Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
PRML Chapter 11 (11.0-11.2)
Search
shogo-d-nakamura
April 01, 2023
Science
460
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
PRML Chapter 11 (11.0-11.2)
PRML, Pattern Recognition and Machine Learning
chapter 11
shogo-d-nakamura
April 01, 2023
More Decks by shogo-d-nakamura
See All by shogo-d-nakamura
Deep Learning Chapter 7
snkmr
0
110
PRML Chapter 1 (1.3-1.6)
snkmr
1
400
PRML Chapter 9
snkmr
1
360
PRML Chapter 5 (5.0-5.4)
snkmr
1
540
PRML Chapter 8 (8.0-8.3)
snkmr
1
390
Other Decks in Science
See All in Science
Conversation is the New Dashboard: 属人性を排除する第4世代BIツールの勢力図
shomaekawa
1
620
摂理と合理の肉体改造 — AI時代の減量を支える観測・制御・継続
kiyoshi
0
1.7k
サンプル対応のない複数遺伝子発現プロファイルに対するテンソル分解型統合解析の要約
tagtag
PRO
0
220
Cross-Media Technologies, Information Science and Human-Information Interaction
signer
PRO
3
32k
20260220 OpenIDファウンデーション・ジャパン ご紹介 / 20260220 OpenID Foundation Japan Intro
oidfj
0
380
Endel Tulvingとエピソード記憶
rmaruy
0
160
AlgorithAlgorihms for Decision Making
mickey_kubo
0
110
Non-Gaussian, nonlinear causal discovery with hidden variables and application
sshimizu2006
0
160
機械学習 - K近傍法 & 機械学習のお作法
trycycle
PRO
1
1.6k
明治薬科大学講義_ビッグデータ解析を支えるデータベース技術とクラウドコンピューティング
ktatsuya
1
140
データベース08: 実体関連モデルとは?
trycycle
PRO
0
1.6k
Snowflake HCLS Meet Upヘルスケアユーザー会紹介
ktatsuya
0
120
Featured
