𝚺𝑘 = ς 𝑘′=1 𝐾 𝜋𝑘′ 𝒩 𝐱𝑛 𝝁𝑘′ , 𝚺𝑘′ 𝑧 𝑛𝑘′ σ𝐳𝒏 [𝜋𝑘 𝒩 𝐱𝑛 𝝁𝑘 , 𝚺𝑘 ]𝑧𝑛𝑘 … … 𝐳𝑛 = 𝑧𝑛1 , 𝑧𝑛2 , … 𝑧𝑛𝑘 , … 𝑧𝑛𝐾 𝑝 𝑧𝑛𝑘 = ෑ 𝑘=1 𝐾 𝜋 𝑘 𝑧𝑛𝑘 Σ𝐳𝑛 は、考え得る 𝐳𝒏 すべてについての 和を表している。 𝑧𝑛1 = 1 1,0, … 0, … 0 𝑧𝑛2 = 1 0,1, … 0, … 0 𝑧𝑛𝑘 = 1 0,0, … 1, … 0 𝑧𝑛𝐾 = 1 (0,0, … 0, … 1) K (9.40) 𝔼𝐳𝑛|𝐱𝑛,𝝁𝑘,𝚺𝑘 𝑧𝑛𝑘 = 𝐳𝑛 𝑧𝑛𝑘 𝑝(𝐳𝑛 𝐱𝑛 , 𝝁𝑘 , 𝚺𝑘 = σ𝐳𝑛 𝑧𝑛𝑘 ς 𝑘′=1 𝐾 𝜋𝑘′ 𝒩 𝐱𝑛 𝝁𝑘′ , 𝚺𝑘′ 𝑧 𝑛𝑘′ σ𝐳𝒏 ς 𝑗=1 𝐾 [𝜋𝑗 𝒩 𝐱𝑛 𝝁𝑗 , 𝚺𝑗 ]𝑧𝑛𝑗 = 0 × 𝜋1 𝒩 𝐱𝑛 𝝁1 , 𝚺1 + ⋯ + 1 × 𝜋𝑘 𝒩 𝐱𝑛 𝝁𝑘 , 𝚺𝑘 + ⋯ 0 × 𝜋𝐾 𝒩 𝐱𝑛 𝝁𝐾 , 𝚺𝐾 𝜋1 𝒩 𝐱𝑛 𝝁1 , 𝚺1 + ⋯ + 𝜋𝐾 𝒩 𝐱𝑛 𝝁𝐾 , 𝚺𝐾 ≡ 𝛾 𝑧𝑛𝑘 34/56
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
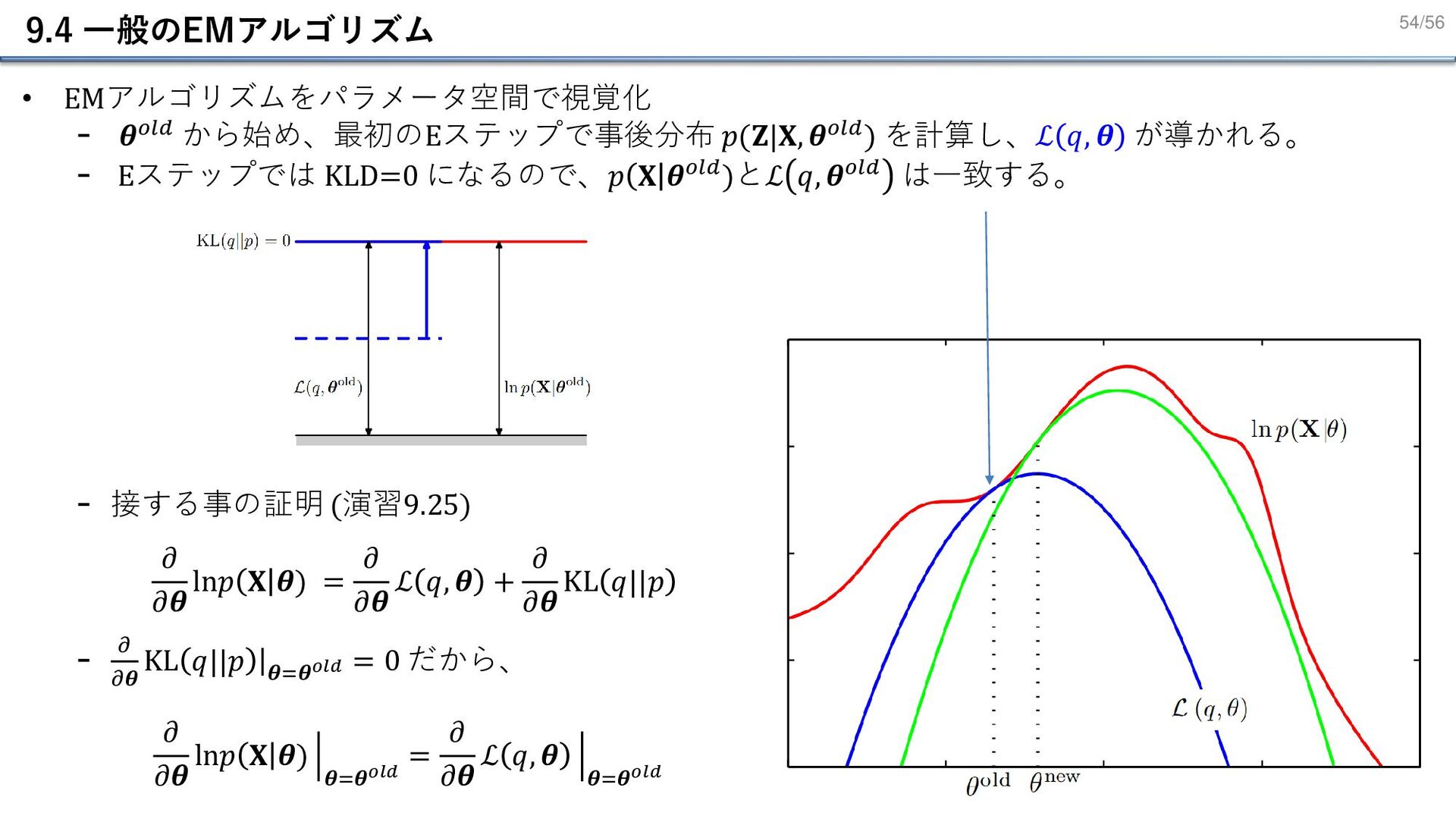{kind=link}
{kind=link}
{kind=link}