Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
LLMチャットボットの評価モデル
Search
Sponsored
·
SiteGround - Reliable hosting with speed, security, and support you can count on.
→
Shinsuke Matsuki(snsk)
January 20, 2025
Technology
35
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
LLMチャットボットの評価モデル
Shinsuke Matsuki(snsk)
January 20, 2025
More Decks by Shinsuke Matsuki(snsk)
See All by Shinsuke Matsuki(snsk)
品質定義の組織レベル
snsk
0
66
メタモルフィックテスティングでMBT気分
snsk
0
25
ゲームのテスト設計のチャレンジ
snsk
0
59
JSTQB Conference2023 基調講演2
snsk
0
23
Other Decks in Technology
See All in Technology
SONiCの統計情報を取得したい
sonic
0
260
現地で盛り上がった WWDC26 Keynote
zozotech
PRO
1
270
「勝手に広まる」人気 AI エージェントを爆速で作ろう!(AWS Summit Japan 2026講演資料)
minorun365
PRO
10
2.2k
Kiro Ambassador を目指す話
k_adachi_01
0
110
【セミナー資料】Claude Code をセキュアに使うための考え方と設定の勘どころ / Claude Code Webinar 20260616
masahirokawahara
2
430
PostgreSQL 19 新機能概要 OSC Hokkaido 2026
nori_shinoda
0
190
SONiCで構築・運用する生成AI向けパブリッククラウドネットワーク ~実装編~
sonic
0
310
アジャイルな経理と Claude Code と 経営の未来
kawaguti
PRO
3
170
AWS Security Agent といっしょに脅威モデリングをやってみよう
amarelo_n24
1
190
AWS Security Hub CSPMの成功・失敗体験
cmusudakeisuke
0
360
Oracle AI Database@AWS:サービス概要のご紹介
oracle4engineer
PRO
4
3k
【Snowflake Summit 2026 Recap!!】Snowflake Summit Deep Dive: Security & Governance
civitaspo
1
280
Featured
See All Featured
Gemini Prompt Engineering: Practical Techniques for Tangible AI Outcomes
mfonobong
2
440
Ruling the World: When Life Gets Gamed
codingconduct
0
260
Agile that works and the tools we love
rasmusluckow
331
21k
Bioeconomy Workshop: Dr. Julius Ecuru, Opportunities for a Bioeconomy in West Africa
akademiya2063
PRO
1
150
KATA
mclloyd
PRO
35
15k
What Being in a Rock Band Can Teach Us About Real World SEO
427marketing
0
260
Automating Front-end Workflow
addyosmani
1370
210k
Agile Actions for Facilitating Distributed Teams - ADO2019
mkilby
0
210
The State of eCommerce SEO: How to Win in Today's Products SERPs - #SEOweek
aleyda
2
11k
First, design no harm
axbom
PRO
2
1.2k
10 Git Anti Patterns You Should be Aware of
lemiorhan
PRO
659
62k
Unlocking the hidden potential of vector embeddings in international SEO
frankvandijk
0
850
Transcript
