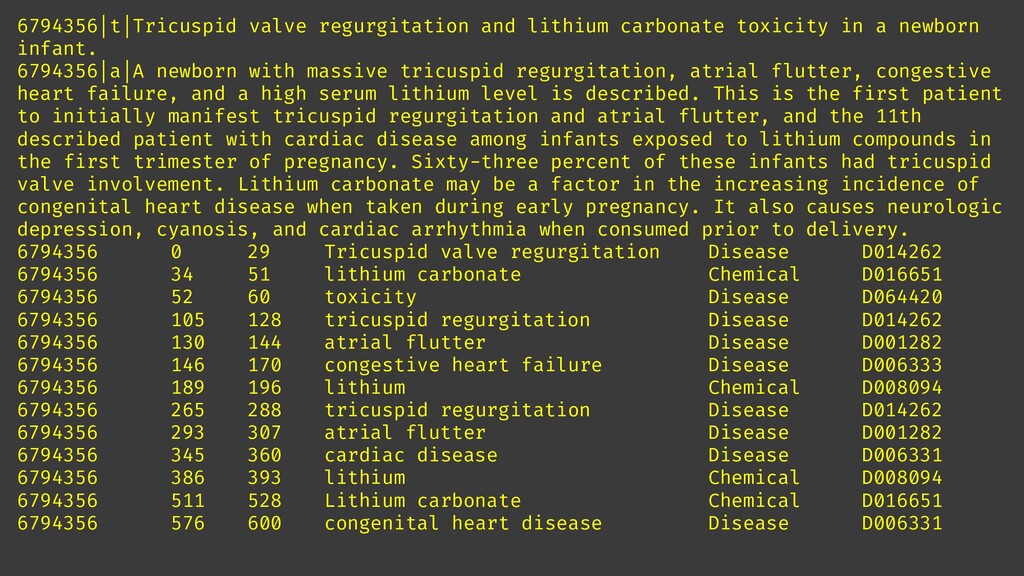
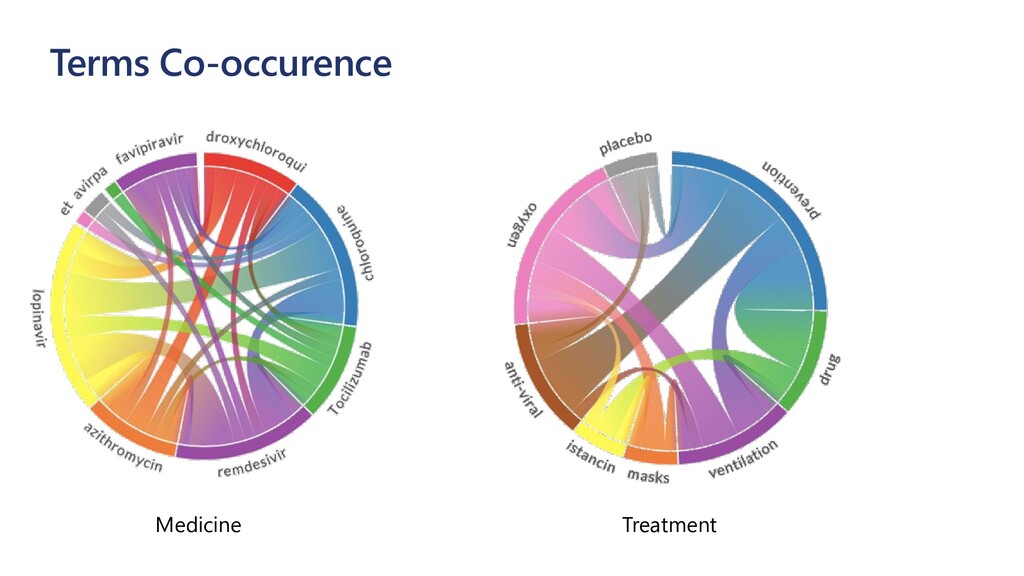
300 mg or favipiravir daily. HealthcareEntity(text=300 mg, category=Dosage, subcategory=None, length=6, offset=47, confidence_score=1.0, data_sources=None, related_entities={HealthcareEntity(text=favipiravir, category=MedicationName, subcategory=None, length=11, offset