Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Machine learning and system design
Search
shibuiwilliam
March 15, 2022
Technology
99
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Machine learning and system design
about machine learning system design for web EC marketplace.
https://techplay.jp/event/768641
shibuiwilliam
March 15, 2022
More Decks by shibuiwilliam
See All by shibuiwilliam
LLMやAIエージェントをソフトウェアに組み込むプラクティス
shibuiwilliam
2
450
From Prompt Engineering to Loop Engineering
shibuiwilliam
1
380
OntologyとLLMOps
shibuiwilliam
3
90
Rule repository
shibuiwilliam
3
66
LLM時代の検索アーキテクチャと技術的意思決定
shibuiwilliam
5
2.5k
Why Open Dataspacesのまとめ
shibuiwilliam
2
100
マルチモーダル非構造データとの闘い
shibuiwilliam
2
690
飽くなき自動生成への挑戦
shibuiwilliam
1
94
AIエージェントのメモリについて
shibuiwilliam
2
800
Other Decks in Technology
See All in Technology
Webアプリ認証の全体像 / The Big Picture of Web App Authentication
kitano_yuichi
1
450
AIエージェントがあれば技術書なんてすぐ書けるでしょ→無理でした
watany
6
500
AI時代におけるテストの基礎の再定義 / Rethinking the Fundamentals of Testing in the AI Era
mineo_matsuya
15
5.7k
伝票作成AIエージェントを支える、LLMOpsとインフラの選択肢 / AICon2026_takeda
rakus_dev
0
300
なぜ、あなたのAPIは使われないのか? AX時代の設計原則、ガードレール、運用体制
yokawasa
1
240
AWS環境のセキュリティ不安を解消した企業事例 ~よくある課題と対策を一挙公開~
asanoharuki
0
190
エンタープライズデータへ安全につなぐ Production-ready なエージェント設計 ― AI × MCP リファレンスアーキテクチャ ― #AIDevDay
cdataj
1
110
データベース研修【MIXI 26新卒技術研修】
mixi_engineers
PRO
1
340
MCPをつなげて作る組織横断のAIエージェント基盤
tsubakimoto_s
0
160
キャリアLT会#3
beli68
2
270
データ活用研修 問いの発見と仮説構築【MIXI 26新卒技術研修】