See All Featured
Primal Persuasion: How to Engage the Brain for Learning That Lasts
tmiket
0
400
A Soul's Torment
seathinner
6
3.1k
Reflections from 52 weeks, 52 projects
jeffersonlam
356
21k
Effective software design: The role of men in debugging patriarchy in IT @ Voxxed Days AMS
baasie
0
460
Heart Work Chapter 1 - Part 1
lfama
PRO
8
36k
How to build an LLM SEO readiness audit: a practical framework
nmsamuel
1
820
Discover your Explorer Soul
emna__ayadi
2
1.2k
How to build a perfect <img>
jonoalderson
1
5.8k
Money Talks: Using Revenue to Get Sh*t Done
nikkihalliwell
0
440
AI Search: Where Are We & What Can We Do About It?
aleyda
0
7.7k
A Modern Web Designer's Workflow
chriscoyier
698
190k
Navigating the Design Leadership Dip - Product Design Week Design Leaders+ Conference 2024
apolaine
1
380
Transcript
2022/12/2 D1 中村 PRML Chapter 11 サンプリング法
まえがき 2 • 抽象的で分かりにくい • 以下を参考にしました - http://bin.t.u-tokyo.ac.jp/summercamp2015/document/prml11_chika.pdf - http://bin.t.u-tokyo.ac.jp/prml2009/
- ゼロからできるMCMC (本棚にあるやつ)
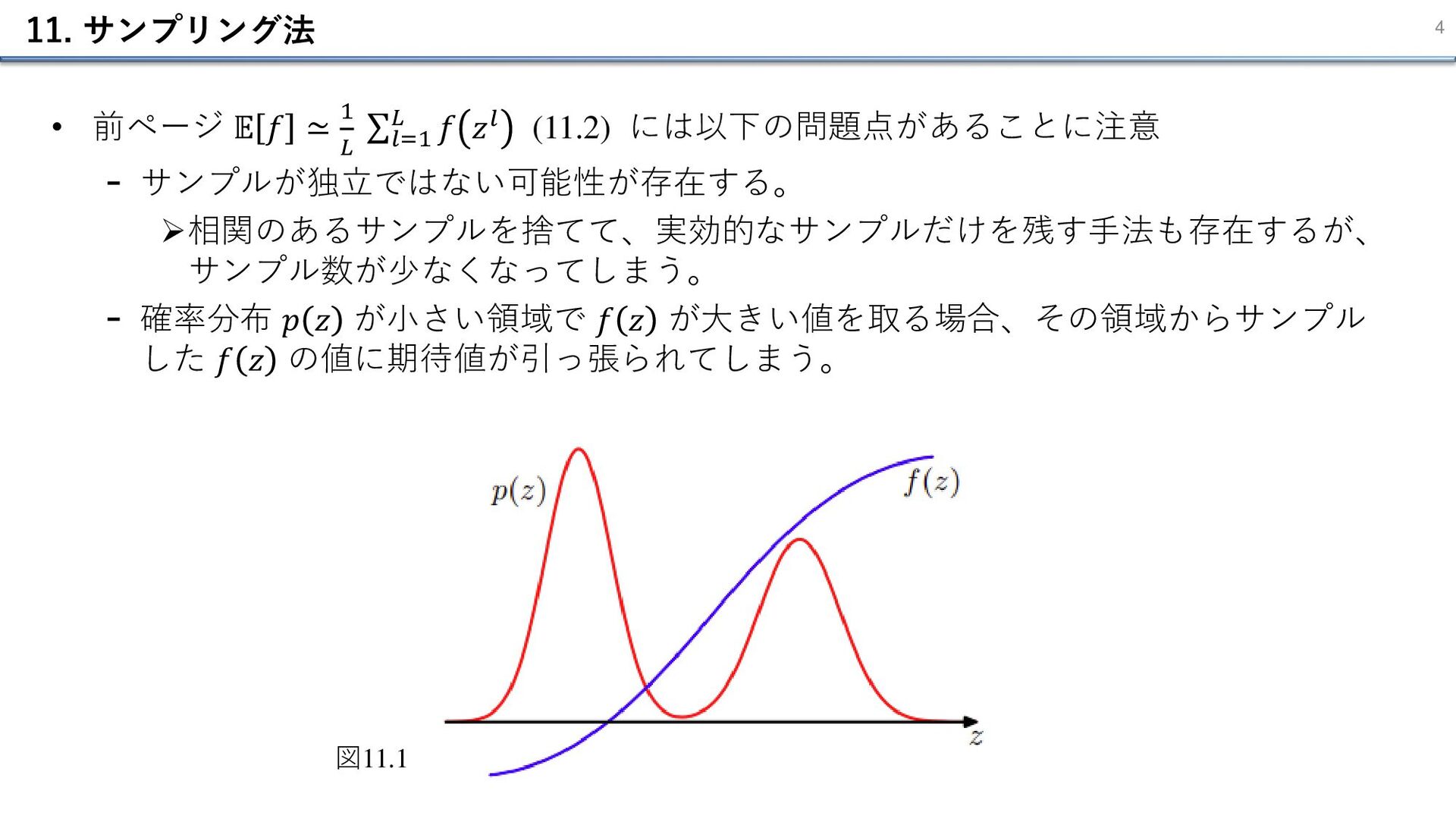
11. サンプリング法 3 • サンプリングの目的 - ある関数 𝑓(𝑧) について、確率分布 𝑝(𝑧)
の下での期待値を計算したい(図11.1)。 • 期待値の計算 - 連続変数であれば、 - サンプリング法の背後にある一般的なアイデアは、分布 𝒑(𝒛) から独立にサンプリング した集合 𝒛𝒍 (𝒍 = 𝟏, 𝟐, … 𝑳) を得ること。 - この場合、期待値は単純に有限和をとることで近似できる。 𝔼 𝑓 = ∫ 𝑓 𝑧 𝑝 𝑧 𝑑𝑧 (11.1) 𝔼 𝑓 ≃ 1 𝐿 𝑙=1 𝐿 𝑓 𝑧𝑙 (11.2)
11. サンプリング法 4 • 前ページ 𝔼 𝑓 ≃ 1 𝐿
