Share
MMVCというオープンソースのリアルタイムボイスチェンジャーと、そのエンジン部分であるVITSというディープラーニングを利用したTTS音声生成手法について、紹介と解説をしました。
NSEG + JAWS-UG 長野支部 合同勉強会 - connpass https://nseg.connpass.com/event/251366/
の勉強会で話した内容です。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
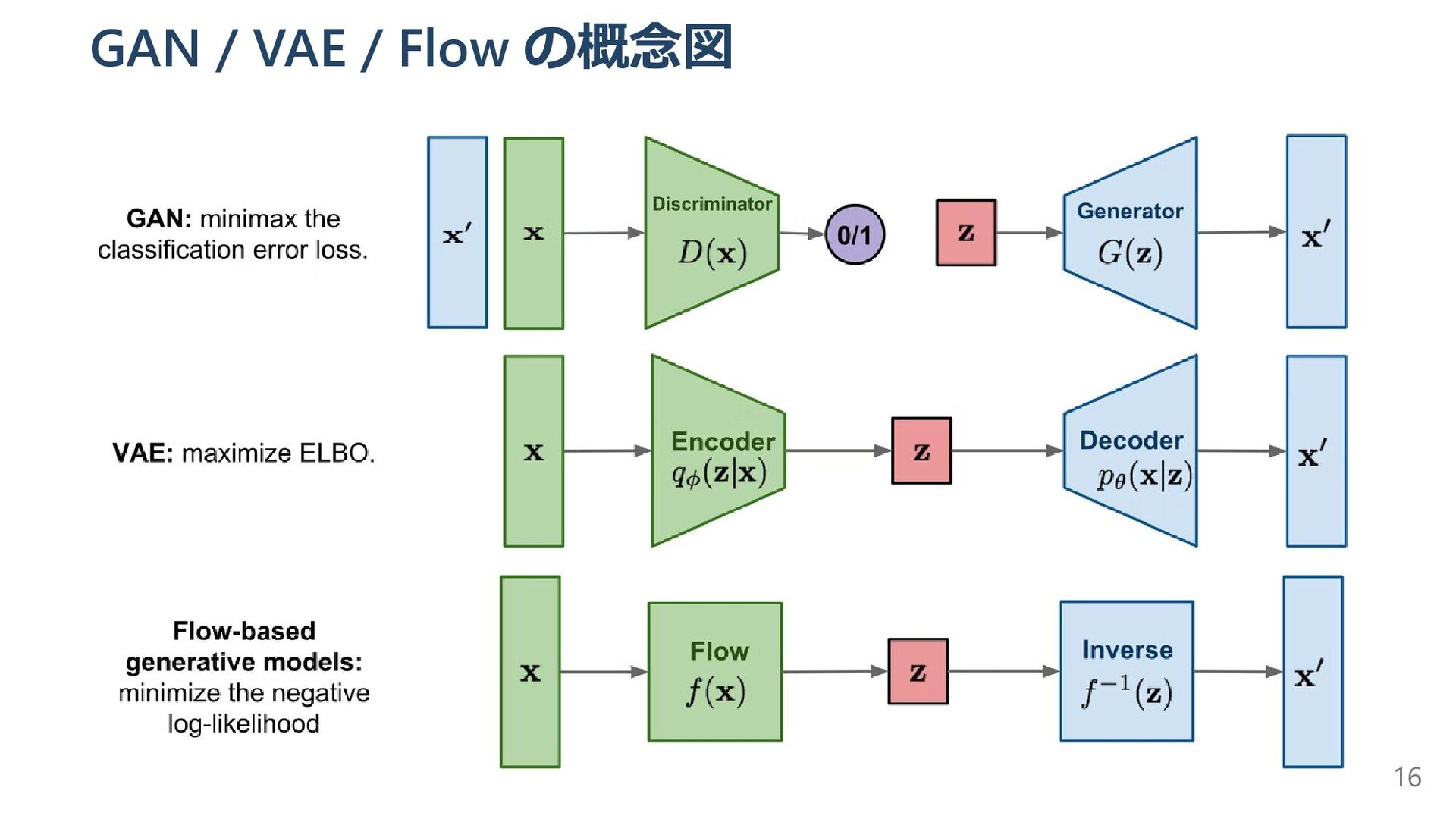{kind=link}
{kind=link}
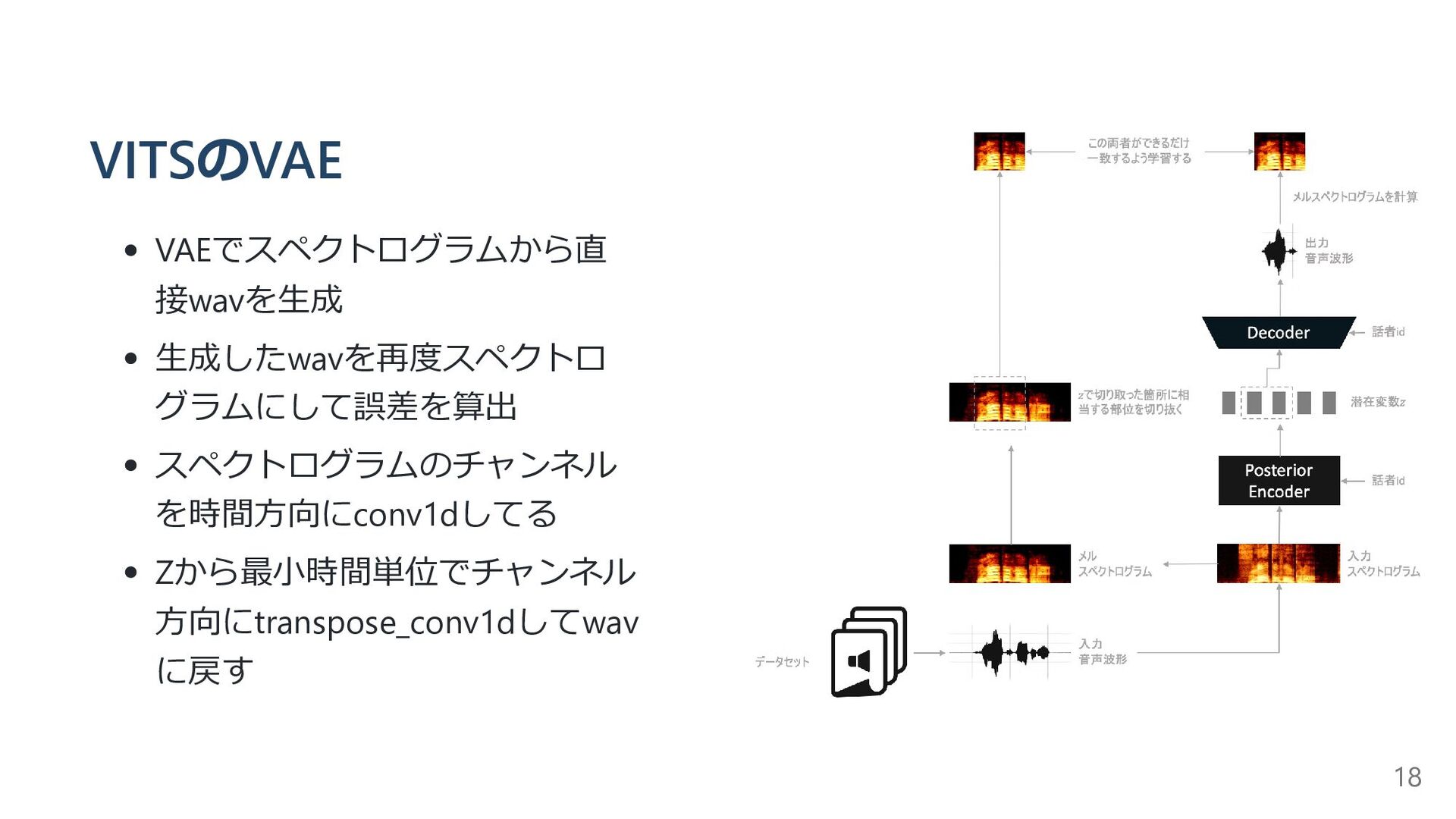{kind=link}