mixi_engineers
PRO
1
330
Flutter研修【MIXI 26新卒技術研修】
mixi_engineers
PRO
1
150
Featured
See All Featured
Paper Plane (Part 1)
katiecoart
PRO
1
9.8k
Applied NLP in the Age of Generative AI
inesmontani
PRO
4
2.4k
Self-Hosted WebAssembly Runtime for Runtime-Neutral Checkpoint/Restore in Edge–Cloud Continuum
chikuwait
0
660
Optimising Largest Contentful Paint
csswizardry
37
3.8k
The Anti-SEO Checklist Checklist. Pubcon Cyber Week
ryanjones
0
190
Building AI with AI
inesmontani
PRO
1
1.1k
Stop Working from a Prison Cell
hatefulcrawdad
274
21k
How to Build an AI Search Optimization Roadmap - Criteria and Steps to Take #SEOIRL
aleyda
1
2.1k
I Don’t Have Time: Getting Over the Fear to Launch Your Podcast
jcasabona
34
2.8k
The State of eCommerce SEO: How to Win in Today's Products SERPs - #SEOweek
aleyda
2
11k
Fight the Zombie Pattern Library - RWD Summit 2016
marcelosomers
234
17k
Evolution of real-time – Irina Nazarova, EuRuKo, 2024
irinanazarova
9
1.5k
Transcript
1 機械学習とシステムデザイン 2020/03/02 Mercari AI & Search Engineering Team shibui
yusuke
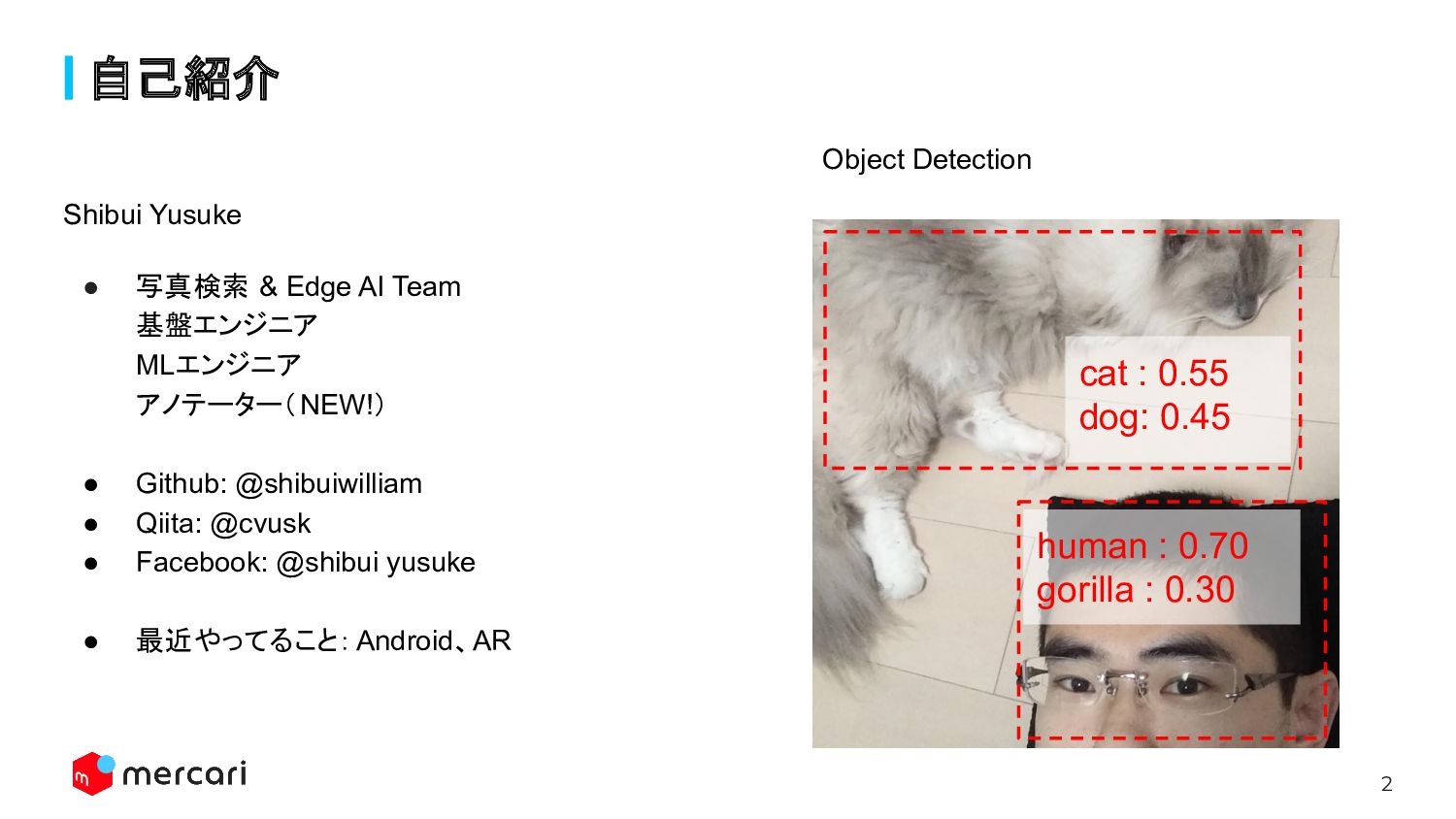
2 自己紹介 cat : 0.55 dog: 0.45 human : 0.70
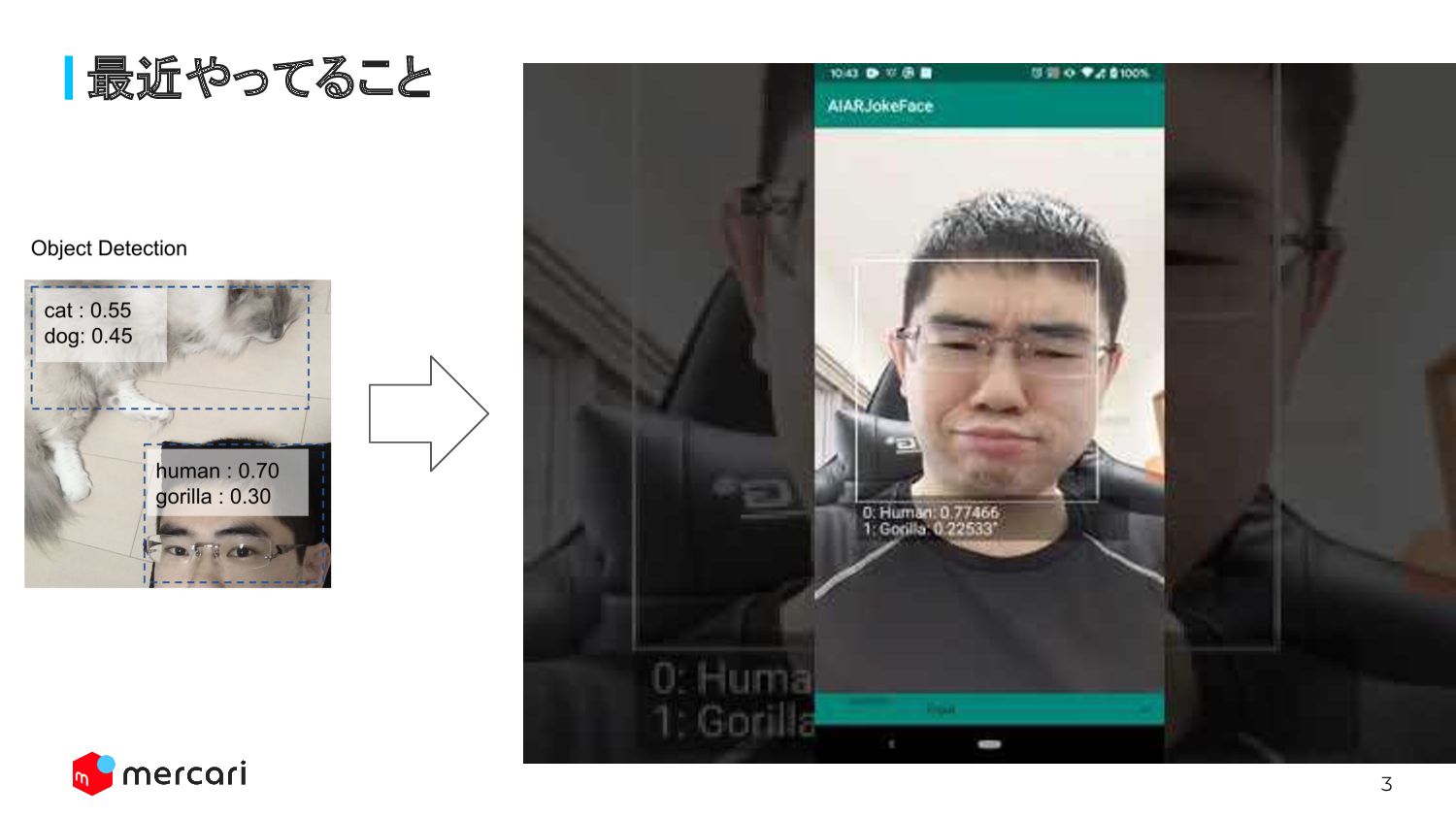
gorilla : 0.30 Object Detection Shibui Yusuke • 写真検索 & Edge AI Team 基盤エンジニア MLエンジニア アノテーター(NEW!) • Github: @shibuiwilliam • Qiita: @cvusk • Facebook: @shibui yusuke • 最近やってること:Android、AR
3 最近やってること
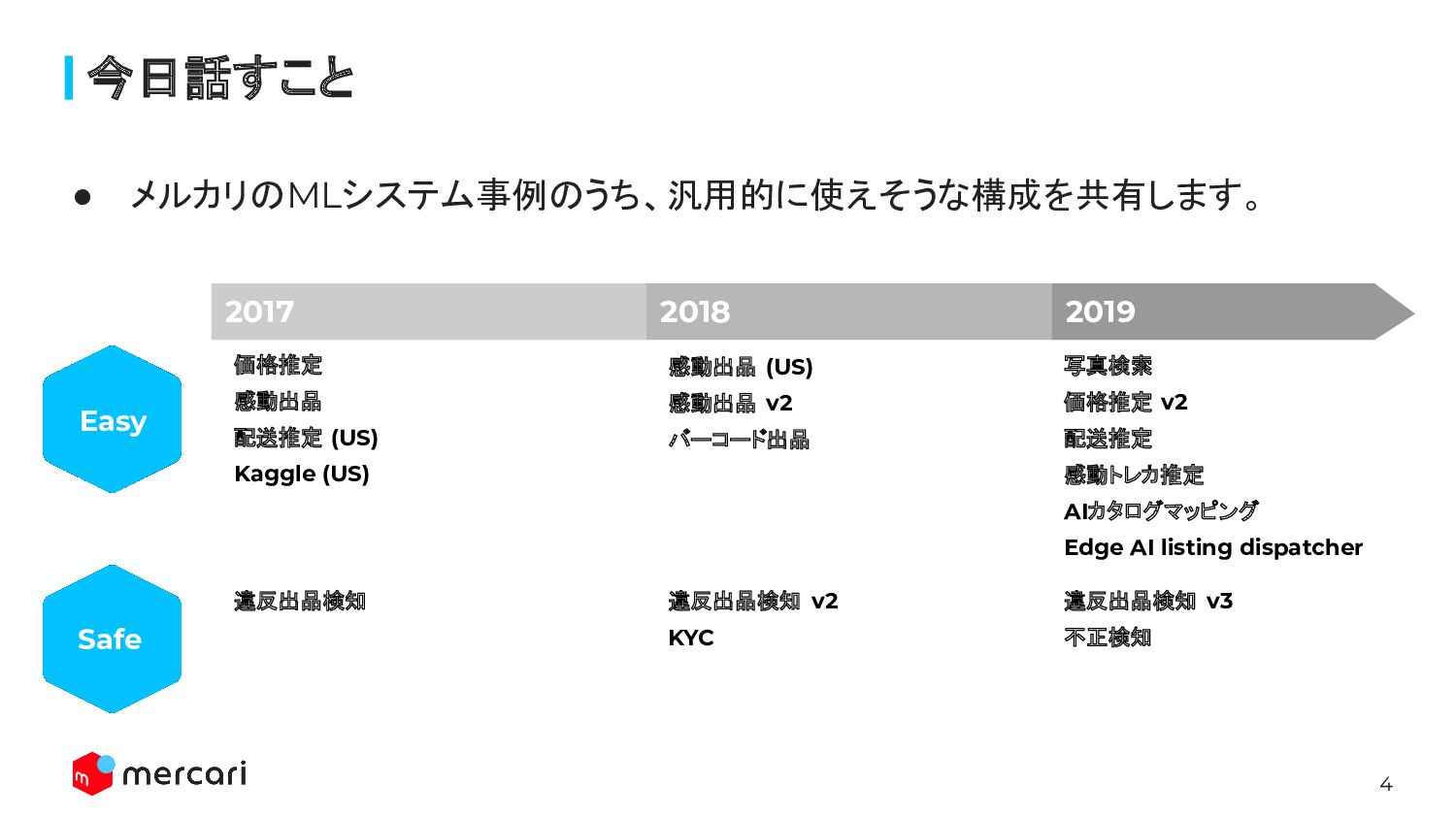
4 • メルカリのMLシステム事例のうち、汎用的に使えそうな構成を共有します。 今日話すこと Easy Safe 違反出品検知 価格推定 感動出品 配送推定
