Die NoSQL Datenbank MongoDB bietet eine gute Grundlage für flexible und skalierbare Applikationen. Besonders die Skalierung des Backends beim Wachstum der eigenen Applikation kann mit MongoDB sehr einfach sein, wenn man das richtige Verteilungskriterium definiert. Im Rahmen dieses Vortrages wird die grundlegende Funktionsweise der Verteilung skizziert und den Zuhörern mögliche Lösungsansätze für die Skalierung ihrer Datenmengen gezeigt.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
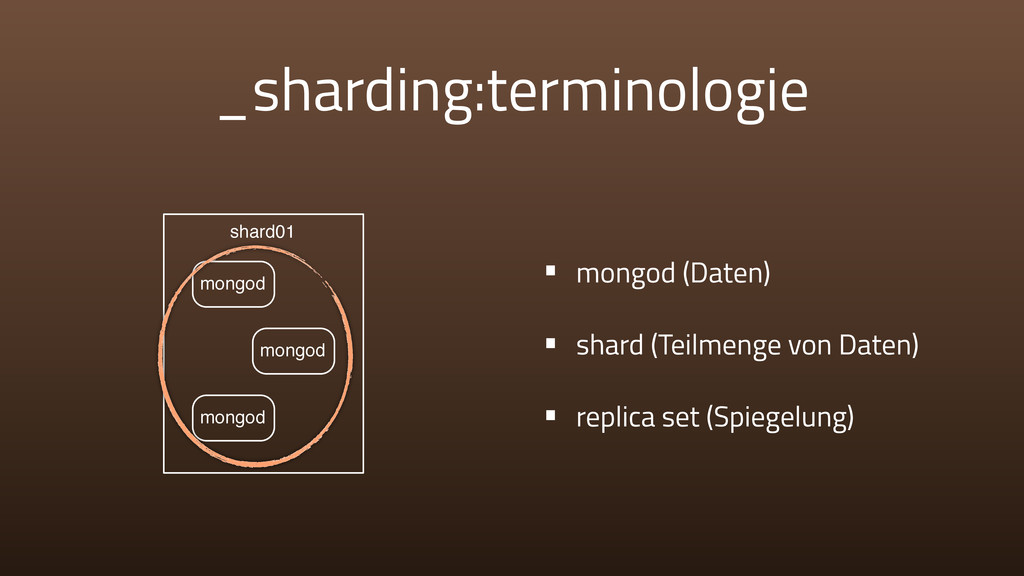{kind=link}
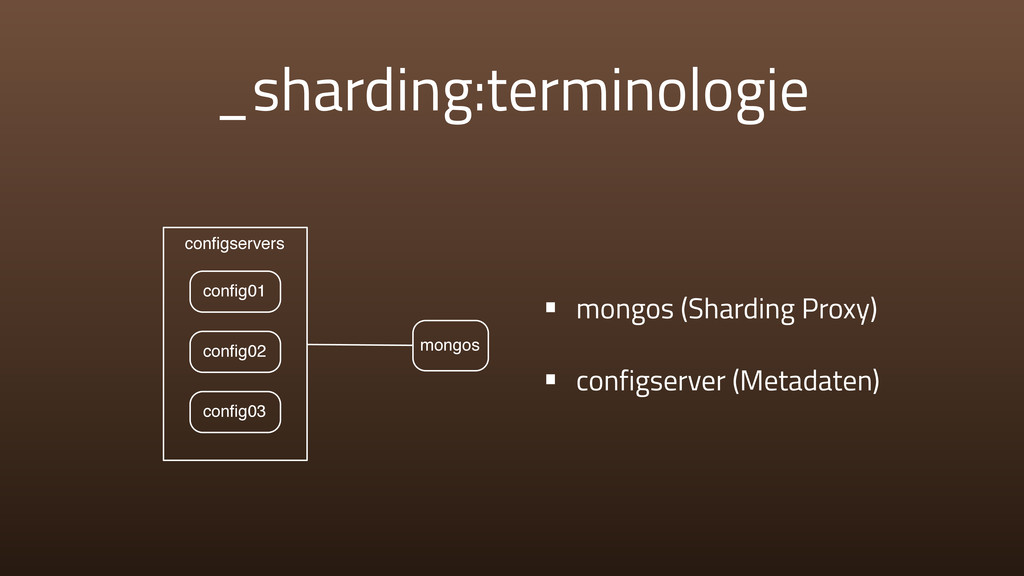{kind=link}
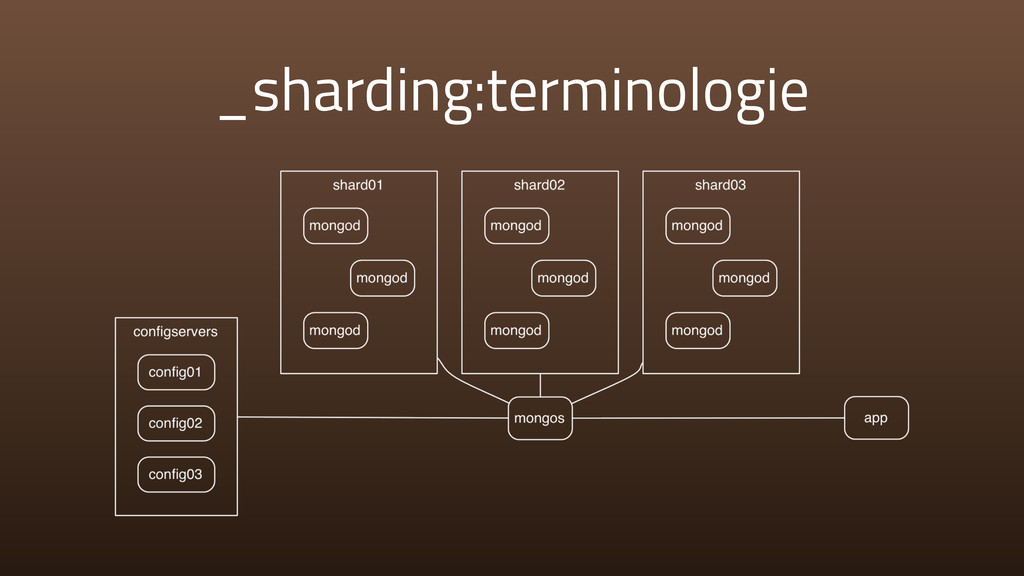{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