σ𝑙=1 𝐿 𝑓 𝑧𝑙 (11.2) には以下の問題点があることに注意 - サンプルが独立ではない可能性が存在する。 ➢相関のあるサンプルを捨てて、実効的なサンプルだけを残す手法も存在するが、 サンプル数が少なくなってしまう。 - 確率分布 𝑝 𝑧 が小さい領域で 𝑓 𝑧 が大きい値を取る場合、その領域からサンプル した 𝑓 𝑧 の値に期待値が引っ張られてしまう。 図11.1
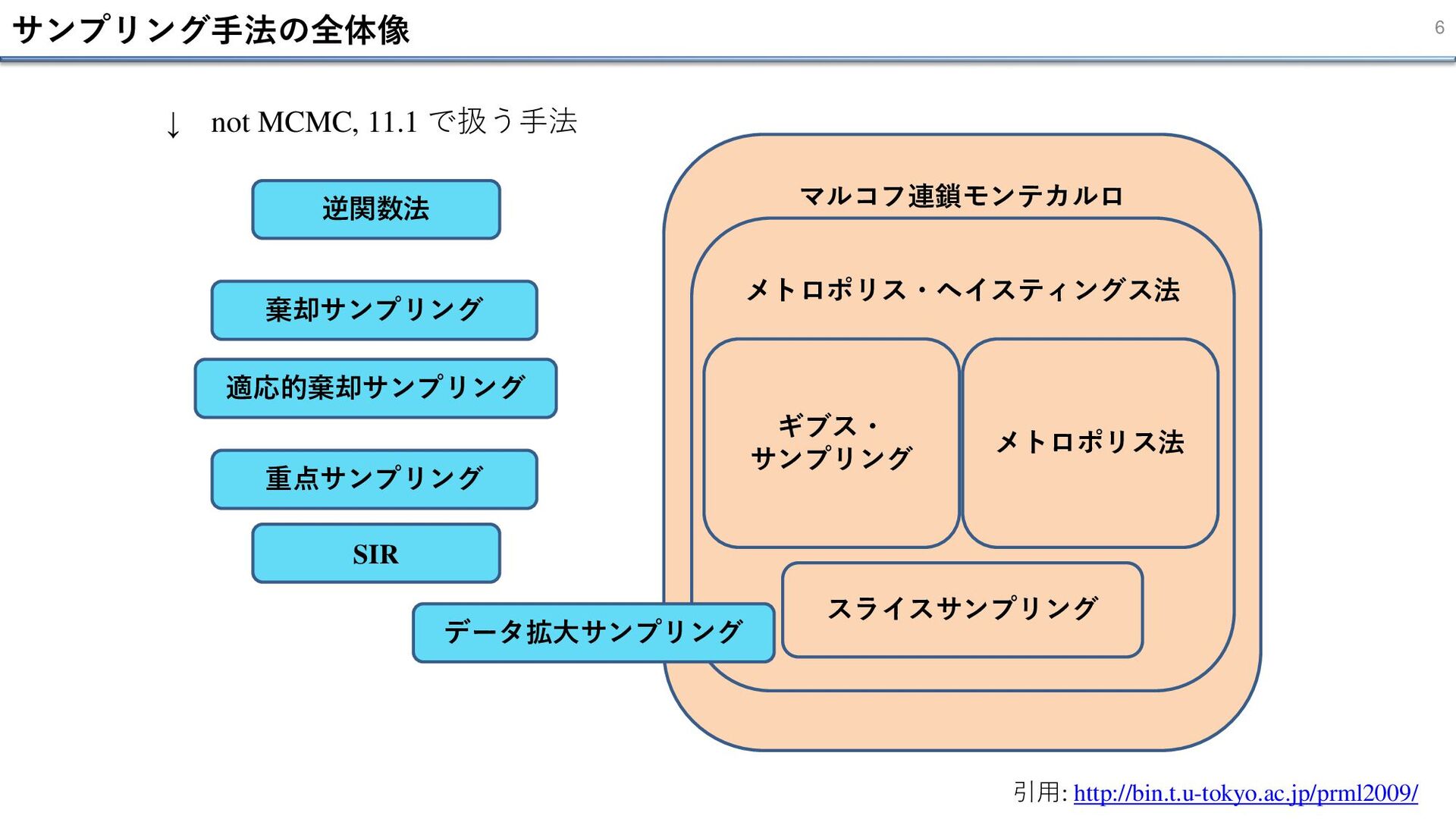
5 11.1 基本的なサンプリングアルゴリズム 11.1.1 標準的な分布 11.2 マルコフ連鎖モンテカルロ 目次 11.1.2 棄却サンプリング
11.1.3 適応的棄却サンプリング 11.1.4 重点サンプリング 11.1.5 SIR 11.1.6 サンプリングとEMアルゴリズム 11.2.1 マルコフ連鎖 11.2.2 Metropolis-Hastings アルゴリズム
サンプリング手法の全体像 6 逆関数法 棄却サンプリング 適応的棄却サンプリング 重点サンプリング SIR マルコフ連鎖モンテカルロ メトロポリス・ヘイスティングス法 メトロポリス法
ギブス・ サンプリング スライスサンプリング データ拡大サンプリング ↓ not MCMC, 11.1 で扱う手法 引用: http://bin.t.u-tokyo.ac.jp/prml2009/
11.1.1 標準的な分布: 逆関数法 7 • 逆関数法 - 一様な乱数 z を生成することが可能であるという前提。
- 𝑧 が 0~1に一様分布している場合を考える (𝑝 𝑧 = 1) 。 - 求めたい分布の確率密度関数の逆関数が簡単に書き下すことができる場合、逆関数法を 適用できる。 ➢ 一様乱数 z を生成し、 𝑦 = 𝑓 𝑧 で y に変換することを考える。 ➢ このとき、y の分布は以下 𝑝 𝑦 = 𝑝 𝑧 𝑑𝑧 𝑑𝑦 (11.5) ➢ 式(11.5) を積分すると、 𝑧 = ℎ 𝑦 = න −∞ 𝑦 𝑝 ො 𝑦 𝑑 ො 𝑦 11.6 • これは、 𝑝 𝑦 の不定積分になっている。 ➢ (11.6) より𝑦 = ℎ−1 𝑧 を得た。一様に分布している z をこの式で変換すれば、分布 𝑝 𝑦 に従って y をサンプリングすることが可能。
11.1.1 標準的な分布: 逆関数法 8 • 逆関数法の具体例 - 𝑝(𝑦) = 𝜆
exp −𝜆𝑦 (0 ≤ 𝑦) からサンプリングする場合について考える。 𝑧 = ℎ 𝑦 = න −∞ 𝑦 𝑝 ො 𝑦 𝑑 ො 𝑦 11.6 - 式(11.6) を使う。まず 𝑝(𝑦) の不定積分を求める。 𝑧 = ℎ 𝑦 = න 0 𝑦 𝜆exp(−𝜆ො 𝑦)𝑑 ො 𝑦 = 1 − exp(−𝜆𝑦) 𝑦 = ℎ−1 𝑧 = −𝜆ln(1 − 𝑧) - 以上で 𝑝(𝑦) の不定積分 ℎ(𝑦) の逆関数が表せた。 ➢この 𝑦 が分布 𝑝(𝑦) に従うことは簡単に証明できる(演習11.2)。 - 一様な乱数 𝑧 を生成し、 𝑦 に変換することで 𝑝(𝑦) から 𝑦 をサンプリングできる。