(US) Kaggle (US) 感動出品 (US) 感動出品 v2 バーコード出品 違反出品検知 v2 KYC 違反出品検知 v3 不正検知 写真検索 価格推定 v2 配送推定 感動トレカ推定 AIカタログマッピング Edge AI listing dispatcher 2017 2018 2019
5 メルカリのワークフロー 売れるかな? 出品する 探す 買う 配送する • ユーザの売る・買うをつなぐC2Cマーケットプレイス・プラットフォーム。 出品者
購入者
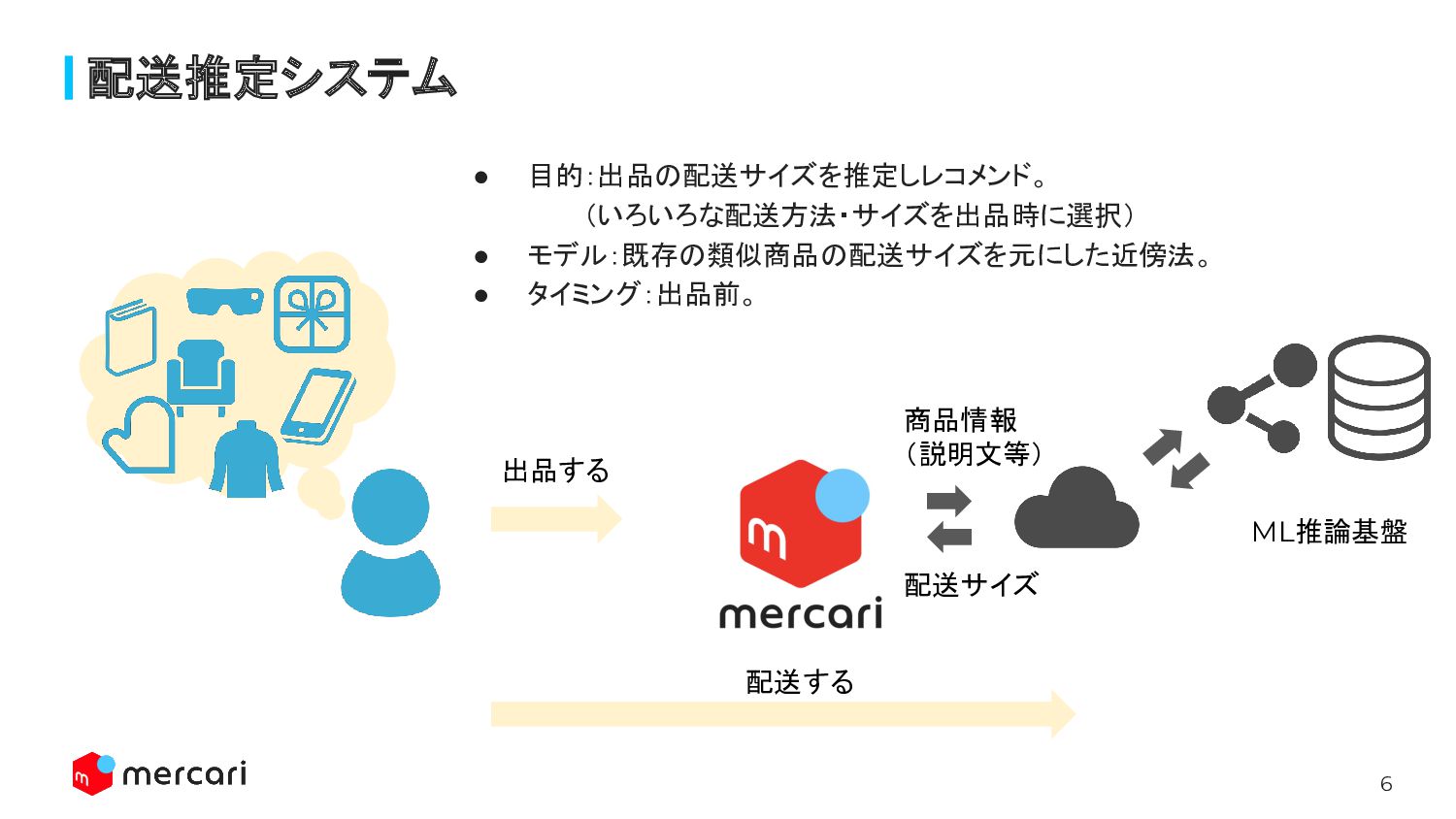
6 • 目的:出品の配送サイズを推定しレコメンド。 (いろいろな配送方法・サイズを出品時に選択) • モデル:既存の類似商品の配送サイズを元にした近傍法。 • タイミング:出品前。 配送推定システム 出品する
配送する ML推論基盤 商品情報 (説明文等) 配送サイズ
7 • 解決したい課題: ◦ 1リクエストに1推論を返すサービスを作りたい。 • 解決策: ◦ GET/POSTを受け付けるREST APIに推論モデルを組み込
む。 • 利点: ◦ シンプルな構成のため、開発、運用が簡単。 ◦ スケールアウトや障害箇所の特定が容易。 • 注意点: ◦ 推論モデルのサイズ次第でレスポンス速度が上下する。 ◦ レスポンス内容: ▪ 分類の場合、全確率値を返すか、 top-kを返すか。 ▪ 確率に応じたクライアントの動作。 シンプルなWeb API クライアント 推論REST API
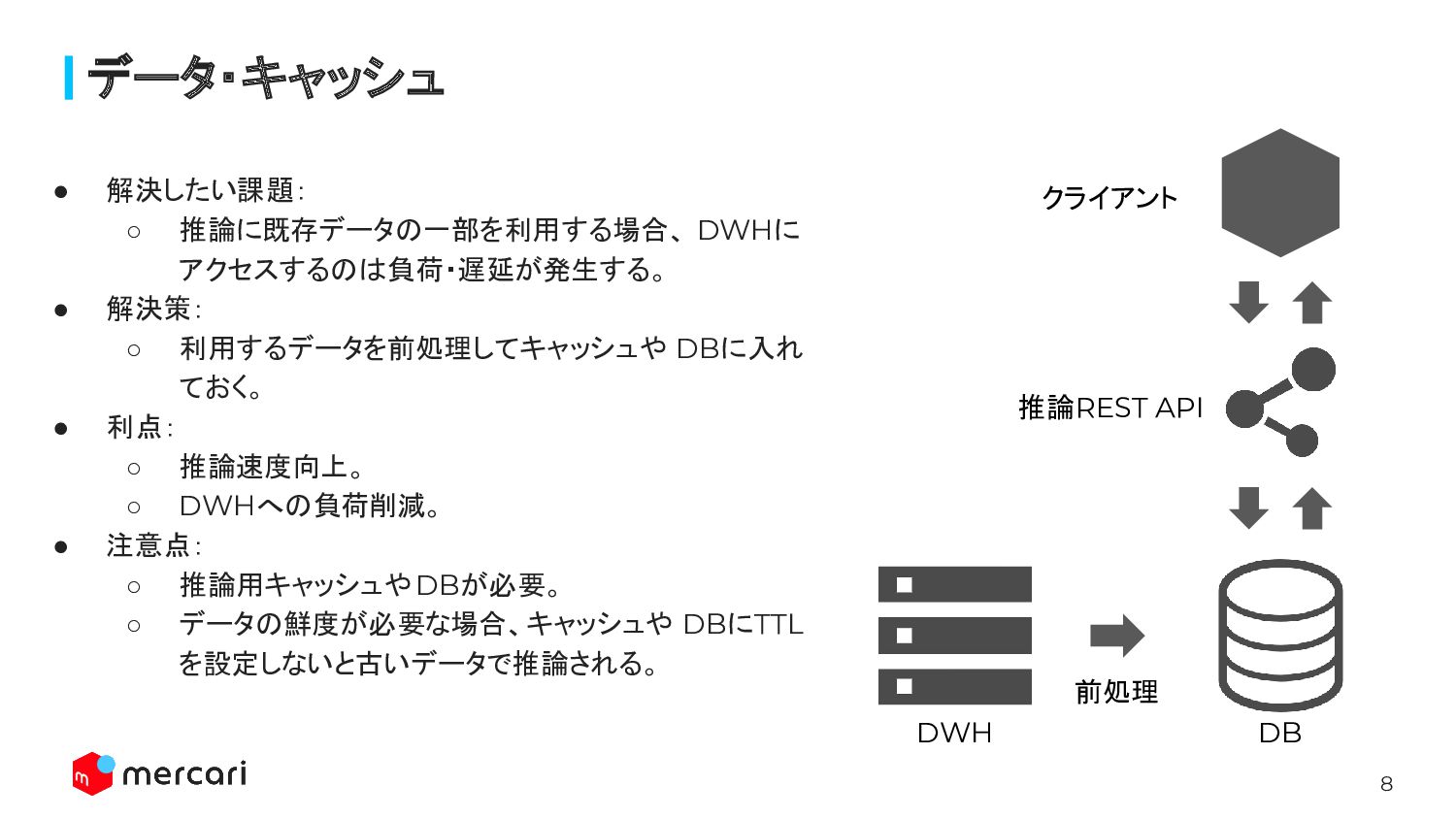
