Here are the slides used on IstioCon2021 Lightning Talk.
https://events.istio.io/istiocon-2021/sessions/how-istio-helped-us-investigate-failures-on-our-microservices/
---
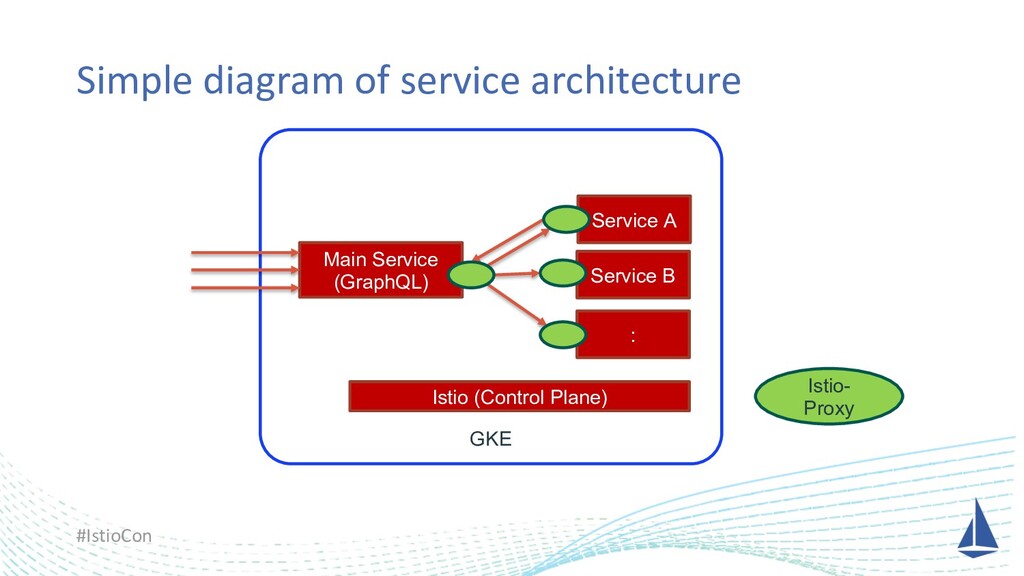
We introduced Istio to our microservices. Istio’s logs, metrics, and features are very helpful for us to investigate in detail in case of failures.
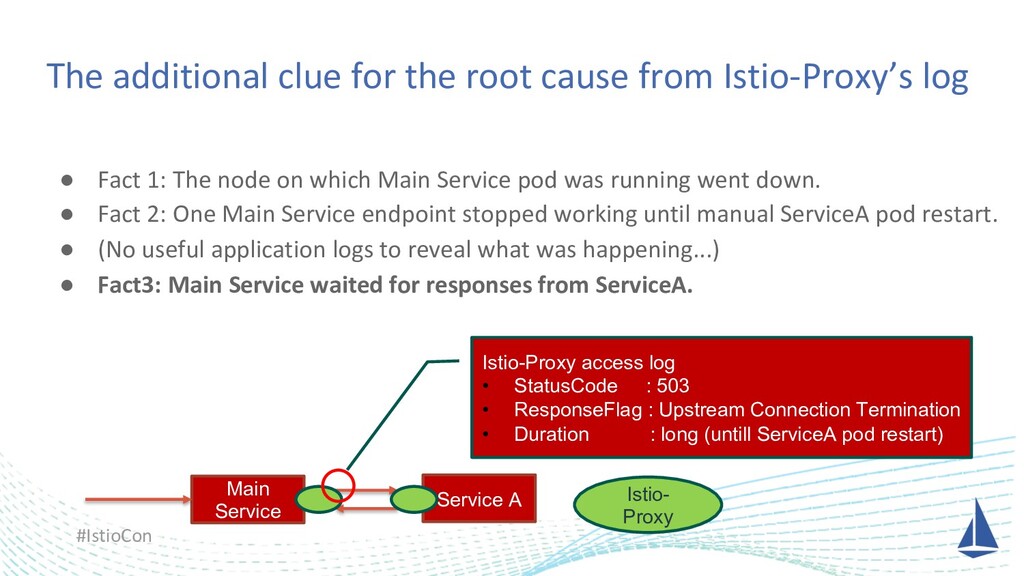
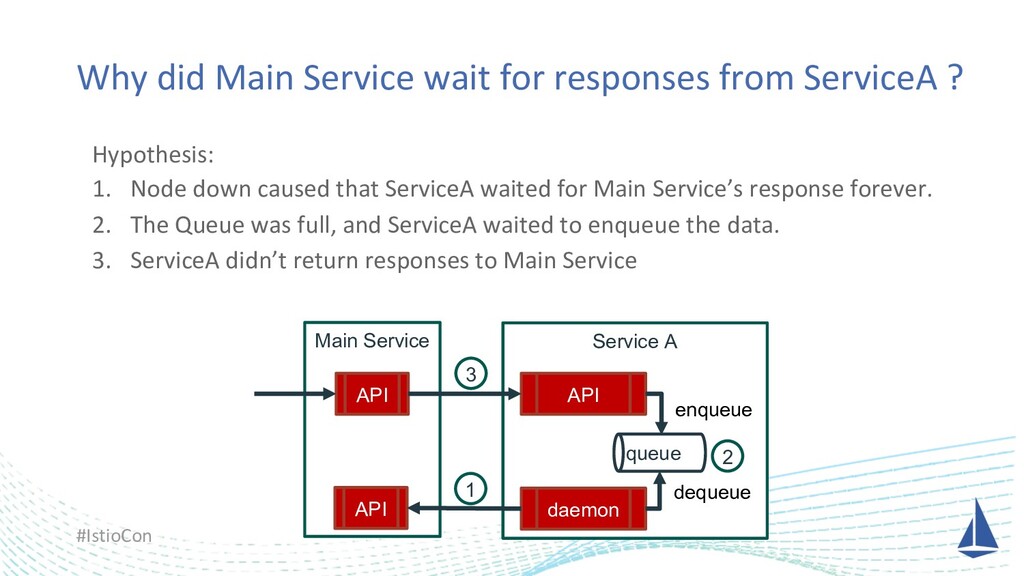
