Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Deep Learning Chapter 7
Search
shogo-d-nakamura
July 10, 2024
Science
100
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Deep Learning Chapter 7
Deep Learning: Foundations and Concepts
Chapter 7
https://www.bishopbook.com/
shogo-d-nakamura
July 10, 2024
More Decks by shogo-d-nakamura
See All by shogo-d-nakamura
PRML Chapter 1 (1.3-1.6)
snkmr
1
400
PRML Chapter 9
snkmr
1
360
PRML Chapter 5 (5.0-5.4)
snkmr
1
540
PRML Chapter 8 (8.0-8.3)
snkmr
1
380
PRML Chapter 11 (11.0-11.2)
snkmr
1
460
Other Decks in Science
See All in Science
(メタ)科学コミュニケーターからみたAI for Scienceの同床異夢
rmaruy
0
260
機械学習 - 授業概要
trycycle
PRO
0
560
AkarengaLT vol.40
hashimoto_kei
0
110
AI(人工知能)の過去・現在・未来 ~AIは人類を越えるのか~
tagtag
PRO
0
120
Cross-Media Technologies, Information Science and Human-Information Interaction
signer
PRO
3
32k
あなたに水耕栽培を愛していないとは言わせない
mutsumix
1
360
先端因果推論特別研究チームの研究構想と 人間とAIが協働する自律因果探索の展望
sshimizu2006
3
960
次代のデータサイエンティストへ~スキルチェックリスト、タスクリスト更新~
datascientistsociety
PRO
3
46k
俺たちは本当に分かり合えるのか? ~ PdMとスクラムチームの “ずれ” を科学する
bonotake
2
2.5k
(2025) Balade en cyclotomie
mansuy
0
640
「遂行理論の未来」(松島斉教授最終講義記念セッションの発表資料)
shunyanoda
0
930
「念のためのログ保存」を組織全体でやめるためのポリシーと仕組み作り
i2tsuki
4
260
Featured
See All Featured
B2B Lead Gen: Tactics, Traps & Triumph
marketingsoph
0
170
Git: the NoSQL Database
bkeepers
PRO
432
67k
Building AI with AI
inesmontani
PRO
1
1.1k
Everyday Curiosity
cassininazir
0
250
Practical Orchestrator
shlominoach
191
11k
Designing Dashboards & Data Visualisations in Web Apps
destraynor
231
55k
Leo the Paperboy
mayatellez
8
1.9k
Have SEOs Ruined the Internet? - User Awareness of SEO in 2025
akashhashmi
0
390
Jamie Indigo - Trashchat’s Guide to Black Boxes: Technical SEO Tactics for LLMs
techseoconnect
PRO
0
350
Let's Do A Bunch of Simple Stuff to Make Websites Faster
chriscoyier
508
140k
The Power of CSS Pseudo Elements
geoffreycrofte
82
6.4k
The Limits of Empathy - UXLibs8
cassininazir
1
490
Transcript
2024/07/10 D3 中村 Deep Learning Chapter 7
2 7.1 Error Surfaces 7.1.1 Local quadratic approximation 7.2 Gradient