8 • 解決したい課題: ◦ 推論に既存データの一部を利用する場合、 DWHに アクセスするのは負荷・遅延が発生する。 • 解決策: ◦
利用するデータを前処理してキャッシュや DBに入れ ておく。 • 利点: ◦ 推論速度向上。 ◦ DWHへの負荷削減。 • 注意点: ◦ 推論用キャッシュやDBが必要。 ◦ データの鮮度が必要な場合、キャッシュや DBにTTL を設定しないと古いデータで推論される。 データ・キャッシュ クライアント 推論REST API DB DWH 前処理
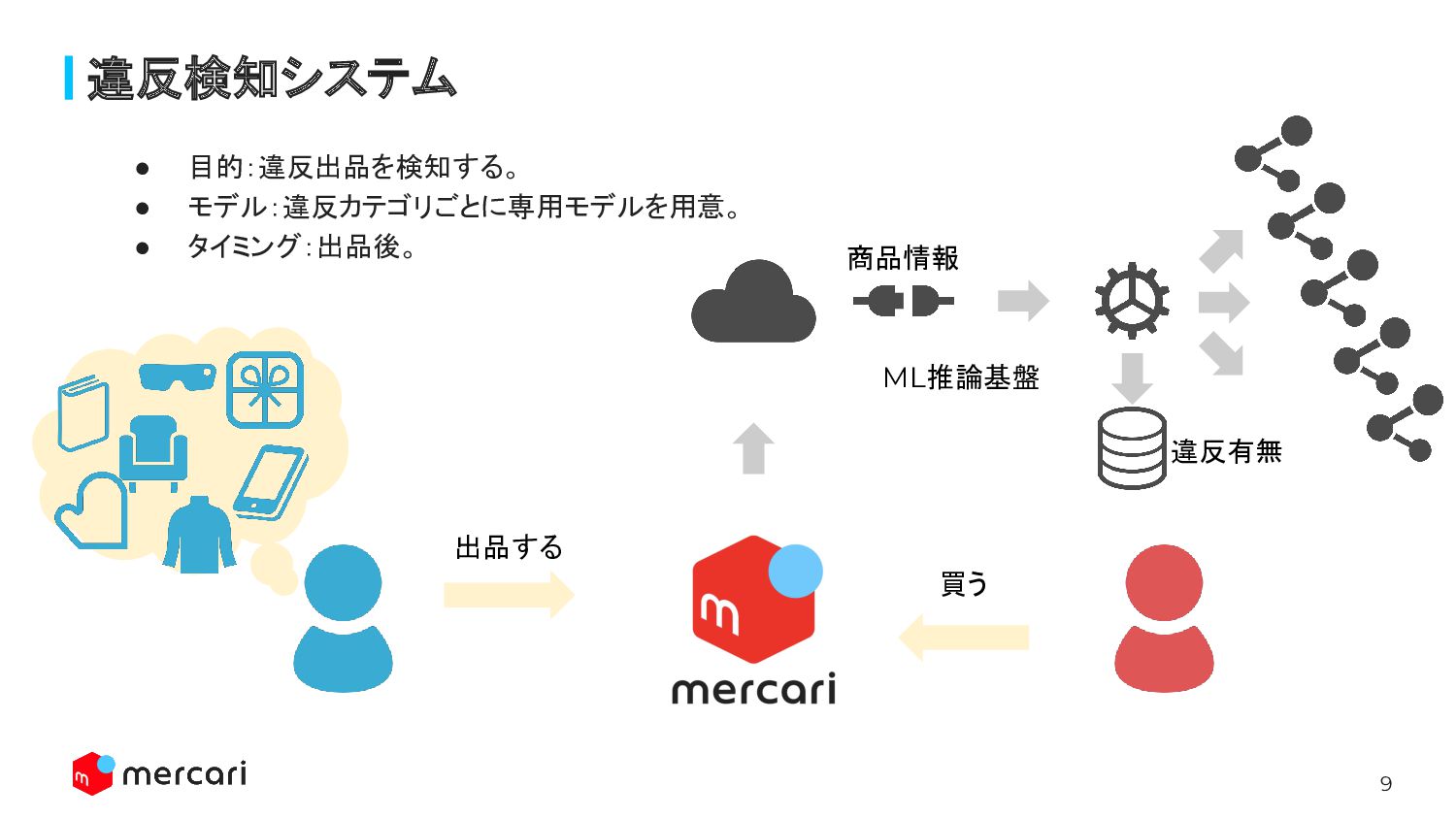
9 違反検知システム 出品する 買う • 目的:違反出品を検知する。 • モデル:違反カテゴリごとに専用モデルを用意。 • タイミング:出品後。
ML推論基盤 商品情報 違反有無
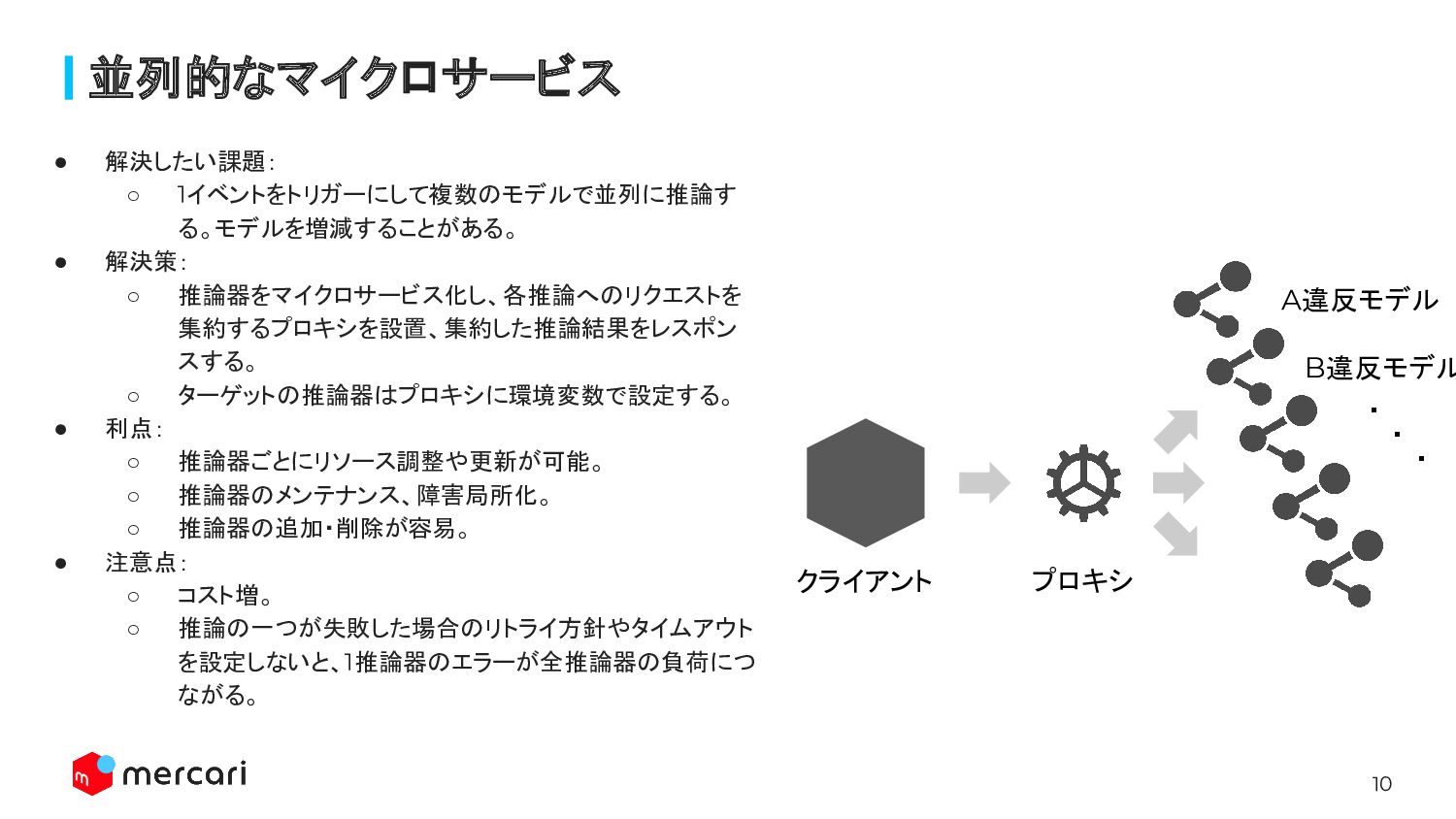
10 並列的なマイクロサービス • 解決したい課題: ◦ 1イベントをトリガーにして複数のモデルで並列に推論す る。モデルを増減することがある。 • 解決策: ◦
推論器をマイクロサービス化し、各推論へのリクエストを 集約するプロキシを設置、集約した推論結果をレスポン スする。 ◦ ターゲットの推論器はプロキシに環境変数で設定する。 • 利点: ◦ 推論器ごとにリソース調整や更新が可能。 ◦ 推論器のメンテナンス、障害局所化。 ◦ 推論器の追加・削除が容易。 • 注意点: ◦ コスト増。 ◦ 推論の一つが失敗した場合のリトライ方針やタイムアウト を設定しないと、1推論器のエラーが全推論器の負荷につ ながる。 クライアント プロキシ A違反モデル B違反モデル ・ ・ ・