=57, confidence_score=1.0, data_sources=[HealthcareEntityDataSource(entity_id=C1138226, name=UMLS), HealthcareEntityDataSource(entity_id=J05AX27, name=ATC), HealthcareEntityDataSource(entity_id=DB12466, name=DRUGBANK), HealthcareEntityDataSource(entity_id=398131, name=MEDCIN), HealthcareEntityDataSource(entity_id=C462182, name=MSH), HealthcareEntityDataSource(entity_id=C81605, name=NCI), HealthcareEntityDataSource(entity_id=EW5GL2X7E0, name=NCI_FDA)], related_entities={}): 'DosageOfMedication'}) aspirin (C0004057) [MedicationName] 300 mg [Dosage] --DosageOfMedication--> favipiravir (C1138226) [MedicationName] favipiravir (C1138226) [MedicationName] daily [Frequency] --FrequencyOfMedication--> favipiravir (C1138226) [MedicationName]
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
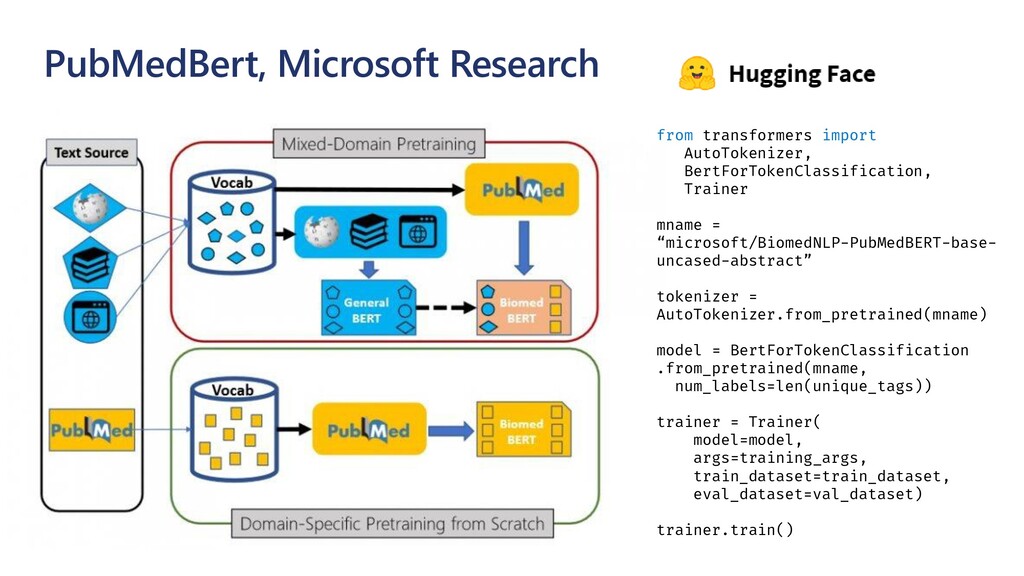{kind=link}
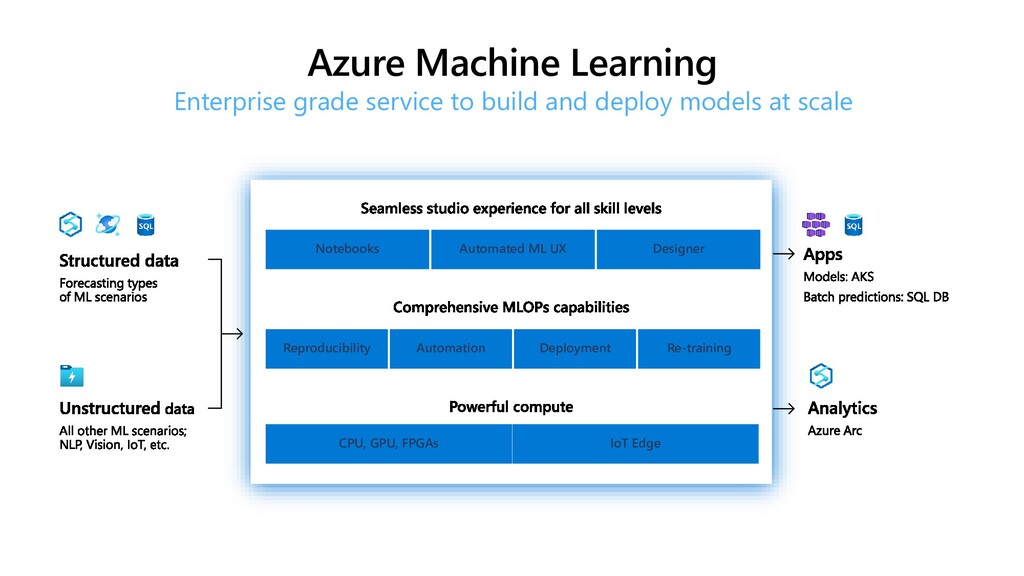{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
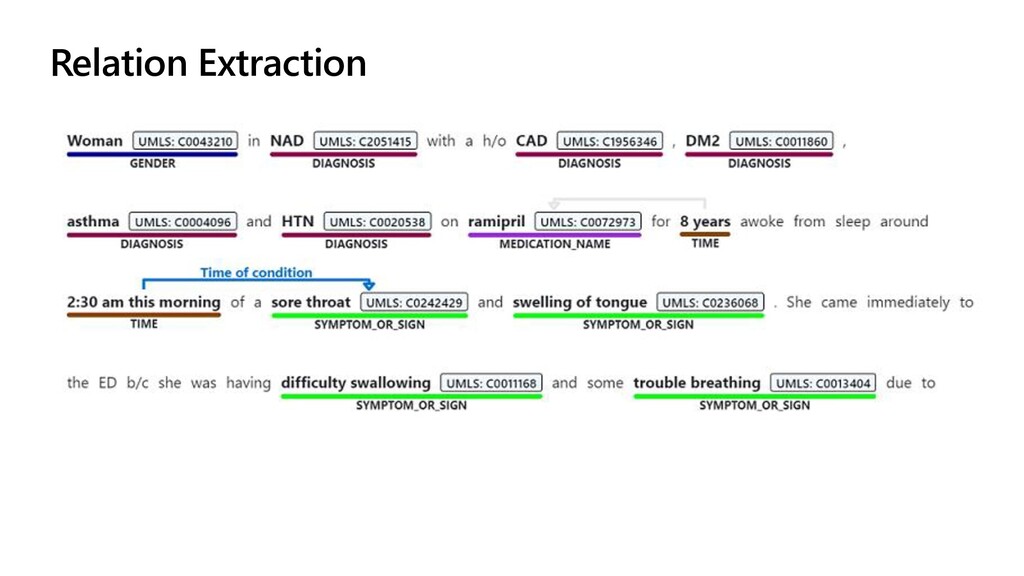{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
