of converting a locational description such as a street address into some form of geographic representation such as geographic coordinates (latitude and longitude).
words is the minimum number of single-character edits (i.e. insertions, deletions or substitutions) required to change one word into the other Levenshtein distance between "kitten" and "sitting" is 3, since the following three edits change one into the other, and there is no way to do it with fewer than three edits: 1. kitten → sitten (substitution of "s" for "k") 2. sitten → sittin (substitution of "i" for "e") 3. sittin → sitting (insertion of "g" at the end). ❖ It is always at least the difference of the sizes of the two strings. ❖ It is at most the length of the longer string. ❖ It is zero if and only if the strings are equal.
similarity between two strings. Best suited for short strings such as person names. A score of 0 equates to no similarity and 1 is an exact match. Example: Given string s1 MARTHA and string s2 MARHTA m(number of matching characters) = 6 t(number of transpositions required) = 1
maximum number of occurrences of different q-grams in two strings. The strings are closer relatives greater the q-grams in common. Variants: 1. Jaccard Similarity 2. Dice Coefficient 3. Overlap Coefficient
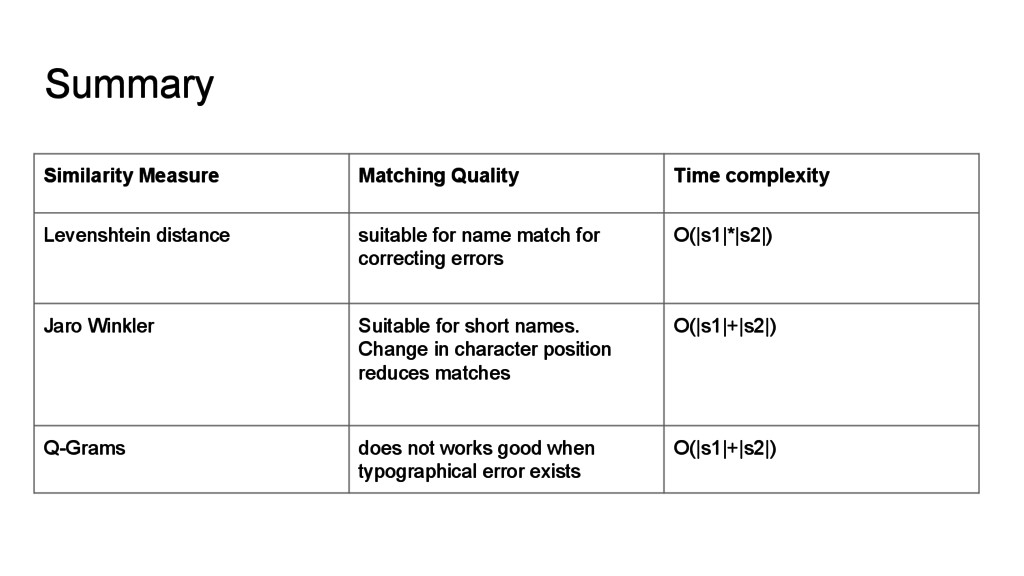
for name match for correcting errors O(|s1|*|s2|) Jaro Winkler Suitable for short names. Change in character position reduces matches O(|s1|+|s2|) Q-Grams does not works good when typographical error exists O(|s1|+|s2|)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}