11 非同期推論 • 解決したい課題: ◦ 推論の呼び出し元と出力先が違う場合、同期的 に処理すると遅延・障害の原因になる。 • 解決策: ◦
呼び出し元と推論器の間にキューやメッセージ ングを置き、疎結合にする。 • 利点: ◦ 各コンポーネントを分離可能。 ◦ 推論器で障害が発生してもリトライ可能。 • 注意点: ◦ 推論の順番は保証されないため、入力やデータ に対する推論順が必要なワークフローでは注意 が必要。 ◦ 推論エラー時のリトライポリシー。 A違反モデル B違反モデル ・ ・ ・ プロキシ メッセージング 出力先
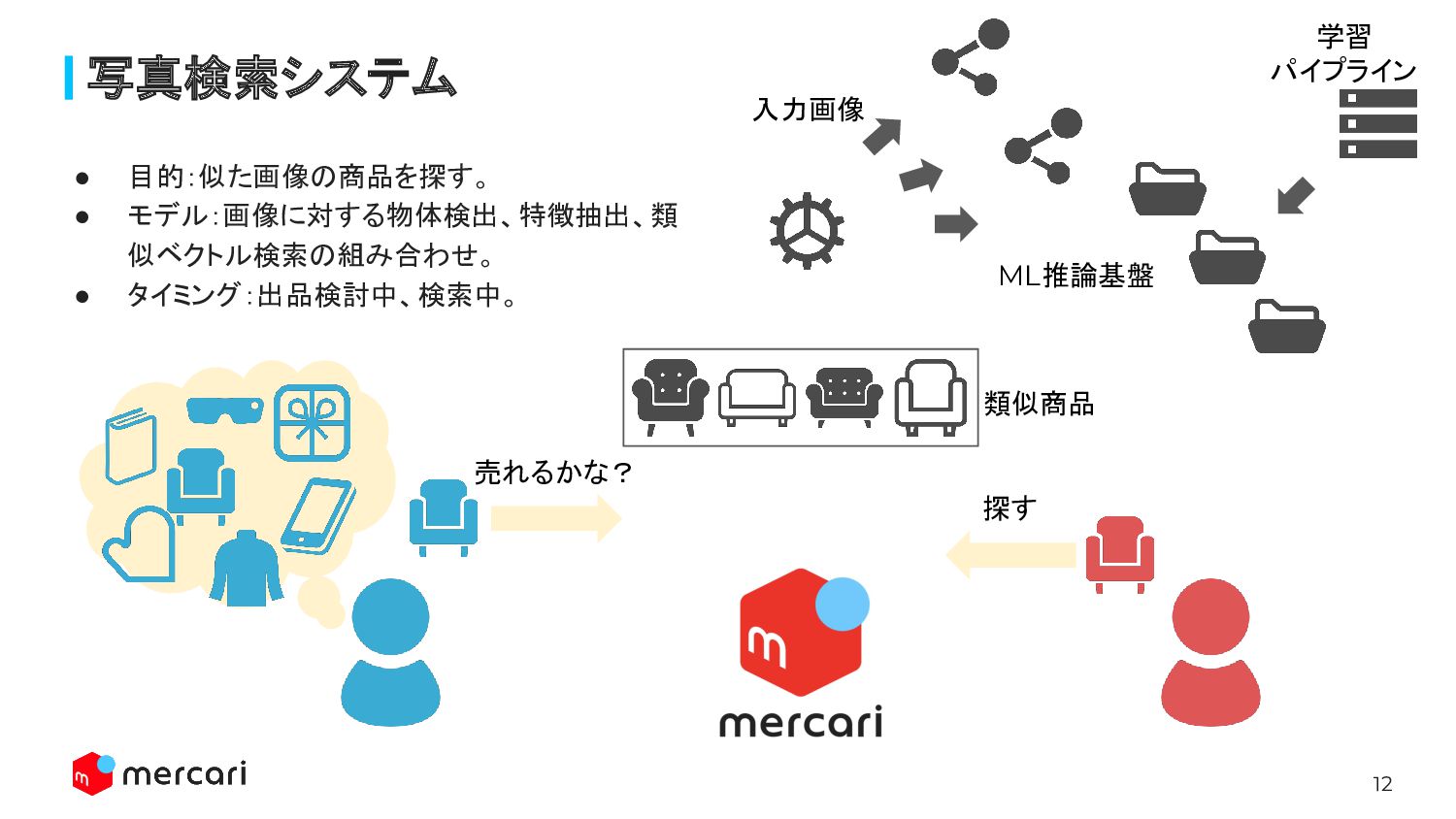
12 写真検索システム 売れるかな? 探す • 目的:似た画像の商品を探す。 • モデル:画像に対する物体検出、特徴抽出、類 似ベクトル検索の組み合わせ。 •
タイミング:出品検討中、検索中。 ML推論基盤 学習 パイプライン 入力画像 類似商品
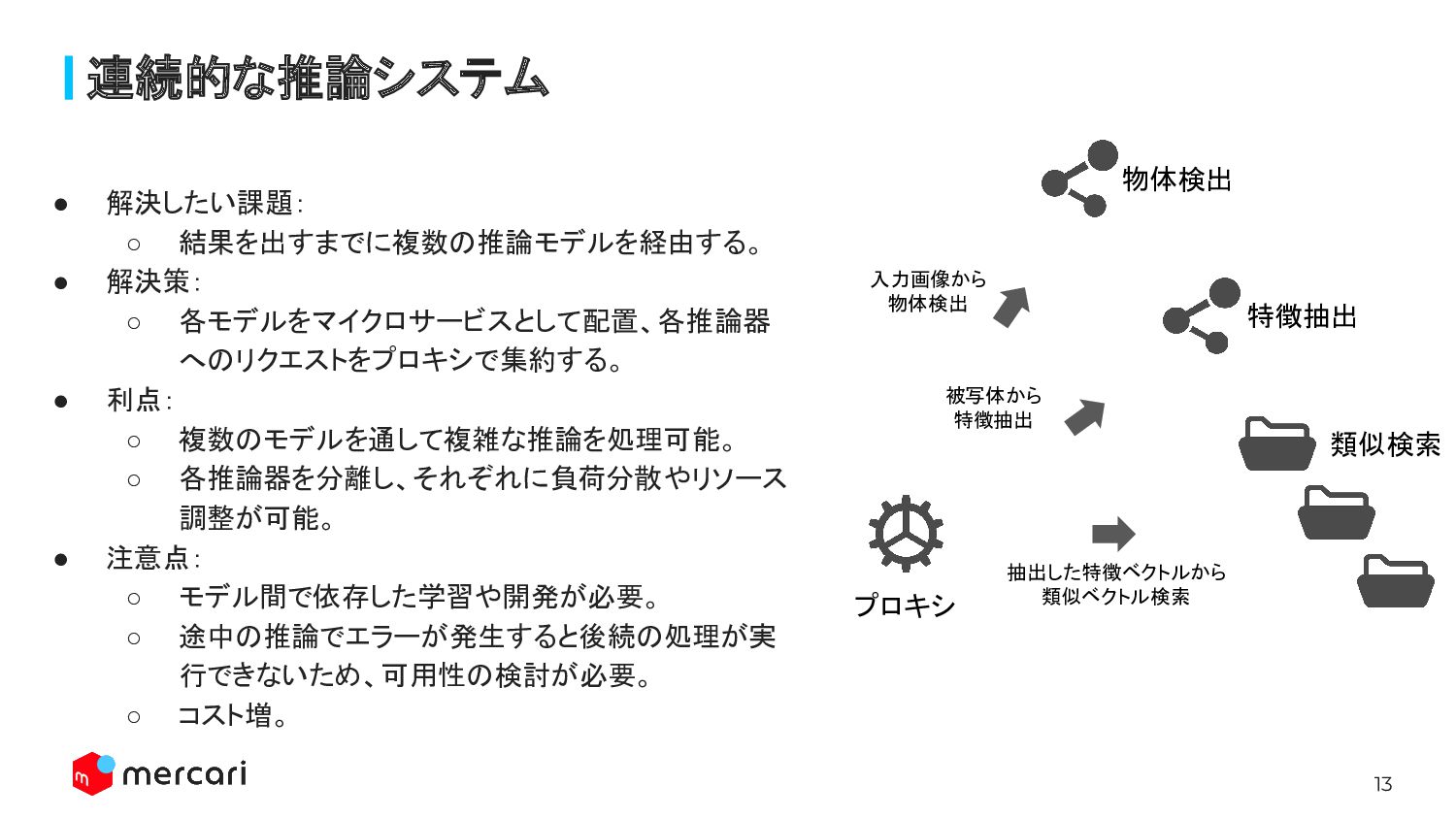
13 連続的な推論システム • 解決したい課題: ◦ 結果を出すまでに複数の推論モデルを経由する。 • 解決策: ◦ 各モデルをマイクロサービスとして配置、各推論器
へのリクエストをプロキシで集約する。 • 利点: ◦ 複数のモデルを通して複雑な推論を処理可能。 ◦ 各推論器を分離し、それぞれに負荷分散やリソース 調整が可能。 • 注意点: ◦ モデル間で依存した学習や開発が必要。 ◦ 途中の推論でエラーが発生すると後続の処理が実 行できないため、可用性の検討が必要。 ◦ コスト増。 プロキシ 物体検出 特徴抽出 類似検索 入力画像から 物体検出 被写体から 特徴抽出 抽出した特徴ベクトルから 類似ベクトル検索
