1. Typical issues within designing a large Kubernetes cluster on GKE/On-Prem.
2. Pitfalls and possible tricky areas in elaboration.
3. Consider existing solutions consistent with real-life and best practice cases.
automating the deployment, scaling, and management of containerized applications. However, maintaining the service can be difficult and expensive. For that reason, it is easy to find platforms offering Kubernetes as a managed service.
to 5000 nodes. More specifically, kubernetes support configurations that meet all of the following criteria: • No more than 5000 nodes • No more than 150000 total pods • No more than 300000 total containers • No more than 100 pods per node
quota issues, when creating a cluster with many nodes, consider: • Increase the quota for things like CPU, IPs, etc. ◦ In GCE, for example, you’ll want to increase the quota for: ◦ CPUs ◦ VM instances ◦ Total persistent disk reserved ◦ In-use IP addresses ◦ Firewall Rules
Target pools • Preparing the setup script so that it brings up new node VMs in smaller batches with waits in between, because some cloud providers rate limit the creation of VMs.
clusters, we store events in a separate dedicated etcd instance. When creating a cluster, existing scripts: • start and configure additional etcd instance • configure api-server to use it for storing events
than 100 clients, fewer than 200 of requests per second, and stores no more than 100MB of data. Example application workload: A 50-node Kubernetes cluster Provider Type vCPUs Memory (GB) Max concurrent IOPS Disk bandwidth (MB/s) AWS m4.large 2 8 3600 56.25 GCE n1-standard-2 + 50GB PD SSD 2 7.5 1500 25
