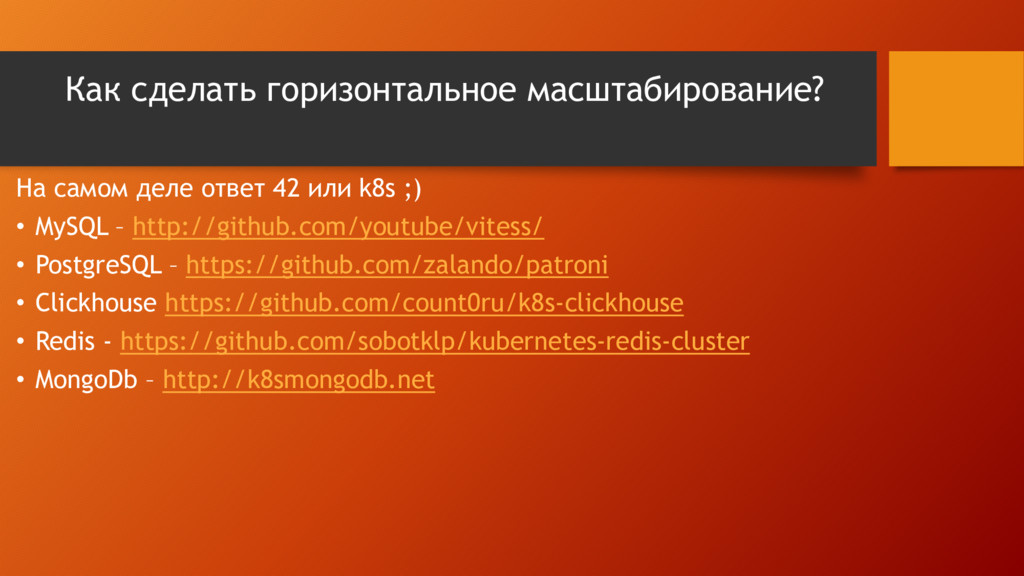
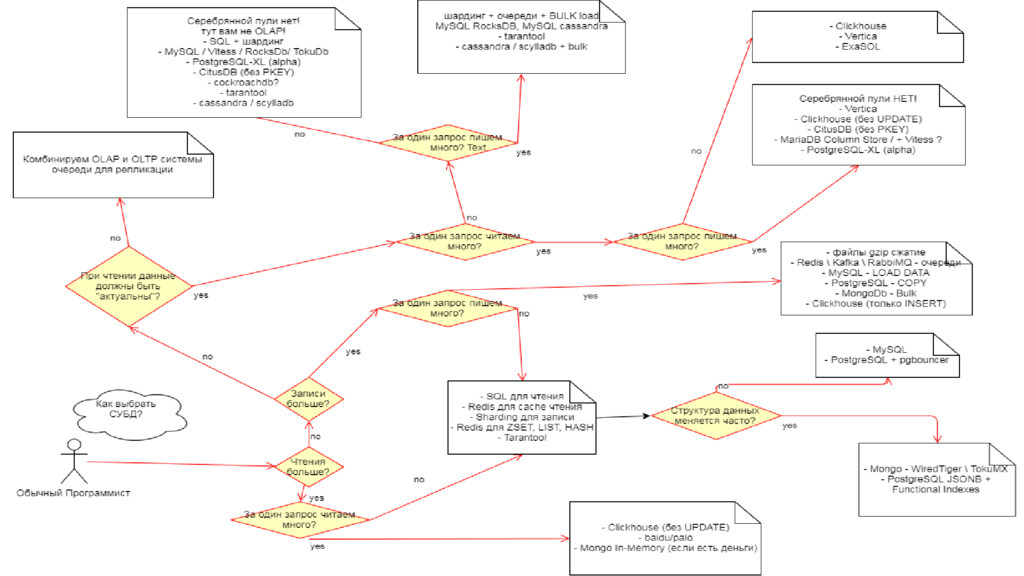
Попытался "быстренько" пробежаться по всем СУБД с которыми работал за 20 лет и постараться вложить слушателям мысль что СУБД надо выбирать под нагрузку
и что для СУБД надо знать "алгоритмы" и "эксплуатацию"
Видео тут https://www.youtube.com/watch?v=_je9o0Y03rs
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}