// 64-bit int v1 = hash(“foo”); int v2 = hash(“goo”); int hash(byte[] value) { // a simple hash int h = 0; for (byte b: value) { h = (h<<5) ^ (h>>27) ^ b; } return h % PRIME; }
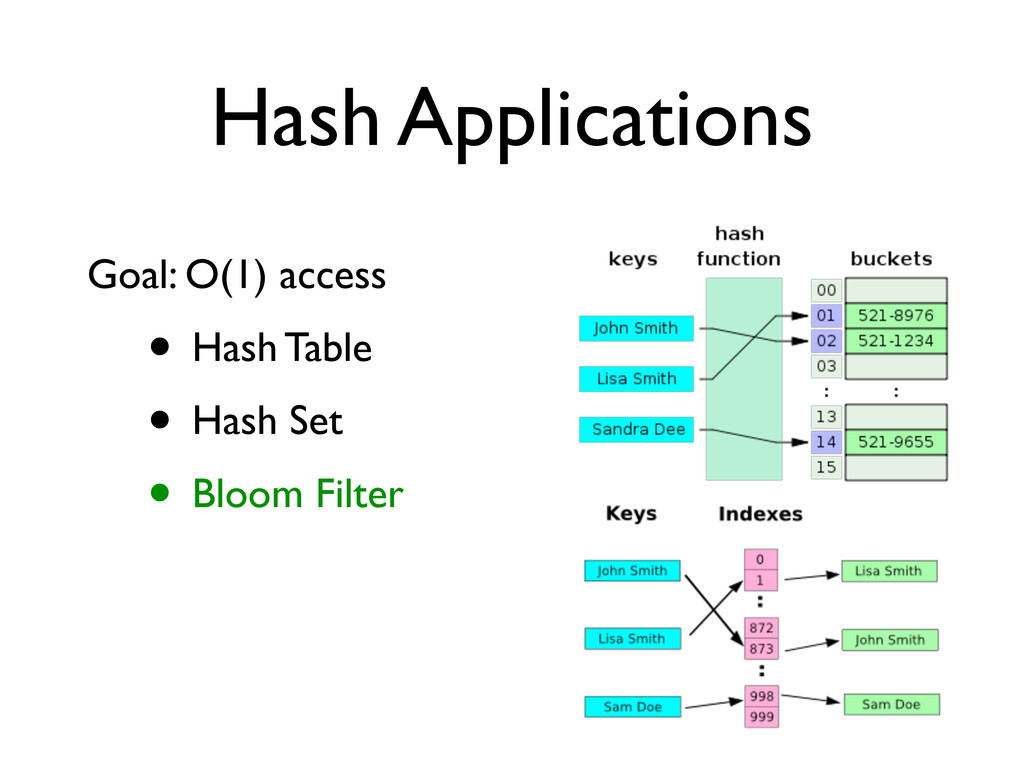
• Allocate array of size K * N bytes • Utilize array storage as: • a heap or tree: O(lg N) insert/delete/ remove • a hash: O(1) insert/delete/remove • What if we don’t have room for K*N bytes?
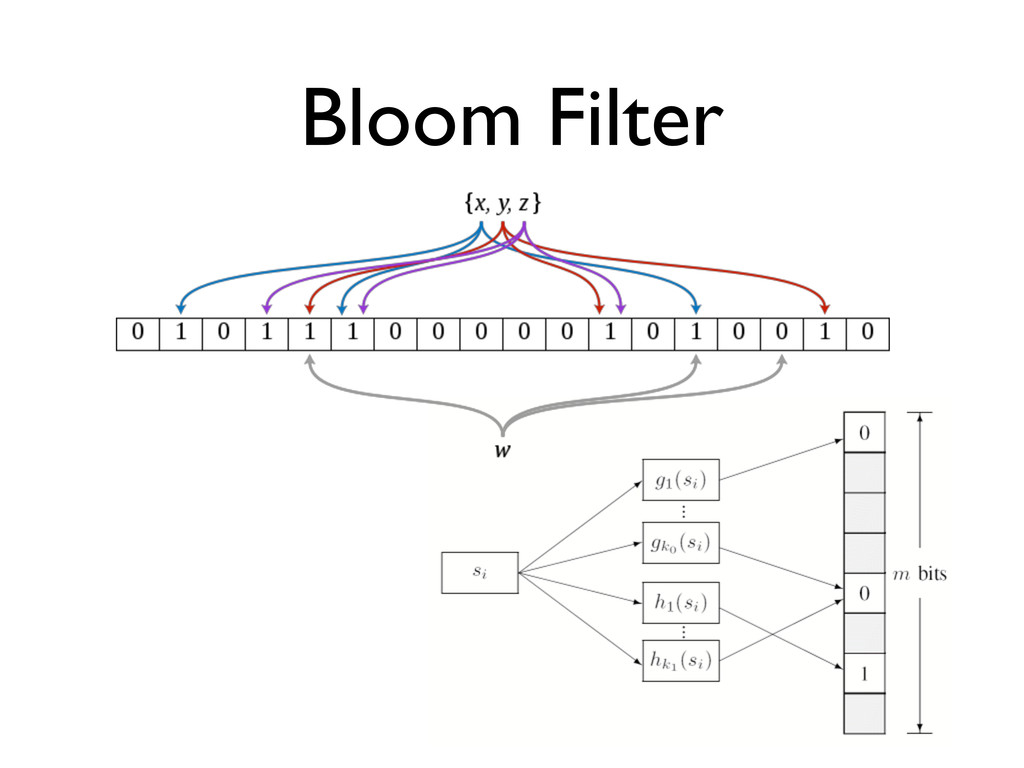
the keys • Store r bits per key instead of K bytes • Allocate bit vector of size: M = r * N, where N is expected number of entries • Use multiple hash functions of key to determine which bits to set • Premise: if hash functions are well- distributed, few collisions, high accuracy
keys (r: num bits/key) Let k = 0.7 * r (k: num hashes to use) Let p = 0.6185 ** r (p: probability of false positives) Working backwards, we can use desired false positive rate p to tune the data structure space consumption: r = 8, p = 2.1e-2 r = 16, p = 4.5e-4 r = 24, p = 9.8e-6 r = 32, p = 2.1e-7 r = 40, p = 4.5e-9 r = 48, p = 9.6e-11
