Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
PRML Chapter 5 (5.0-5.4)
Search
shogo-d-nakamura
April 01, 2023
Science
540
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
PRML Chapter 5 (5.0-5.4)
PRML, Pattern Recognition and Machine Learning
chapter 5
shogo-d-nakamura
April 01, 2023
More Decks by shogo-d-nakamura
See All by shogo-d-nakamura
Deep Learning Chapter 7
snkmr
0
100
PRML Chapter 1 (1.3-1.6)
snkmr
1
400
PRML Chapter 9
snkmr
1
360
PRML Chapter 8 (8.0-8.3)
snkmr
1
380
PRML Chapter 11 (11.0-11.2)
snkmr
1
460
Other Decks in Science
See All in Science
Snowflake HCLS Meet Upヘルスケアユーザー会紹介
ktatsuya
0
100
機械学習 - pandas入門
trycycle
PRO
0
660
生成AIと司法書士の未来.pdf
tagtag
PRO
0
140
見上公一.pdf
genomethica
0
170
データベース04: SQL (1/3) 単純質問 & 集約演算
trycycle
PRO
0
1.5k
明治薬科大学講義_ビッグデータ解析を支えるデータベース技術とクラウドコンピューティング
ktatsuya
1
130
機械学習 - SVM
trycycle
PRO
2
1.2k
Understanding CVP Waveforms: Interpretation and Clinical Implications in Anesthesiology
taka88
0
660
20251212_LT忘年会_データサイエンス枠_新川.pdf
shinpsan
0
300
不動産業界における業界特化のデータ整備とAI活用 ─Vertical DataとVertical AI─
estie
1
800
Testing the Longevity Bottleneck Hypothesis
chinson03
0
370
Tensor Factorization Meets Deformed Information Geometry: Convex Relaxation under Deformed Algebra
gkazunii
0
110
Featured
See All Featured
Speed Design
sergeychernyshev
33
1.9k
Connecting the Dots Between Site Speed, User Experience & Your Business [WebExpo 2025]
tammyeverts
11
970
Site-Speed That Sticks
csswizardry
13
1.3k
Save Time (by Creating Custom Rails Generators)
garrettdimon
PRO
32
3.8k
Cheating the UX When There Is Nothing More to Optimize - PixelPioneers
stephaniewalter
287
14k
The World Runs on Bad Software
bkeepers
PRO
72
12k
Building a Scalable Design System with Sketch