Descent Optimization 7.2.1 Use of gradient information 7.2.2 Batch gradient descent 7.2.3 Stochastic gradient descent 7.2.4 Mini-batches 7.2.5 Parameter initialization 7.3 Convergence 7.3.1 Momentum 7.3.2 Learning rate schedule 7.3.3 RMSProp and Adam 7.4 Normalization 7.4.1 Data normalization 7.4.2 Batch normalization 7.4.3 Layer normalization Contents
3 7. Gradient Descent • 6章までで、Deepが任意の関数を近似できることをみてきた • 7章では、トレーニングデータを基にネットワークの最適なパラメータを求める問題につい て再び考える。 •
これまでにやってきた回帰, 分類では誤差関数を設計したが、パラメータを闇雲に変えて 誤差関数を評価するのは非常に効率が悪い。 ➢そこで、誤差関数の微分である勾配の情報を使う。 ➢ニューラルネットワークを設計する際、誤差関数を微分できるように、活性化関数など 各要素について微分可能な関数が選ばれている。 • 古典的な統計学:尤度関数の最大化 ➢パラメータ数よりもデータ数が大きいことが前提 ➢求められたパラメータ自体がdirect interest • モダンなDeep Learning:単なる尤度関数の最大化=過学習 ➢膨大なパラメータ数を持つモデル ➢正則化などを使いながら汎化能力の獲得を目指す
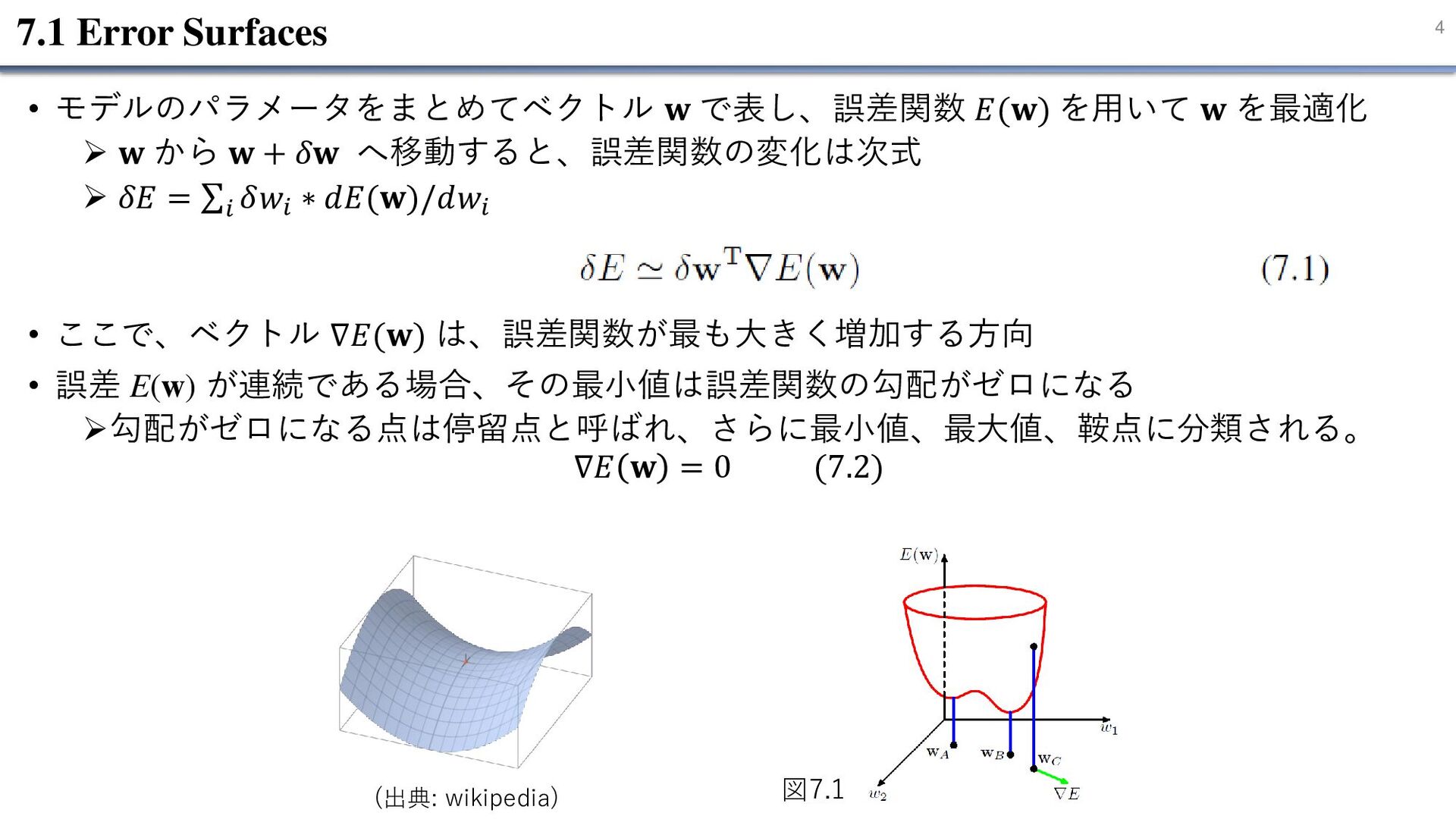
4 7.1 Error Surfaces • モデルのパラメータをまとめてベクトル 𝐰 で表し、誤差関数 𝐸(𝐰) を用いて
𝐰 を最適化 ➢ 𝐰 から 𝐰 + 𝛿𝐰 へ移動すると、誤差関数の変化は次式 ➢ 𝛿𝐸 = σ𝑖 𝛿𝑤𝑖 ∗ 𝑑𝐸(𝐰)/𝑑𝑤𝑖 • ここで、ベクトル ∇𝐸(𝐰) は、誤差関数が最も大きく増加する方向 • 誤差 E(w) が連続である場合、その最小値は誤差関数の勾配がゼロになる ➢勾配がゼロになる点は停留点と呼ばれ、さらに最小値、最大値、鞍点に分類される。 ∇𝐸 𝐰 = 0 (7.2) 図7.1 (出典: wikipedia)
5 7.1 Error Surfaces • E(w) が最小値を取るようなベクトル w を見つけることを目指す •
しかし、E(w)は通常、重みとバイアスパラメータに非常に非線形に依存する ➢重み空間には勾配がゼロになる(または数値的に非常に小さくなる)点が多数存在 • 重み空間全体にわたって誤差関数が最小値を取る点は、大域最適解 と呼ばれる。 • 誤差関数がより大きな値を取る他の極小値はすべて、局所最適解 と呼ばれる。 • 従来、深層学習モデルの E(w) は非常に複雑になる可能性があり、勾配ベースの方法は性能 の低い局所最適に陥ってしまうと考えられていた。 ➢実際には、大規模なネットワークは様々な初期条件下で同程度の性能を持つ解に到達す ることができる。 大域最適解 局所最適解 図7.1
6 7.1.1 Local quadratic approximation • 誤差関数の局所的な2次近似を考えることで、最適化問題とそのさまざまな解法に対する洞 察を得ることができる。 • 𝐸(𝐰)
について、点 ෝ 𝐰 の周りで2次のテイラー展開 • (7.3)より、両辺を微分して対応する勾配の局所的な近似が得られる。 1 2 𝐰 − ෝ 𝐰 T𝐇 𝐰 − ෝ 𝐰 = 𝑖𝑗 𝜕2 𝜕𝑤𝑖 𝜕𝑤𝑗 𝐸(𝐰) 𝑤𝑖 − ෝ 𝑤𝑖 𝑤𝑗 − ෝ 𝑤𝑗 • ෝ 𝐰 に十分近い点に対しては、これらの式で近似できる。
7 7.1.1 Local quadratic approximation • 𝐸(𝐰)の最小値である点 w* の周りでの局所的な2次近似について考える。 •
この場合、w* において ∇𝐸 𝐰 = 0 であるため、1次の項が消える • これを幾何的に解釈するために、ヘッセ行列の固有値問題を考える。 • 完全な正規直交系を形成するため、 𝑖 = 𝑗 のとき、 𝛿𝑖𝑗 = 1 𝑖 ≠ 𝑗 のとき、𝛿𝑖𝑗 = 0 ➢固有ベクトルが直交しており、かつ長さが 1 で正規化されていることを意味する
8 7.1.1 Local quadratic approximation • ここで、(w - w*) を以下の形で展開
➢原点が点 w* に移動し、軸が{𝐮1 , … , 𝐮𝑊 } 固有ベクトルに沿って回転される座標系の変換 とみなすことができる。 • (7.10) を (7.7) に代入し、(7.8) と (7.9) を使用すると、誤差関数は以下 ➢𝐮𝑖 T𝐮𝑖 が出て1になる • 𝑖 ≠ 𝑗 に対してすべての 𝛼𝑖 = 0 とし、𝛼𝑗 を変化させた時について考える ➢これは、𝐮𝑗 方向に wを w* から遠ざけることに対応する。 ➢𝐸(𝐰)は 𝜆𝑗 が正の場合に増加し、負の場合は減少 ➢すべての固有値が正の場合 w は局所最適解、すべてが負の場合 w は局所最大値 ➢正と負の固有値が混在している場合、w は鞍点
9 7.1.1 Local quadratic approximation • 行列 H は、以下の場合に限り、正定値と呼ばれる。 •