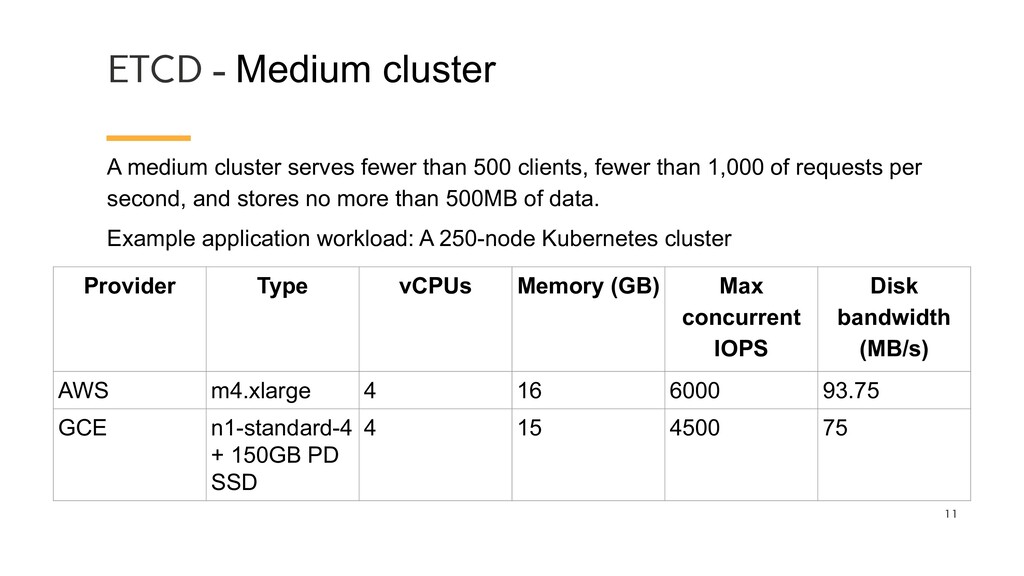
than 500 clients, fewer than 1,000 of requests per second, and stores no more than 500MB of data. Example application workload: A 250-node Kubernetes cluster Provider Type vCPUs Memory (GB) Max concurrent IOPS Disk bandwidth (MB/s) AWS m4.xlarge 4 16 6000 93.75 GCE n1-standard-4 + 150GB PD SSD 4 15 4500 75
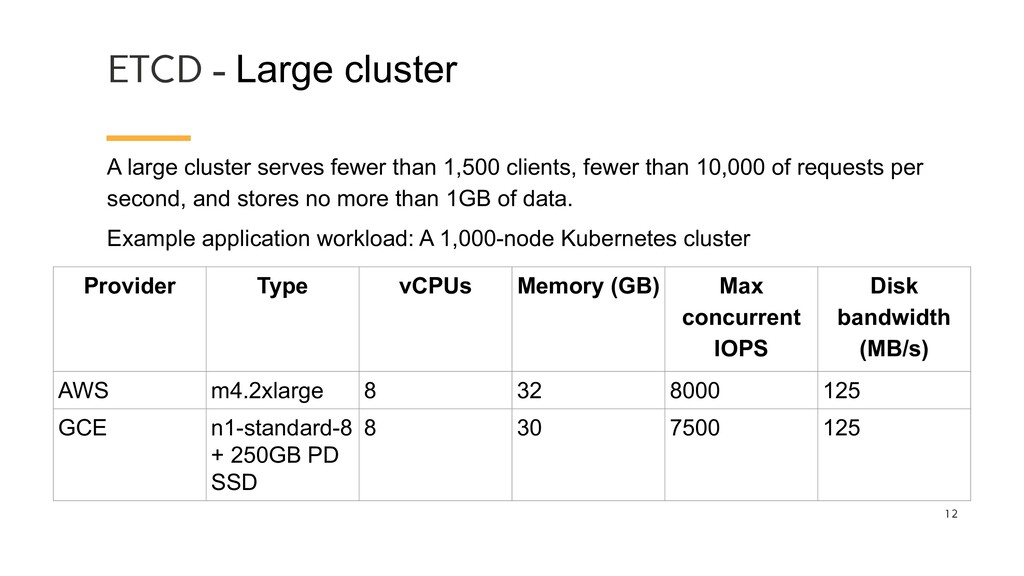
than 1,500 clients, fewer than 10,000 of requests per second, and stores no more than 1GB of data. Example application workload: A 1,000-node Kubernetes cluster Provider Type vCPUs Memory (GB) Max concurrent IOPS Disk bandwidth (MB/s) AWS m4.2xlarge 8 32 8000 125 GCE n1-standard-8 + 250GB PD SSD 8 30 7500 125
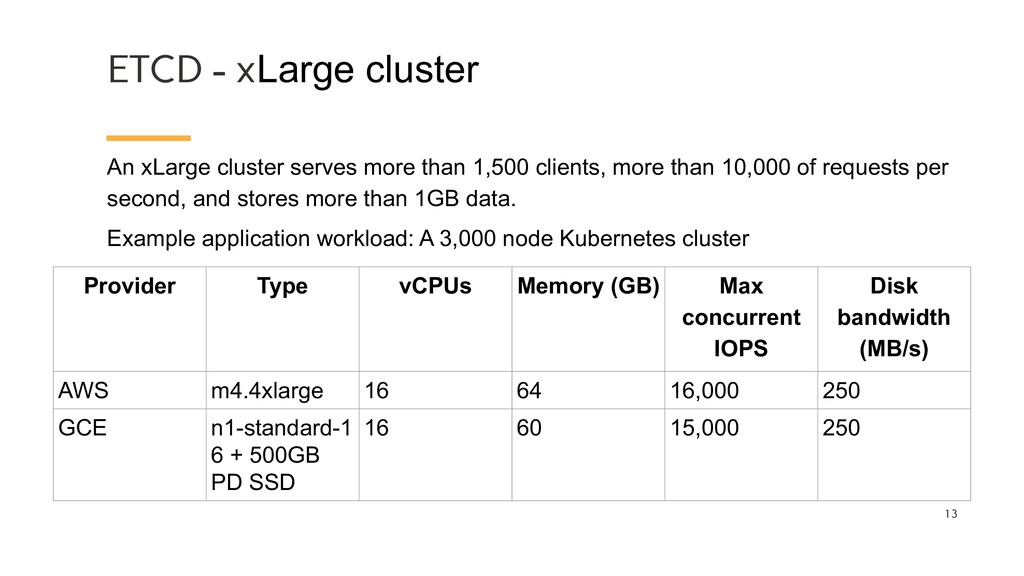
than 1,500 clients, more than 10,000 of requests per second, and stores more than 1GB data. Example application workload: A 3,000 node Kubernetes cluster Provider Type vCPUs Memory (GB) Max concurrent IOPS Disk bandwidth (MB/s) AWS m4.4xlarge 16 64 16,000 250 GCE n1-standard-1 6 + 500GB PD SSD 16 60 15,000 250
Kubernetes Engine, and AWS, kube-up automatically configures the proper VM size for your master depending on the number of nodes in your cluster. On other providers, you will need to configure it manually. For reference, the sizes we use on GCE are • 1-5 nodes: n1-standard-1 • 6-10 nodes: n1-standard-2 • 11-100 nodes: n1-standard-4 • 101-250 nodes: n1-standard-8 • 251-500 nodes: n1-standard-16 • more than 500 nodes: n1-standard-32
