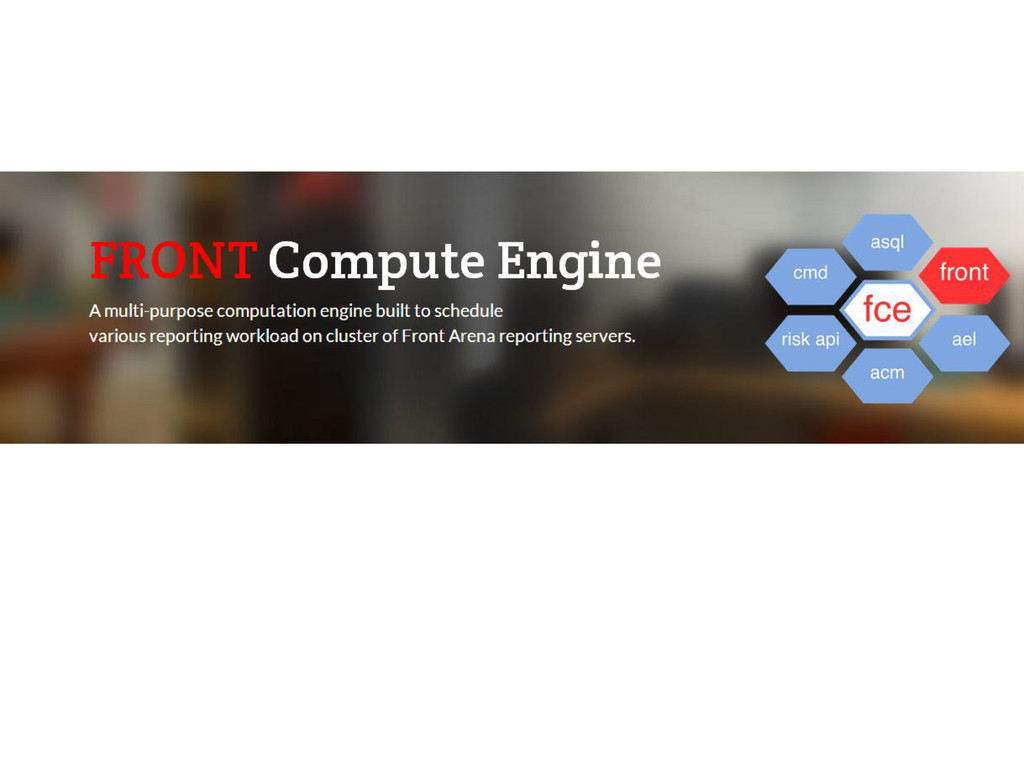
DBS ITT Lunch and Learn Tech Sharing August 2014
Topic: FRONT Compute Engine
Speaker: DBS ITT Front Arena Team
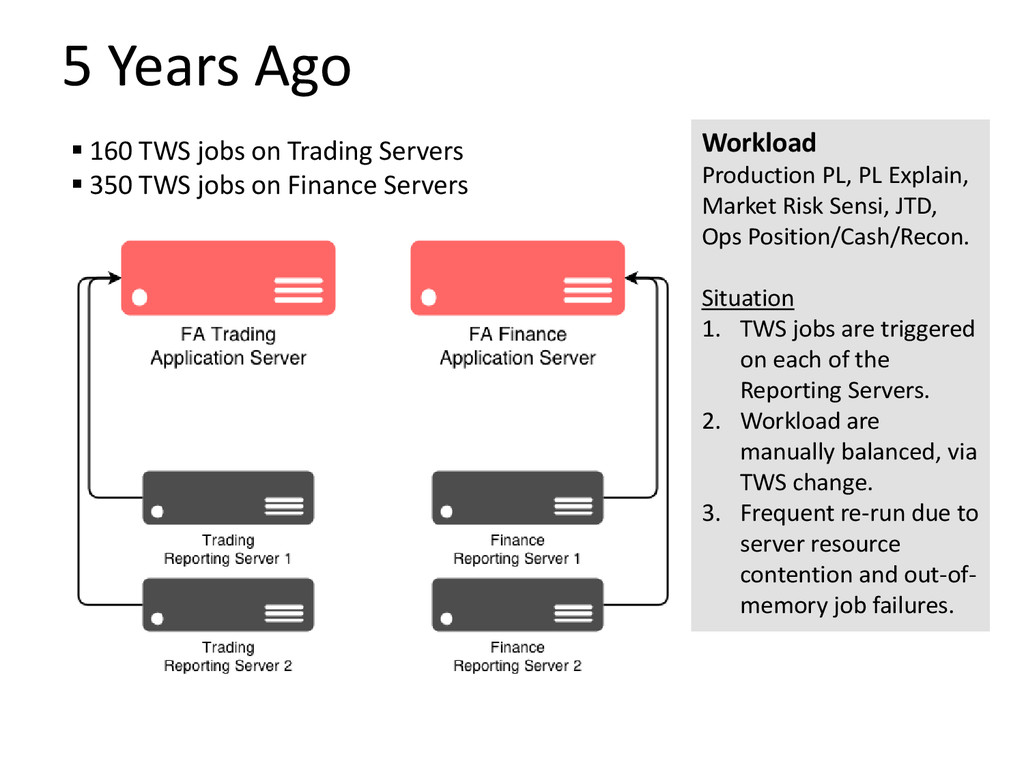
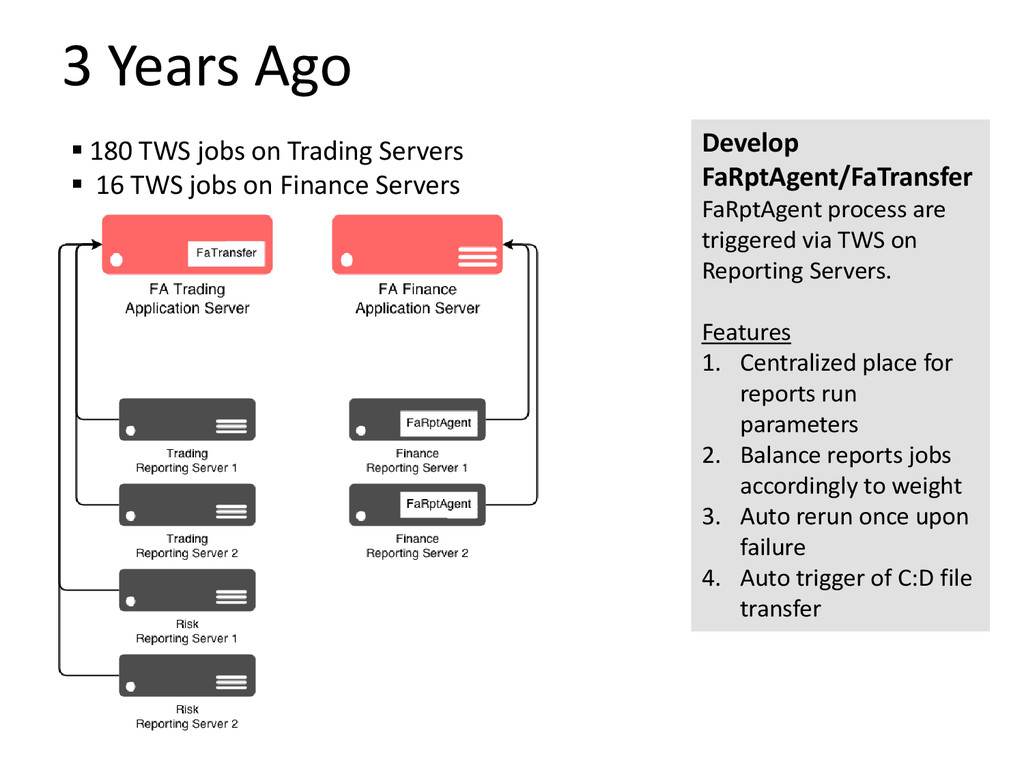
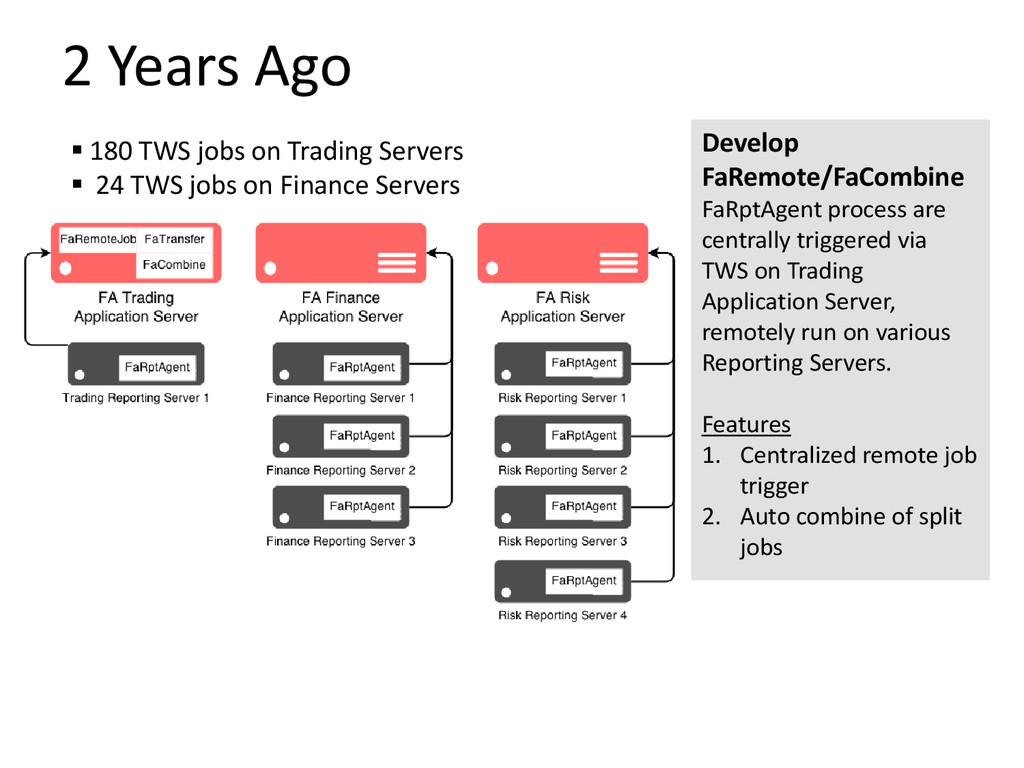