任意のベクトル vを固有ベクトル {𝐮𝑖 } を使って以下に設定 • (7.8) から、 • Hの全ての固有値が正である場合に限り、H は正定値になる。 • 前ページの議論(すべての固有値が正=w は局所最適解) から、w が局所最適解であるための必要十分条件は以下 ➢ w において∇𝐸 𝐰 = 0 ➢ w* 周りでのHが正定値 ✓ 正定値=全ての固有値が正=全ての軸に対して 𝛼 を動かすと誤差関数が増加= w*は局所最適解 • 𝐸 𝐰 の等高線は、図7.2のような楕円になる。 図7.2
10 7.1.1 Local quadratic approximation • 𝐸 𝐰 の等高線は、図7.2のような楕円になる事の説明 ➢𝑖
= 1, 2 の場合について考えると、 ➢𝐸 𝐰 = 𝐸 𝐰∗ + 1 2 𝛼1 1 𝜆1 + 𝛼2 1 𝜆2 ➢等高線を考えているので𝐸 𝐰 を定数にする ➢𝐶 = 𝛼1 1 𝜆1 + 𝛼2 1 𝜆2 ➢よく見る形: 𝑥2 𝑎2 + 𝑦2 𝑏2 = 1 ➢ 固有値の大きさのバラつきによって 誤差関数の形が分かる 図7.2 𝑢1 , 𝑢2 は完全直行基底ベクトルなので 長さ1のベクトル
11 7.1 Error Surfaces 7.1.1 Local quadratic approximation 7.2 Gradient
Descent Optimization 7.2.1 Use of gradient information 7.2.2 Batch gradient descent 7.2.3 Stochastic gradient descent 7.2.4 Mini-batches 7.2.5 Parameter initialization 7.3 Convergence 7.3.1 Momentum 7.3.2 Learning rate schedule 7.3.3 RMSProp and Adam 7.4 Normalization 7.4.1 Data normalization 7.4.2 Batch normalization 7.4.3 Layer normalization Contents
12 7.2 Gradient Descent Optimization • ニューラルネットワークによって定義されるような複雑な誤差関数に対して、∇E(w) = 0 の
方程式の解析解を見つけることは 難しく、反復的な数値計算手順に頼ることになる。 • ほとんどの手法では、重みベクトル w に対して何らかの初期値 𝐰 0 を選択し、次のような ステップを繰り返しながら重み空間を移動していく。 ➢ 𝜏: 反復ステップ数 • 単純なニューラルネットワークの場合を除いて、誤差関数の形状は複雑 ➢見つかる解は、初期パラメータ値 𝐰 0 の選択に依存 • 十分に良い解を見つけるためには、勾配ベースのアルゴリズムを、異なるランダムに選択さ れた開始点から開始して複数回実行し、独立したvalidation setにおける結果のパフォーマン スを比較する必要があるかもしれない。
13 7.2.1 Use of gradient information • 誤差関数の勾配は、誤差逆伝播で効率的に評価することが可能 • 式(7.3)で与えられる誤差関数の二次近似では、誤差関数の形状は
b と H で指定される。 • 学習可能なパラメータ w の次元数をWとしたとき、b と H は合計で 𝑊 + 𝑊(𝑊 + 1)/2 = 𝑊(𝑊 + 3)/2 個の要素を持つ ➢行列 H は対称行列 • 二次近似の最小値の位置は、𝑂(𝑊2) 個の独立な項に依存 • 𝑂(𝑊2) 個の独立した情報が得られるまでは、最小値を見つけ出すことはできないかも ➢𝑂(𝑊2) 個のパラメータそれぞれを動かしてみて、𝐸(𝐰)の挙動を調べる必要があり、この 操作をだいたい 𝑂(𝑊2) 回程度繰り返す必要がありそう と言っているっぽい • 上記の𝑂(𝑊2)個のパラメータを動かす操作で 𝐸(𝐰) が下がる方向を探すステップが、おそら く 𝑂(𝑊) くらい必要 (?) • トータルで 𝑂 𝑊2 × 𝑂 𝑊 = 𝑂(𝑊3) くらい計算量がいる(?)
14 7.2.1 Use of gradient information • これを、勾配情報を利用するアルゴリズムと比較 • ∇𝐸
は長さ W のベクトルなので、∇𝐸 を 1 回評価するごとに W 個の情報が得られる ➢ 𝑂(𝑊) 回の勾配評価で関数の最小値を見つけられると期待できる(?) • 誤差逆伝播法を用いることで、このような評価はそれぞれ 𝑂(𝑊) ステップしかかからず(?)、 最小値は 𝑂 𝑊 × 𝑂 𝑊 = 𝑂(𝑊2) ステップで見つけることができる。 • ここはPRML5.2.3と同じ内容だがフワっとしている ➢パラメータ更新の回数が 𝑂(𝑊) とか突然出てきて経験的な話(?) • とりあえず勾配情報があると、パラメータを動かしまくってある点 𝐰 𝜏 周りでの誤差関数 𝐸(𝐰)の形を知るより、勾配情報を使って 𝐸(𝐰) が小さくなる方向にパラメータを動かして いった方が計算コストが小さくなるということを理解していればいいんでしょうか?