issues in cluster addons from consuming all the resources available on a node, Kubernetes sets resource limits on addon containers to limit the CPU and Memory resources they can consume. To avoid running into cluster addon resource issues, when creating a cluster with many nodes, consider the following: • Scale memory and CPU limits for each of the following addons, if used, as you scale up the size of cluster (there is one replica of each handling the entire cluster so memory and CPU usage tends to grow proportionally with size/load on cluster): ◦ InfluxDB, Grafana, Kibana ◦ kubedns, dnsmasq, and sidecar
addons, if used, along with the size of cluster (there are multiple replicas of each so increasing replicas should help handle increased load, but, since load per replica also increases slightly, also consider increasing CPU/memory limits): • elasticsearch Increase memory and CPU limits slightly for each of the following addons, if used, along with the size of cluster (there is one replica per node but CPU/memory usage increases slightly along with cluster load/size as well): • FluentD with ElasticSearch Plugin • FluentD with GCP Plugin
50 clusters per zone, plus 50 regional clusters per region. GKE's per-cluster limits are: • Maximum of 5000 nodes per cluster. ◦ Route-based networking - 2000 nodes ◦ VPC-Narite - 5000 nodes • Maximum of 1000 nodes per node pool. • Maximum of 1000 nodes per cluster if you use the GKE ingress controller. • 110 Pods per node. • 300,000 containers.
