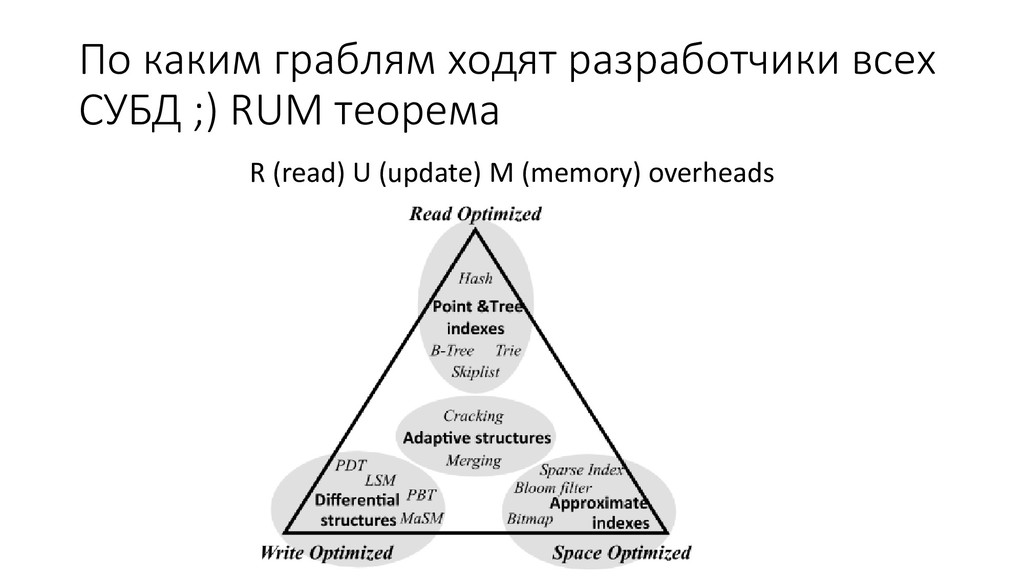
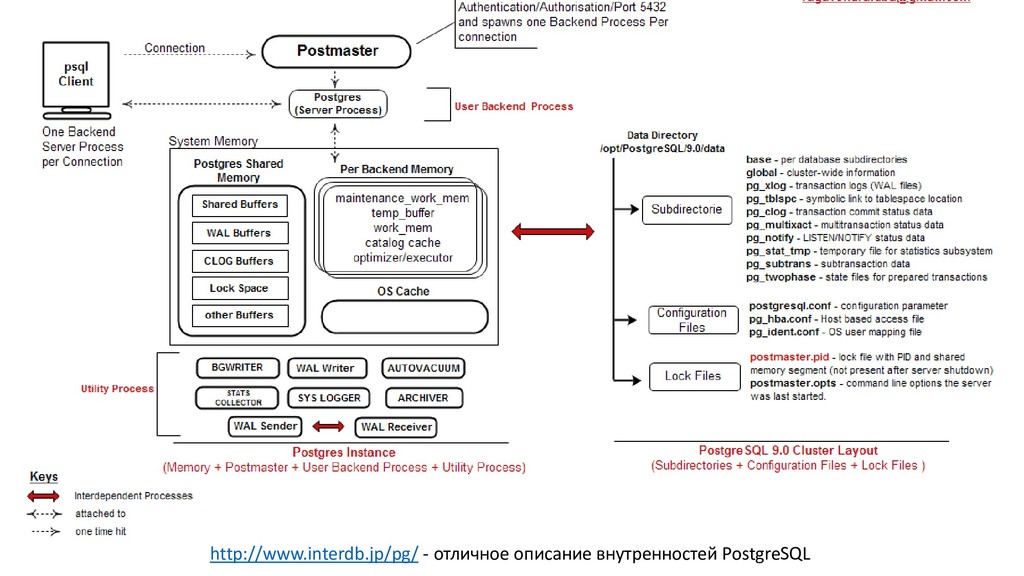
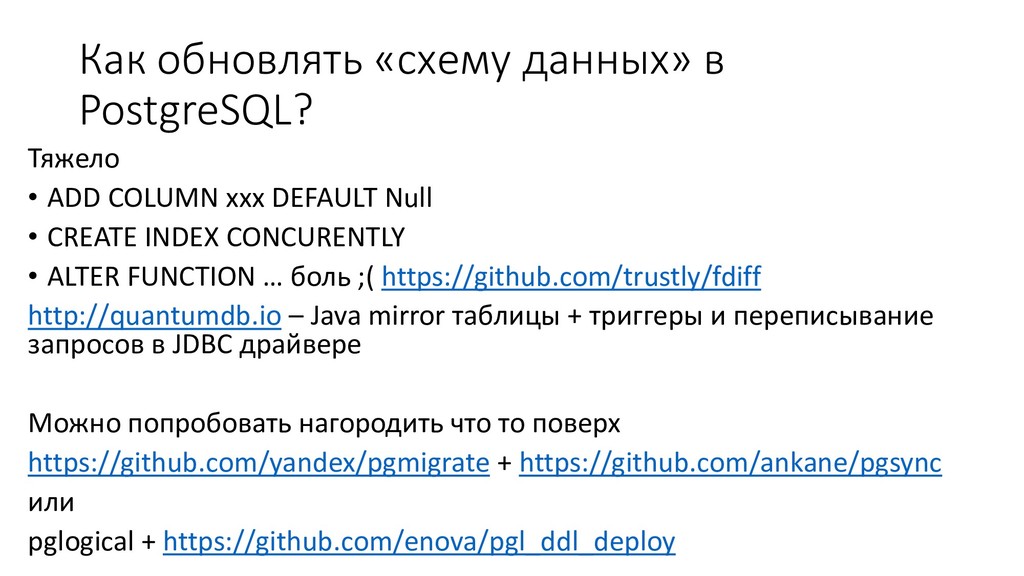
В своем докладе я постарался дать ответы на вопросы, с которыми в той или иной степени сталкивается любой обычный программист работая с СУБД PostgreSQL. Надеюсь получилось простым и понятным языком рассказать о том, как работает PostgreSQL, а также о том, как его эксплуатировать и масштабировать.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Вопросы из зала? Со мной можно связаться [email protected] https://t.me/bloodjazman](https://files.speakerdeck.com/presentations/c9640805c9d84aa19316bc802ea22452/slide_16.jpg){kind=link}