{kind=link}
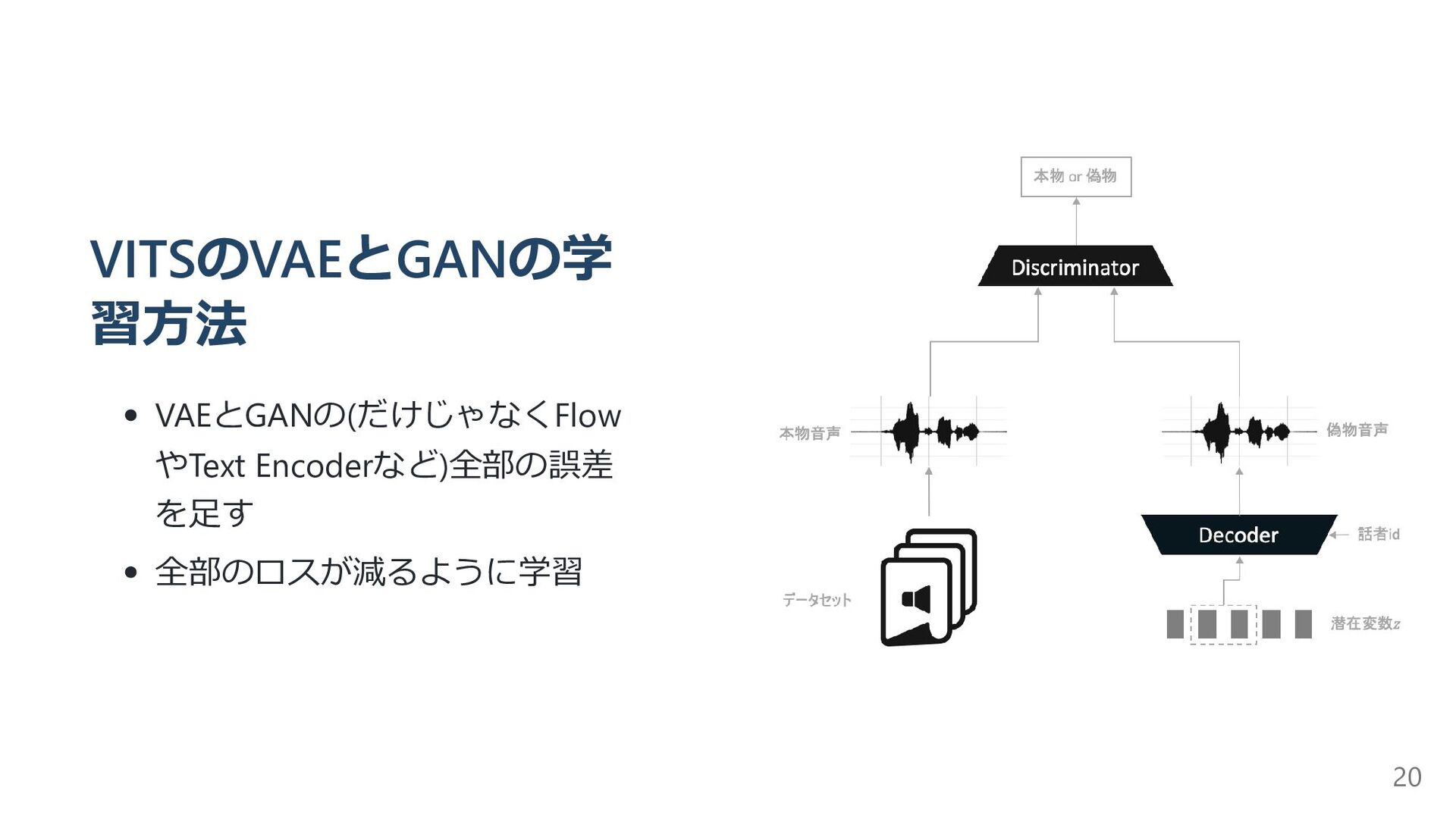{kind=link}
{kind=link}
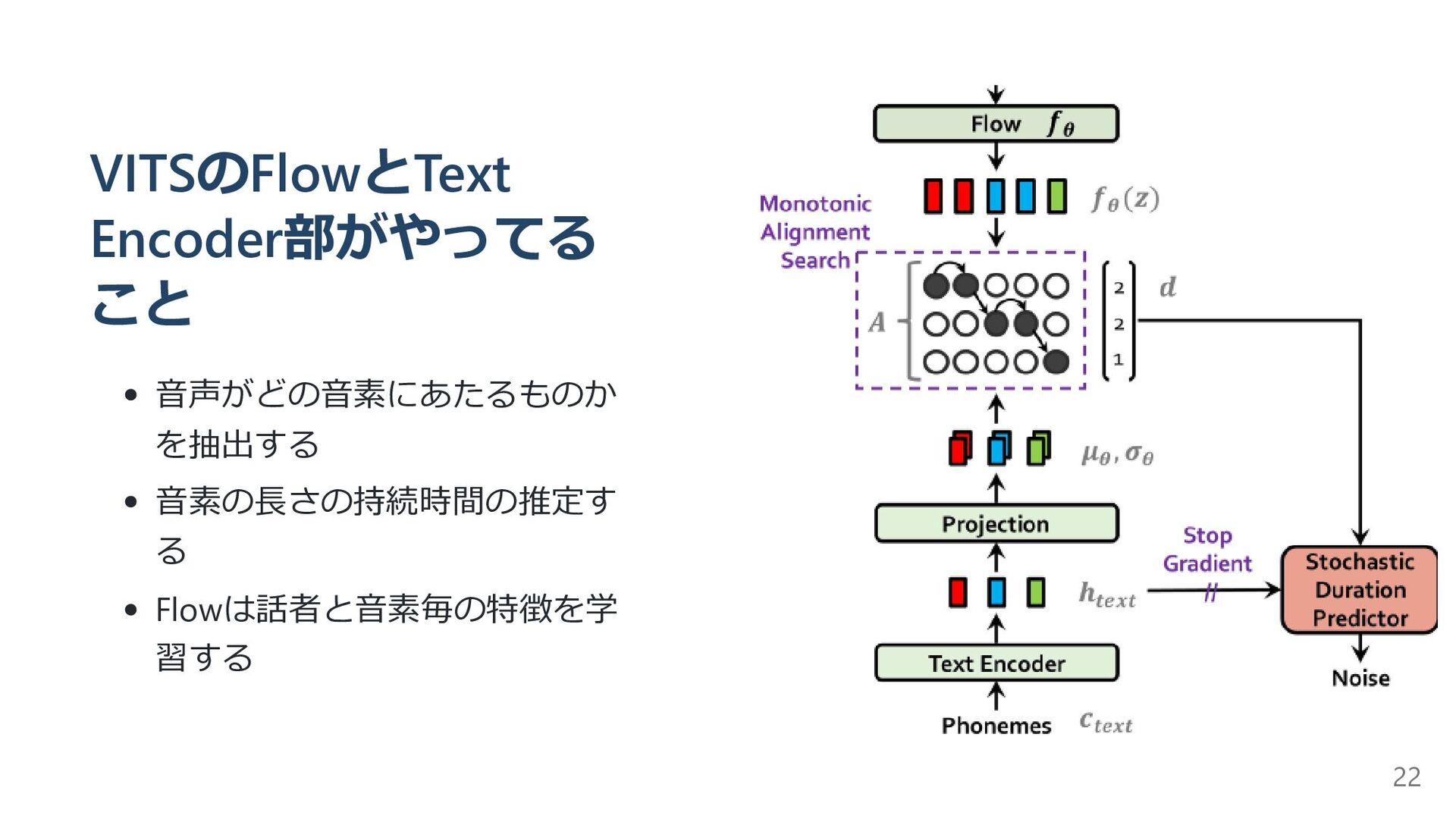{kind=link}
