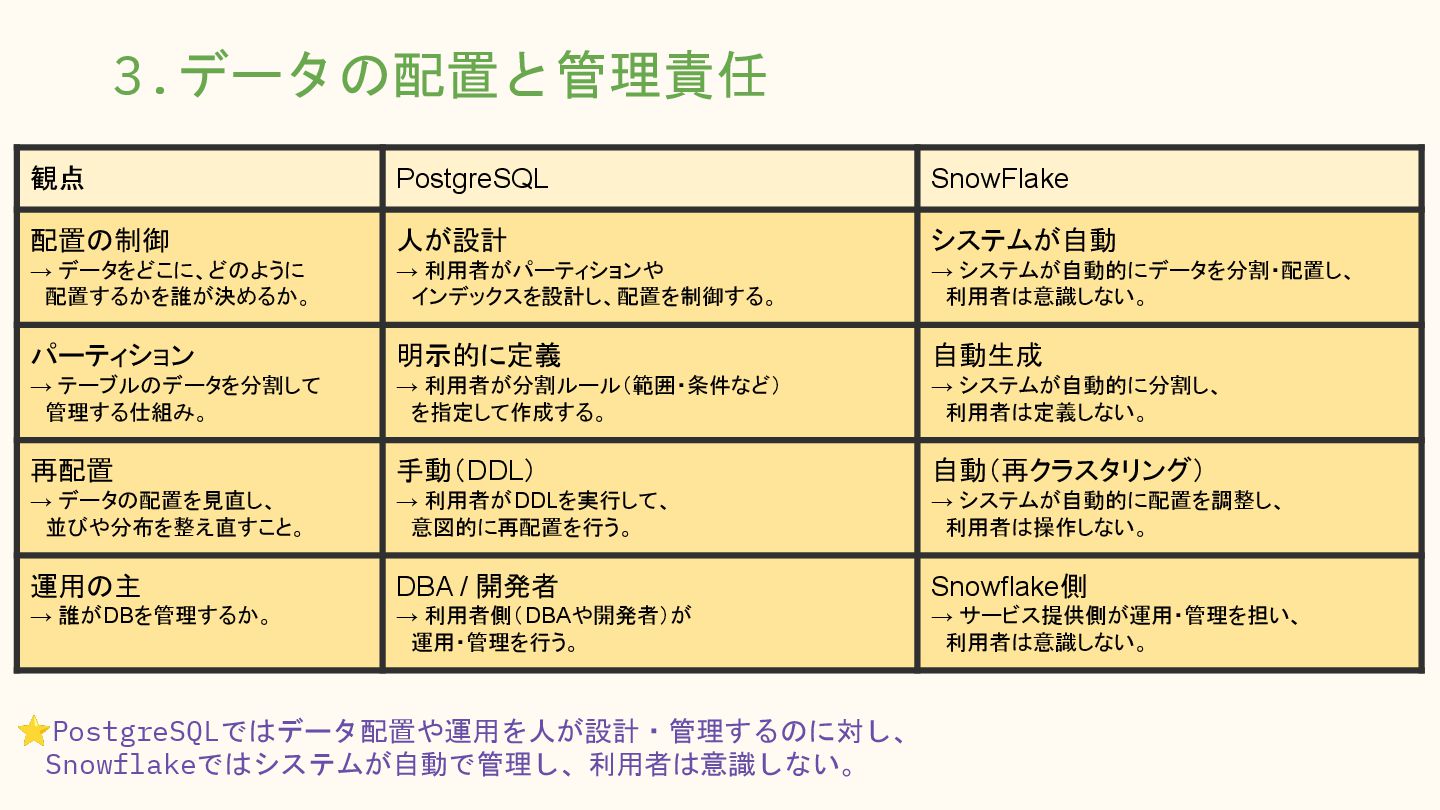
利用者がパーティションや インデックスを設計し、配置を制御する。 システムが自動 → システムが自動的にデータを分割・配置し、 利用者は意識しない。 パーティション → テーブルのデータを分割して 管理する仕組み。 明示的に定義 → 利用者が分割ルール(範囲・条件など) を指定して作成する。 自動生成 → システムが自動的に分割し、 利用者は定義しない。 再配置 → データの配置を見直し、 並びや分布を整え直すこと。 手動(DDL) → 利用者がDDLを実行して、 意図的に再配置を行う。 自動(再クラスタリング) → システムが自動的に配置を調整し、 利用者は操作しない。 運用の主 → 誰がDBを管理するか。 DBA / 開発者 → 利用者側(DBAや開発者)が 運用・管理を行う。 Snowflake側 → サービス提供側が運用・管理を担い、 利用者は意識しない。 ⭐PostgreSQLではデータ配置や運用を人が設計・管理するのに対し、 Snowflakeではシステムが自動で管理し、利用者は意識しない。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}