15 7.2.2 Batch gradient descent • 勾配情報を利用する最も単純なアプローチは、式(7.15)における重みの更新を、負の勾配方 向への小さなステップとなるように選択することである。 ➢ η
> 0: 学習率 • このような更新を行うたびに、新しい重みベクトル 𝐰 𝜏 に対して勾配を再評価 • 各ステップにおいて、重みベクトルは誤差関数が最も大きく減少する方向に移動するため、 このアプローチは勾配降下法または最急降下法と呼ばれる。 • 誤差関数は学習セットに対して定義されているため、∇𝐸 を評価するには、各ステップで学 習セット全体を処理する必要がある。 • 学習データセット全体を一度に使用する手法は、バッチ法と呼ばれる。
16 7.2.3 Stochastic gradient descent • 大規模なデータセットだと全体を処理するのに時間がかかり非効率 • 一連の独立した観測値に対する誤差関数は、各データ点に対する項の和で構成される •
大規模なデータセットに対して最も広く用いられている学習アルゴリズムは、確率的勾配降 下法 (Stochastic Gradient Descent, SGD ) ➢一度に 1 つのデータ点に基づいて重みベクトルを更新 (勾配降下法の逐次バージョン) • 学習セット全体を 1 回パスすることを、1エポックと呼ぶ。 • SGDは局所最小値から抜け出せる可能性がある ➢データセット全体に対する誤差関数の停留点が、個々のデータ点に対する停留点ではな いことが一般的であるため。
17 7.2.4 Mini-batches • 確率的勾配降下法の欠点 ➢1 つのデータ点から計算された誤差関数の勾配のノイズが大きい • バッチ法とSGDの中間:ミニバッチ法 ➢データ点の小さなサブセットを使用して、反復ごとに勾配を評価
• ミニバッチを使用する際の注意事項 ➢一部のハードウェアプラットフォームでは、2 の累乗(たとえば、64、128、256、...)の ミニバッチサイズが適している。 ➢ミニバッチを構成するデータ点をデータセットからランダムに選択する必要がある ✓生のデータセットでは、データの収集方法に起因する連続するデータ点間の相関関 係が存在する可能性があるため。 ✓データセットを反復処理するたびにデータセットを再シャッフルする。 ➢ミニバッチを使用する場合でも、学習アルゴリズムは多くの場合、「確率的勾配降下 法」と呼ばれる。
18 7.2.5 Parameter initialization • 勾配降下法などの反復アルゴリズムでは、学習するパラメータに何らかの初期設定を選択す る必要がある。 • 初期化の方法によって、解に到達するまでの時間や、結果として得られる学習済みネット ワークの汎化性能が大きく異なる場合がある。
➢残念ながら、初期化戦略の指針となる理論は比較的少ない。 • 重要な考慮事項の 1 つは、対称性の解消 ➢同じ入力を受け取る隠れユニットまたは出力ユニットのセットを考える。 ➢すべてのパラメータがゼロに設定されるなど、同じ値で初期化された場合、これらのユ ニットのパラメータはすべて一斉に更新され、各ユニットは同じ関数を計算するため、 冗長になってしまう。 ➢この問題は、対称性を崩すために、何らかの分布からパラメータをランダムに初期化す ることで対処できる。 ➢計算リソースが許せば、異なるランダムな初期化からネットワークを複数回学習させ、 結果を比較することもできる。 対称性がある=ユニットの線形変換で別のユニットを表せる=冗長
19 7.2.5 Parameter initialization: He initialization • 重みの初期化には、 [−𝜖, 𝜖]
の範囲の一様分布か、𝑁(0, 𝜖2) のガウス分布がよく利用される。 • 𝜀 の値の選択は重要であり、選択のためのさまざまなヒューリスティックが提案されている。 ➢広く用いられているアプローチの 1 つに、He 初期化と呼ばれるものがある (He et al., 2015b)。 ✓今年の2月末に輪講した論文で登場してた • pytorch では呼び出すレイヤーごとに初期化方法が違うらしい ➢ nn.Linear はデフォルトで Kaiming initialization が使われている ✓ He initialization は、Kaiming He さんが提案したので Kaiming initialization と呼ばれる こともある
20 7.2.5 Parameter initialization: He initialization • He initiallization •
層 𝑙 が次の変換を評価するネットワークを考える。 ➢ 1個前(𝑙 − 1層)にM個のユニットがあるとすると、 𝑙 層目の 𝑖 番目のユニットの 𝑎 𝑖 𝑙 , 𝑧 𝑖 𝑙 は以下で表される。 • 重みをガウス分布 𝑁 0, 𝜀2 を用いて初期化し、層 (l-1) のユニットの出力 𝑧 𝑗 𝑙−1 の分散が 𝜆2で あるとすると、
