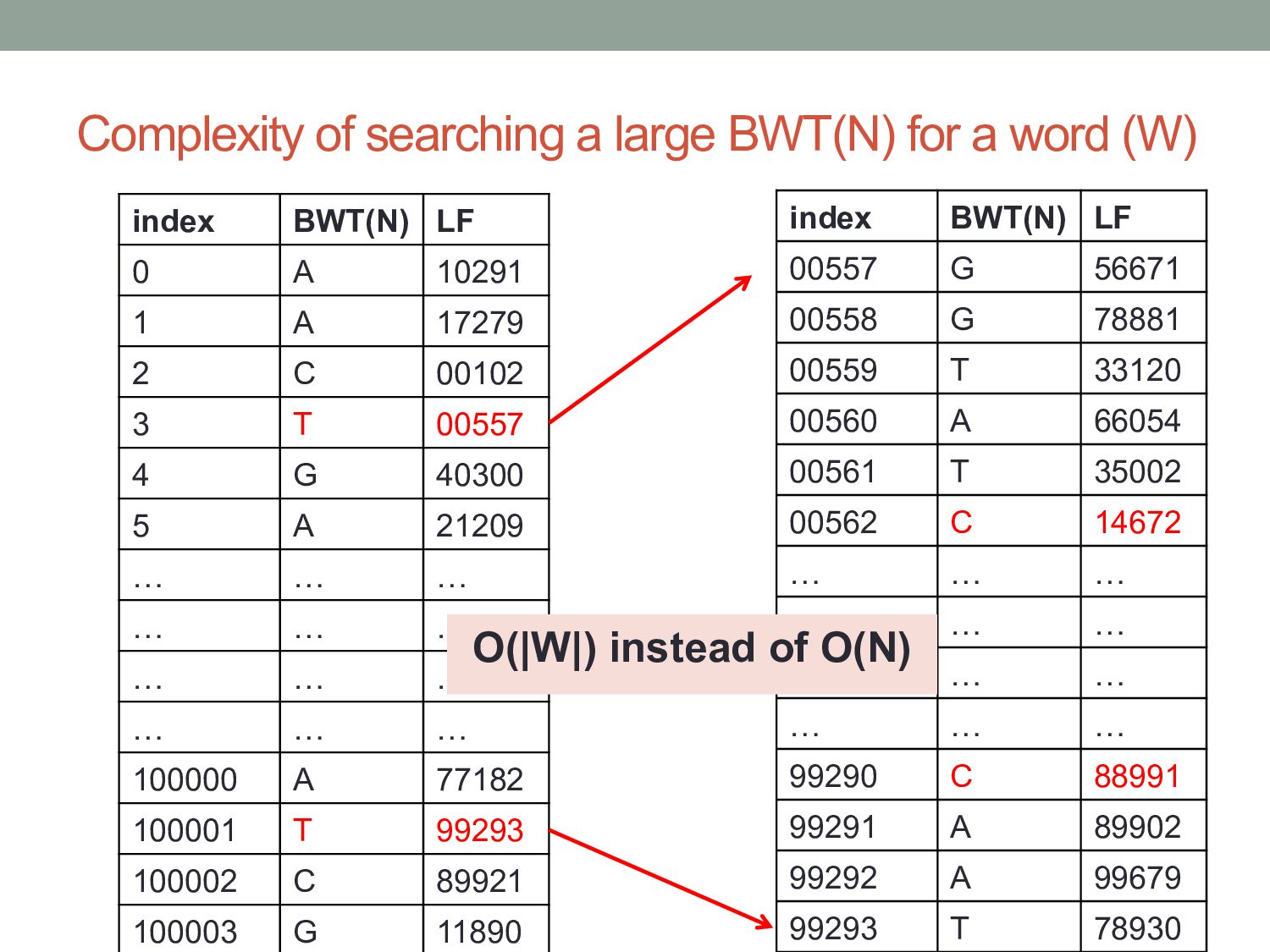
index BWT(N) LF 0 A 10291 1 A 17279 2 C 00102 3 T 00557 4 G 40300 5 A 21209 … … … … … … … … … … … … 100000 A 77182 100001 T 99293 100002 C 89921 100003 G 11890 index BWT(N) LF 00557 G 56671 00558 G 78881 00559 T 33120 00560 A 66054 00561 T 35002 00562 C 14672 … … … … … … … … … … … … 99290 C 88991 99291 A 89902 99292 A 99679 99293 T 78930 O(|W|) instead of O(N)
transformation of a string. • BWT enables fast exact matching of short strings in a longer string. • See Chapter 5, Bioinformatics & Functional Genomics (p196-7) • See Chapter 7, Compeau & Pevzner (p325 - 350)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}