11.1.1 標準的な分布: 逆関数法 9 [0,1]の一様乱数zを 100000個発生 𝑦 = ℎ−1(𝑧) =
−2 ln( 1 − 𝑧) にぶち込む 乱数発生 引用: http://bin.t.u-tokyo.ac.jp/prml2009/ 𝑦 𝑧
11.1.2 棄却サンプリング 10 • 逆関数が求められないような、複雑な分布 𝑝 𝑧 からサンプリングしたい場合は、先述の 逆関数法は使えない。 •
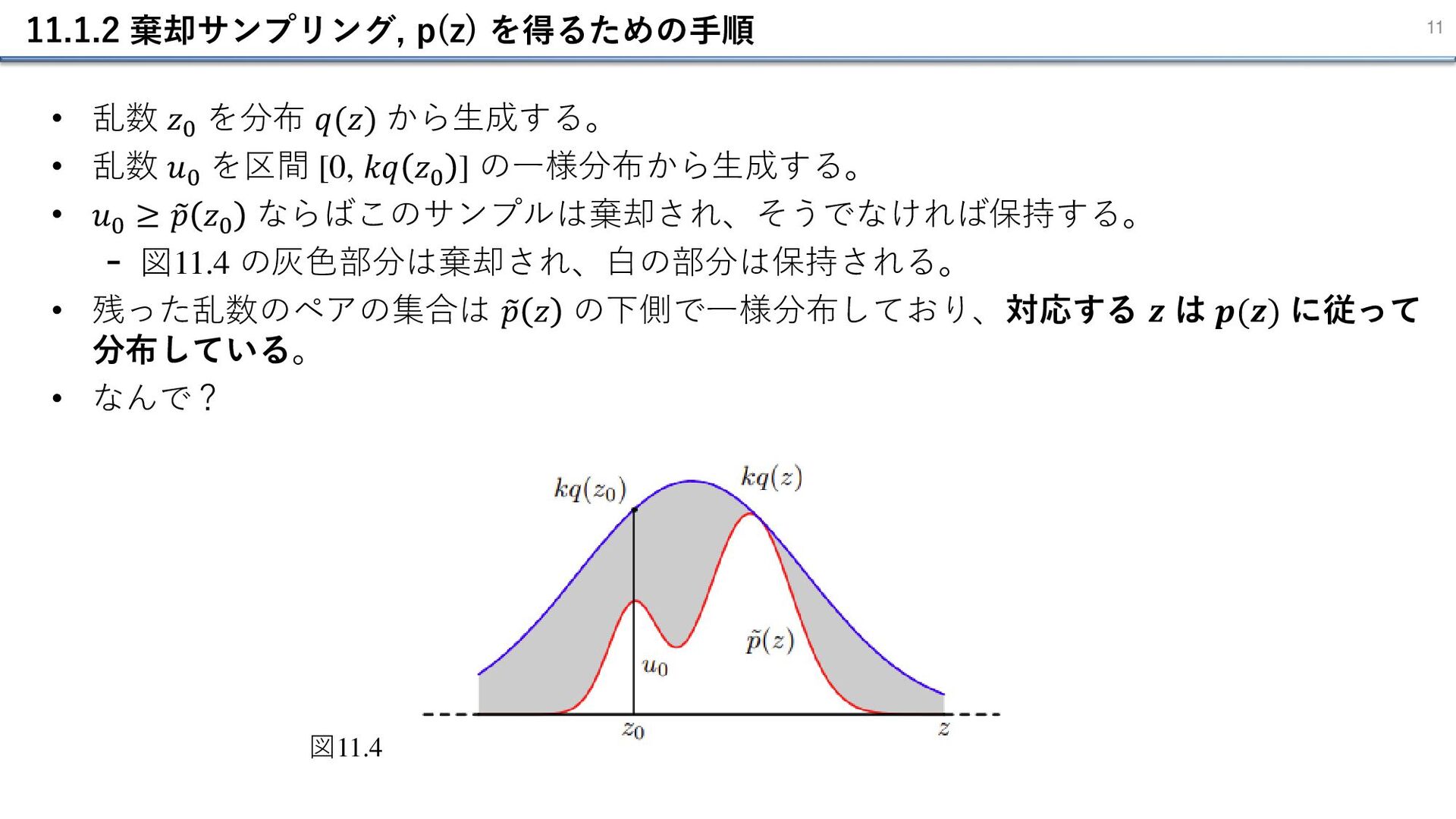
実際によくある、任意の z が与えられたとき、正規化定数 𝑍𝑝 を除いた 𝑝 𝑧 を求めること は容易であるという状況について考える。 𝑝 𝑧 = 1 𝑍𝑝 𝑝 𝑧 (1.13) • ここで、容易にサンプリング可能な単純な分布 𝑞 𝑧 を考える。これを提案分布と呼ぶ。 - 𝑞 𝑧 を使って z をサンプリングし、 𝑝 𝑧 を表現することが目的 - 定数 k を用意し、全ての z に対して 𝑘𝑞 𝑧 ≥ 𝑝 𝑧 が成立するように k を定める。 ➢図11.4 のような状況になる。 ➢続いて、乱数を生成して𝑝 𝑧 を得る手順を踏む。 図11.4
11.1.2 棄却サンプリング, p(z) を得るための手順 11 • 乱数 𝑧0 を分布 𝑞(𝑧)
から生成する。 • 乱数 𝑢0 を区間 [0, 𝑘𝑞 𝑧0 ] の一様分布から生成する。 • 𝑢0 ≥ 𝑝 𝑧0 ならばこのサンプルは棄却され、そうでなければ保持する。 - 図11.4 の灰色部分は棄却され、白の部分は保持される。 • 残った乱数のペアの集合は 𝑝 𝑧 の下側で一様分布しており、対応する 𝒛 は 𝒑(𝒛) に従って 分布している。 • なんで? 図11.4
11.1.2 棄却サンプリング, p(z) を得るための手順 12 • 演習11.6 𝑝 受理 =
∫ 𝑝 𝑧 𝑘𝑞 𝑧 𝑞 𝑧 𝑑𝑧 = 1 𝑘 ∫ 𝑝 𝑧 𝑑𝑧 = 𝑍𝑝 𝑘 (11.14) 𝑝 𝑧|受理 = 𝑝 𝑧, 受理 𝑝 受理 = 𝑝 受理 𝑧 𝑞 𝑧 𝑍𝑝 𝑘 = 𝑘 𝑍𝑝 𝑝 𝑧 𝑘𝑞 𝑧 𝑞 𝑧 = 𝒑(𝒛) • ガンマ分布のサンプリングについて、提案分布をコーシー分布とした棄却サンプリングを 具体的に使ってみる問題が演習11.7
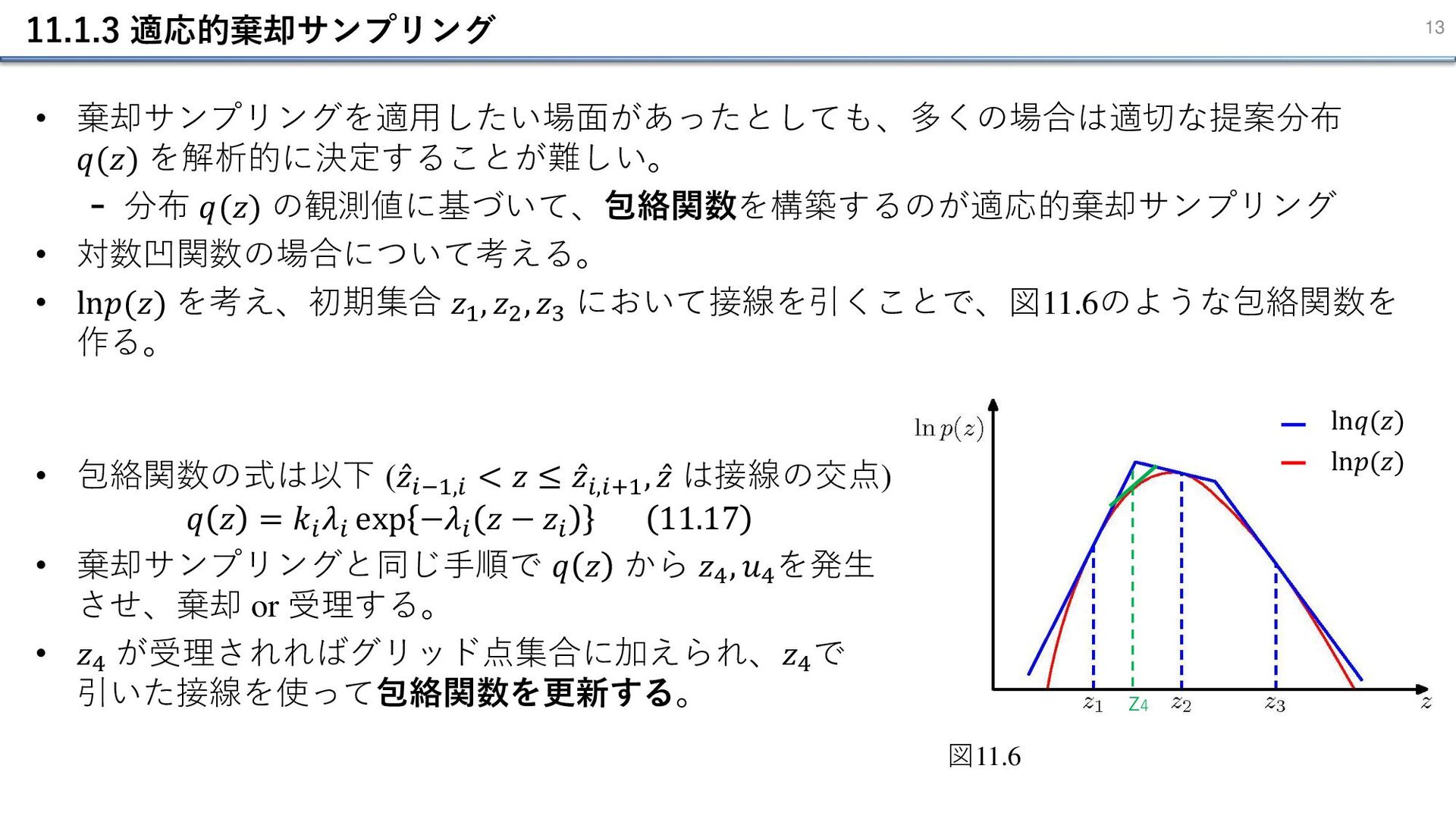
11.1.3 適応的棄却サンプリング 13 • 棄却サンプリングを適用したい場面があったとしても、多くの場合は適切な提案分布 𝑞(𝑧) を解析的に決定することが難しい。 - 分布 𝑞(𝑧)
の観測値に基づいて、包絡関数を構築するのが適応的棄却サンプリング • 対数凹関数の場合について考える。 • ln𝑝(𝑧) を考え、初期集合 𝑧1 , 𝑧2 , 𝑧3 において接線を引くことで、図11.6のような包絡関数を 作る。 z4 図11.6 • 包絡関数の式は以下 ( Ƹ 𝑧𝑖−1,𝑖 < 𝑧 ≤ Ƹ 𝑧𝑖,𝑖+1 , Ƹ 𝑧 は接線の交点) 𝑞 𝑧 = 𝑘𝑖 𝜆𝑖 exp −𝜆𝑖 𝑧 − 𝑧𝑖 11.17 • 棄却サンプリングと同じ手順で 𝑞 𝑧 から 𝑧4 , 𝑢4 を発生 させ、棄却 or 受理する。 • 𝑧4 が受理されればグリッド点集合に加えられ、𝑧4 で 引いた接線を使って包絡関数を更新する。 ln𝑝(𝑧) ln𝑞(𝑧)