21 7.2.5 Parameter initialization: He initialization • 導出 • 𝑎
𝑖 𝑙 の期待値をとる ➢𝔼 𝑤𝑖𝑗 = 0 なので0になる 𝔼 𝑎 𝑖 𝑙 = Σ𝑗=1 𝑀 𝔼 𝑤𝑖𝑗 𝑧 𝑗 𝑙−1 = Σ𝑗=1 𝑀 𝔼 𝑤𝑖𝑗 𝔼 𝑧 𝑗 𝑙−1 = 0
22 7.2.5 Parameter initialization: He initialization • var[𝑎 𝑖 𝑙
]の計算 (ReLU 𝑥 = max(0, 𝑥), 分散の対称性を利用)
23 7.2.5 Parameter initialization: He initialization • 理想的には活性化の分散が、ある層から次の層に伝播する際に、ゼロに減衰したり、大幅に 増加したりしないようにしたい。 ➢多層になったときに活性化関数の出力が0に収束したり発散したりしたら困る
• 層 𝑙 のユニットの分散も 𝜆2 であることを要求する(=分散が一定になることを要求する)と、 初期化に用いるガウス分布の標準偏差として、以下が得られる。 var 𝑧 𝑗 𝑙 = 𝑀 2 𝜖2𝜆2 = 𝜆2 • 初期化の分布のスケール 𝜖 をハイパーパラメータとして扱い、複数の学習実行にわたって異 なる値を探索することも考えられる。
24 7.1 Error Surfaces 7.1.1 Local quadratic approximation 7.2 Gradient
Descent Optimization 7.2.1 Use of gradient information 7.2.2 Batch gradient descent 7.2.3 Stochastic gradient descent 7.2.4 Mini-batches 7.2.5 Parameter initialization 7.3 Convergence 7.3.1 Momentum 7.3.2 Learning rate schedule 7.3.3 RMSProp and Adam 7.4 Normalization 7.4.1 Data normalization 7.4.2 Batch normalization 7.4.3 Layer normalization Contents
25 7.3 Convergence • 勾配降下法を適用する際に、学習率パラメータ 𝜂 の値を選択する必要がある。 • 2次元重み空間において、誤差関数の曲率が方向によって大きく異なり、「谷」が形成され ている場合について考える。
➢ 𝜂 の値を大きくすると、重み空間を大きく動くことができるが、振動が発散してしまう こともあるため、ある程度小さく保つ必要がある。 • 最小値付近における誤差関数の2次近似を考えることで、より深く理解することができる。 ➢式(7.7)、(7.8)、(7.10)より、(7.24), (7.25)が導出できる。 図7.3
26 7.3 Convergence • (7.25) では、重みベクトルの変化を対応する係数 {𝛼𝑖 } の変化で表している。 •
式(7.25)と勾配降下法の式(7.16)を組み合わせ、ヘッセ行列の固有ベクトルに対する正規直交 関係式(7.9)を用いると 𝛼𝑖 の変化について、更新式(7.27)が得られる。 ➢𝛼𝑜𝑙𝑑: 更新前、𝛼𝑛𝑒𝑤: 更新後 • 固有ベクトルの正規直交関係式(7.9)と式(7.10)を用いると、以下が得られる。 ➢𝛼𝑖 は𝐮𝑖 方向の最小値までの距離と解釈できる。
27 7.3 Convergence: Derivation of (7.26) • (7.26) 𝐸 𝐰
= 𝐸 𝐰∗ + 1 2 𝑖 𝛼𝑖 𝐮𝑖 T 𝐇 𝑖 𝛼𝑖 𝐮𝑖 = 𝐸 𝐰∗ + 1 2 𝑖 𝛼𝑖 𝐮𝑖 T 𝑖 𝛼𝑖 𝜆𝑖 𝐮𝑖 = 𝐸 𝐰∗ + 1 2 𝑖 𝜆𝑖 𝛼𝑖 2 ∇𝐸 𝐰 = 𝑖 𝜆𝑖 𝛼𝑖 𝐮𝑖 𝐰 𝜏 − 𝐰 𝜏−1 = 𝑖 Δ𝛼𝑖 𝐮𝑖 𝐰 𝜏 − 𝐰 𝜏−1 = Δ𝐰 = −𝜂∇𝐸 𝐰 (7.16) 𝑖 Δ𝛼𝑖 𝐮𝑖 = −𝜂 𝑖 𝜆𝑖 𝛼𝑖 𝐮𝑖 𝛥𝛼𝑖 = −𝜂𝜆𝑖 𝛼𝑖 (7.26)
28 7.3 Convergence • 式(7.27)から、各ステップにおいて𝐮𝑖 方向の距離は(1 − 𝜂𝜆𝑖)倍されるため、合計Tステップ後 には、以下が得られる。 ➢|1
− 𝜂𝜆𝑖 | < 1であれば、極限T → ∞において𝛼𝑖 = 0となり、式(7.28)より𝐰 = 𝐰∗ となり、 重みベクトルは誤差の最小値に到達する。 • 𝜂を大きくすると収束速度を向上させることができるが、 |1 − 𝜂𝜆𝑖 | < 1 じゃないと𝛼𝑖 の値 が発散してしまう。 ➢ 𝜂の値を𝜂 < 2/𝜆max に制限することでこれを回避できる (𝜆max:固有値の最大値)。 𝛼 𝑖 (𝑇) = 1 − 2 𝜆𝑚𝑎𝑥 𝜆𝑖 𝑇 𝛼 𝑖 (0)
29 7.3 Convergence • しかし、収束速度は最小固有値によって支配される。 ➢最小固有値が楕円の長い軸に対応しており、楕円が細長くなれば収束が遅くなる。 • 𝜂 をできるだけ大きくしたとき( 𝜂