assign IP addresses to nodes, Pods, and Services. • Each node has an IP address assigned from the cluster's Virtual Private Cloud (VPC) network. This node IP provides connectivity from control components like kube-proxy and the kubelet to the Kubernetes API server. This IP is the node's connection to the rest of the cluster. • Each node has a pool of IP addresses that GKE assigns Pods running on that node (a /24 CIDR block by default). You can optionally specify the range of IPs when you create the cluster. The Flexible Pod CIDR range feature allows you to reduce the size of the range for Pod IPs for nodes in a given node pool.
region, per account: 50 Maximum number of control plane security groups per cluster (these are specified when you create the cluster) - 5 Amazon EKS supports native VPC networking via the Amazon VPC CNI plugin for Kubernetes. Using this CNI plugin allows Kubernetes pods to have the same IP address inside the pod as they do on the VPC network. https://github.com/awslabs/amazon-eks-ami/blob/master/files/eni-max-pods.txt
for instance type ) * ( IPv4 Addresses per Interface ) - 1 For example, if you have a t3.medium instance which support max 3 ethernet and 6 IPs per interface. You can create only 17 pods including the kubernetes internal Pods, Because One IP is reserved for nodes itself. 3 * 6 - 1 = 17
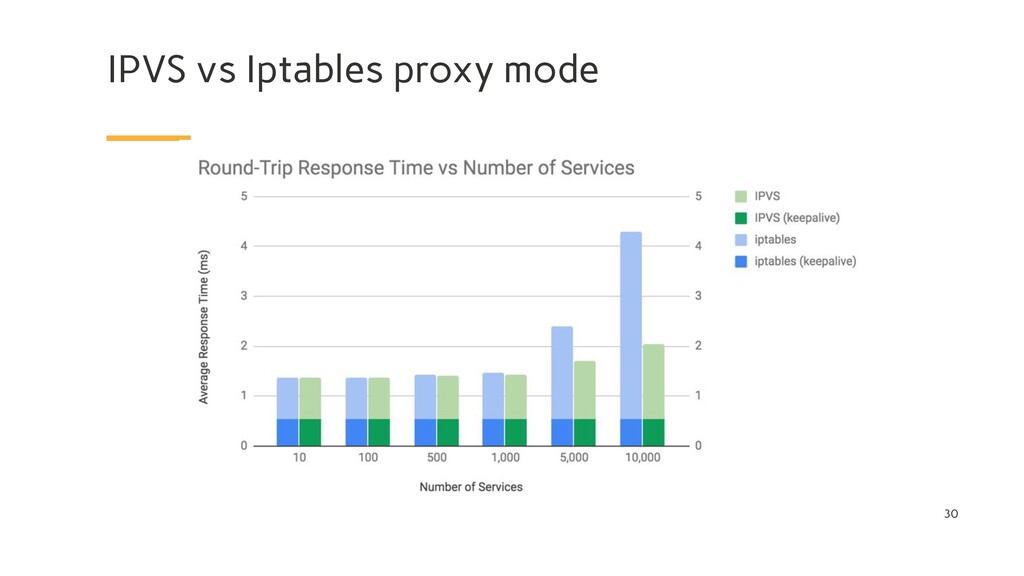
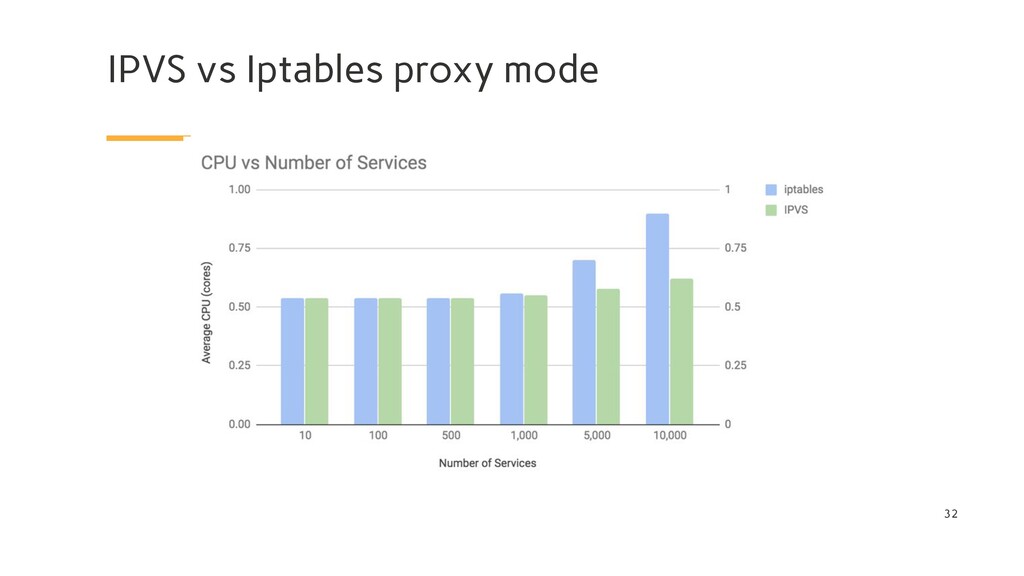
