т.е. «часто» пишем и «часто читаем», «малыми порциями» данных https://ru.wikipedia.org/wiki/OLTP Есть некоторые подвижки сторону OLAP («тяжелые» выборки с GROUP BY, ORDER BY и JOIN) https://mariadb.com/kb/en/library/mariadb-columnstore/ Быстрая batch вставка через LOAD DATA https://dev.mysql.com/doc/en/load-data.html
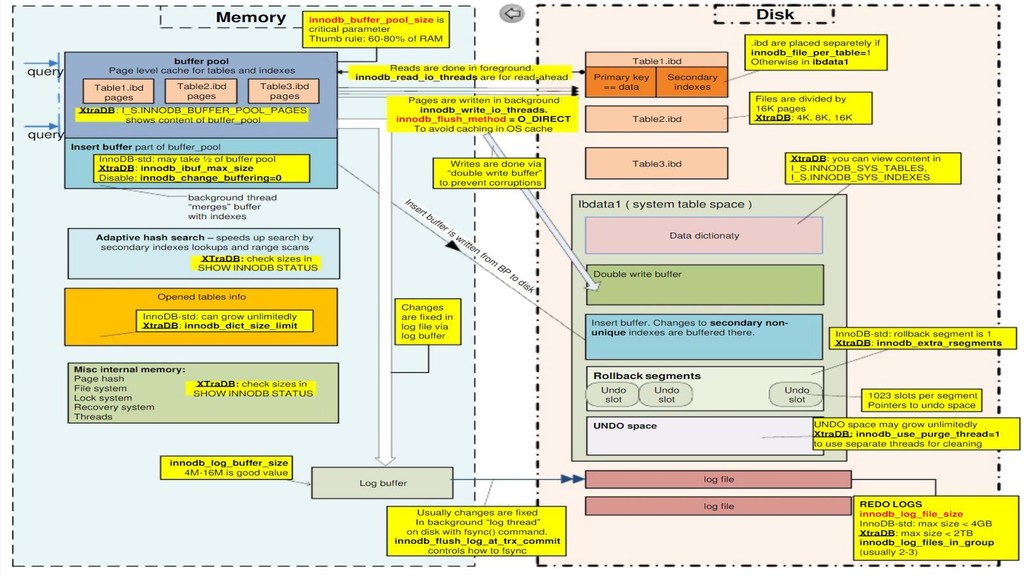
«страницы» 16Kb • Внутри страниц «строки» целиком • Отдельные страницы для «вторичных индексов» и для «больших полей (BLOB, JSON, TEXT) • Страницы с данными строки «упорядочены» по clustered index (primary key, first unique key или internal 6 bytes index) Подробнее https://dev.mysql.com/doc/refman/5.7/en/innodb- physical-record.html
делаются в «странице» памяти см. innodb_buffer_pool, чтобы сделать delete или update страницу надо прочитать (см. innodb_read_io_threads) • Параллельно «изменения» формируются в log buffer (в памяти) • Log buffer скидывается на диск в ib_logdata при каждом commit, либо при заполнении, либо 1 раз в секунду см. innodb_flush_at_trx_commit • Параллельно в фоне через «thread pool» (размер ограничен innodb_write_io_threads) + O_DIRECT (чтобы) делается «сброс» в <table_name>.ibd (ibdata) в double write buffer
индексы и таблицы из которых будет произведено чтение • Чтение идет с диска через O_DIRECT «страницами» (16kb) и кешируется в buffer pool (если страница уже в памяти, то нет смысла читать ее второй раз) • Чтение из clustered\secondary индекса «по значению» = O(log n) дисковых операций где n общее кол-во «страниц» • Для «страниц данных» даже если вам нужно 1 поле из 100, прочитается вся строка
каждый коннект, можно оптимизировать через thread_cache_size и back_log • Innodb\Xtradb storage engine использует свой thread pool для «чтения» и «записи» настраивается через innodb_io_write_threads и innodb_io_read_threads (пропорционально возможностям диска и кол-ву ядер) • Есть отдельный механизм thread pools в Mariadb и Percona, для узких специализированных видов нагрузки
триггеры - репликация running status, replication lag - 90% connection usage - low innodb cache hit rate - deadlocks - high CPU\Memory usage - high iowait, high disk utilization
triggers+INSERT INTO SELECT, плохо работает если таблица сильно нагружена, прерывание в середине процесса опасно, нельзя использовать foreign keys и triggers, написано на perl • https://github.com/github/gh-ost ROW binary log (меньше нагрузка), но foreign key и triggers все равно нельзя (может сделают), вместо RENAME – LOCK TABLE, нельзя NULL в индексах, не поддерживается JSON • https://github.com/facebookincubator/OnlineSchemaChange triggers + SELECT INTO OUTFILE\LOAD DATA, запускается на мастере, python – можно попробовать использовать как библиотеку для миграций • https://github.com/skeema/skeema используется в связке с pt-online-schema-change, тоже куча ограничений • https://dev.mysql.com/doc/mysql-utilities/1.6/en/mysqldbcompare.html мало кто вспоминает, но может даже INSERT данных
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Вопросы из зала? Со мной можно связаться [email protected] https://t.me/bloodjazman](https://files.speakerdeck.com/presentations/1cf8c4c2343c4de3a5a05d06a0038b6c/slide_16.jpg){kind=link}