SECR 2018
Екатерина Полицына
Доцент, Московский авиационный институт (национальной исследовательский университет)
Потребность в автоматизации обработки больших объемов текстовых данных приводит к необходимости использования инструментов компьютерной лингвистики в прикладных промышленных системах разной направленности (системах документооборота, электронной коммерции и др.), что накладывает дополнительные требования к средствам автоматического анализа текста.
В отличие более мягких требований к исследовательским инструментам, для использования в промышленных системах необходимы библиотеки, отвечающие требованиям производительности, надежности, совместимости с современными современными языками программирования, сборки проектов и т.д.
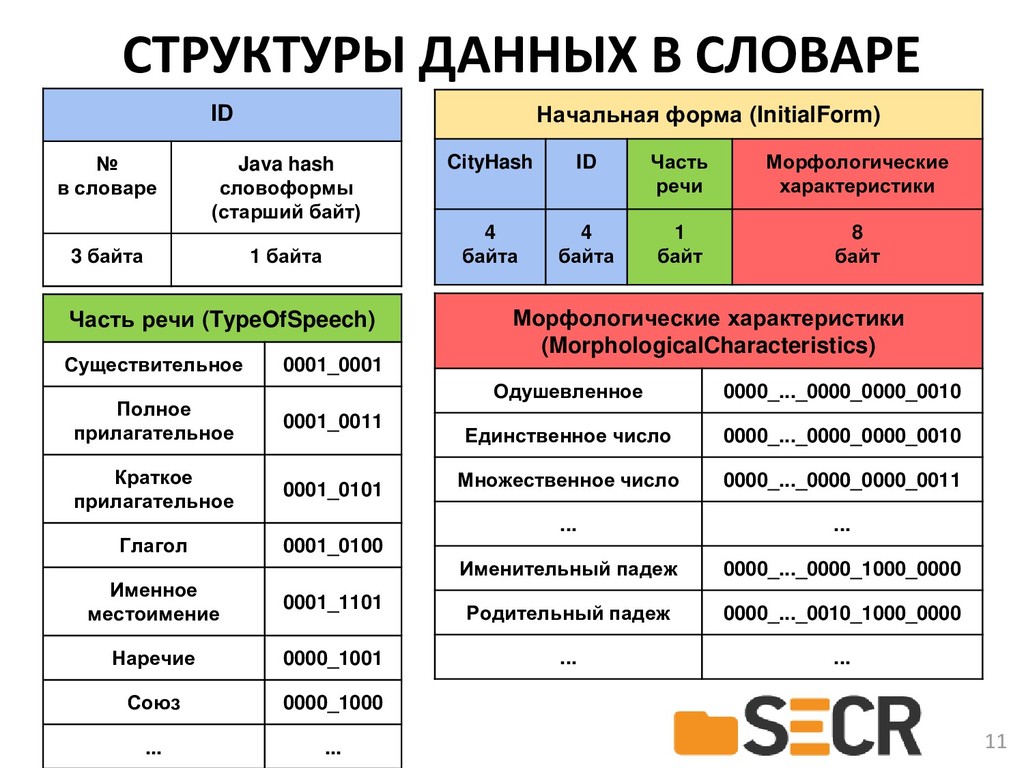
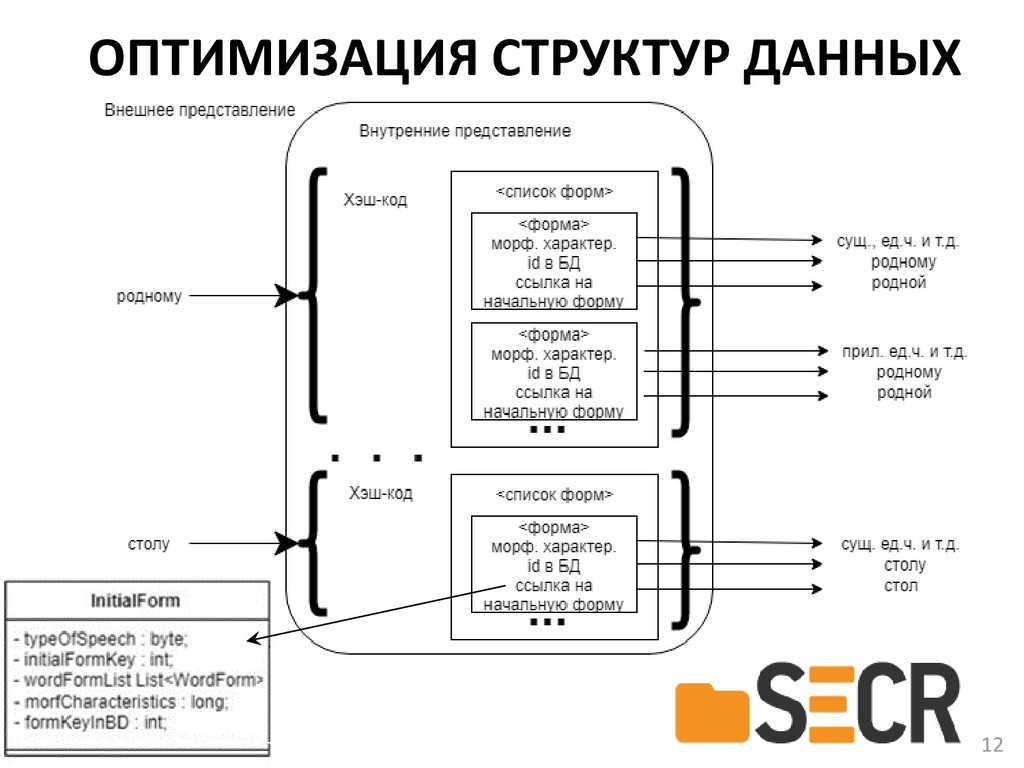
