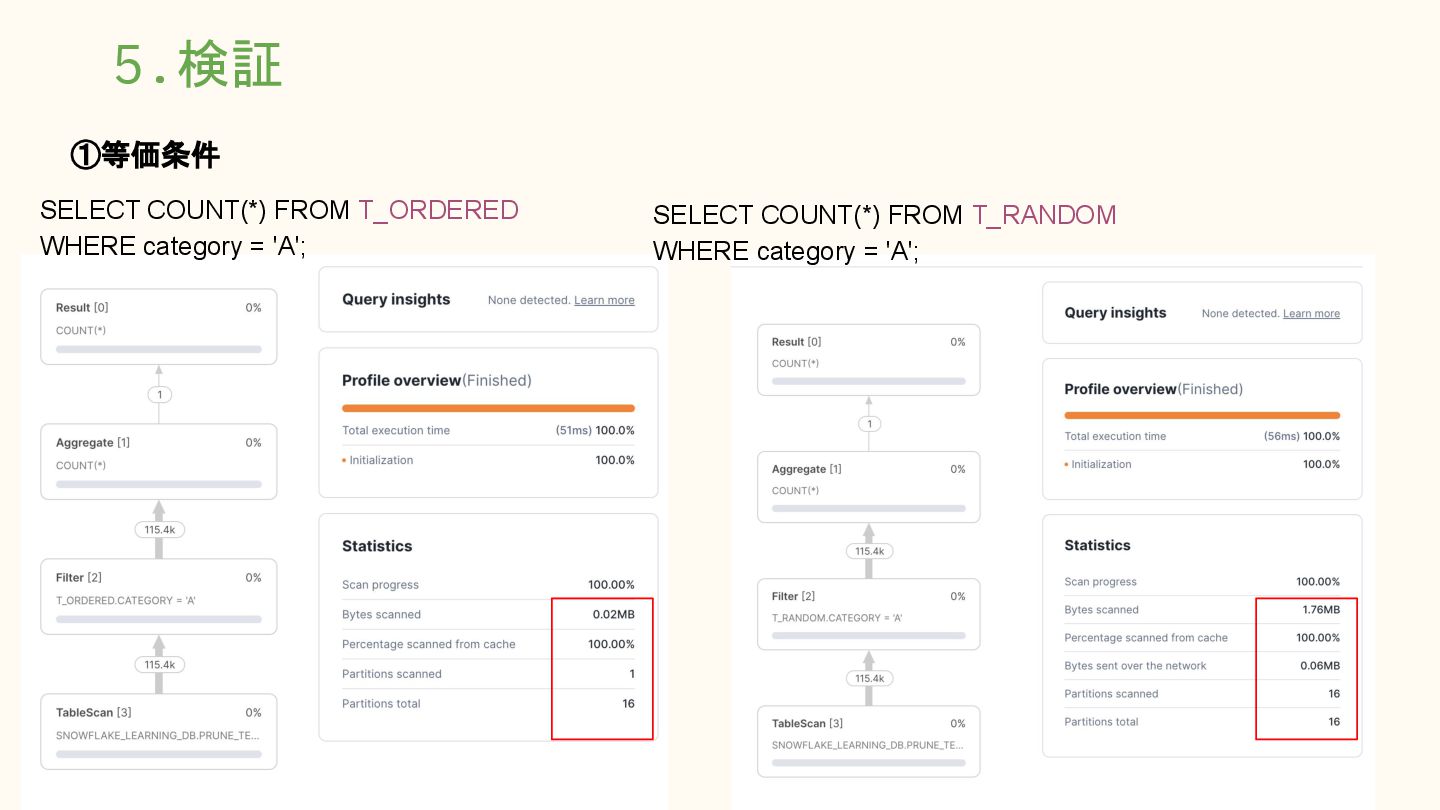
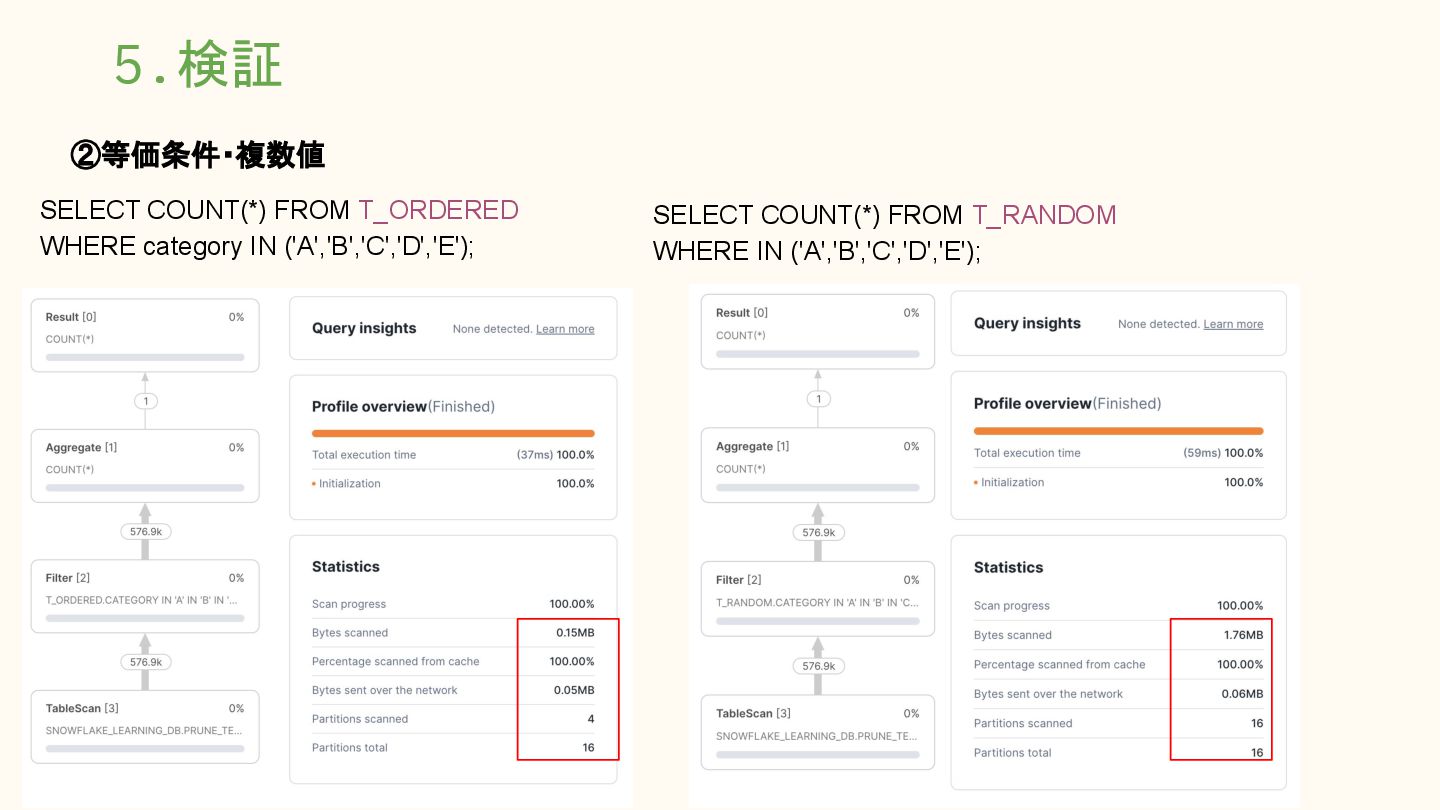
= 'A'; ◦ SELECT COUNT(*) FROM T_RANDOM WHERE category = 'A'; ▪ 等価条件(=)を使用 ▪ 返却行数の影響を避けるため COUNT(*) ▪ キャッシュの影響を避けて実行 • ②使用するクエリ(等価条件・複数値) ◦ SELECT COUNT(*) FROM T_ORDERED WHERE category IN ('A','B','C','D','E'); ◦ SELECT COUNT(*) FROM T_RANDOM WHERE category IN ('A','B','C','D','E'); ▪ 等価条件の 複数値指定(IN) ▪ 対象データ範囲を意図的に拡張 ▪ プルーニング効率の変化を確認 ▪ キャッシュの影響を避けて実行
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}