QNLI : Question Natural Language Inference 質問応答データセット,質問と文が正答を含むか判定 4. SST-2 : The Stanford Sentiment Treebank 映画感想の感情分析で,ネガポジ判定 5. CoLA : The Corpus of Linguistic Acceptability 使われている英語が,言語学的に受け入れられるか判定 16
02/06/2019). [2] [dl 輪読会]bert: Pre-training of deep bidirectional transformers for lang…. https://www.slideshare.net/DeepLearningJP2016/ dlbert-pretraining-of-deep-bidirectional-transformers-for-language-understanding. (Accessed on 02/07/2019). [3] 汎用言語表現モデル bert を日本語で動かす (pytorch) - qiita. https://qiita.com/Kosuke-Szk/items/4b74b5cce84f423b7125. (Accessed on 02/07/2019). [4] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. BERT: pre-training of deep bidirectional transformers for language understanding. CoRR, abs/1810.04805, 2018. 23
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
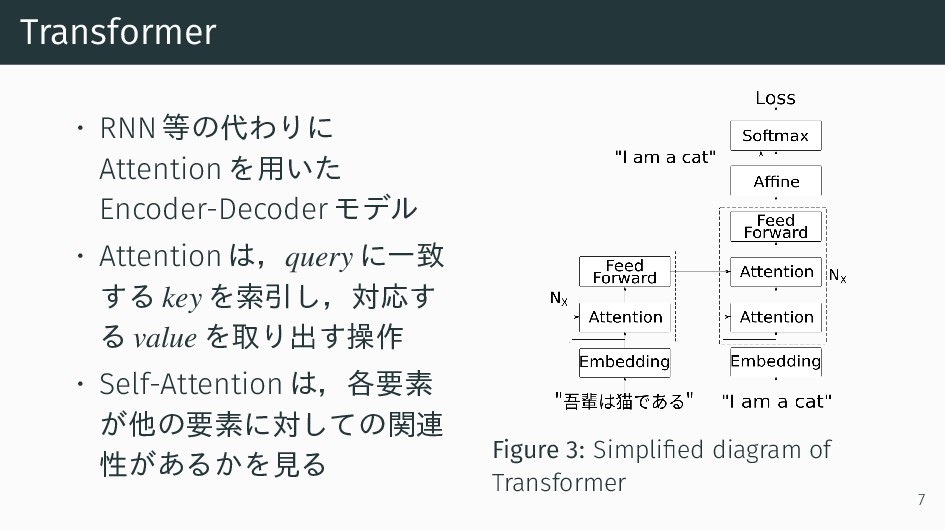{kind=link}
{kind=link}
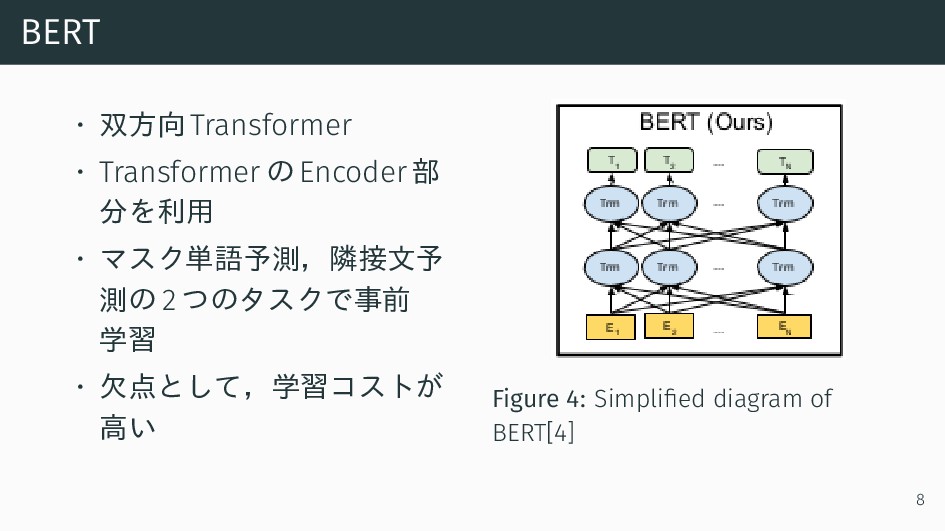{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![実験結果 i Table 1: GLUE Test results[4] 18](https://files.speakerdeck.com/presentations/0cc7582b904047f6b712c40a4256a6a4/slide_21.jpg){kind=link}
![実験結果 ii Table 2: SQuAD Test results[4] 19](https://files.speakerdeck.com/presentations/0cc7582b904047f6b712c40a4256a6a4/slide_22.jpg){kind=link}
![実験結果 iii Table 3: NER Test results[4] 20](https://files.speakerdeck.com/presentations/0cc7582b904047f6b712c40a4256a6a4/slide_23.jpg){kind=link}
![実験結果 iv Table 4: SWAG Test results[4] 21](https://files.speakerdeck.com/presentations/0cc7582b904047f6b712c40a4256a6a4/slide_24.jpg){kind=link}
{kind=link}
{kind=link}
![参考文献 [1] Bert(ディープラーニング)による自然言語処理は、どんなデータで評価されたの? どんな応用が できそう?| 忙しいあなたの代わりに、史上最強の良い本・良い暮らしのご提案. https: //it-mint.com/2018/11/06/datasets-of-deep-learning-bert-1603.html. (Accessed on](https://files.speakerdeck.com/presentations/0cc7582b904047f6b712c40a4256a6a4/slide_27.jpg){kind=link}