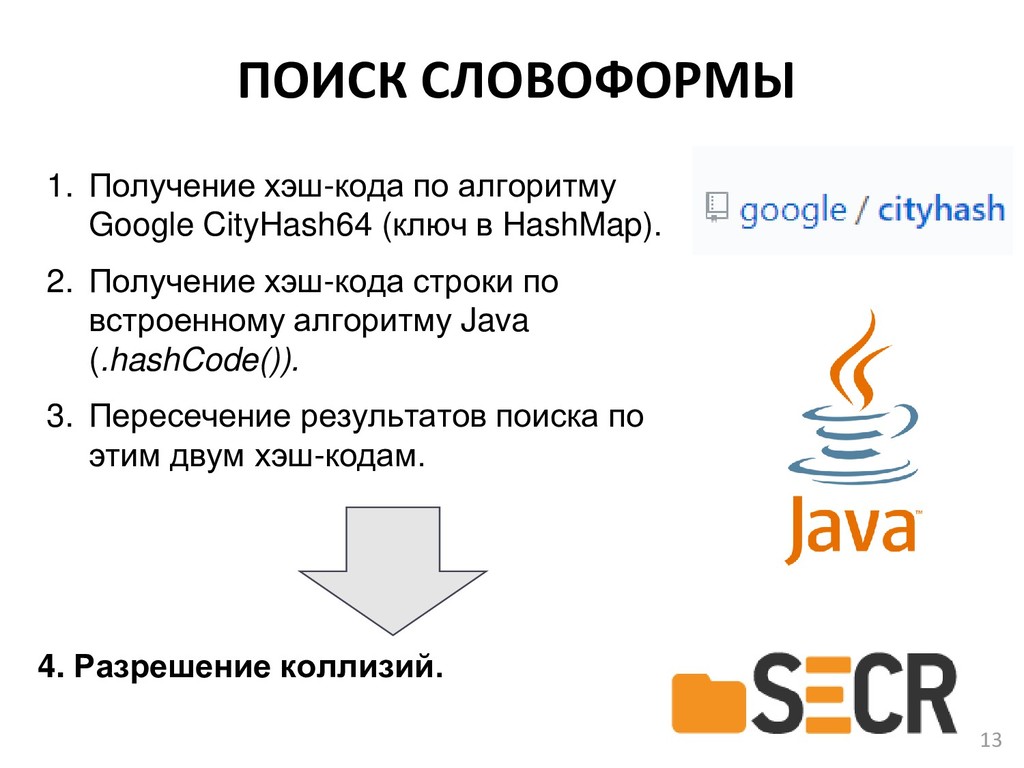
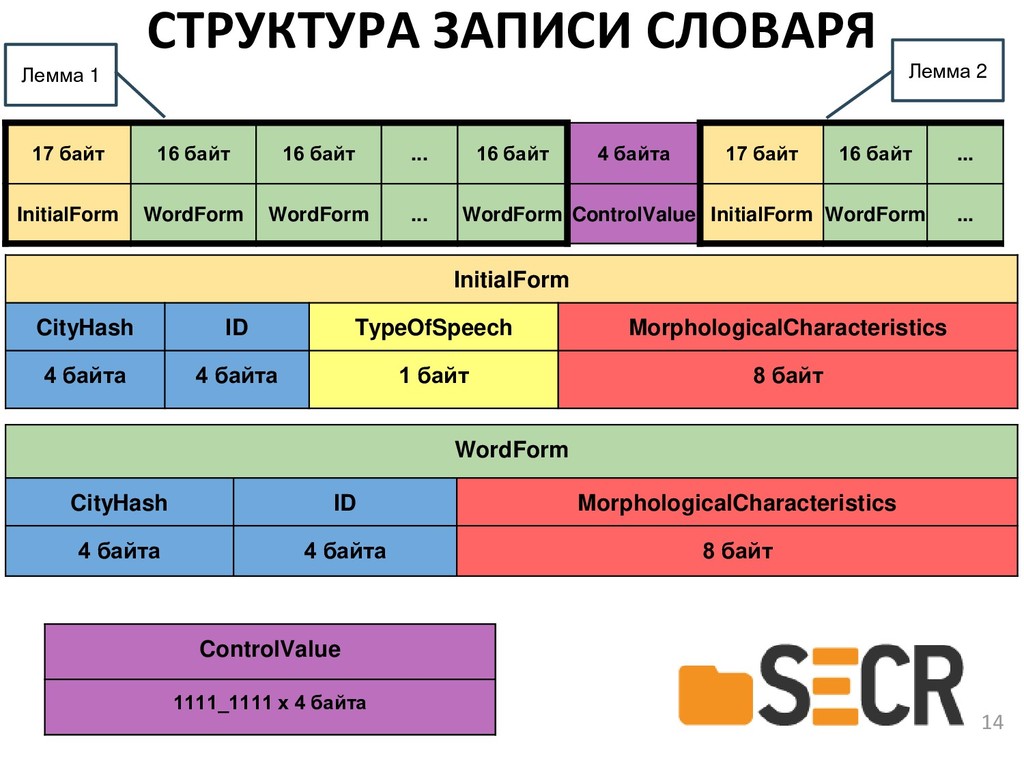
В докладе предлагается новая кроссплатформенная библиотека морфологического анализа текстов на русском языке с открытым исходным кодом, которая может быть полезна разработчикам информационных систем и исследователям