lauravandoore
463
34k
10 Git Anti Patterns You Should be Aware of
lemiorhan
PRO
659
62k
What does AI have to do with Human Rights?
axbom
PRO
1
2.2k
How GitHub (no longer) Works
holman
316
150k
Hiding What from Whom? A Critical Review of the History of Programming languages for Music
tomoyanonymous
3
950
Leading Effective Engineering Teams in the AI Era
addyosmani
9
2.1k
Transcript
2022/06/24 D1 中村 PRML Chapter 5
2 5.1 フィードフォワードネットワーク関数 5.2 ネットワーク訓練 5.3 誤差逆伝播 5.4 ヘッセ行列 目次
5.5 正則化 5.6 混合密度ネットワーク 5.6 ベイズニューラルネットワーク
5. ニューラルネットワーク 3 3章・4章:固定された基底関数の線形和で表されるモデル 訓練データ点が増えると基底関数の数も増える →応用可能性は低い(次元の呪い §1.4 ) 大規模な問題に対してモデルを適応させる方法 ・SVM,
RVM → 7章 ・ニューラルネットワーク → 5章 基底関数を固定し、パラメータをデータに適応させる。
4 5.1 フィードフォワードネットワーク関数 5.2 ネットワーク訓練 目次 5.1.1 重み空間対称性 5.2.1 パラメータ最適化
5.2.2 局所二次近似 5.2.3 勾配情報の利用 5.2.4 勾配降下最適化
5.1 フィードフォワード関数 5 3章・4章で議論した線形モデル (5.1) ここで関数 f (・) は、 クラス分類:非線形関数(シグモイド、Softmax)
回帰:恒等写像 NNでは基底関数 ϕj (x) を固定し、訓練中にパラメータ wj を調整する。
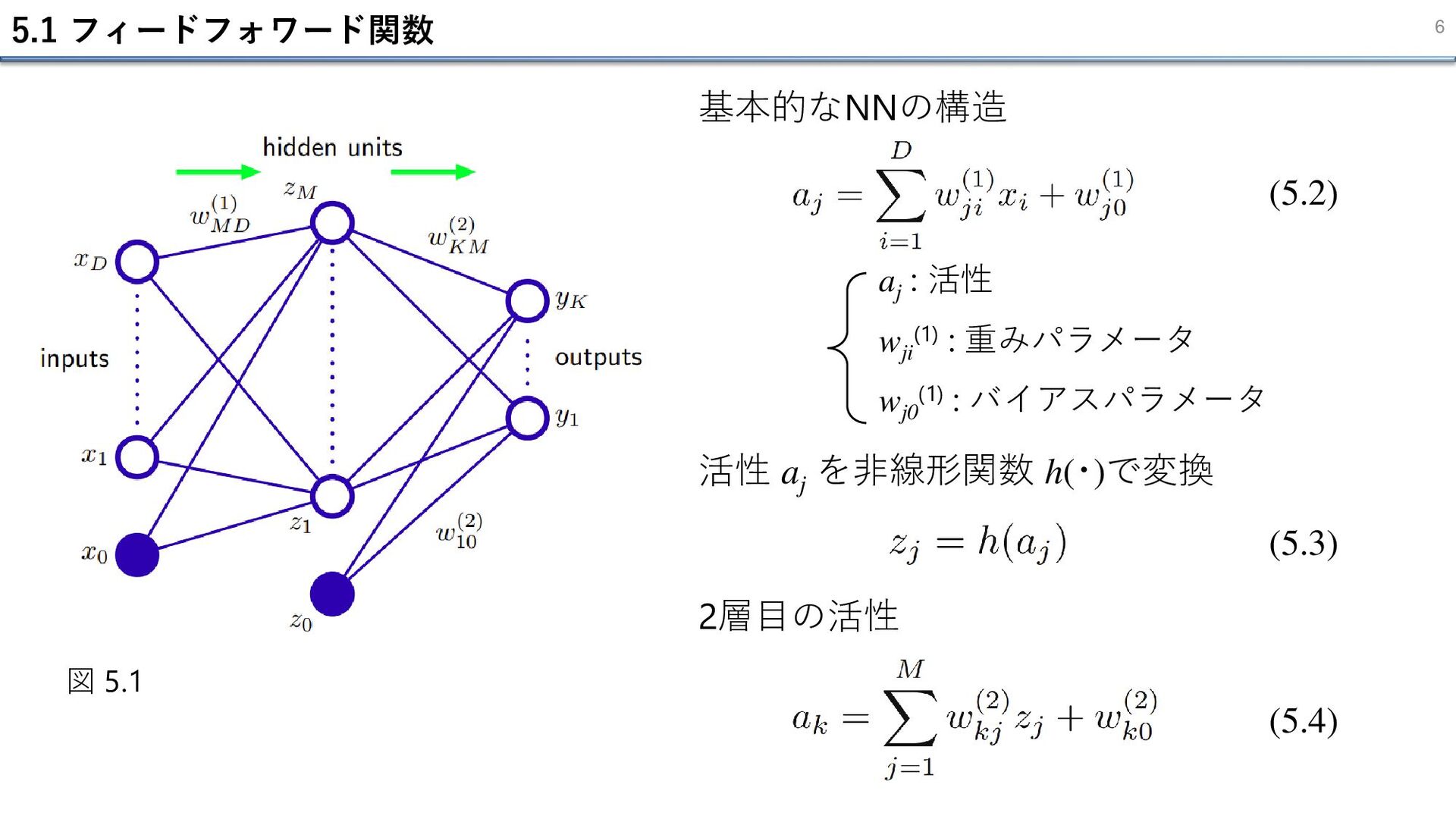
5.1 フィードフォワード関数 6 (5.2) 図 5.1 aj : 活性 wji
(1) : 重みパラメータ wj0 (1) : バイアスパラメータ (5.3) (5.4) 活性 aj を非線形関数 h(・)で変換 基本的なNNの構造 2層目の活性
5.1 フィードフォワード関数 7 (5.5) 1層目と2層目をまとめると、 2クラス分類ではロジスティックシグモイド関数を使う。 where (5.6) (5.7) ・
NNは、単に可変ベクトル w に制御される入力 x から出力 y への非線形関数 ・この関数は、図5.1 のようなネットワーク上の順伝播と解釈可能
5.1 フィードフォワード関数 8 NNは4.1.7 節で登場したパーセプトロンモデルと似ているが、 活性化関数に連続なシグモイド関数を利用している点で異なる。 (パーセプトロンは活性化関数が非連続な非線形関数) → NNはマルチパーセプトロンと呼ばれることもあるが、この点で決定的に異なる。 ・
・ NNの構造は簡単に一般化される。 1. 隠れ層の追加 2. 層を飛び越えた結合の導入
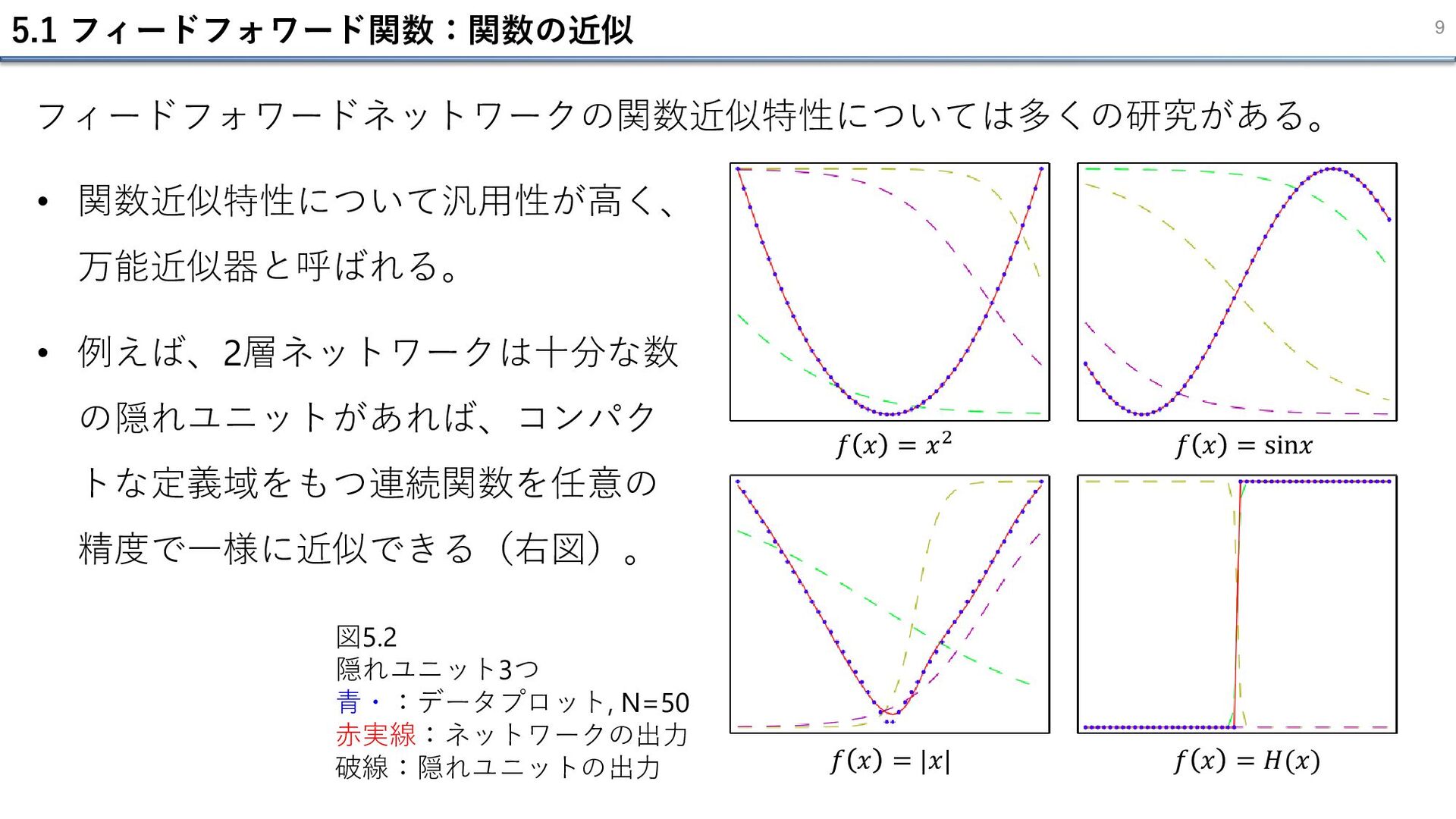
5.1 フィードフォワード関数:関数の近似 9 フィードフォワードネットワークの関数近似特性については多くの研究がある。 𝑓 𝑥 = 𝑥2 𝑓 𝑥
= sin𝑥 𝑓 𝑥 = |𝑥| 𝑓 𝑥 = 𝐻(𝑥) • 関数近似特性について汎用性が高く、 万能近似器と呼ばれる。 • 例えば、2層ネットワークは十分な数 の隠れユニットがあれば、コンパク トな定義域をもつ連続関数を任意の 精度で一様に近似できる(右図)。 図5.2 隠れユニット3つ 青・:データプロット, N=50 赤実線:ネットワークの出力 破線:隠れユニットの出力