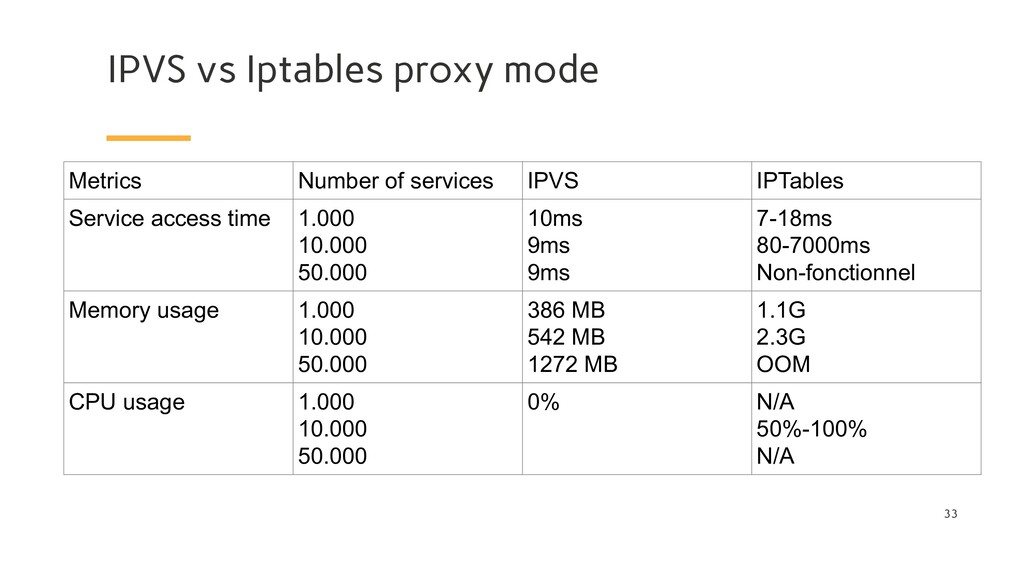
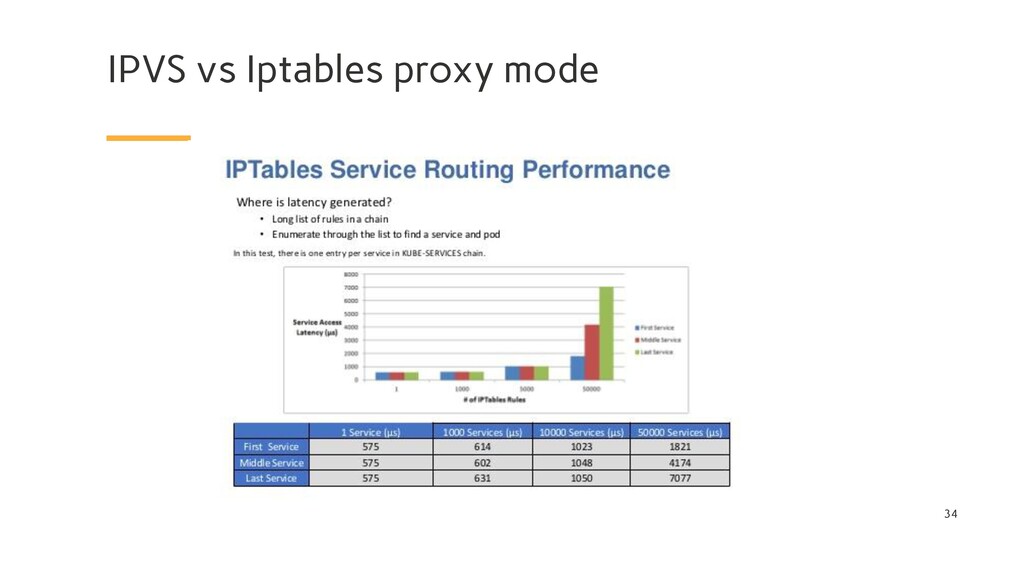
kernel feature that was designed to be an efficient firewall with sufficient flexibility to handle a wide variety of common packet manipulation and filtering needs. It allows flexible sequences of rules to be attached to various hooks in the kernel’s packet processing pipeline. In iptables mode, kube-proxy attaches rules to the “NAT pre-routing” hook to implement its NAT and load balancing functions. This works, it’s simple, it uses a mature kernel feature, and, it “plays nice” with other programs that also work with iptables for filtering (such as Calico!). However, the way kube-proxy programs the iptables rules means that it is nominally an O(n) style algorithm, where n grows roughly in proportion to your cluster size (or more precisely the number of services and number of backend pods behind each service).
kernel feature that is specifically designed for load balancing. In IPVS mode, kube-proxy programs the IPVS load balancer instead of using iptables. This works, it also uses a mature kernel feature and IPVS is designed for load balancing lots of services; it has an optimized API and an optimized look-up routine rather than a list of sequential rules. The result is that kube-proxy’s connection processing in IPVS mode has a nominal computational complexity of O(1). In other words, in most scenarios, its connection processing performance will stay constant independent of your cluster size.
