日本語版 より https://doc.rust-jp.rs/book-ja/ch08-02-strings.html • Unicode® Version 14.0 Character Counts https://www.unicode.org/versions/stats/charcountv14_0.html • Japanese Character Encoding for Internet Messages (RFC1468) https://datatracker.ietf.org/doc/html/rfc1468 28
{kind=link}
{kind=link}
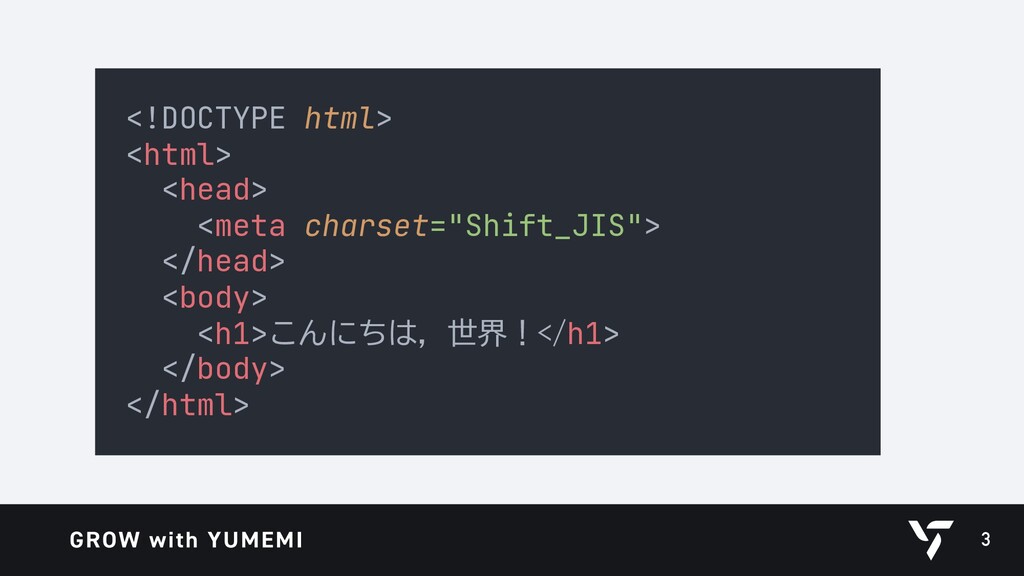{kind=link}
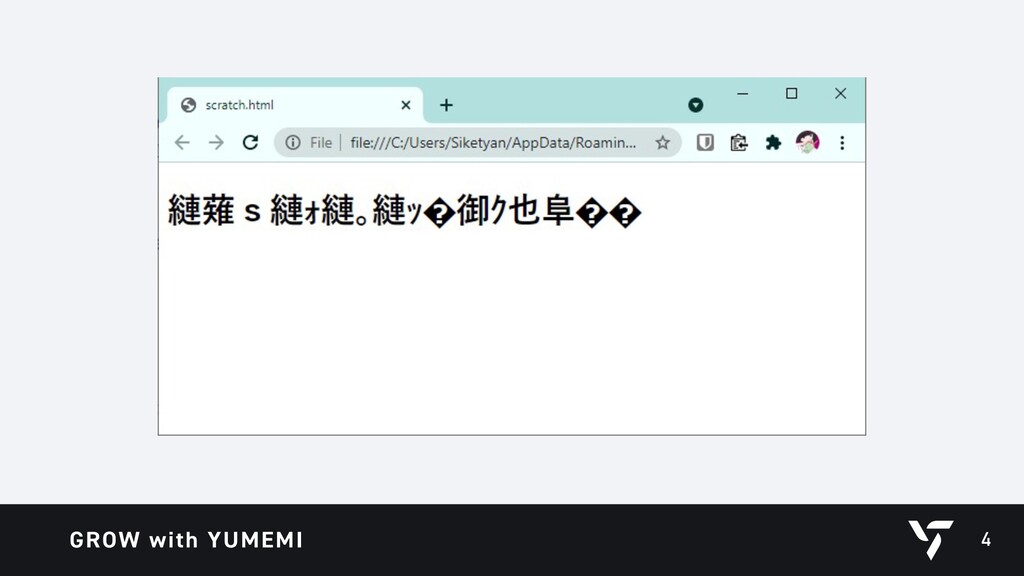{kind=link}
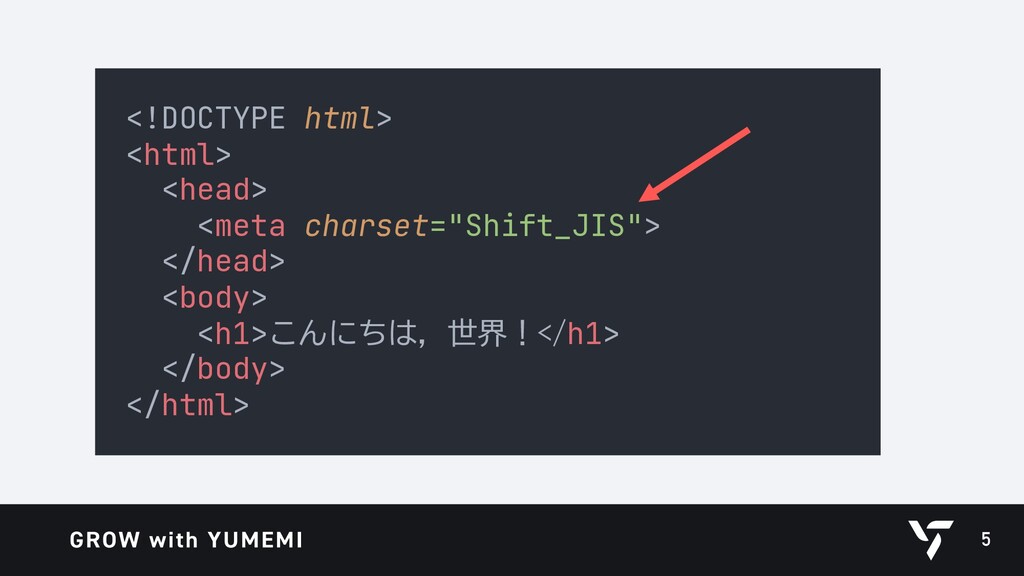{kind=link}
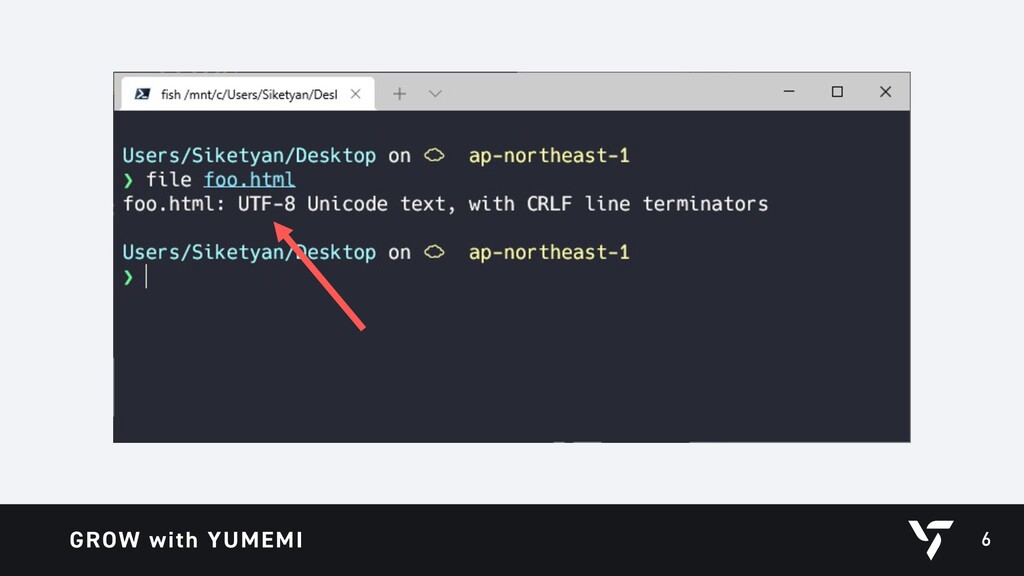{kind=link}