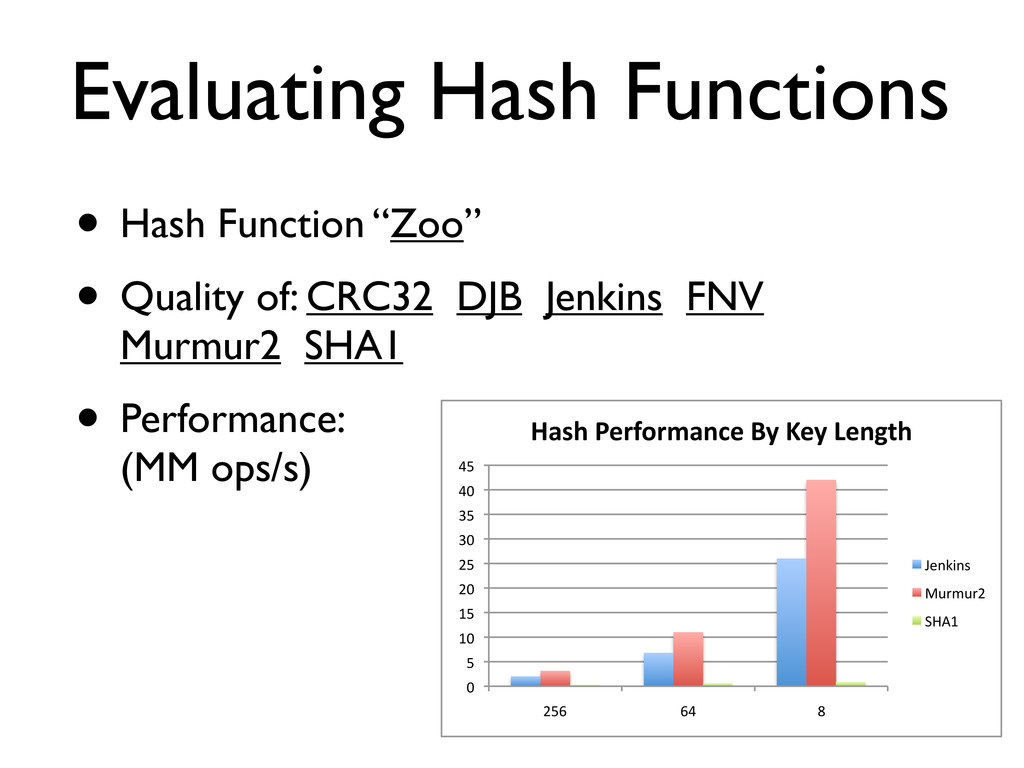
entries, 32bits/key : 256k ops/s 1BN entries, 8bits/key : 714k ops/s 1BN entries, 32bits/key : 185k ops/s Hypothesis : difference between 100MM and 1BN is due to locality of memory access in smaller bit vector
db “CDB” • Plain ol’ Key/Value storage: add(byte[] k, byte[] v), byte[] lookup(byte[] k) • Constant aka “Immutable” Data Store create(), add(k, v) ... , build() ... before lookup(k) • Use properties of hash table to achieve O(1) disk seeks per lookup
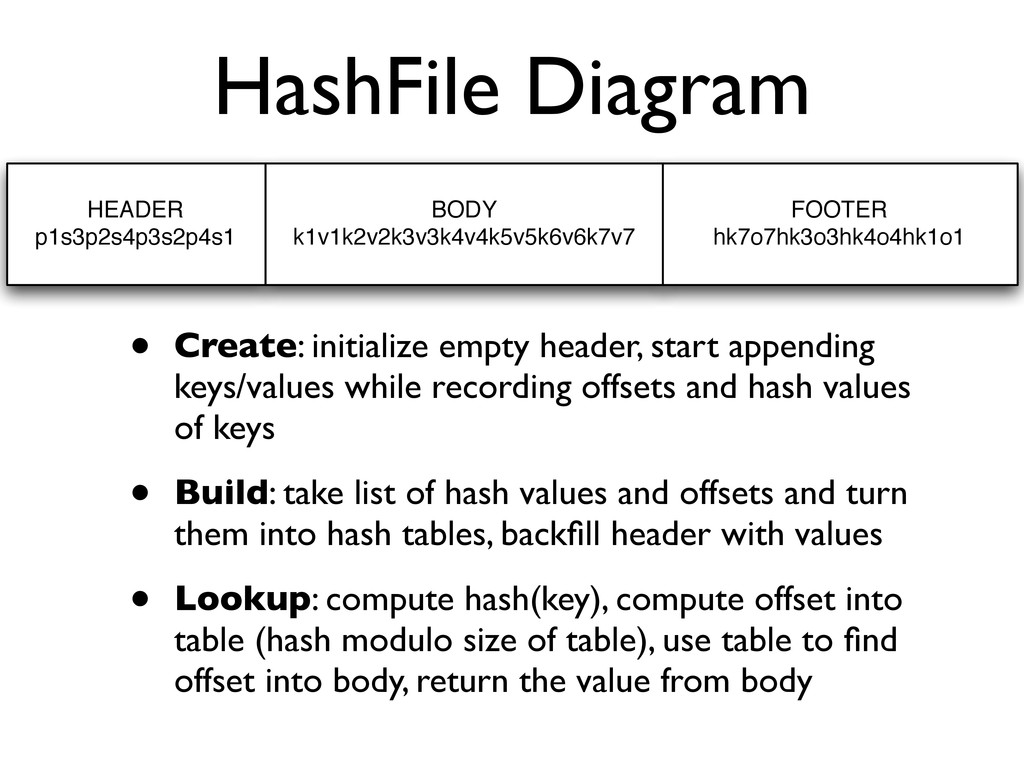
of hash tables and count of elements per table • Body (variable width): contains concatenation of all keys and values (with data lengths) • Footer (fixed width): hash “tables” containing long hash values of keys alongside long offsets into body
while recording offsets and hash values of keys • Build: take list of hash values and offsets and turn them into hash tables, backfill header with values • Lookup: compute hash(key), compute offset into table (hash modulo size of table), use table to find offset into body, return the value from body HEADER p1s3p2s4p3s2p4s1 BODY k1v1k2v2k3v3k4v4k5v5k6v6k7v7 FOOTER hk7o7hk3o3hk4o4hk1o1
• Number of seeks independent of number of entries • X25E SSD: 1BN 8-byte keys, values (41GB): 650μs lookup w/ cold cache, up to 700x faster as filesystem cache warms, 0.9μs when in-memory • With 100MM entries (4GB), cold cache is ~600μs (from locality), 0.6μs warm
collision / performance tradeoffs • Bloom Filters are extremely useful for fast, large-scale set membership • HashFile provides excellent performance in cases where a static K/V store suffices
HashFile with configurable hash, pointer, and key/value lengths to conserve space (reduce 24 bytes-per-KV overhead) • Implement a read-write (non-constant) version of HashFile • Bloom Filter that spills to SSD
{kind=link}
{kind=link}
![Hash Functions int getIntHash(byte[] data); // 32-bit long getLongHash(byte[] data)](https://files.speakerdeck.com/presentations/65962a408f2a013006c41231381a7469/slide_2.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}