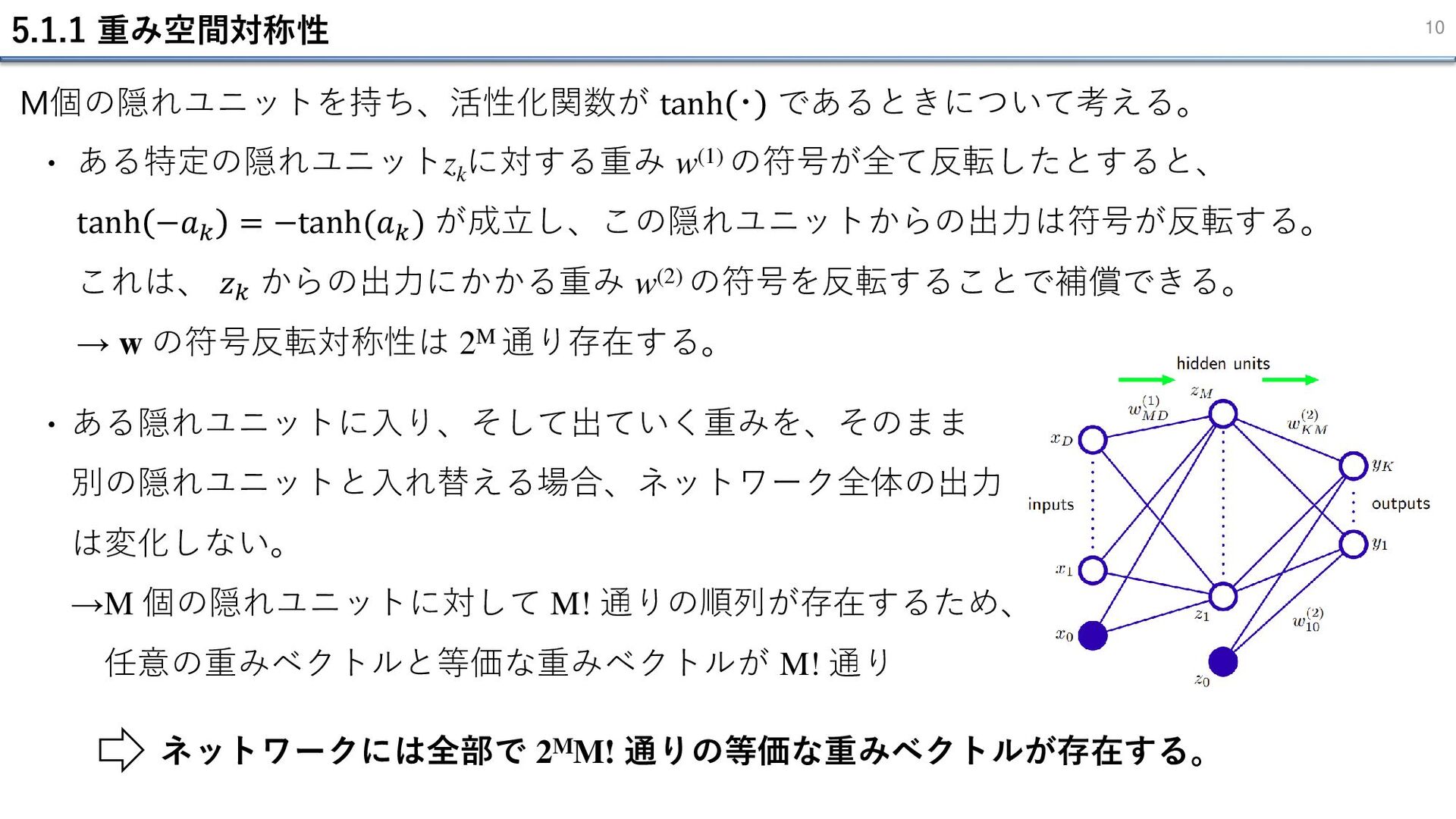
5.1.1 重み空間対称性 10 M個の隠れユニットを持ち、活性化関数が tanh ・ であるときについて考える。 ある特定の隠れユニットzk に対する重み w(1)
の符号が全て反転したとすると、 tanh −𝑎𝑘 = −tanh(𝑎𝑘 ) が成立し、この隠れユニットからの出力は符号が反転する。 これは、 𝑧𝑘 からの出力にかかる重み w(2) の符号を反転することで補償できる。 → w の符号反転対称性は 2M 通り存在する。 ・ ある隠れユニットに入り、そして出ていく重みを、そのまま 別の隠れユニットと入れ替える場合、ネットワーク全体の出力 は変化しない。 →M 個の隠れユニットに対して M! 通りの順列が存在するため、 任意の重みベクトルと等価な重みベクトルが M! 通り ・ ネットワークには全部で 2MM! 通りの等価な重みベクトルが存在する。
5.2 ネットワーク訓練 11 ネットワークパラメータ w の決定問題への単純なアプローチは、二乗和誤差の最小化 (5.11) 1.5.4 節で説明されているように、ネットワークの出力を確率的に解釈すると、 出力ユニットの非線形活性化関数と誤差関数の選択に明確な理由付けができる。
5.2 ネットワーク訓練:回帰 12 t は x に依存する平均を持つ、以下のガウス分布に従うとする。 (5.12) 尤度関数と負の対数尤度については以下のようになる (2.3
節)。 まずは、実数値をとる 1 つの目標変数 t に関する回帰問題について考える。 (5.13) NNの文献では尤度の最大化よりも誤差関数 E(w) を最小化する方が多い。 (5.14)
5.2 ネットワーク訓練:回帰 13 (5.14) E (w) を最小化する w は最尤推定解に相当するため、wML で表す。
実際には E (w) は非凸であるため、得られるのは E (w) の極小点=尤度関数の極大点である。 wML が求まれば、βML は負の対数尤度 (5.13) を最小化することで求められる。 (5.13) ※ (5.14) には wML が含まれているため、 βML は wML を求めるための反復最適化が 終了してからでないと評価することができない。
5.2 ネットワーク訓練:回帰, 多次元の出力 14 目標変数が複数ある場合、条件付き確率が独立かつノイズ精度 β が共通と仮定すれば、 K 個の目標値の条件付き分布とノイズ精度は、 (5.16)
(5.17) (5.14) 回帰問題では活性化関数を恒等関数とするため、yk = ak であり、 (5.18) where . で表すことができる(4.3.6 節)。
5.2 ネットワーク訓練:2クラス分類 15 4.3.6 節に従い、2クラス分類では活性化関数にロジスティックシグモイド関数を使う。 y(x,w) = p(C1 |x) と解釈でき、
p(C2 |x) = 1 – p(C1 |x) となる。 t = 1 がクラスC1 、t = 0 がクラスC2 を表すとき、目標変数の条件付き分布は (5.20) 訓練集合が独立であれば、誤差関数は交差エントロピー誤差関数になる。 (5.21) ・クラス分類問題では、二乗和誤差よりも交差エントロピー誤差を使う方が 訓練が速くなると同時に汎化性能が高まるらしい(Simard et al. 2003)。
5.2 ネットワーク訓練:K個の異なる2クラス分類 16 K 個の異なる2クラス分類問題を解く場合、各々の出力に tk ∈{0, 1} ( k
= 1, 2, ….. K ) を割り当てることで尤度関数を表す。 (5.22) (5.23) 誤差関数は、負の対数尤度をとることで、
5.2 ネットワーク訓練:多クラス分類 17 多クラス分類 = K 個の排他的なクラスの 1 つに割り当てる問題であり、 目標変数は