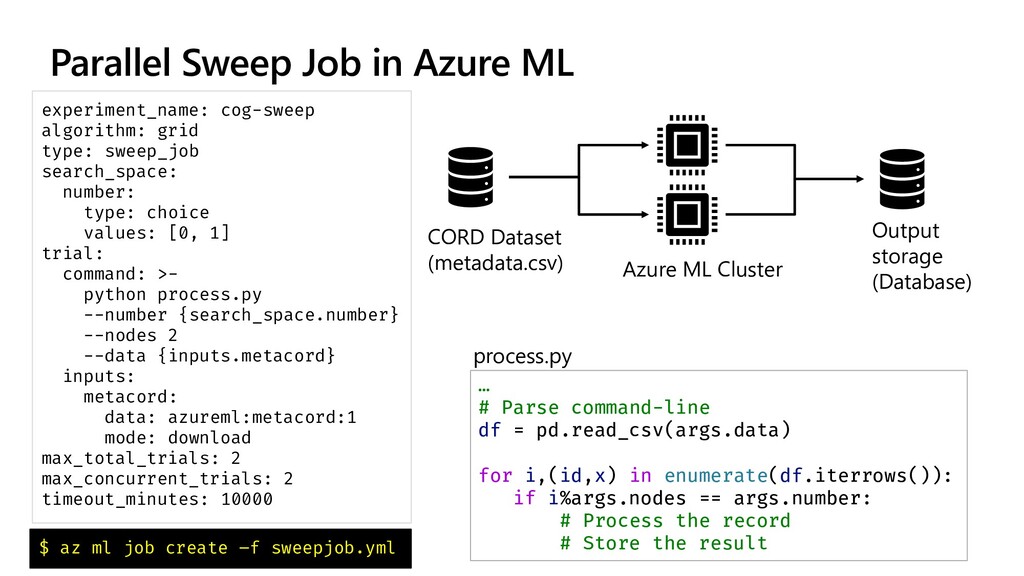{kind=link}
{kind=link}
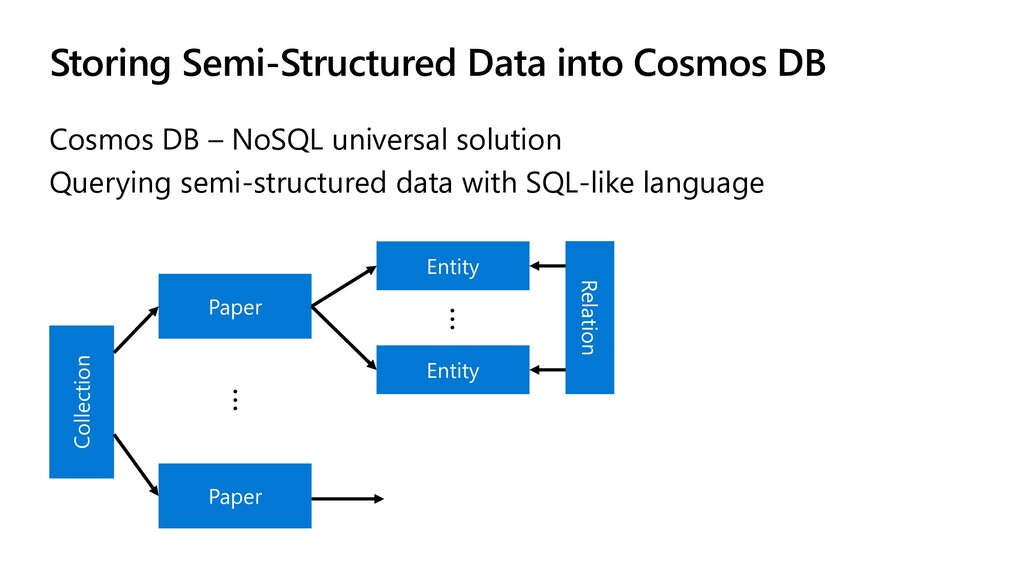{kind=link}
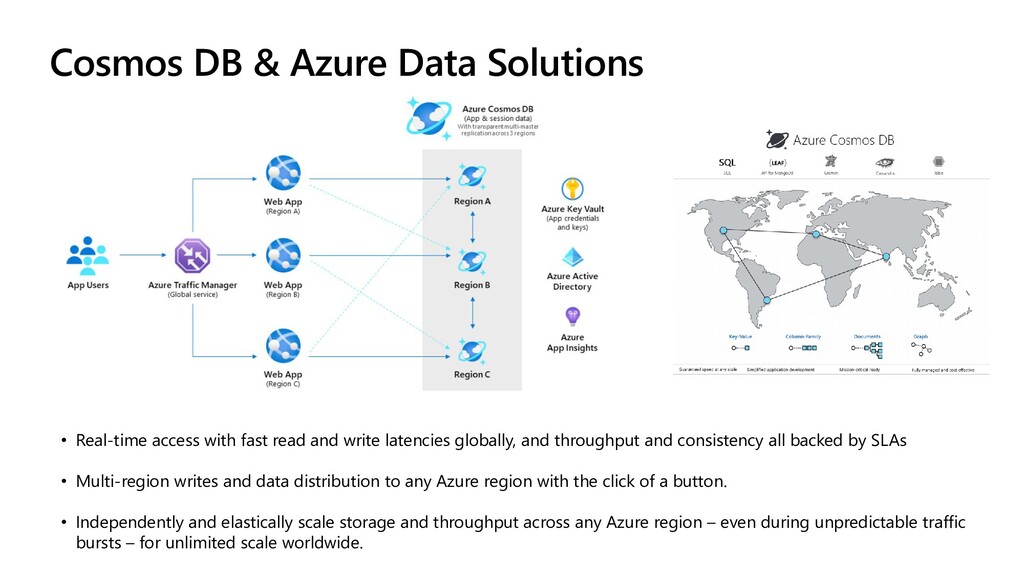{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
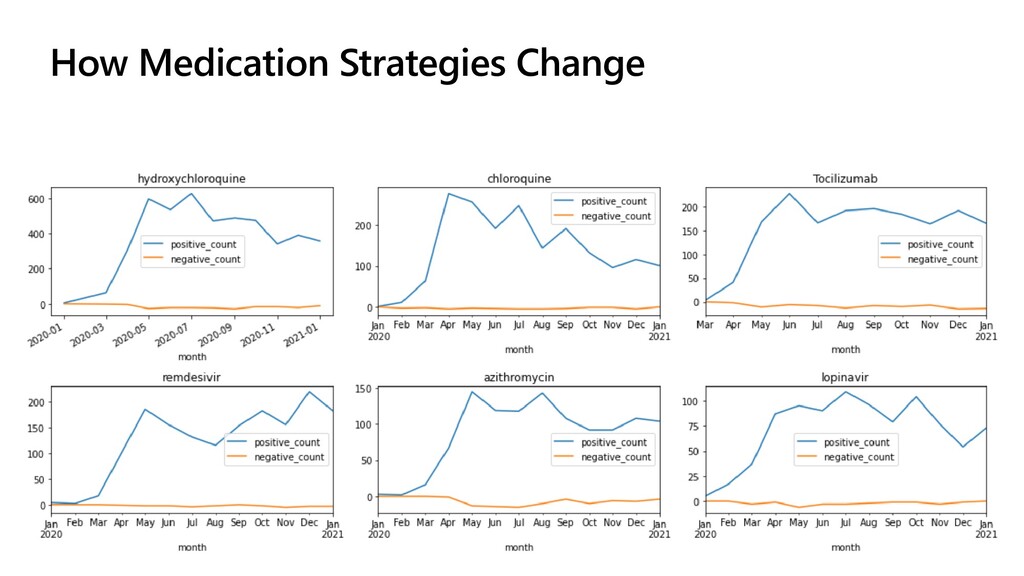{kind=link}
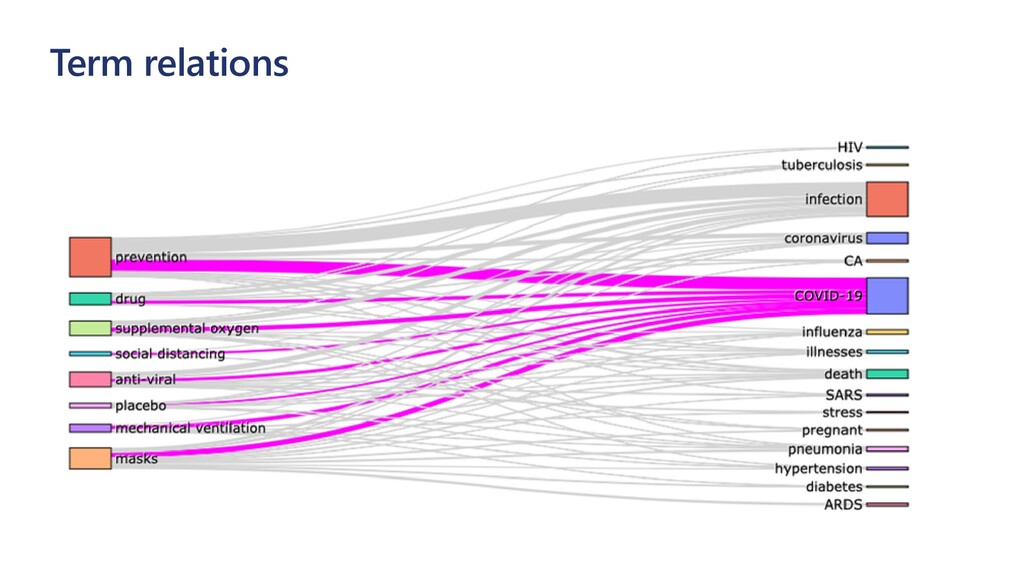{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}