= 2/𝜆max)、 最小固有値 (楕円の最も長い軸) に沿った収 束は、次の式によって決まる。 𝛼 𝑖 (𝑇) = 1 − 2 𝜆𝑚𝑎𝑥 𝜆𝑚𝑖𝑛 𝑇 𝛼 𝑖 (0) • この式から、式(7.30) の項が収束のスピードを決めていることが分かる。 ➢ 固有値の値に差がありすぎると 𝜆𝑚𝑖𝑛 /𝜆𝑚𝑎𝑥 が小さくなり、収束が遅くなる。 図7.2 再掲, -1/2乗なので、この図では 𝜆1 の方が最小固有値に対応
30 7.3.1 Momentum • 大きく異なる固有値の問題に対処したい ➢Momentum が効果的 ✓重み空間の動きに慣性項(Δ𝐰 𝜏−2 )を加え、振動を滑らかにする。
✓𝜇: モーメンタムパラメータ, 0 ≤ 𝜇 ≤ 1 • 図7.4に示すような、誤差曲面の曲率が比較的小さい重み空間の領域を考える。勾配が変化 しないと仮定すると、式(7.31)を一連の重み更新に反復的に適用すると、以下が得られる。 ➢ 滑らかな斜面では実効学習率を𝜂から𝜂/(1 − 𝜇)に増加させる。 図7.4 Δ𝐰(𝜏−1) = −𝜂∇𝐸 𝐰 𝜏−1 + 𝜇 −𝜂∇𝐸 𝐰 𝜏−2 + 𝜇 −𝜂∇𝐸 𝐰 𝜏−3 … 仮定: ∇𝐸 𝐰 𝜏−1 = ∇𝐸 𝐰 𝜏−2 = ∇𝐸 𝐰 𝜏−3 = ⋯ = ∇𝐸
31 7.3.1 Momentum • 一方、勾配降下法が振動するような曲率の高い領域ではMomentum項からの連続する寄与は 相殺される傾向があり、実効学習率は𝜂に近くなる(図7.5) (?)。 ➢Momentum項は、振動を引き起こすことなく、最小値への収束を高速化する(図7.6) 。 •
∇𝐸 𝐰 𝜏−1 = −∇𝐸 𝐰 𝜏−2 = ∇𝐸 𝐰 𝜏−3 = ⋯ という極端な例を考えてみる ➢実行学習率が𝜂/(1 + 𝜇)になる=𝜂 より小さくなる(?)。 ➢実際にはステップ 𝜏 − 1-> 𝜏 で勾配が真逆になるよりは変化がマイルドなので実行学習率 は 𝜂 に近い所に落ち着く…ってコト? Δ𝐰 = −𝜂∇𝐸 + 𝜇 𝜂∇𝐸 + 𝜇 −𝜂∇𝐸 … = −𝜂∇𝐸 1 − 𝜇 + 𝜇2 − 𝜇3 + ⋯ = − 𝜂 1 + 𝜇 ∇𝐸 図7.5 図7.6
32 7.3.1 Momentum • Momentumを導入することで勾配降下法のパフォーマンスを向上させることがでるが、学習 率 𝜂 に加えて 𝜇 についても検討が必要になる。
➢(7.33)から、μ は 0 ≤ 𝜇 ≤ 1の範囲であるべきであることがわかる。実際に使用される典型 的な値は 𝜇 = 0.9
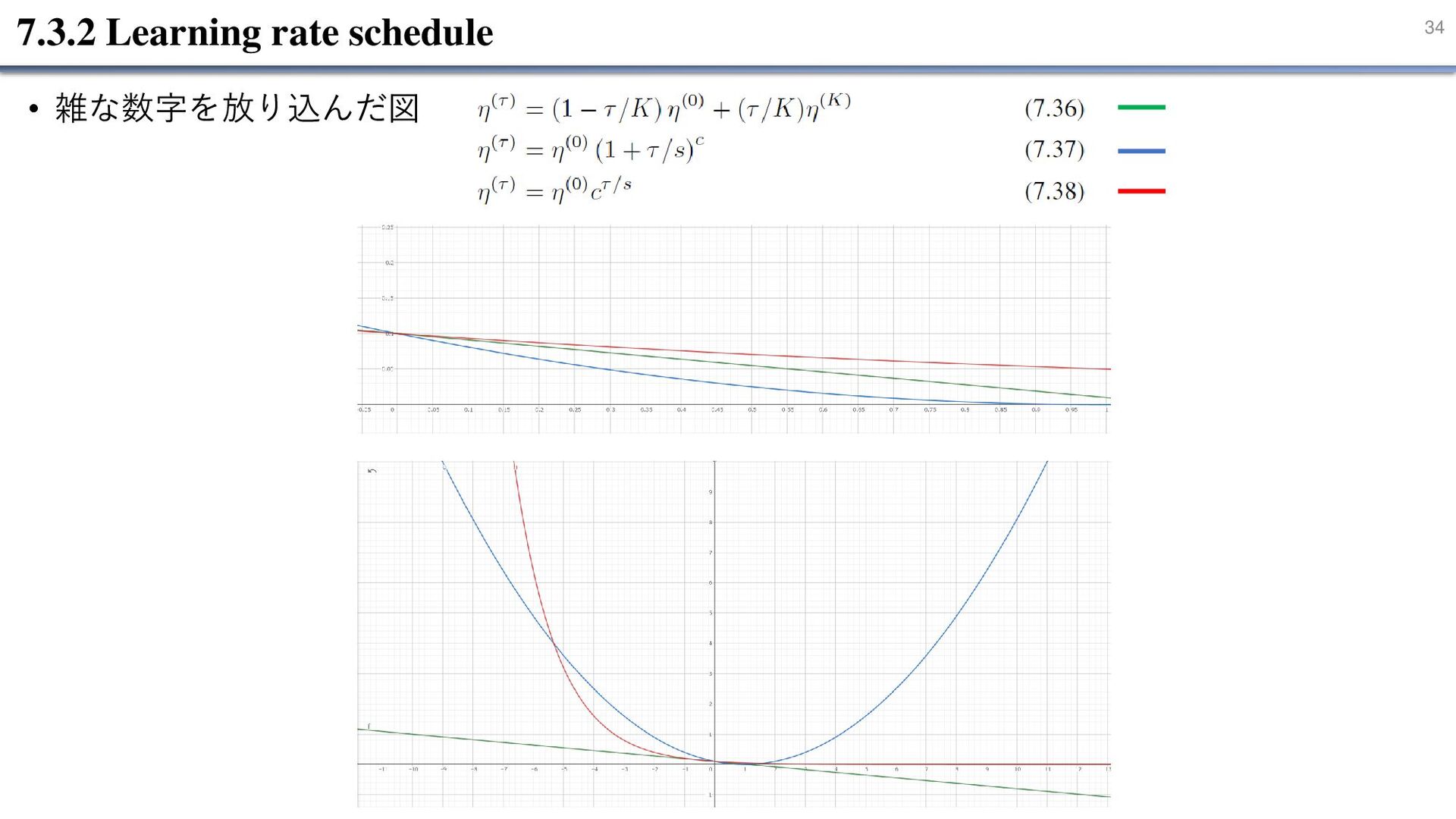
33 7.3.2 Learning rate schedule • 確率的勾配降下法 式 (7.18)では、𝜂 の値を指定する必要がある。
➢ 𝜂 が非常に小さい場合、学習が遅くなる。 ➢ 𝜂 を大きくしすぎると、学習が不安定になる可能性がある。 ➢学習の開始時に 𝜂 の値を大きくし、時間の経過とともに学習率を減らしていくことで、 効率よく学習が進む。 • 学習率のスケジューラとしては、線形、べき乗則、指数関数的減衰などが挙げられる。 ➢(7.36)では、𝜂 の値はKステップにわたって線形に減少し、その後は 𝜂 𝐾 で一定にする。 ➢ 𝜂 0 , 𝜂(𝐾), 𝐾, 𝑆, 𝑐 の値は経験的に探索する必要がある。 ✓実際には、学習中の誤差関数の変化を監視し、適切な速度で減少していることを確 認することが役立つ。
34 7.3.2 Learning rate schedule • 雑な数字を放り込んだ図
35 7.3.3 RMSProp and Adam • 最適な学習率は、誤差局面の局所的な曲率に依存し、さらにこの曲率はパラメータ空間の方 向によって異なる可能性があることがSection 7.3で確認できた。 ➢ネットワーク内のパラメータごとに異なる学習率を適用するアルゴリズムが有用
• AdaGrad (Adaptive Gradient) ➢パラメータに対して計算されたすべての導関数の2乗の累積和を使用して、時間の経過と ともに各学習率を低減する(Duchi, Hazan, and Singer, 2011)。 ➢高い曲率に関連付けられたパラメータが最も急速に減少 ➢ 𝜂: 学習率, 𝛿: 𝑟𝑖 が小さい時に0除算を避けるための項 ➢ 𝑟𝑖 = 0 で初期化 ➢ 𝐸(𝐰)は特定のミニバッチの誤差関数であり、更新式(7.40)は標準的な確率的勾配降下法 であるが、各パラメータに固有の学習率が適用される。
36 7.3.3 RMSProp and Adam • AdaGradの問題点 ➢学習の最初から勾配の2乗を累積するため、重みの更新が小さくなっていく。 ✓ 𝑟𝑖
は単調に増加するので、後半で学習がどんどん遅くなる。 • RMSProp (Root Mean Square Propagation) ➢ AdaGradの勾配の2乗和を exponentially weighted average に置き換えた (Hinton, 2012)。 ➢ 0 < 𝛽 < 1, 典型的な値は 𝛽 = 0.9 ➢ (7.41)の 𝑟𝑖 を再帰的に計算すると 𝛽 が exponentially にかかる。 ➢ 𝑟𝑖 は単調に増加するのではなく、指数移動平均になる。 AdaGrad再掲