{kind=link}
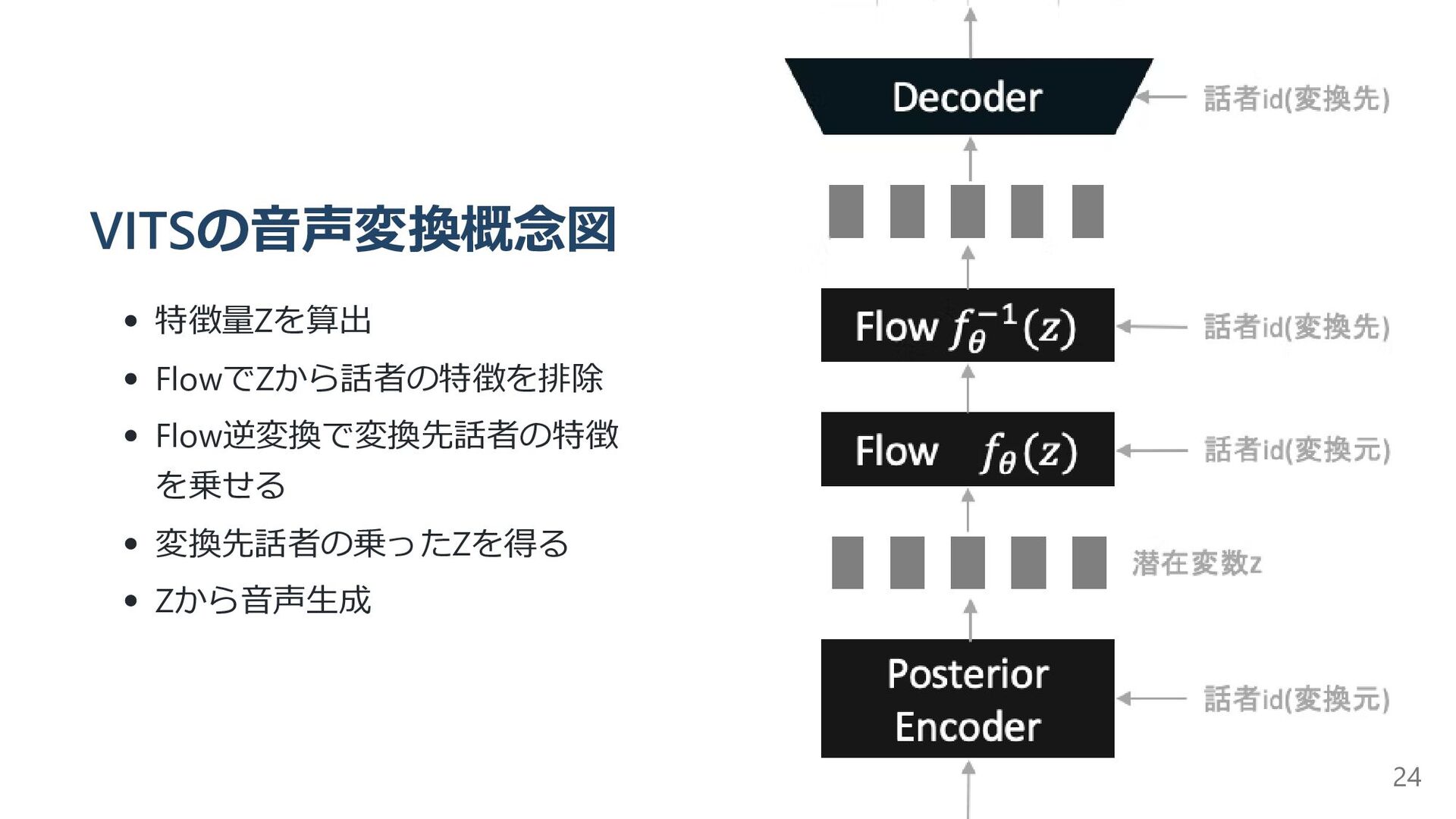{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}