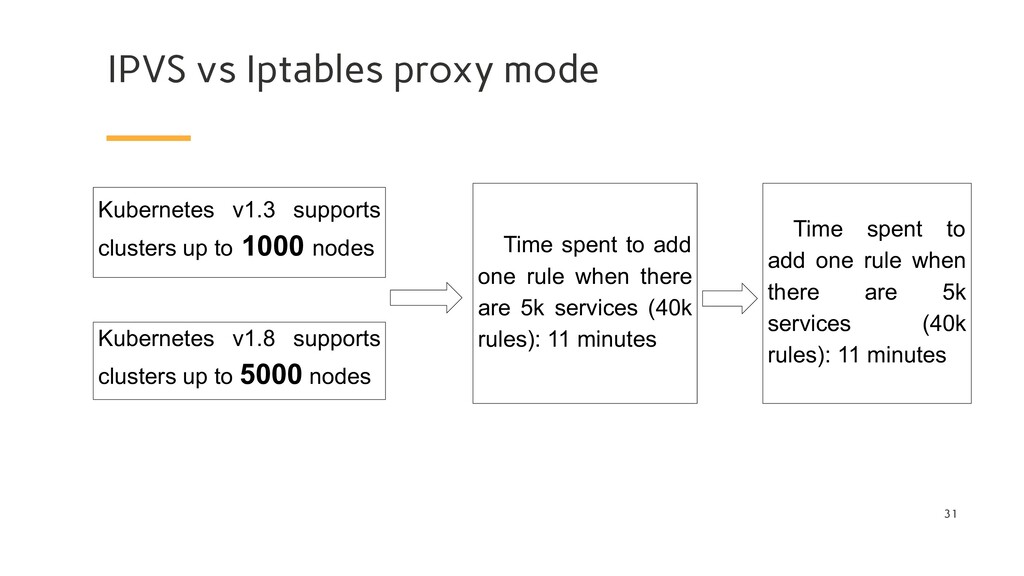
up to 1000 nodes Kubernetes v1.8 supports clusters up to 5000 nodes Time spent to add one rule when there are 5k services (40k rules): 11 minutes Time spent to add one rule when there are 5k services (40k rules): 11 minutes
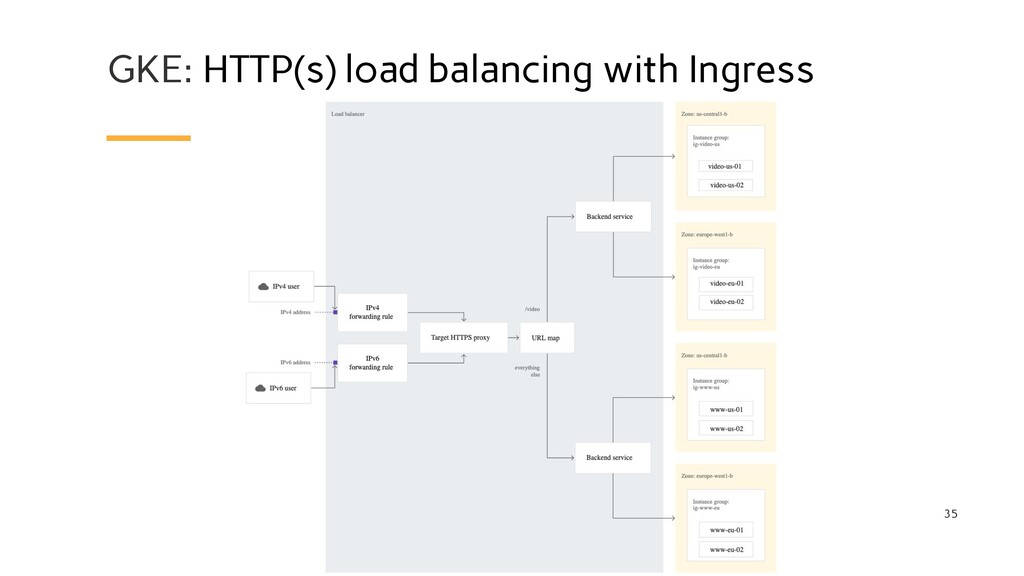
GCE L7 load balancer controller that manages external loadbalancers configured through the Kubernetes Ingress API. Limitations: • The total length of the namespace and name of an Ingress must not exceed 40 characters. Failure to follow this guideline may cause the GKE ingress controller to act abnormally. • The maximum number of rules for a URL map is 50. This means that you can specify a maximum of 50 rules in an Ingress. • Maximum of 1000 nodes per cluster if you use the GKE ingress controller.