1 of K 符号化法を用いて、 tk ∈{0, 1} ( k = 1, 2, ….. K ) で表すことができる。 (1 of K 符号化法: ( 0, 0, 0, 0, 1, 0 ) みたいなやつ。) ネットワークの出力は y(x, w) = p(tk = 1|x) と解釈すると、誤差関数は、 (5.24) 出力ユニットはソフトマックス関数で与えられ (4.3.6 節)、 (5.25)
18 5.1 フィードフォワードネットワーク関数 5.2 ネットワーク訓練 目次 5.1.1 重み空間対称性 5.2.1 パラメータ最適化
5.2.2 局所二次近似 5.2.3 勾配情報の利用 5.2.4 勾配降下最適化
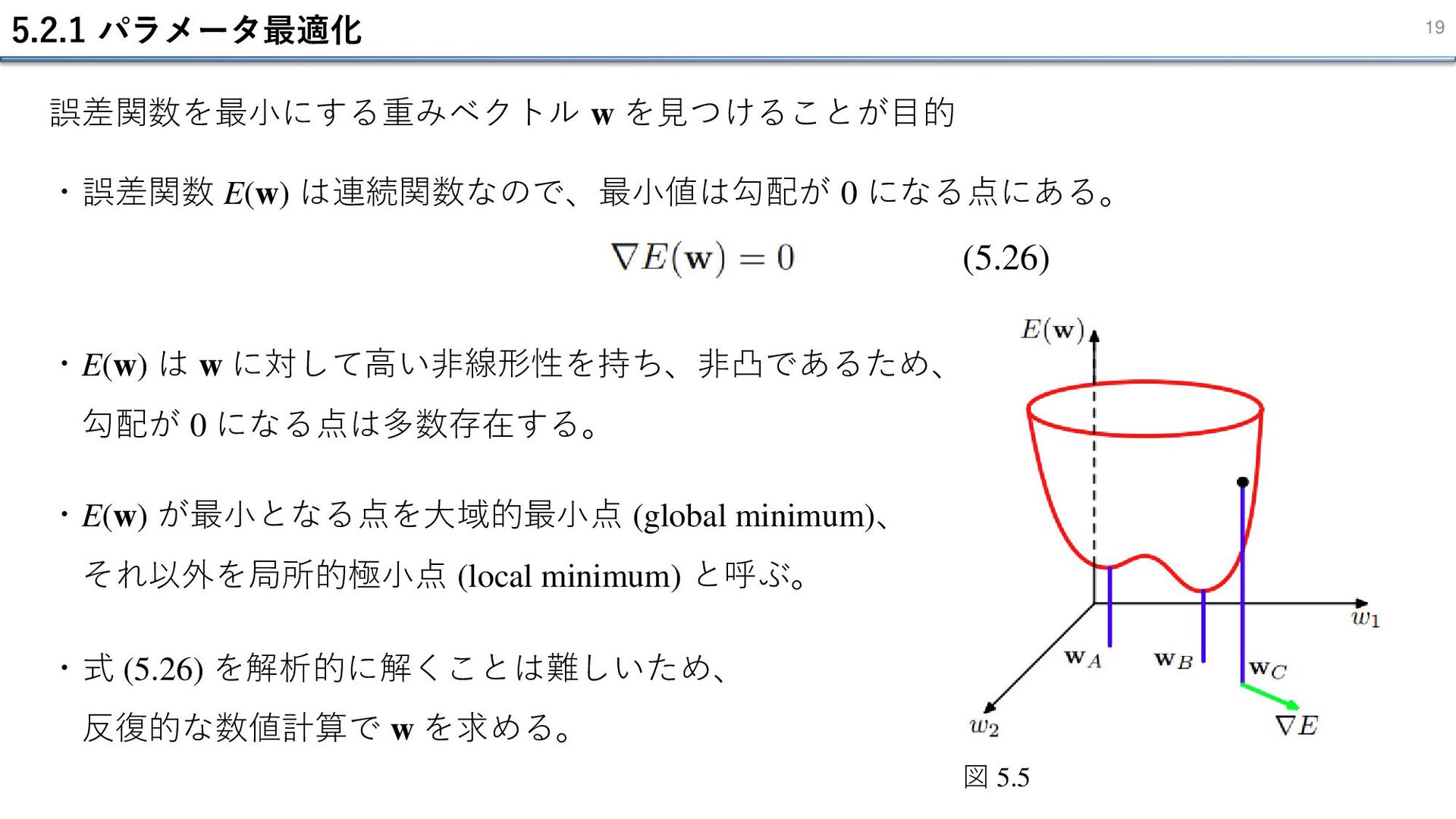
5.2.1 パラメータ最適化 19 (5.26) 誤差関数を最小にする重みベクトル w を見つけることが目的 ・誤差関数 E(w) は連続関数なので、最小値は勾配が
0 になる点にある。 ・E(w) は w に対して高い非線形性を持ち、非凸であるため、 勾配が 0 になる点は多数存在する。 ・E(w) が最小となる点を大域的最小点 (global minimum)、 それ以外を局所的極小点 (local minimum) と呼ぶ。 ・式 (5.26) を解析的に解くことは難しいため、 反復的な数値計算で w を求める。 図 5.5
5.2.2 局所二次近似 20 (5.28) 重み空間内のある点 ෝ 𝐰 周りでの E(w) のテイラー展開
(二次まで) ここで、bとHはそれぞれ ෝ 𝐰 周りでの勾配とヘッセ行列 (5.29, 5.30) 停留点 w⋆ 周りについて考えると、∇𝐸 w⋆ = 0 であるから、 (5.32) ここで、Hは w⋆ で評価されている。 w の反復計算をする際に、更新した w が極小点にあるかどうかを判定する手法が必要
5.2.2 局所二次近似: ヘッセ行列の対角化 21 (5.33) H の評価を幾何学的に解釈するために、Hの固有方程式について考える。 対称行列 (𝐇⊤ =
𝐇) であれば、完全直行基底ベクトル ui を選ぶことができる。 (付録C, p317-318.) (5.34) (𝐰 − w⋆) を固有ベクトルの線形和で表すと、 (5.35) 以上を (5.32) に代入すると、(5.36) が得られる。 (5.32) (5.36) (∵ 𝐮 𝑖 ⊤𝐇𝐮 𝑖 = 𝜆 𝑖 )
5.2.2 局所二次近似: ヘッセ行列の対角化 22 H は、任意のベクトル v ≠ 0 に対して𝐯⊤𝐇𝐯
> 𝟎 を満たすときに正定値となる。 また、 w⋆ で評価された H が正定値ならば w⋆ は極小点である (演習5.12) 。 (5.38) (5.39) (∵ 𝐮 𝑖 ⊤𝐇𝐮 𝑖 = 𝜆 𝑖 ) 𝐯⊤𝐇𝐯 > 𝟎 を満たすためには、全ての固有値 λ が正であればよい。 𝜆 について幾何的に解釈するために、E(w) = C となるような等高線について考える。 (5.36)
5.2.2 局所二次近似: ヘッセ行列の対角化 23 𝐸 𝐰⋆ は定数、C0 も定数なので、 𝐸 𝐰
= 𝐸 𝐰⋆ + 1 2 𝑖 𝜆𝑖 𝛼𝑖 2 = 𝐶0 𝑖 𝜆𝑖 𝛼𝑖 2 = 𝐶1 𝜆1 𝛼1 2 + 𝜆2 𝛼2 2 = 𝐶1 α は (𝐰 − w⋆) を固有ベクトルの線形和 で表すために (5.35) で導入した。 (5.35) 基底ベクトル ui とその座標を表す変数 α i =1, 2 について考えると、 図 5.6
5.2.2 参考 24 𝐯⊤𝐇𝐯 > 𝟎 すなわち全ての固有値 λ が正であれば、w⋆ は極小点である。
固有値 λ が全て正じゃないときは、 𝜆1 𝛼1 2 − 𝜆2 𝛼2 2 = 𝐶1 この双曲線は、停留点であるが極小点ではない点=鞍点の等高線を表している。 wikipedia (https://ja.wikipedia.org/wiki/%E9%9E%8D%E7%82%B9) accessed 2022/06/20.