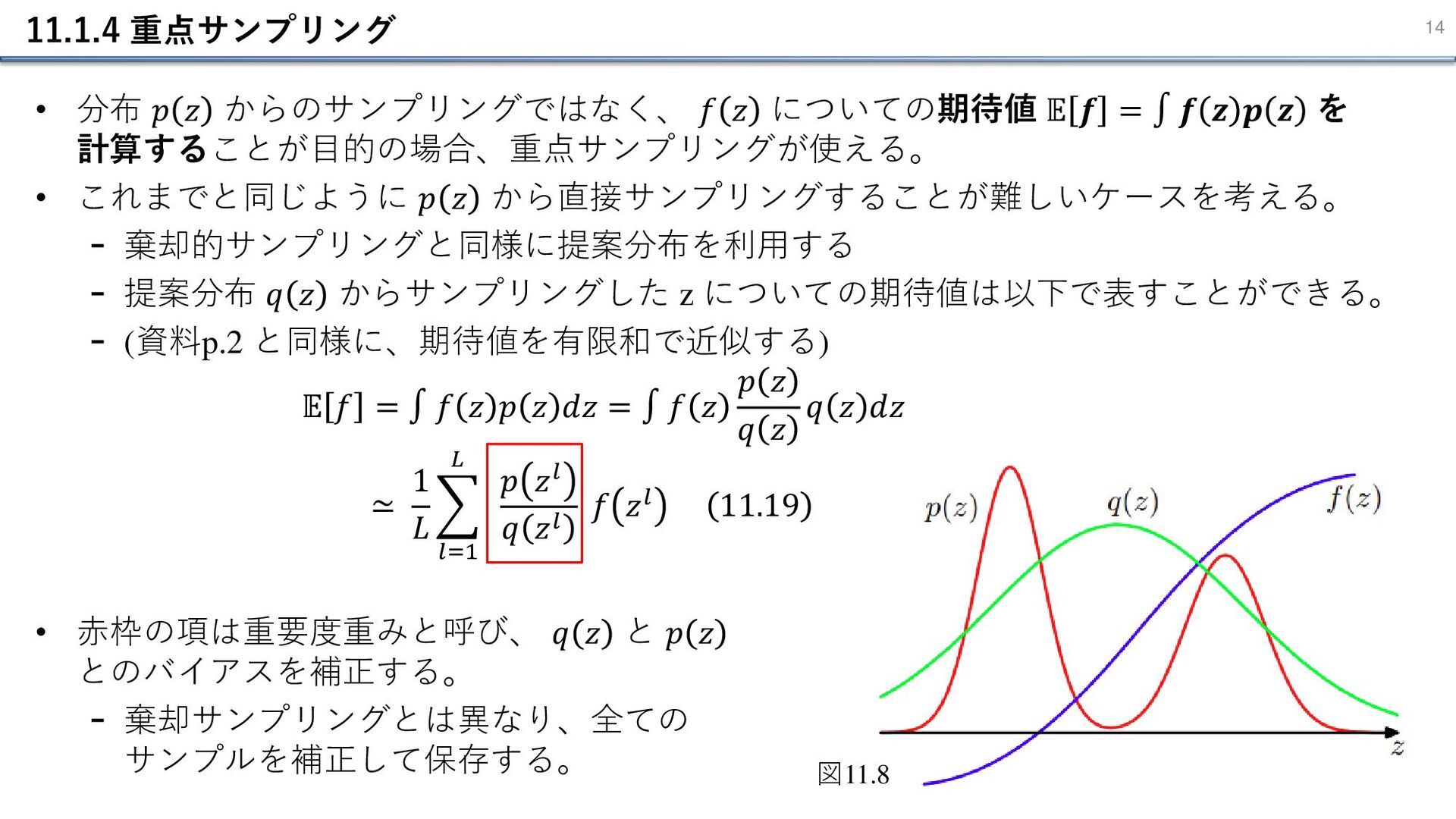
11.1.4 重点サンプリング 14 • 分布 𝑝 𝑧 からのサンプリングではなく、 𝑓 𝑧
についての期待値 𝔼 𝒇 = ∫ 𝒇 𝒛 𝒑 𝒛 を 計算することが目的の場合、重点サンプリングが使える。 • これまでと同じように 𝑝 𝑧 から直接サンプリングすることが難しいケースを考える。 - 棄却的サンプリングと同様に提案分布を利用する - 提案分布 𝑞 𝑧 からサンプリングした z についての期待値は以下で表すことができる。 - (資料p.2 と同様に、期待値を有限和で近似する) 𝔼 𝑓 = ∫ 𝑓 𝑧 𝑝 𝑧 𝑑𝑧 = ∫ 𝑓 𝑧 𝑝 𝑧 𝑞 𝑧 𝑞 𝑧 𝑑𝑧 ≃ 1 𝐿 𝑙=1 𝐿 𝑝 𝑧𝑙 𝑞 𝑧𝑙 𝑓 𝑧𝑙 11.19 • 赤枠の項は重要度重みと呼び、 𝑞 𝑧 と 𝑝 𝑧 とのバイアスを補正する。 - 棄却サンプリングとは異なり、全ての サンプルを補正して保存する。 図11.8
15 • 分布 𝑝 𝑧 が正規化定数 𝑍𝑝 を除いてしか評価できない場合においても、有限和近似を使 うことで期待値を計算できる。 𝔼
𝑓 = ∫ 𝑓 𝑧 𝑝 𝑧 𝑑𝑧 = 𝑍𝑞 𝑍𝑝 ∫ 𝑓 𝑧 𝑝 𝑧𝑙 𝑞 𝑧𝑙 𝑞 𝑧 𝑑𝑧 ≃ 𝑍𝑞 𝑍𝑝 1 𝐿 𝑙=1 𝐿 𝑟𝑙 𝑓 𝑧 11.20 • 同じサンプル集合を、 𝑍𝑝 /𝑍𝑞 を計算するために使うことができ、 𝑍𝑝 𝑍𝑞 = 1 𝑍𝑞 ∫ 𝑝 𝑧 𝑑𝑧 = 1 𝑍𝑞 ∫ 𝑝 𝑧 𝑑𝑧 𝑞 𝑧 𝑞 𝑧 = ∫ 𝑝 𝑧𝑙 𝑞 𝑧𝑙 𝑞 𝑧 𝑑𝑧 ≃ 1 𝐿 𝑙=1 𝐿 𝑟𝑙 11.21 • 式11.20と式11.21より、 𝔼 𝑓 ≃ 𝑙=1 𝐿 𝑟𝑙 σ𝑚 𝑟𝑚 𝑓 𝑧𝑙 = 𝑙=1 𝐿 𝑤𝑙 𝑓 𝑧𝑙 11.22 , (11.23) 重要度重みを ǁ 𝑟𝑙 にまとめた 正規化定数が計算できなくても期待値を計算できた。 重み 𝑤𝑙 とする 11.1.4 重点サンプリング
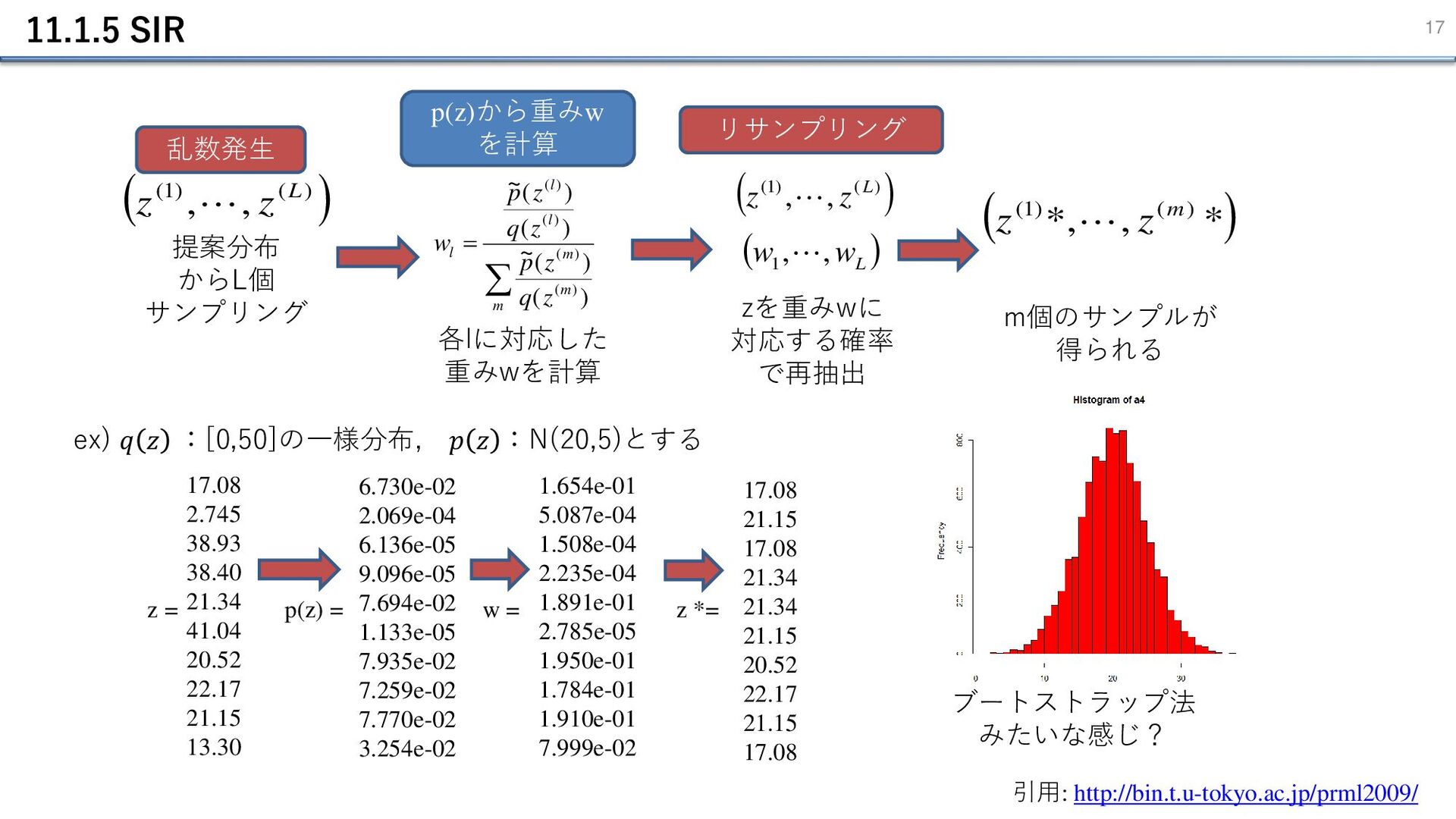
11.1.5 SIR 16 • 棄却サンプリングで、 𝑝 𝑧 を完全に覆うような 𝒒 𝒛
を選ぶことが難しい - 受理される確率が非常に低くなるケースも多く存在する。 • そこで、重点サンプリングの重要度重みを活用したサンプリング手法が考案された。 - SIR (Sampling-Importance-Resampling) • 第1段階:提案分布 𝑞 𝑧 から、L 個のサンプル 𝑧1 , 𝑧2 , … 𝑧𝐿 を抽出する。 • 第2段階:次式によって重み w を計算する 𝑤𝑙 = 𝑟𝑙 σ𝑚 𝑟𝑚 = 𝑝 𝑧𝑙 /𝑞(𝑧𝑙) σ𝑚 𝑝 𝑧𝑚 /𝑞(𝑧𝑚) (11.23) • 最後に、 𝑧 から 𝑤 で与えられる確率に従ってリサンプリングする。 • これは L → ∞ では分布は正確に従うことが証明されている。