37 7.3.3 RMSProp and Adam • Adam (Adaptive moments) ➢RMSProp
とMomentum の組み合わせ (Kingma and Ba, 2014) ➢各パラメータの Momentum を個別に保存し、勾配と勾配の2乗の両方について exponentially weighted average で構成される更新式を利用 ➢1/(1 − 𝛽1 𝜏)と1/(1 − 𝛽2 𝜏)は、𝑠 𝑖 0 と𝑟 𝑖 0 をゼロに初期化した際に生じるバイアス(低く見積 もられてしまう)を修正するために導入された。 ✓𝛽(𝜏) ではなく𝛽𝜏 (𝛽の𝜏乗) ➢𝛽𝑖 < 1であるため、𝜏 が大きくなるとバイアスはゼロに近づく。 ➢実際には、このバイアス補正が省略されることもある。 ➢パラメータの一般的な値は、𝛽1 = 0.9, 𝛽2 = 0.99
38 7.1 Error Surfaces 7.1.1 Local quadratic approximation 7.2 Gradient
Descent Optimization 7.2.1 Use of gradient information 7.2.2 Batch gradient descent 7.2.3 Stochastic gradient descent 7.2.4 Mini-batches 7.2.5 Parameter initialization 7.3 Convergence 7.3.1 Momentum 7.3.2 Learning rate schedule 7.3.3 RMSProp and Adam 7.4 Normalization 7.4.1 Data normalization 7.4.2 Batch normalization 7.4.3 Layer normalization Contents
39 7.4 Normalization • 原則として、ニューラルネットワークのパラメータは、どのような値でもよい ➢実際には、効果的に学習を進めるにはパラメータが発散しないように正規化することが が非常に重要になる場合がある。 • 入力データ全体、ミニバッチ全体、または層全体のいずれを正規化するかによって、3種類 の正規化がある。
40 7.4.1 Data normalization • 異なる入力変数が広範な数値を持つデータセットで学習する場合 • ヘルスケア関連のデータで、患者の身長がメートル単位で測定される場合があったり、血小 板数はマイクロリットルあたりの血小板数で測定される場合がある(300,000 /
𝜇𝐿とか) 。 ➢2つの重みを持つ単層回帰ネットワークを考えてみると、一方の重みの値を変更した場合、 誤差関数がもう一方の重みの同様の変更よりもはるかに大きく変化する。 ➢これは図7.3 のような、異なる軸に沿って非常に異なる曲率を持つ誤差面に相当する。 図7.3 𝑤1 身長 (m) 血小板 (個/ 𝜇𝐿) 𝑤2 𝑤2 が誤差関数に与える影響が相対的に大きい
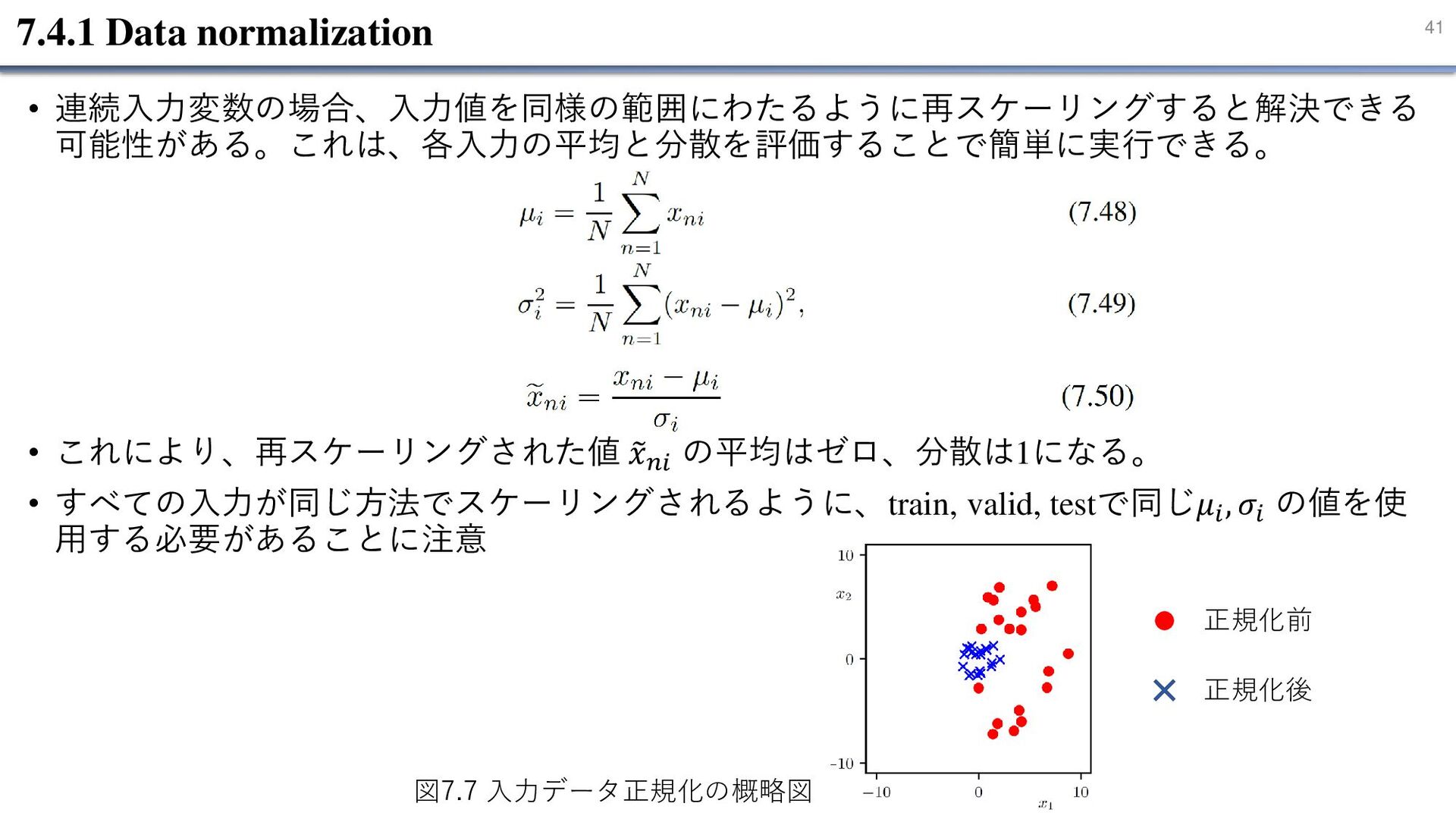
41 7.4.1 Data normalization • 連続入力変数の場合、入力値を同様の範囲にわたるように再スケーリングすると解決できる 可能性がある。これは、各入力の平均と分散を評価することで簡単に実行できる。 • これにより、再スケーリングされた値
𝑥𝑛𝑖 の平均はゼロ、分散は1になる。 • すべての入力が同じ方法でスケーリングされるように、train, valid, testで同じ𝜇𝑖 , 𝜎𝑖 の値を使 用する必要があることに注意 図7.7 入力データ正規化の概略図 正規化前 正規化後
42 7.4.2 Batch normalization • 入力データではなく、ネットワークの各隠れ層にも正規化が適用できる。 • 特定の隠れ層の活性化値の範囲に大きなばらつきがある場合、それらの値を平均0、分散1に 正規化すると、次の層の学習が容易になる。 ➢ただし、入力値の正規化では学習の開始前に一度だけ実行すればよかったのに対し、隠
れユニットの正規化は重みの値が更新されるたびに繰り返す必要がある。これを Batch normalization と呼ぶ (Ioffe and Szegedy, 2015)。 ➢Batch normalization は、非常に深いネットワークを学習する際に発生する勾配消失と勾配 爆発に対して効果的である。 ➢最初の層のパラメータに関する誤差関数の勾配は、次のように表される。 ✓𝑧 𝑗 𝑘 : 層𝑘, ノード𝑗の活性化 ➢勾配は、偏微分のほとんどが1未満であれば0に近づき、1を超えると無限大に近づく。 ✓ネットワークの深さが増すにつれて勾配消失 or 勾配爆発が起こりやすくなる。 ✓Batch normalization はこの問題をおおよそ解決できる。