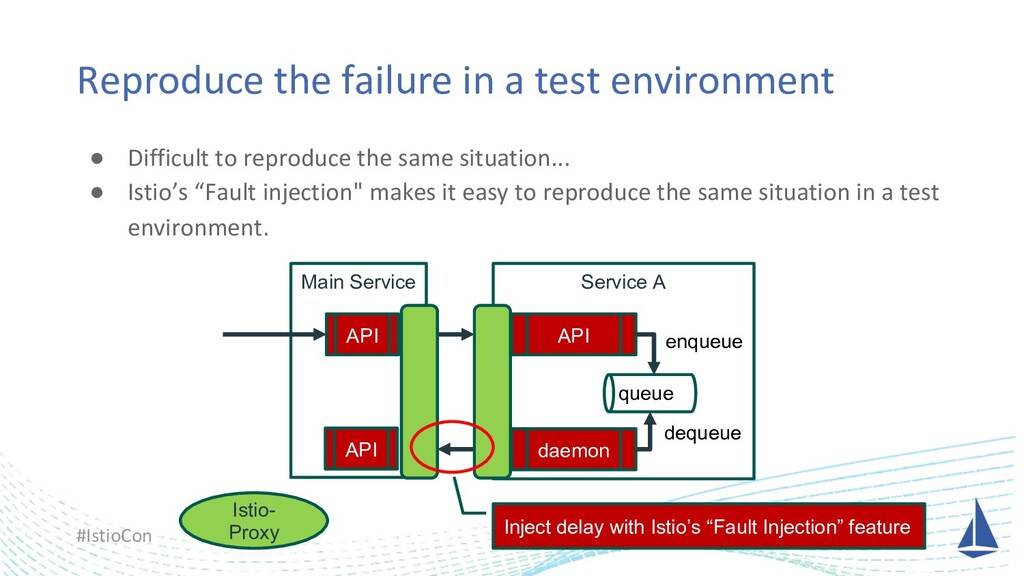
One day we had big trouble due to a node failure, and it was very hard to find the root cause of why our application had not been recovered automatically. At that time, we finally found the root cause of it on our application logic thanks to Istio and we could reproduce the same failure in the development environment with Istio as well. I’d like to share this story.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}