{kind=link}
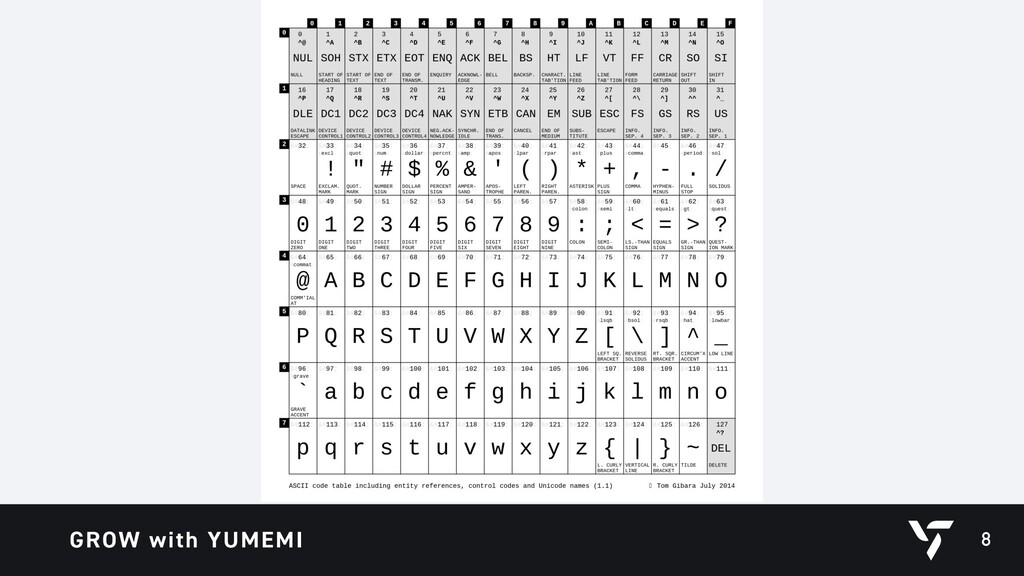{kind=link}
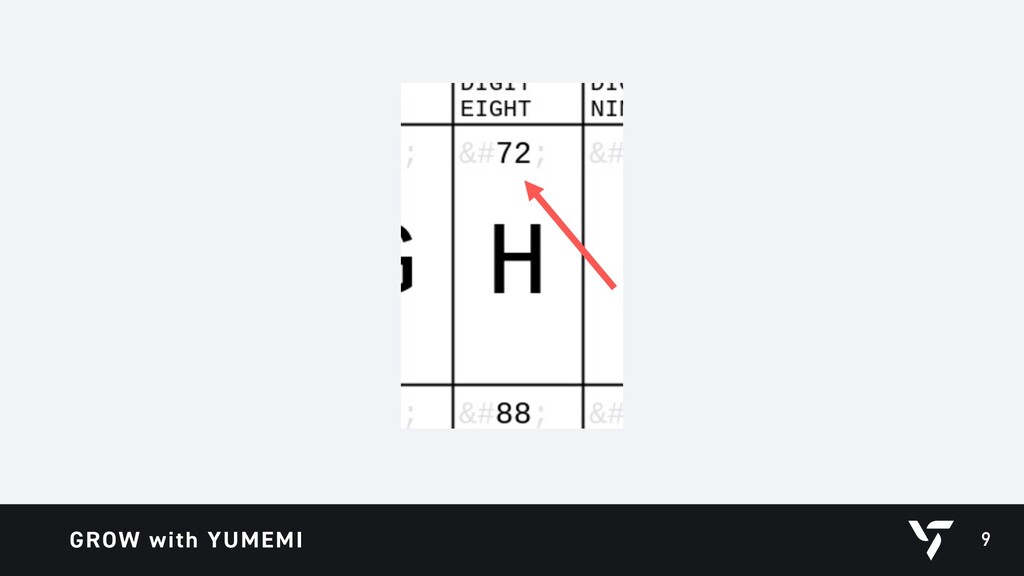{kind=link}
{kind=link}
{kind=link}
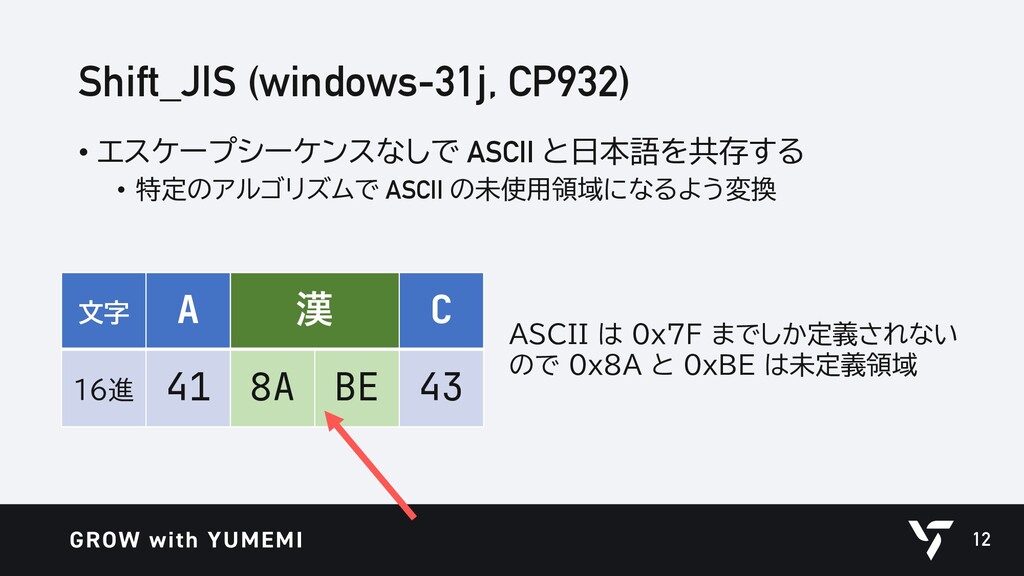{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}