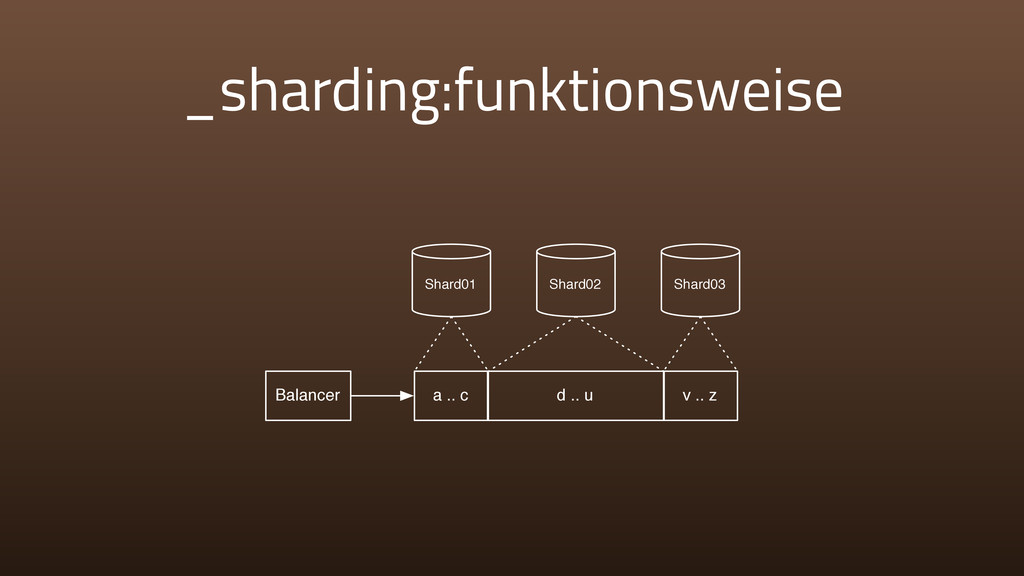{kind=link}
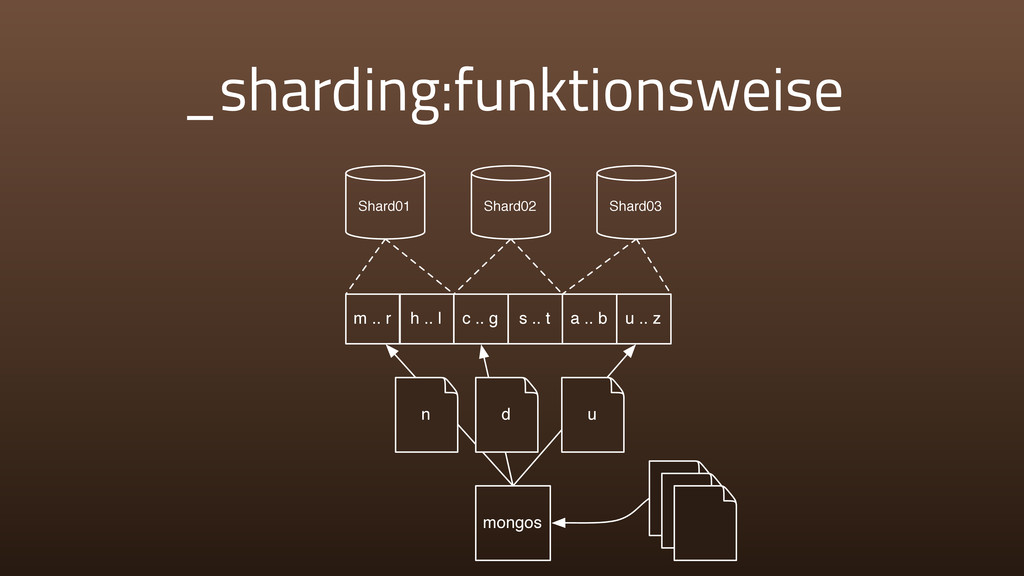{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
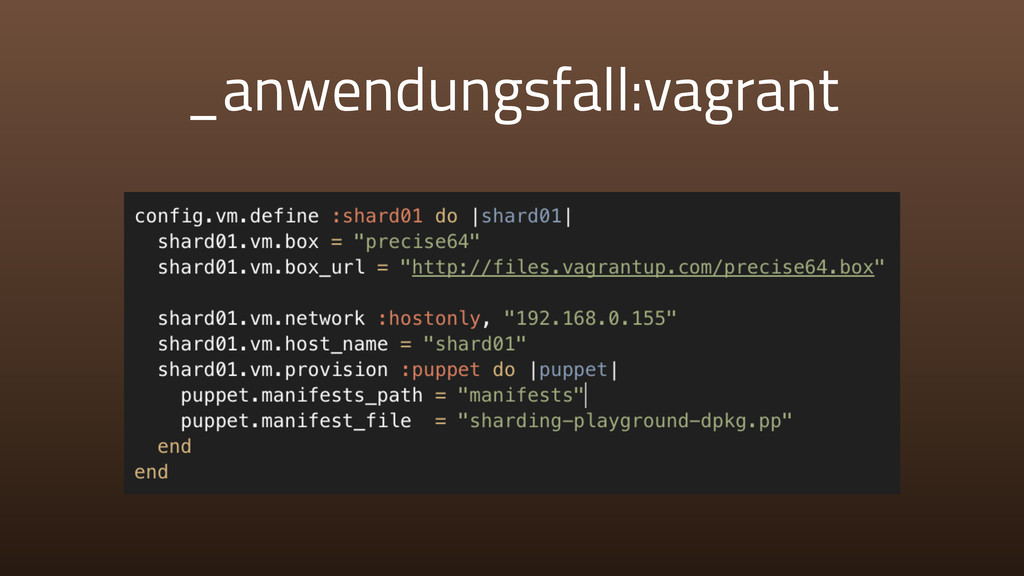{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
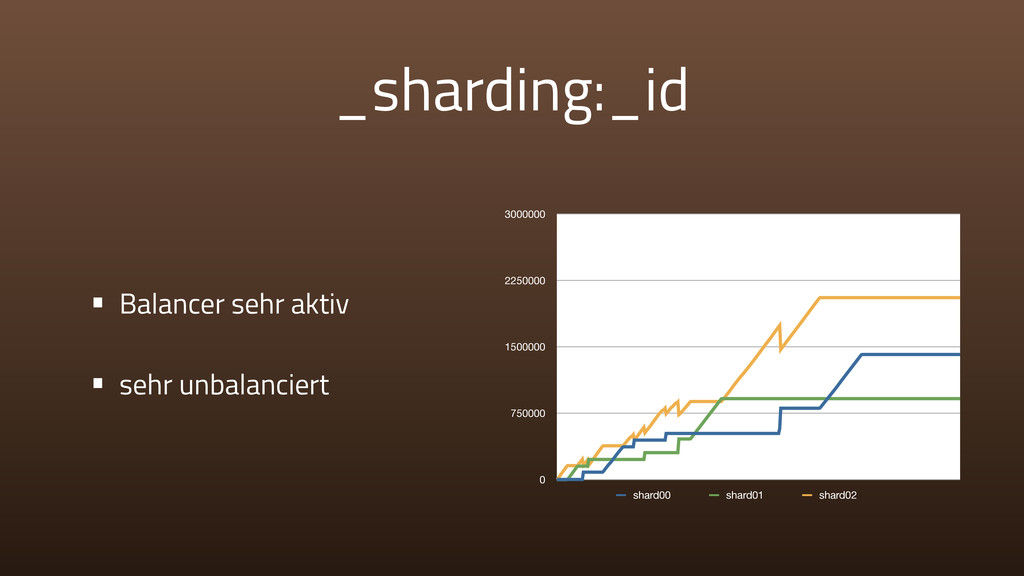{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}