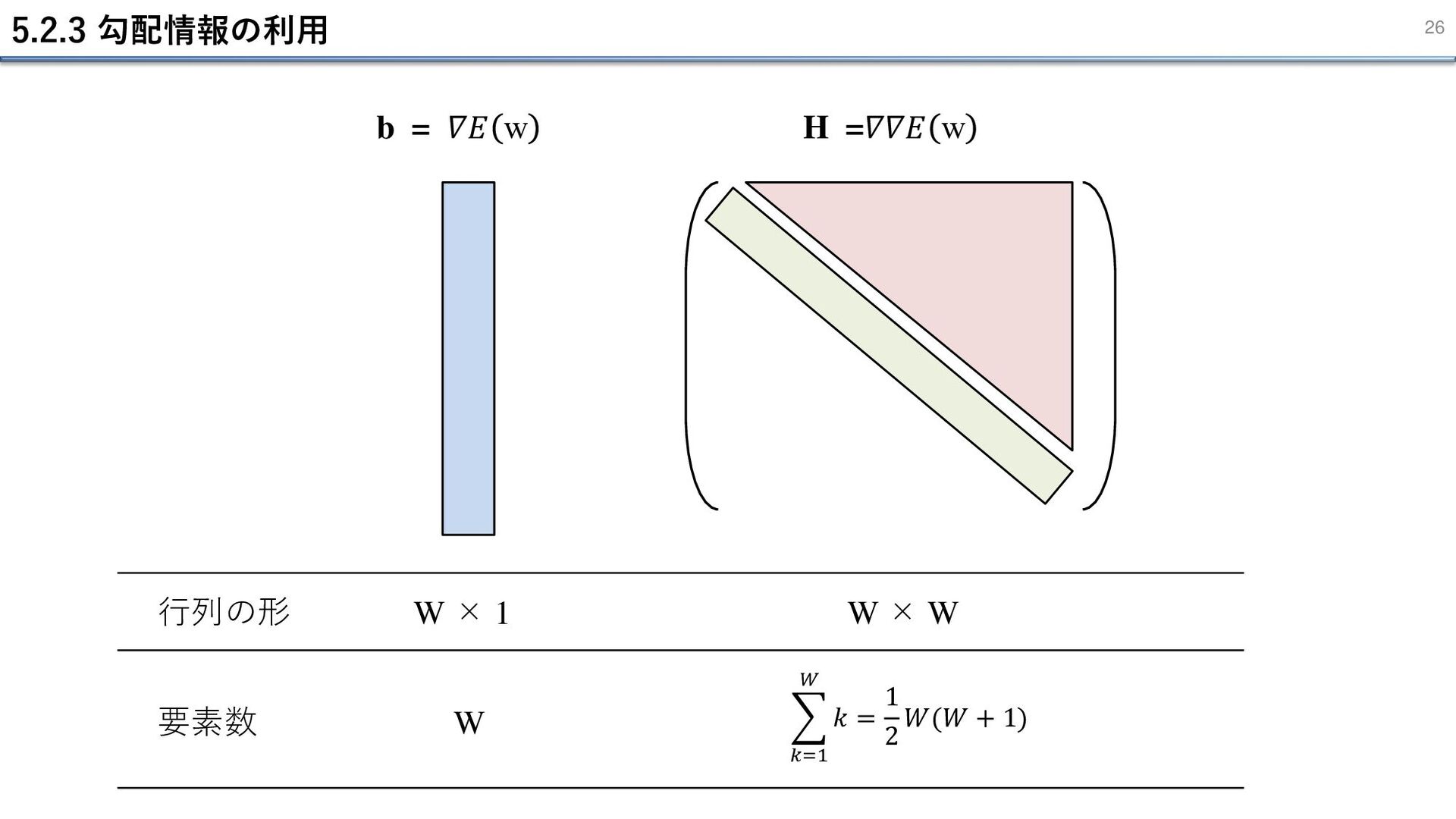
5.2.3 勾配情報の利用 25 勾配情報を利用すれば、 ∇𝐸 w を評価するごとに W 個の情報が得られる。 この場合、逆誤差伝播を利用することでトータルの計算量は
O(W2) で済む (§5.2.3 )。 (5.28) で与えられる誤差関数の近似式で、誤差局面は b と H によって特定される。 (5.28) ・ここで b の要素は W 個、H の要素は 1 2 𝑊(𝑊 + 1) 個存在する→計算量は O(W2)。 ・もし勾配情報を利用しなければ、 w を更新 → 順伝播 → 極値判定 ステップを繰り返す。 この工程は W に対して一次で計算量が増えていくため、計算量 O(W) を要する。 ・以上から、合計の計算量は O(W2) × O(W) = O(W3) ネットワーク全体の重みパラメータの数 W と計算量の関係 (ユニット数は W に対して小さいので、h(・)の計算量は考慮しない。)
5.2.3 勾配情報の利用 26 b = 𝛻𝐸 w H =𝛻𝛻𝐸 w
W × 1 W × W 𝑘=1 𝑊 𝑘 = 1 2 𝑊(𝑊 + 1) 行列の形 要素数 W
5.2.4 勾配降下最適化 27 (5.41) 勾配情報を利用した最も単純な更新式は、学習率パラメータ η を用いて、 ・勾配の評価と重みパラメータ w の更新を繰り返すことで極小点を探索
・全てのデータ集合を一度に扱う手法をバッチ訓練と呼ぶ バッチ最適化の手法 ・勾配降下法(最急降下法) 誤差関数の減少率が最大である方向に w を動かす。 ・共役勾配法、準ニュートン法 極小点に到達していない限り、反復ごとに誤差関数が減少する。 勾配降下法よりも頑健かつ速い。
28 5.3 誤差逆伝播 目次 5.3.1 誤差関数微分の評価 5.3.2 単純な例 5.3.3 逆伝播の効率
5.3.4 ヤコビ行列 5.4 ヘッセ行列 5.4.1 対角近似 5.4.2 外積による近似 5.4.3 ヘッセ行列の逆行列 5.4.4 有限幅の差分による近似 5.4.5 ヘッセ行列の厳密な評価 5.4.6 ヘッセ行列の積の高速な計算
5.3 誤差逆伝播 29 誤差関数の最小化には2つのステップがある。 1. 誤差関数の重みに関する微分を評価する。 2. 微分を用いて重みの調整量が計算される。 誤差逆伝播は 1.