43 7.4.2 Batch normalization • 多層ネットワーク内の特定の層について考える。 ➢その層の各隠れユニットは、𝑧𝑖 = ℎ 𝑎𝑖
の非線形関数を計算するため、事前活性化値 𝑎𝑖 を正規化するか、活性化値 𝑧𝑖 を正規化するかを選択できる。 ✓実際には、どちらのアプローチも使用できる。ここでは、事前活性化を正規化する。 ➢重みの値はサンプルのミニバッチごとに更新されるため、各ミニバッチに正規化を適用 する。具体的には、サイズ 𝐾 のミニバッチの場合、以下を定義 ✓𝑛: データポイント, 𝐾:バッチサイズ, 𝛿: ゼロ除算を避けるための項
44 7.4.2 Batch normalization • Batch normalization で事前活性化 𝑎𝑖 の平均が
0, 分散が 1 になれば、その層のパラメータの 自由度が減少し、表現力が低下する。 ➢以下の (7.55) でバッチの事前活性化 𝑎𝑖 を学習可能なパラメータ 𝛽𝑖 (平均) と 𝛾𝑖 (標準偏差) に再スケールする方法もある。 ➢Batch normalization を適用する前は層内のすべてのパラメータによる複雑な関数で平均と 分散が決まっていたが、(7.55) では独立したパラメータ𝛽𝑖 と𝛾𝑖 によって直接決定される。 ➢𝛽𝑖 , 𝛾𝑖 は追加レイヤーとして各標準隠れ層の後に取り付けることができる。 ✓pytorchではデフォルトで 𝛽𝑖 , 𝛾𝑖 を学習するようになっていた ✓オプションで𝛽𝑖 , 𝛾𝑖 を使わない方法に切り替えられる 図7.8 (a) Batch normalization
45 7.4.2 Batch normalization • 学習後に新しいデータで予測を行いたい場合、トレーニングミニバッチは使用できなくなり、 1つのデータ例だけから平均と分散を判断することはできない • これを解決するために、学習後にトレーニングセット全体で各層の 𝜇𝑖
と 𝜎𝑖 を評価する方法 が考えられる。 ➢ただし、 𝜇𝑖 と 𝜎𝑖 を評価するためだけにデータセット全体を処理する必要があるため、 通常はコストが高すぎて非現実的。 ➢代わりに、トレーニング中に層ごとの 𝜇𝑖 と 𝜎𝑖 の移動平均を計算して保存しておき、推 論時に使う。 ✓0 ≤ 𝛼 ≤ 1 • Batch normalizationは、なぜうまく機能するのかよく分かっていない。 ➢最初は内部共変量シフトを抑制するために開発されたが、最近では共変量シフトは重要 な要因ではなく、誤差関数がより滑らかになるのが重要と主張している論文もある (Santurkar et al, 2018)。
46 7.4.3 Layer normalization • Batch normalizationではバッチサイズが小さすぎると、平均と分散の推定値のノイズが大きく なってしまう。 • Layer
normalization (Ba, Kiros, Hinton, 2016) ➢ミニバッチ内のサンプル間で各隠れ層を正規化する代わりに、各データポイントに対し て隠れユニットで個別に正規化する方法 (図7.8 (b)) ➢もともとは、RNNのような、各データポイントに対して複数のタイムステップで異なる 出力を持つためにBatch normalizationが適用できないアーキテクチャ向けに開発されたが、 現在では広く利用されている。 ➢𝑀: 隠れユニット ➢訓練と推論で同じ正規化手法を採用するため、 移動平均を保存する必要はない 図7.8 (b) Layer normalization
47 まとめ • 7.1 Error Surfaces ➢誤差関数の幾何的な解釈 ➢∇𝐸 = 0,
𝐯T𝐇𝐯 > 0(正定値) であれば全ての固有値𝜆𝑖 が正であり、極小である • 7.2 Gradient Descent Optimization ➢勾配降下法 ➢確率的勾配降下法 ➢層の出力の分散が一定になるようにHe initializationを導入 • 7.3 Convergence ➢固有値の差が大きいと学習が難しい -> Momentumを導入 ➢パラメータごとに学習率を変化させる方がいい -> AdaGrad, RMSprop ➢Momentum と RMSprop の組み合わせ -> Adam • 7.4 Normalization ➢入力データの正規化 ➢Batch normalization: ミニバッチのデータポイントに対して正規化 ➢Layer normalization: 隠れユニットに対して正規化
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![19 7.2.5 Parameter initialization: He initialization • 重みの初期化には、 [−𝜖, 𝜖]](https://files.speakerdeck.com/presentations/24c36bf0652b40459beb90fc1cf6861f/slide_18.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}