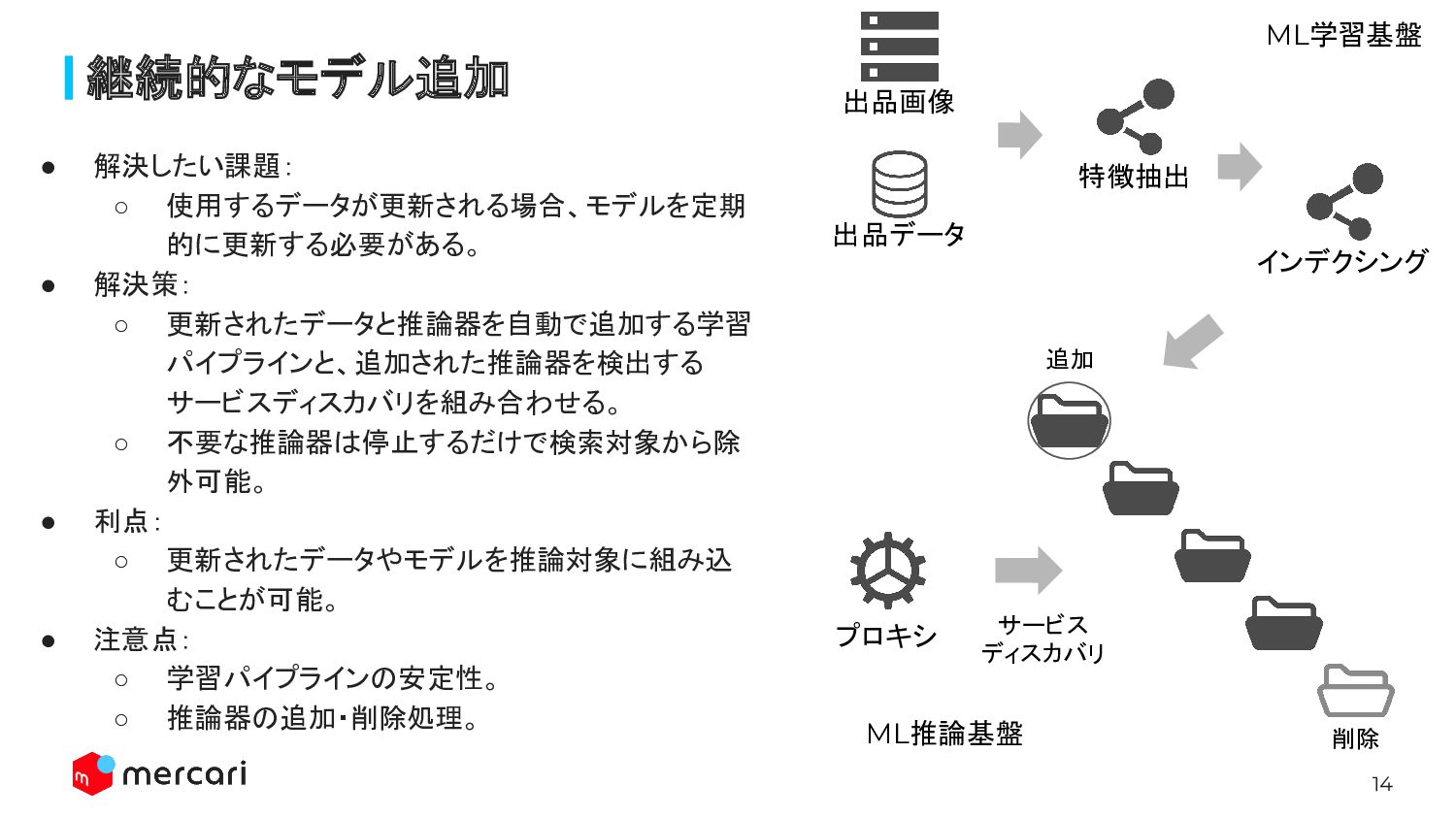
14 継続的なモデル追加 • 解決したい課題: ◦ 使用するデータが更新される場合、モデルを定期 的に更新する必要がある。 • 解決策: ◦
更新されたデータと推論器を自動で追加する学習 パイプラインと、追加された推論器を検出する サービスディスカバリを組み合わせる。 ◦ 不要な推論器は停止するだけで検索対象から除 外可能。 • 利点: ◦ 更新されたデータやモデルを推論対象に組み込 むことが可能。 • 注意点: ◦ 学習パイプラインの安定性。 ◦ 推論器の追加・削除処理。 削除 追加 プロキシ サービス ディスカバリ 特徴抽出 出品データ 出品画像 インデクシング ML推論基盤 ML学習基盤
15 • MLシステムの難しさ まとめ ! 出力が確率的 ! スピードが遅い ! データの変化 ! モデルの更新 閾値による出力判定、上位 x件を見せて人間の判断に委ねる
リソース調整、タイムアウト、キャッシュ、シンプルなモデル キャッシュ、定期的なデータ更新 カナリアリリース、ABテスト、サービスディスカバリー ビジネスロジックやUI/UXとの整合性
16 コロナウィルスに負けずにイベントを開催した運営に称賛と感謝! この登壇者紹介を本人の 確認なく掲載した大胆さに も称賛申し上げます。 https://techplay.jp/event/768641
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}