のステップにおいて特に貢献している。 2. のステップには様々な最適化スキームを組み合わせることができる。
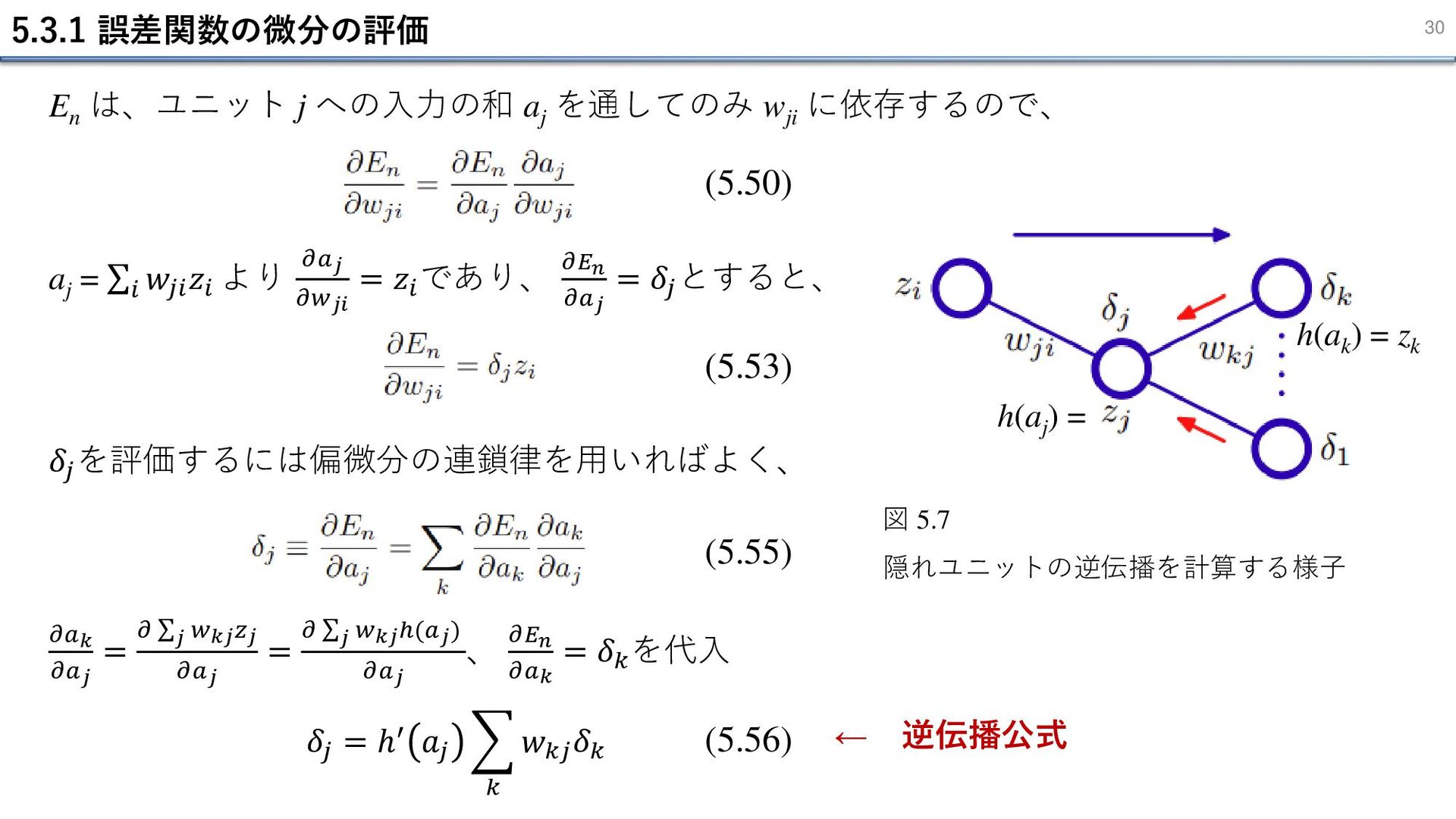
5.3.1 誤差関数の微分の評価 30 En は、ユニット j への入力の和 aj を通してのみ wji
に依存するので、 (5.50) (5.53) aj = σ𝑖 𝑤𝑗𝑖 𝑧𝑖 より 𝜕𝑎𝑗 𝜕𝑤𝑗𝑖 = 𝑧𝑖 であり、 𝜕𝐸𝑛 𝜕𝑎𝑗 = 𝛿𝑗 とすると、 𝛿𝑗 を評価するには偏微分の連鎖律を用いればよく、 (5.55) 図 5.7 隠れユニットの逆伝播を計算する様子 𝜕𝑎𝑘 𝜕𝑎𝑗 = 𝜕 σ𝑗 𝑤𝑘𝑗𝑧𝑗 𝜕𝑎𝑗 = 𝜕 σ𝑗 𝑤𝑘𝑗ℎ(𝑎𝑗) 𝜕𝑎𝑗 、 𝜕𝐸𝑛 𝜕𝑎𝑘 = 𝛿𝑘 を代入 h(aj ) = h(ak ) = zk (5.56) ← 逆伝播公式 𝛿𝑗 = ℎ′ 𝑎𝑗 𝑘 𝑤𝑘𝑗 𝛿𝑘
5.3.1 誤差関数の微分の評価 31 誤差逆伝播の手順 1. 入力 x をネットワークに入れて、𝑎𝑗 = σ𝑖
𝑤𝑗𝑖 𝑧𝑗 と 𝑧𝑗 = ℎ(𝑎𝑗 ) を用いて順伝播させ、 すべての隠れユニットと出力ユニットの出力を計算する。 2. 𝛿𝑘 = 𝑦𝑘 − 𝑡𝑘 を用いてすべての出力ユニットの 𝛿𝑘 を評価する。 3. (5.56) を用いて 𝛿 を逆伝播させ、全ての隠れユニットの 𝛿 を得る。 4. (5.53) を用いて必要な微分を評価する。 (5.56) (5.53)
5.3.3 逆伝播の効率 32 順伝播における計算量は、𝑎𝑗 = σ𝑖 𝑤𝑗𝑖 𝑧𝑗 の計算が大部分を占める。 一般に重みパラメータ数
W はユニット数よりもはるかに多いため、十分に大きいWに対して 活性化関数の評価は小さなオーバーヘッドに過ぎない。 →各項では1回の積算と1回の和算なので、順伝播の計算量は O(W) 逆伝播は 5.3.1 でみたように計算量 O(W) で実行可能なので、 全体の計算量 O(W2) で極小点を探索できる (§5.2.2)。
5.3.3 逆伝播の効率 33 逆伝播の代わりのアプローチとして、数値微分がある。 ・前進差分近似 (5.68) ・中心差分近似 (5.69) ・重みが W
個ある場合、それぞれに対して摂動を与えるため、 数値微分に必要な計算量は順伝播の計算 O(W) × ∇En の成分数分の O(W) 。 逆誤差伝播を使えば O(W) で済む工程に O(W2)の計算量を要する。 ・数値微分は計算量が多くなるが、逆伝播のアルゴリズムが正しく機能しているかどうかを テストするケースにおいては有用である。
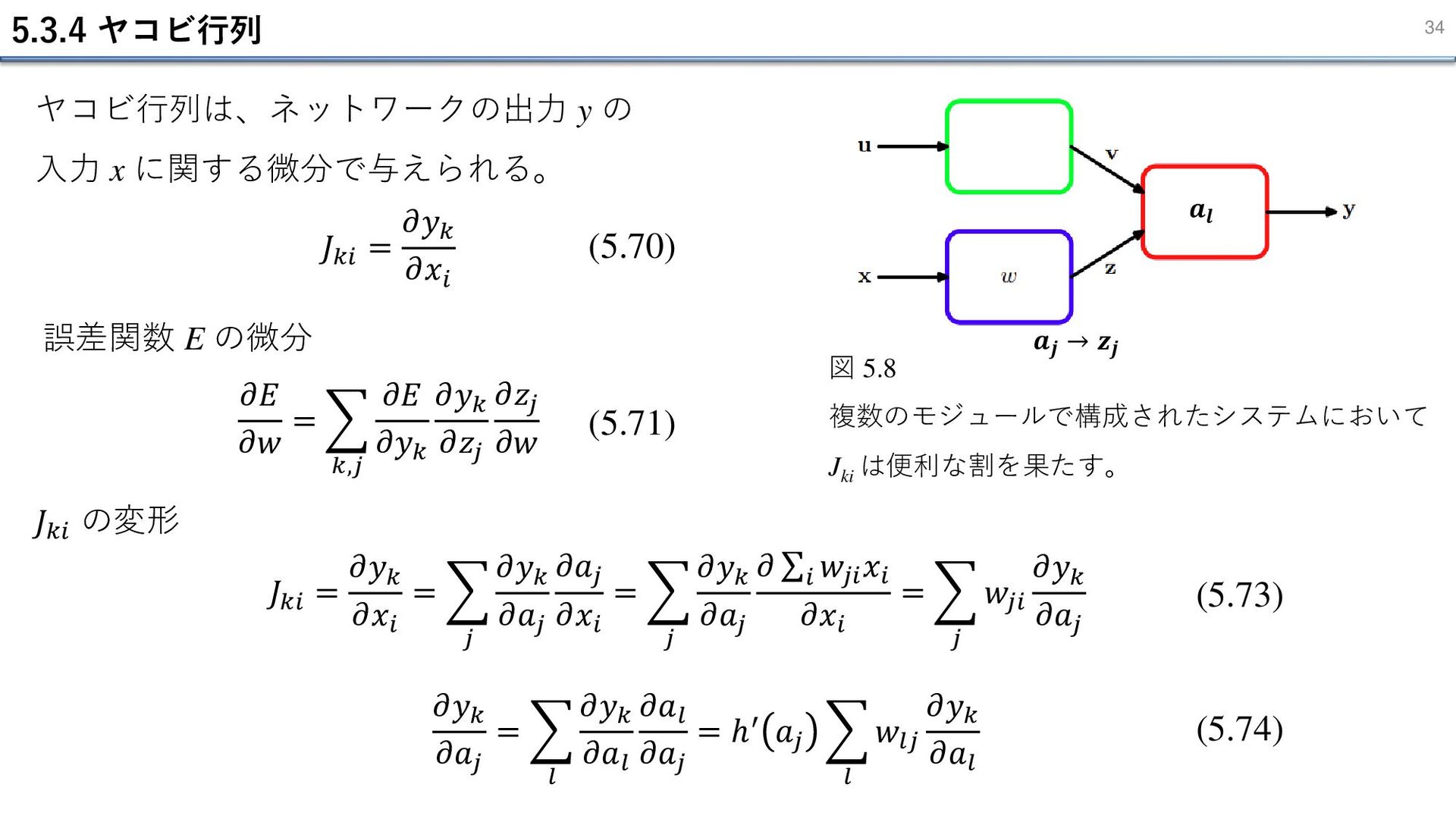
5.3.4 ヤコビ行列 34 ヤコビ行列は、ネットワークの出力 y の 入力 x に関する微分で与えられる。 (5.70)
𝐽𝑘𝑖 = 𝜕𝑦𝑘 𝜕𝑥𝑖 𝜕𝐸 𝜕𝑤 = 𝑘,𝑗 𝜕𝐸 𝜕𝑦𝑘 𝜕𝑦𝑘 𝜕𝑧𝑗 𝜕𝑧𝑗 𝜕𝑤 (5.71) 誤差関数 E の微分 𝐽𝑘𝑖 の変形 𝐽𝑘𝑖 = 𝜕𝑦𝑘 𝜕𝑥𝑖 = 𝑗 𝜕𝑦𝑘 𝜕𝑎𝑗 𝜕𝑎𝑗 𝜕𝑥𝑖 = 𝑗 𝜕𝑦𝑘 𝜕𝑎𝑗 𝜕 σ𝑖 𝑤𝑗𝑖 𝑥𝑖 𝜕𝑥𝑖 = 𝑗 𝑤𝑗𝑖 𝜕𝑦𝑘 𝜕𝑎𝑗 𝜕𝑦𝑘 𝜕𝑎𝑗 = 𝑙 𝜕𝑦𝑘 𝜕𝑎𝑙 𝜕𝑎𝑙 𝜕𝑎𝑗 = ℎ′ 𝑎𝑗 𝑙 𝑤𝑙𝑗 𝜕𝑦𝑘 𝜕𝑎𝑙 図 5.8 複数のモジュールで構成されたシステムにおいて Jki は便利な割を果たす。 𝒂𝒋 → 𝒛𝒋 𝒂𝒍 (5.73) (5.74)
