These days, it seems like all the "cool kids" are using trendy NoSQL solutions for data storage. Unfortunately, many of these solutions come with relaxed transaction, durability and recovery guarantees. In this presentation, we provide tips for using MySQL efficiently to provide SQL functionality and reliability with NoSQL design and performance. We begin by reviewing a flexible key-value schema design, including optimization techniques such as schema extraction and row-level data compression using binary JSON and LZF, efficient versioning, and data access techniques to avoid the perils of UUID-randomized table access. Since Key-Value storage is seldom enough for real-world applications, we also take a look at optimization techniques for range queries and secondary indexes, materialized aggregations (think: counters and drill-downs) and full-text integration.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
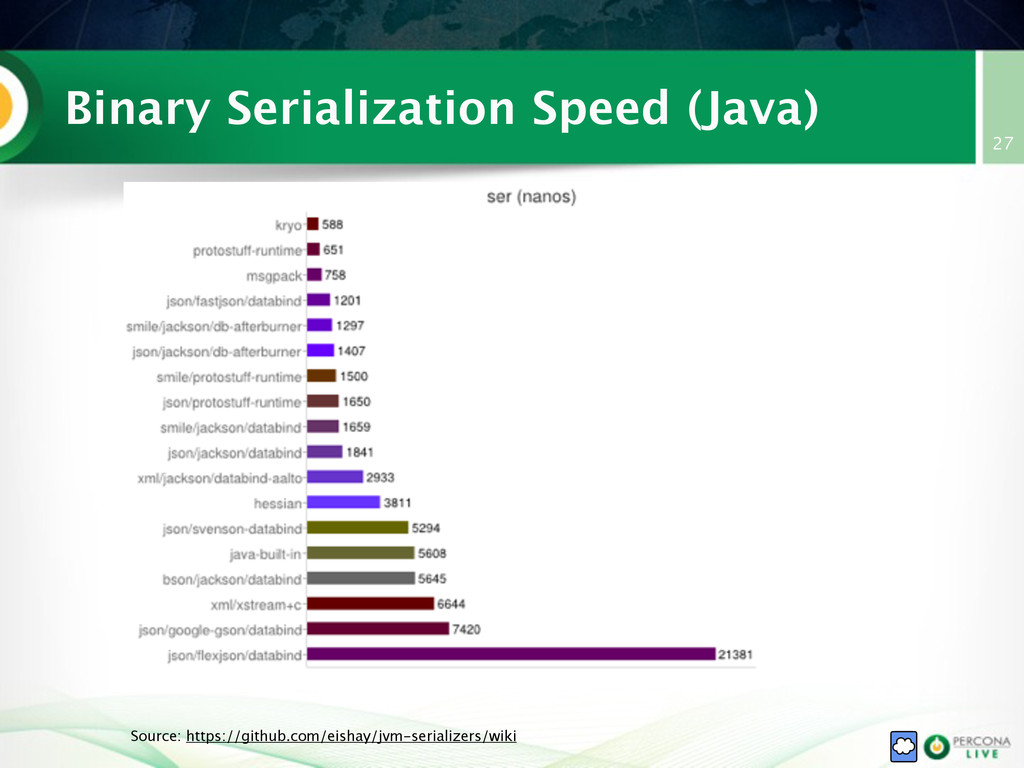{kind=link}
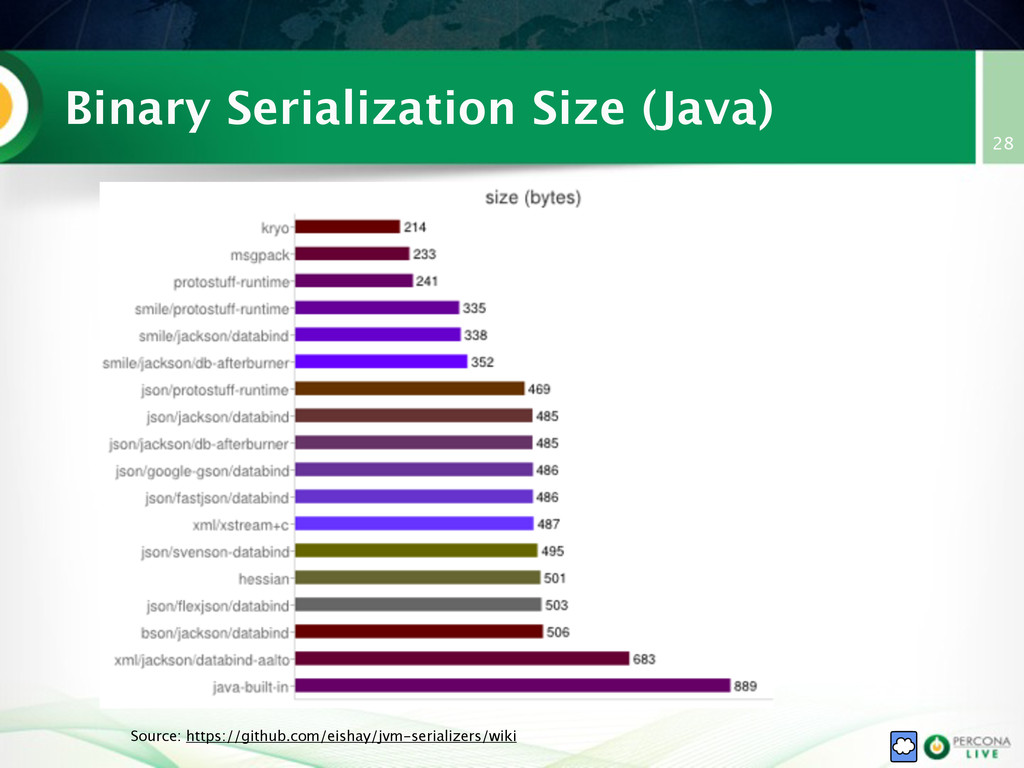{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
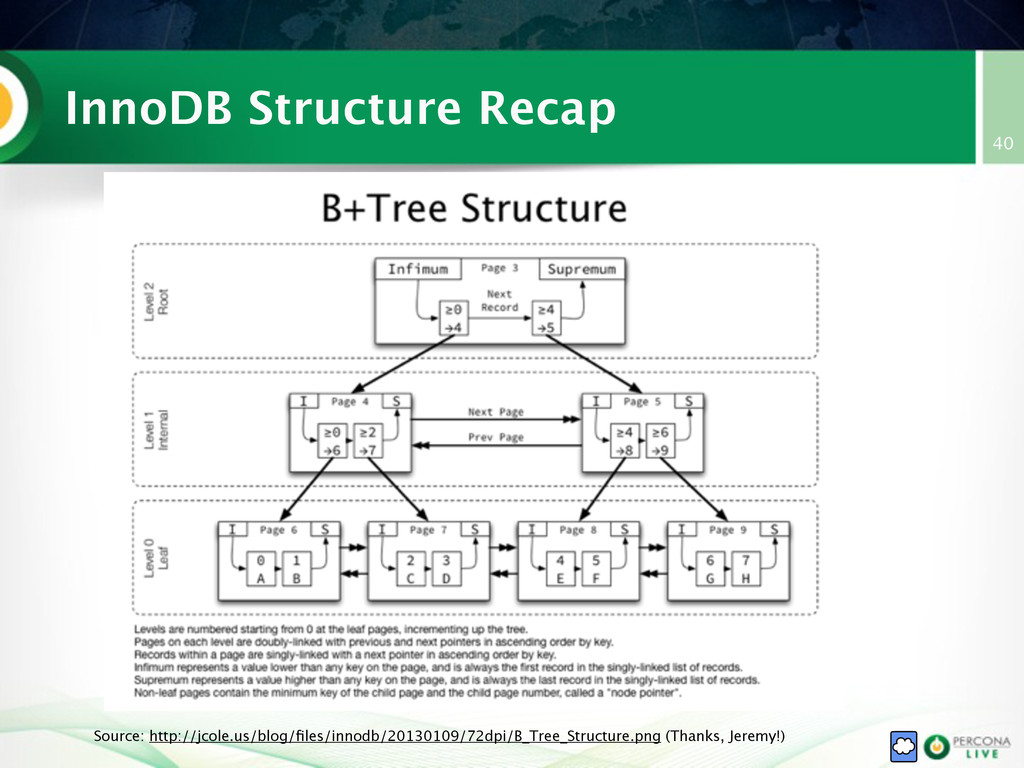{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Range-Based Secondary Indexes • Logical Index Definition: [{“zip_code”:”asc”},{”car_make”:”asc”}, {“_key_id”:”asc”}] CREATE](https://files.speakerdeck.com/presentations/16bb45408f250130434422000a8f8be6/slide_56.jpg){kind=link}
![Materialized Aggregations 58 • Logical Counter Definition: [{“zip_code”:”asc”},{”car_make”:”asc”}] CREATE TABLE](https://files.speakerdeck.com/presentations/16bb45408f250130434422000a8f8be6/slide_57.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}