11.1.5 SIR 17 ( ) ) ( ) 1 (
, , L z z 提案分布 からL個 サンプリング zを重みwに 対応する確率 で再抽出 乱数発生 各lに対応した 重みwを計算 p(z)から重みw を計算 リサンプリング = m m m l l l z q z p z q z p w ) ( ) ( ~ ) ( ) ( ~ ) ( ) ( ) ( ) ( ( ) ) ( ) 1 ( , , L z z ( ) L w w , , 1 ( ) * , *, ) ( ) 1 ( m z z ex) 𝑞 𝑧 :[0,50]の一様分布, 𝑝 𝑧 :N(20,5)とする 17.08 2.745 38.93 38.40 21.34 41.04 20.52 22.17 21.15 13.30 z = p(z) = 6.730e-02 2.069e-04 6.136e-05 9.096e-05 7.694e-02 1.133e-05 7.935e-02 7.259e-02 7.770e-02 3.254e-02 w = 1.654e-01 5.087e-04 1.508e-04 2.235e-04 1.891e-01 2.785e-05 1.950e-01 1.784e-01 1.910e-01 7.999e-02 z *= 17.08 21.15 17.08 21.34 21.34 21.15 20.52 22.17 21.15 17.08 ブートストラップ法 みたいな感じ? m個のサンプルが 得られる 引用: http://bin.t.u-tokyo.ac.jp/prml2009/
11.1.6 サンプリングとEMアルゴリズム 18 • EMアルゴリズムのMステップで求める期待値は以下 𝑄 𝜃, 𝜃𝑜𝑙𝑑 = ∫
𝑝 𝐙 𝐗, 𝜃𝑜𝑙𝑑 ln𝑝 𝐙, 𝐗 𝜃 𝑑𝐙 • Eステップでは、 𝑝 𝐙 𝐗, 𝜃𝑜𝑙𝑑 を計算する必要があるが、これが解析的に計算できないこ とがある。 • → Zの事後分布をサンプリングすることで期待値を計算する。 • この後は、通常のMステップと同様の方法で最適化される。 • この手続きを、モンテカルロEMアルゴリズムと呼ぶ。 𝑄 𝜃, 𝜃𝑜𝑙𝑑 = ∫ 𝑝 𝐙 𝐗, 𝜃𝑜𝑙𝑑 ln𝑝 𝐙, 𝐗 𝜃 𝑑𝐙 ≃ 1 𝐿 𝑙=1 𝐿 ln𝑝 𝐙(𝑙), 𝐗 𝜃
11.2 マルコフ連鎖モンテカルロ 19 • 11.1 でみたサンプリング法は、高次元空間において問題が生じることが多い。 • マルコフ連鎖モンテカルロ(MCMC) はサンプル空間の次元が大きくても機能する。 •
MCMCでは、棄却サンプリングなどと同様に提案分布を用いる。 - 現在の状態 𝑧 𝜏 の記録を保持し、 𝑧(𝜏) に依存する提案分布 𝑞 𝑧|𝑧(𝜏) を使う。 - このとき、サンプル系列 𝑧 1 , 𝑧 2 , … はマルコフ連鎖をなす。 • 簡単な例:Metropolis アルゴリズム - 対称な提案分布 𝑞 𝑧|𝑧(𝜏) からサンプル候補 𝑧∗ をサンプリングする。 ➢ 対称な分布では 𝑧𝐴 と 𝑧𝐵 の全ての値に対して 𝑞 𝑧𝐴 |𝑧𝐵 = 𝑞 𝑧𝐵 |𝑧𝐴 - サンプル候補を、確率 𝐴 𝑧∗, 𝑧𝜏 = min 1, 𝑝 𝑧∗ 𝑝 𝑧 𝜏 で受理する。 ➢ 𝑧(𝜏) から 𝑧∗ へのステップが 𝑝 𝑧 を増加させるなら、 𝑧∗ は必ず受理される。 - 受理されれば 𝑧(𝜏+1) = 𝑧∗ とし、このサイクル を繰り返す。 ➢ 棄却された場合は 𝑧(𝜏+1) = 𝑧(𝜏)