35 5.3 誤差逆伝播 目次 5.3.1 誤差関数微分の評価 5.3.2 単純な例 5.3.3 逆伝播の効率
5.3.4 ヤコビ行列 5.4 ヘッセ行列 5.4.1 対角近似 5.4.2 外積による近似 5.4.3 ヘッセ行列の逆行列 5.4.4 有限幅の差分による近似 5.4.5 ヘッセ行列の厳密な評価 5.4.6 ヘッセ行列の積の高速な計算
5.4 ヘッセ行列 36 ヘッセ行列 H は、誤差関数の重みに関する 2 回微分で与えられる。 (5.78) ヘッセ行列の役割
1. ニューラルネットワークの訓練に用いられる非線形最適化アルゴリズムには、 誤差曲面の2次の性質を考慮して設計されたものがあり、それは H によって制御される。 2. H は、訓練データが少しだけ変わった場合にフィードフォワードネットワークを 再学習するための高速な手続きの基礎をなす。 3. H-1 は、ネットワークの刈り込みアルゴリズムの不要な w を特定するのに使われる。 4. ベイズニューラルネットワーク (§5.7) のラプラス近似において中心的な役割を果たす。 計算量 O(W2) となるヘッセ行列を、近似によって効率よく評価したい。
5.4.1 対角近似 37 H-1 が必要な場合に、H を対角行列に近似すれば計算が容易になる。 パターン n におけるヘッセ行列の対角成分は、 (5.79)
𝜕2𝐸𝑛 𝜕𝑤𝑗𝑖 2 = 𝜕 𝜕𝑎𝑗 𝜕𝑎𝑗 𝜕𝑤𝑗𝑖 2 𝐸𝑛 = 𝜕2𝐸𝑛 𝜕𝑎𝑗 2 𝑧𝑖 2 2回微分 𝜕2𝐸𝑛 𝜕𝑎𝑗 2 は、連鎖律を再帰的に利用することで求まる。 𝜕2𝐸𝑛 𝜕𝑎𝑗 2 = 𝜕 𝜕𝑎𝑗 𝛿𝑗 = 𝜕 𝜕𝑎𝑗 ℎ′ 𝑎𝑗 𝑘 𝑤𝑗𝑘 𝛿𝑘 = ℎ′ 𝑎𝑗 2 𝑘 𝑘′ 𝑤𝑘𝑗 𝑤𝑘′𝑗 𝜕2𝐸𝑛 𝜕𝑎𝑘 𝜕𝑎𝑘′ + ℎ′′ 𝑎𝑗 𝑘 𝑤𝑘𝑗 𝜕𝐸𝑛 𝜕𝑎𝑘 = ℎ′ 𝑎𝑗 2 𝑘 𝑤𝑘𝑗 2 𝜕2𝐸𝑛 𝜕𝑎𝑘 2 + ℎ′′ 𝑎𝑗 𝑘 𝑤𝑘𝑗 𝜕𝐸𝑛 𝜕𝑎𝑘 非対角成分を無視 (5.81) 計算量 O(W) に低減 ・H は非対角なことが多いので注意が必要。
5.4.2 外積による近似 38 二乗和誤差 𝐸𝑛 = 1 2 σ𝑛=1 𝑁
𝑦𝑛 − 𝑡𝑛 2 を利用したネットワークにおいて、 ヘッセ行列は、ネットワークの出力 yn と目標値 tn を用いて以下のように表すことができる。 (5.83) 𝜕𝐸𝑛 𝜕𝑤𝑗 = 𝜕 𝜕𝑤𝑗 1 2 𝑛 𝑁 𝑦𝑛 − 𝑡𝑛 2 = 𝑛 𝑁 𝑦𝑛 − 𝑡𝑛 𝜕𝑦𝑛 𝜕𝑤𝑗 𝜕 𝜕𝑤𝑖 𝜕𝐸𝑛 𝜕𝑤𝑗 = 𝑛 𝑁 𝜕𝑦𝑛 𝜕𝑤𝑖 𝜕𝑦𝑛 𝜕𝑤𝑗 + 𝑛 𝑁 𝑦𝑛 − 𝑡𝑛 𝜕𝑦𝑛 𝜕𝑤𝑖 𝜕𝑤𝑗 𝐇 = ∇∇𝐸𝑛 = 𝑛 𝑁 ∇𝑦𝑛 ∇𝑦𝑛 ⊤ + 𝑛 𝑁 (𝑦𝑛 − 𝑡𝑛 )∇∇𝑦𝑛 𝑦𝑛 − 𝑡𝑛 は平均ゼロの確率変数であり、学習が進むとゼロに近づいていくので無視する。 𝐇 ≃ 𝑛 𝑁 ∇𝑦𝑛 ∇𝑦𝑛 ⊤ = 𝑛 𝑁 𝐛𝒏 𝐛𝒏 ⊤ (5.84) Levenberg-Marquardt 近似 (レーベンバーグ-マーカート)