the GKE ingress controller to use your readinessProbes as health checks, the Pods for an Ingress must exist at the time of Ingress creation. If your replicas are scaled to 0, the default health check will apply. For more information, see this issue comment. • Changes to a Pod's readinessProbe do not affect the Ingress after it is created. • The HTTPS load balancer terminates TLS in locations that are distributed globally, so as to minimize latency between clients and the load balancer. If you require geographic control over where TLS is terminated, you should use a custom ingress controller and GCP Network Load Balancing instead, and terminate TLS on backends that are located in regions appropriate to your needs.
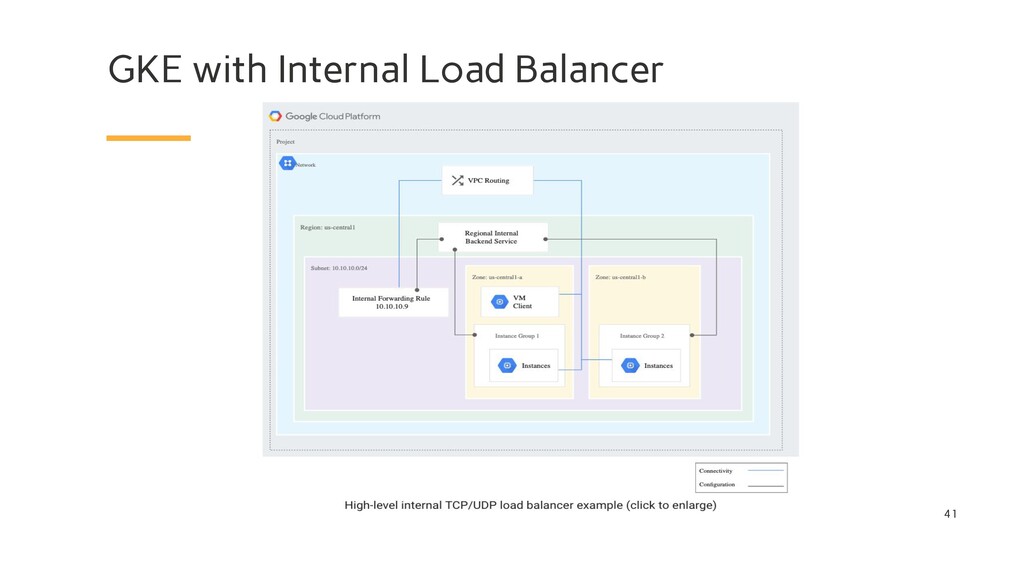
Internal TCP/UDP Load Balancing creates a private (RFC 1918) IP address for the cluster that receives traffic on the network within the same compute region. A Kubernetes Service with type: Loadbalancer and the cloud.google.com/load-balancer-type: Internal annotation creates an ILB that targets the Kubernetes Service. The number of such Services is limited by the number of internal forwarding rules that you can create in a VPC network. Maximum 75 of forwarding rules per network for: - Internal TCP/UDP Load Balancing - Internal HTTP(S) Load Balancing
In a GKE cluster, an internal forwarding rule points to all the nodes in the cluster. Each node in the cluster is a backend VM for the ILB. The maximum number of backend VMs for an ILB is 250, regardless of how the VMs are associated with instance groups. So the maximum number of nodes in a GKE cluster with an ILB is 250. If you have autoscaling enabled for your cluster, you must ensure that autoscaling does not scale your cluster beyond 250 nodes.
When you create an internal forwarding rule, you must choose one of the following port specifications: • Specify at least one and up to five ports, by number • Specify ALL to forward traffic on all ports Google Kubernetes Engine (GKE) doesn't support creating a Service of type LoadBalancer with an internal forwarding rule using all ports. However, you can manually create an internal TCP/UDP load balancer with an internal forwarding rule using all ports for your GKE nodes.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}