11.2 Metropolisアルゴリズムの具体例 20 • 𝑝 𝑧 は2次元のガウス分布 (標準偏差が黒で示されている) で、提案分布 𝑞
𝑧|𝑧(𝜏) は標準 偏差 0.2 の等方ガウス分布。 - 図11.9 で、緑が受理されたステップ、赤が棄却されたステップ 図11.9 • https://visualize-mcmc.appspot.com/2_metropolis.html - 𝑞 𝑧|𝑧(𝜏) は中心 𝑧(𝜏) で標準偏差0.2のガウス分布
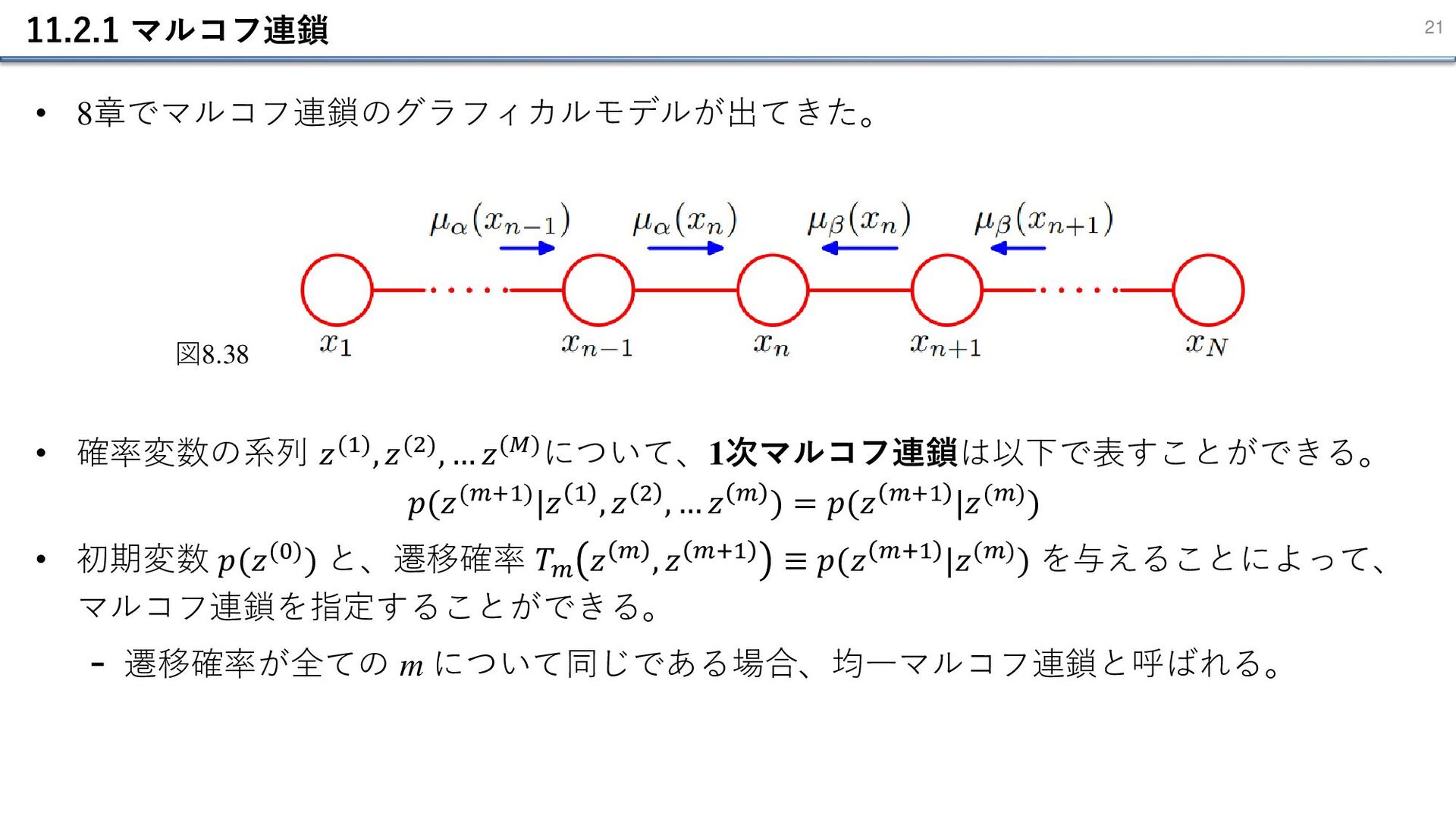
11.2.1 マルコフ連鎖 21 • 8章でマルコフ連鎖のグラフィカルモデルが出てきた。 • 確率変数の系列 𝑧(1), 𝑧(2), …
𝑧(𝑀)について、1次マルコフ連鎖は以下で表すことができる。 𝑝(𝑧(𝑚+1)|𝑧 1 , 𝑧 2 , … 𝑧 𝑚 ) = 𝑝(𝑧 𝑚+1 |𝑧(𝑚)) • 初期変数 𝑝(𝑧(0)) と、遷移確率 𝑇𝑚 𝑧 𝑚 , 𝑧 𝑚+1 ≡ 𝑝(𝑧 𝑚+1 |𝑧(𝑚)) を与えることによって、 マルコフ連鎖を指定することができる。 - 遷移確率が全ての m について同じである場合、均一マルコフ連鎖と呼ばれる。 図8.38
11.2.1 マルコフ連鎖 22 • マルコフ連鎖で周辺確率は以下で表される。 𝑝(𝑧(𝑚+1)) = 𝑧(𝑚) 𝑝(𝑧(𝑚+1)|𝑧(𝑚))
𝑝 𝑧 𝑚 11.38 • 分布がマルコフ連鎖の各ステップで変わらないとき、その分布は不変と呼ばれる。 - すなわち、遷移確率 𝑇 𝑧′, 𝑧 である均一マルコフ分布において以下が成り立つ。 𝑝∗ 𝑧 = 𝑧′ 𝑇 𝑧′, 𝑧 𝑝∗ 𝑧′ (11.39) • 具体例:右図(簡単な離散変数 z) - z は天気を表す晴と雨 - 不変分布は、 𝑝∗ 晴 = 4 7 、 𝑝∗ 雨 = 3 7 - サンプル数を増やしていくにつれて、 不変分布 𝑝∗ 𝑧 に収束していく。 引用: http://bin.t.u-tokyo.ac.jp/prml2009/
11.2.1 マルコフ連鎖 23 • 求めたい分布 𝑝 𝑧 が不変であることの十分条件は、 𝑝∗ 𝑧
𝑇 𝑧, 𝑧′ = 𝑝∗ 𝑧′ 𝑇 𝑧′, 𝑧 11.40 • で定められる詳細釣り合い条件が満たされるように遷移確率を選ぶことである。 - 𝑧 → 𝑧′ と、逆方向の 𝑧′ → 𝑧 で周辺確率×遷移確率が同じ量になっている - 化学平衡みたいな感じ。 - 詳細釣り合い条件を満たすマルコフ連鎖は可逆であると言われる。