5.4.4 有限幅の差分による近似 39 誤差関数の 1 階微分の場合と同様に数値微分による近似が可能 (5.69) ・1 階微分 ・2
階微分 (5.90) ヘッセ行列には W2 個 の要素があり、1つの要素につき O(W) の順伝播を4回行うため、 全体で O(W2) × 4 O(W) → O(W3) の計算量になる。 計算量は増えるが、1 階微分のときと同様、実装のチェックには有用。
5.4.5 ヘッセ行列の厳密な評価 40 2 層ネットワークの En の 2 階微分について、 𝜕𝐸𝑛
𝜕𝑎𝑘 = 𝛿𝑘 𝜕2𝐸𝑛 𝜕𝑎𝑘 𝜕𝑎𝑘′ = 𝑀𝑘𝑘′ ・両方の重みが第 2 層にあるとき ・両方の重みが第 1 層にあるとき ・重みがそれぞれ第 1 層、第 2 層にあるとき (5.92) (5.93) (5.94) (5.95)
5.4.5 ヘッセ行列の厳密な評価 41 手書き途中式
5.4.6 ヘッセ行列の積の高速な計算 42 多くの場合、H 自体ではなく、あるベクトル v との積 𝐯⊤𝐇 = 𝐯⊤𝛁(∇𝐸𝑛
) に興味がある。 H を評価しようとすると O(W2) の計算量とメモリを必要とするのに対し、 𝐯⊤𝐇 ならば要素数が W 個しかないので、O(W) の計算量で済む。 ・𝐯⊤𝐇 を直接求めるアプローチを考えるため、 演算子 ℛ ・ = 𝐯⊤𝛁を導入する。 𝑎𝑗 = 𝑖 𝑤𝑗𝑖 𝑥𝑖 𝑧𝑗 = ℎ(𝑎𝑗 ) 𝑦𝑘 = 𝑗 𝑤𝑘𝑗 𝑧𝑗 2 層ネットワークの順伝播の式に演算子 ℛ ・ を作用させると、 ℛ 𝑎𝑗 = 𝐯⊤𝛁𝑎𝑗 = 𝐯⊤ 𝜕𝑎𝑗 𝜕𝐰 = 𝐯⊤ 𝜕 σ𝑖 𝑤𝑗𝑖 𝑥𝑖 𝜕𝐰 = 𝑖 𝑣𝑗𝑖 𝑥𝑖 ℛ 𝑧𝑗 = 𝐯⊤ 𝜕𝑧𝑗 𝜕𝐰 = 𝐯⊤ 𝜕ℎ(𝑎𝑗 ) 𝜕𝐰 = 𝐯⊤ 𝜕ℎ(𝑎𝑗 ) 𝜕𝑎𝑗 𝜕𝑎𝑗 𝜕𝐰 = ℎ′ 𝑎𝑗 ℛ 𝑎𝑗 ℛ 𝑦𝑘 = 𝐯⊤ 𝜕 σ𝑗 𝑤𝑘𝑗 𝑧𝑗 𝜕𝐰 = 𝐯⊤ 𝑗 𝜕𝑤𝑘𝑗 𝜕𝐰 𝑧𝑗 + 𝑤𝑘𝑗 𝜕𝑧𝑗 𝜕𝐰 = 𝑗 𝑣𝑘𝑗 𝑧𝑗 + 𝑗 𝑤𝑘𝑗 ℛ 𝑧𝑗 (5.101) (5.102) (5.103)
5.4.6 ヘッセ行列の積の高速な計算 43 二乗和誤差 𝐸𝑛 = 1 2 σ𝑛=1 𝑁
𝑦𝑛 − 𝑡𝑛 2 について考えると、 𝛿𝑘 = 𝑦𝑘 − 𝑡𝑘 (5.107) 𝛿𝑗 = ℎ′ 𝑎𝑗 𝑘 𝑤𝑘𝑗 𝛿𝑘 ℛ 𝛿𝑘 = ℛ 𝑦𝑘 ℛ 𝛿𝑗 = ℎ′′ 𝑎𝑗 ℛ 𝑎𝑗 𝑘 𝑤𝑘𝑗 𝛿𝑘 (5.106) 最後に、𝜕𝐸𝑛 𝜕𝑤 に演算子 ℛ ・ を作用させると𝐯⊤𝐇 の要素が得られる。 𝜕𝐸𝑛 𝜕𝑤 𝑗𝑖 (1) = 𝛿𝑗 𝑥𝑖 ℛ 𝜕𝐸𝑛 𝜕𝑤 𝑗𝑖 1 = 𝑥𝑖 ℛ 𝛿𝑗 𝜕𝐸𝑛 𝜕𝑤 𝑘𝑗 (2) = 𝛿𝑘 𝑧𝑗 ℛ 𝜕𝐸𝑛 𝜕𝑤 𝑘𝑗 (2) = ℛ 𝛿𝑘 𝑧𝑗 + 𝛿𝑘 ℛ 𝑧𝑗 (5.110) (5.111) 𝐯⊤𝐇 を評価する方程式が、標準的な逆伝播の方程式を再現している。 (逆伝播で導入した δ を利用してヘッセ行列の要素を表すことができている。) ℛ ・ = 𝐯⊤𝛁 + ℎ′ 𝑎𝑗 𝑘 𝑣𝑘𝑗 𝛿𝑘 + ℎ′ 𝑎𝑗 𝑘 𝑤𝑘𝑗 ℛ 𝛿𝑘
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}