в области компьютерной лингвистики для получения начальных форм слова или генерации нужной формы по заданным морфологическим характеристикам.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
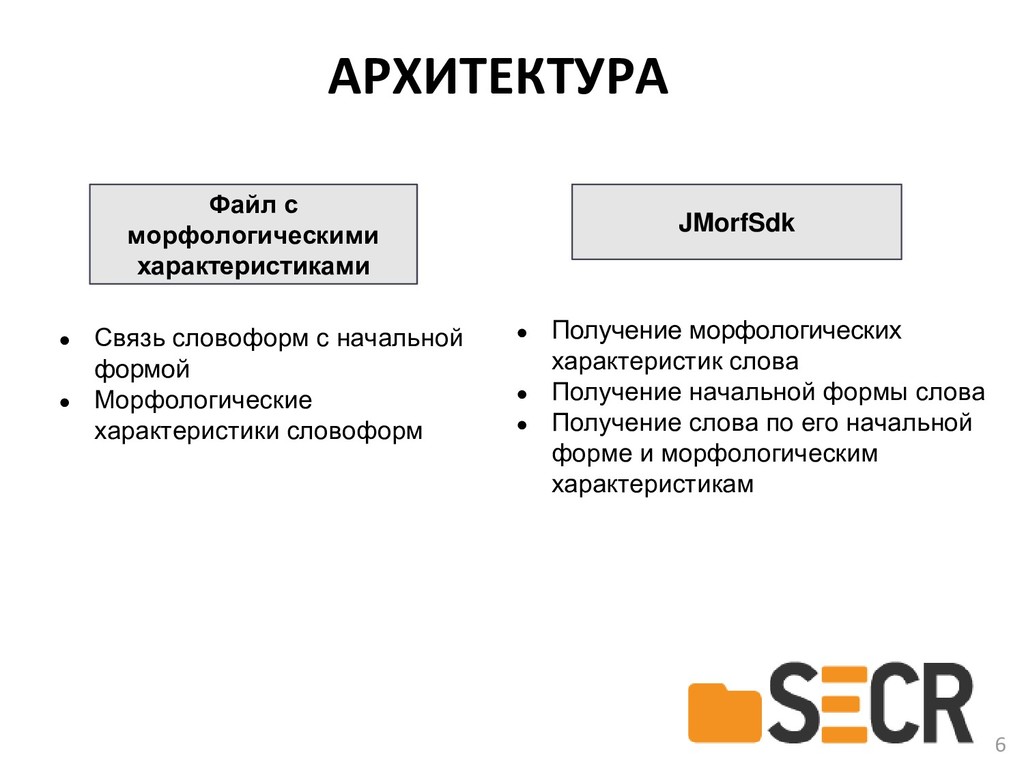{kind=link}
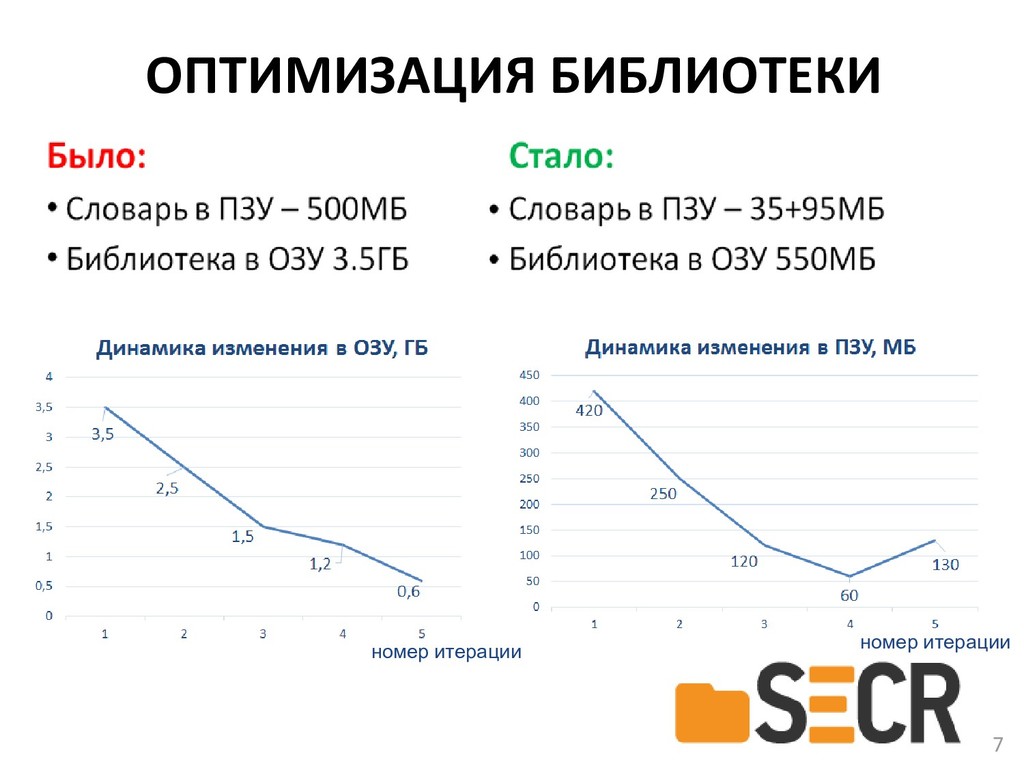{kind=link}