11.2.2 Metropolis-Hastings アルゴリズム 24 • Metropolisアルゴリズムは、提案分布が対称である特殊な場合に用いることができるサンプ リング法であった。 • Metropolis-Hastingsは、Metropolisアルゴリズムの提案分布について一般化したもの -
非対称な提案分布でも使える。 - 等方ガウス分布は対称、そうでないガウス分布は非対称 • サンプリングの手順 - 提案分布 𝑞(𝑧) から 𝑧∗ をサンプリング - 𝑧(𝜏) から 𝑧∗ への遷移について、下記の確率でサンプルを受理 or 棄却する。 𝐴𝑘 𝑧∗, 𝑧(𝜏) = min 1, 𝑝 𝑧∗ 𝑞𝑘 (𝑧(𝜏)|𝑧∗) 𝑝 𝑧 𝜏 𝑞𝑘 (𝑧∗|𝑧(𝜏)) 11.44 ➢ 非対称な分布でも詳細釣り合い条件を満たすように一般化されている。 ➢ 対称な分布、すなわち 𝑞𝑘 𝑧 𝜏 𝑧∗ = 𝑞𝑘 (𝑧∗|𝑧(𝜏)) のとき、Metropolisアルゴリズムが 再現される。
11.2.2 Metropolis-Hastings アルゴリズム 25 • 式11.44 の 𝐴𝑘 𝑧∗, 𝑧(𝜏)
を使うと、Metropolis-Hastingsアルゴリズムで定義されるマルコフ連 鎖で 𝑝(𝑧) が不変分布になることを示すことができる。 - そのために詳細釣り合い条件が満たされることを示す - 順番を入れ替えても一致することを確認するだけ 𝑝 𝑧 𝑞𝑘 𝑧′ 𝑧 𝐴𝑘 𝑧′, 𝑧 = min 𝑝 𝑧 𝑞𝑘 𝑧′ 𝑧 , 𝑝 𝑧′ 𝑞𝑘 𝑧 𝑧′ = min 𝑝 𝑧′ 𝑞𝑘 𝑧 𝑧′ , 𝑝 𝑧 𝑞𝑘 𝑧′ 𝑧 = 𝑝 𝑧′ 𝑞𝑘 𝑧 𝑧′ 𝐴𝑘 𝑧, 𝑧′ (11.45)
まとめ 26 • 11.1 章ではMCMC以外、11.2 章ではMCMCの一部のサンプリング法について説明した - 逆関数法 ➢解析的に正しいけど複雑な分布で逆関数を求めることはほとんどできない -
棄却サンプリング ➢複雑な分布に適用可能であるが、適切な提案分布や k を選ぶのが難しい - 適応的棄却サンプリング ➢包絡関数で 𝑞 𝑧 を選ぶことができるが接線の計算負荷が高く、また多次元で多峰性 の分布などには適用することができない - 重点サンプリング ➢提案分布との重み付けで期待値を近似するが、分布からサンプリングしない。 - SIR ➢棄却サンプリングに重点サンプリングの重み付けを組み合わせた。リサンプリングの 回数を多くする必要がある • MCMC を使えば、𝑝 𝑧 の初期値によらず一定の確率分布(不変分布)に収束する。 - 複雑な分布でもいい感じにサンプリングできる。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![11.1.1 標準的な分布: 逆関数法 9 [0,1]の一様乱数zを 100000個発生 𝑦 = ℎ−1(𝑧) =](https://files.speakerdeck.com/presentations/881531fcbd4e4befba0b2e9879a58e55/slide_8.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}