LLMチャットボットの評価モデル https://www.confident-ai.com/blog/llm-chatbot-evaluation-explained-top-chatbot-evaluation-metrics-and-testing-techniques 出典: 役割の遵守 会話の関連性 知識の保持 会話の完全性 会話全体を通じて LLM チャットボットが指示どおりに行動できるかどうかを評価します。これは、ロール
プレイングのユースケースに特に役立ちます。最終的なロール遵守メトリックスコアは、指定されたチャット ボットがロールに従ったターン数を、会話テストケースの合計ターン数で割った値です LLM チャットボットが会話全体を通じて関連性のある応答を生成できるかどうかを評価します。これは、 各ターンを個別にループして計算され、スライディングウィンドウ アプローチを採用し、最後の min(0, current turn number — window size)ターンを考慮して関連性があるかどうかを判断します。最終 的な会話の関連性メトリックスコアは、関連するターン応答の数を会話テストケースの合計ターン数で割っ た値です LLMチャットボットが会話全体を通じて提示された情報を保持できるかどうかを評価します。これは、ま ず会話の特定のターンまでに提示された知識のリストを抽出し、LLM がターン応答にすでに存在する情 報を求めているかどうかを判断することによって計算されます。知識保持スコアは、知識の喪失がない ターンの数をターンの合計数で割ったものです。 会話全体を通じて LLM チャットボットがユーザーの要求を満たすことができるかどうかを評価します。 会話の完全性は、ユーザー満足度とチャットボットの有効性を測定するための代替評価として使用できま す。会話の完全性は、最初に LLM を使用して会話ターンで見つかった高レベルのユーザー意図のリスト を抽出し、次に同じ LLM を使用して会話全体で各意図が満たされたかどうかを判断して計算されます。 Slide: Shinsuke.Matsuki.2024
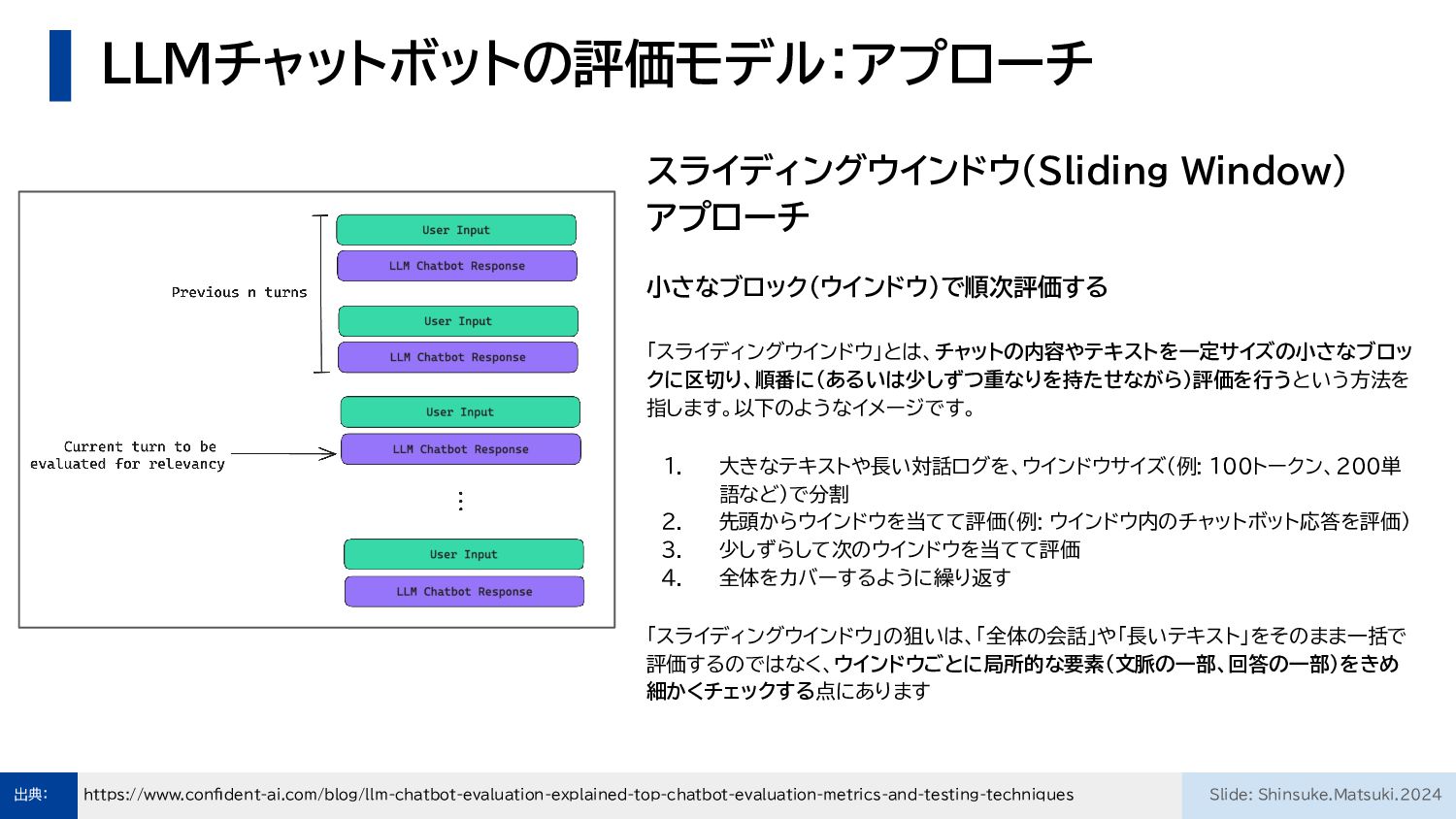
LLMチャットボットの評価モデル:アプローチ https://www.confident-ai.com/blog/llm-chatbot-evaluation-explained-top-chatbot-evaluation-metrics-and-testing-techniques 出典: Slide: Shinsuke.Matsuki.2024 スライディングウインドウ(Sliding Window) アプローチ 小さなブロック(ウインドウ)で順次評価する 「スライディングウインドウ」とは、チャットの内容やテキストを一定サイズの小さなブロッ
クに区切り、順番に(あるいは少しずつ重なりを持たせながら)評価を行うという方法を 指します。以下のようなイメージです。 1. 大きなテキストや長い対話ログを、ウインドウサイズ(例: 100トークン、200単 語など)で分割 2. 先頭からウインドウを当てて評価(例: ウインドウ内のチャットボット応答を評価) 3. 少しずらして次のウインドウを当てて評価 4. 全体をカバーするように繰り返す 「スライディングウインドウ」の狙いは、「全体の会話」や「長いテキスト」をそのまま一括で 評価するのではなく、ウインドウごとに局所的な要素(文脈の一部、回答の一部)をきめ 細かくチェックする点にあります
LLMチャットボットの評価モデル:アプローチ https://www.confident-ai.com/blog/llm-chatbot-evaluation-explained-top-chatbot-evaluation-metrics-and-testing-techniques 出典: Slide: Shinsuke.Matsuki.2024 局所評価を積み重ねるメリット • 詳細な不具合やエラー箇所を発見しやすい ウインドウを使うことで、対話ログ中のどのセクションで問題が起きやすいかを見極められます。 •
チャットボットの長い対話でも評価しやすい 一度に大量の文字数を扱う場合、評価基準がぼやけたり評価コストが膨大になったりすることがあります。スライディングウイ ンドウで段階的に評価することでその問題を軽減できます。 • メトリクスが安定しやすい 1箇所だけ極端に良い /悪い応答があっても全体平均に埋もれることがあるため、ウインドウ単位での評価を集計することでト レンドを捉えやすくなります。 スライディングウインドウの注意点 • ウインドウサイズ・ステップサイズの選定 ◦ 大きすぎるウインドウでは「細部を見逃しがち」、小さすぎると「文脈が途切れて正しい評価ができない」など、バランスが重 要 • 評価コスト ◦ ウインドウ単位で繰り返し評価するため、評価ツールや人手アノテーションのコストが増大する場合がある • 重複カウント・重複評価の扱い ◦ ウインドウ同士が重複する場合、その部分の応答をどう扱うかを明確に決めておかないと、一部の箇所だけ過剰に評価さ れる可能性がある
{kind=link}
{kind=link}
{kind=link}