{kind=link}
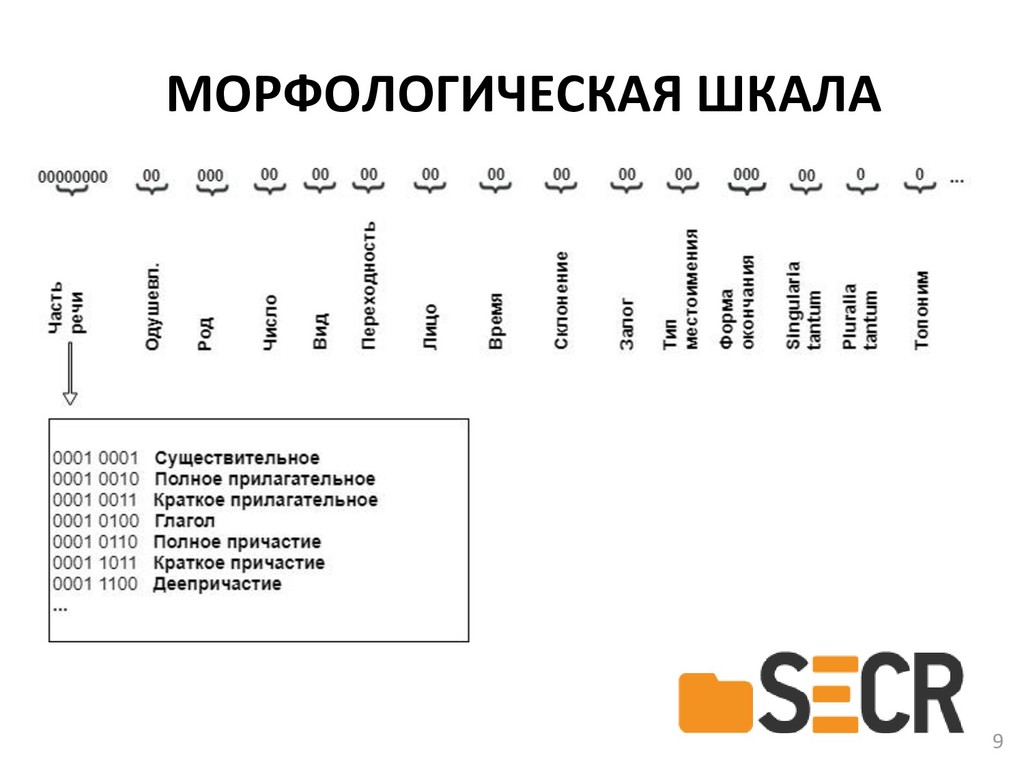{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
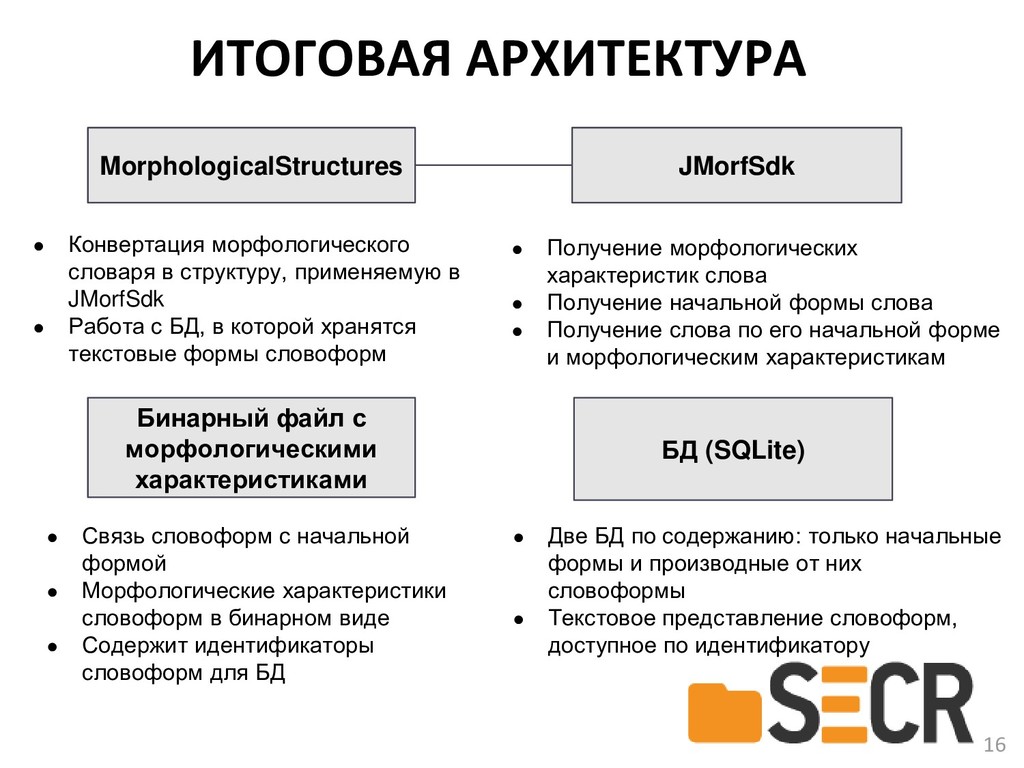{kind=link}
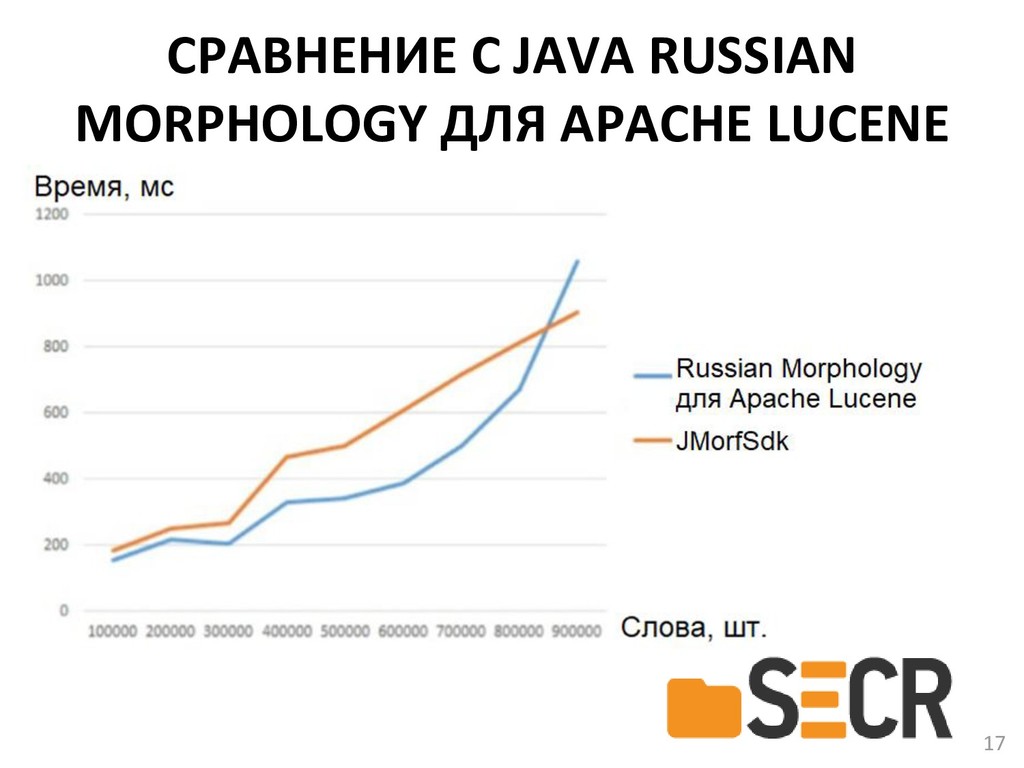{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}