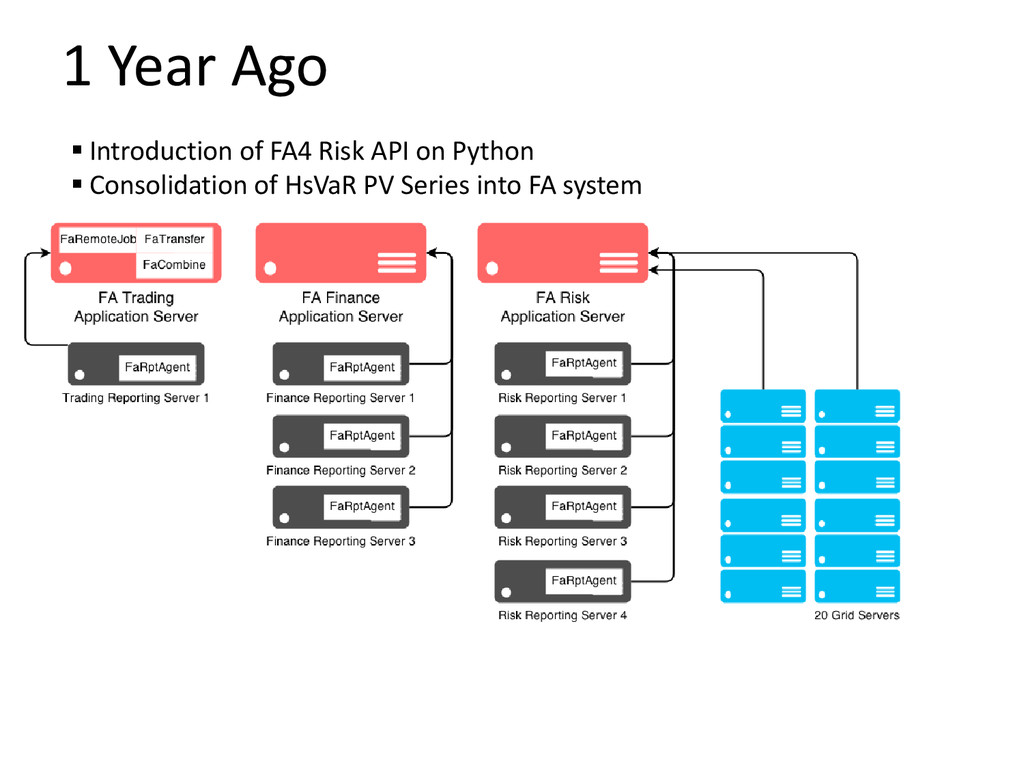
For Front Arena system, we have a constant challenge of balancing various workload across various server hardware in order to turnover all reporting demands before the next business day starts or feed into down-stream systems before a stipulated cut-off. And, the workload demand is always increasing: Production PL, PL Explain, PL Sensitivity, Historical VaR PV Series, JTD, intra-day runs, re-runs, more portfolio, more Sensi measures. How do we address this challenge with one solution?
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}