Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Mobile, AI and TensorFlow
Search
Sponsored
·
Ship Features Fearlessly
Turn features on and off without deploys. Used by thousands of Ruby developers.
→
Supriya Srivatsa
October 05, 2017
Technology
630
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Mobile, AI and TensorFlow
Supriya Srivatsa
October 05, 2017
More Decks by Supriya Srivatsa
See All by Supriya Srivatsa
Forgotten Histories
supriyasrivatsa
0
660
The Story of Villagers, Marbles and Oh, A Blockchain!
supriyasrivatsa
0
640
Going Multiplatform With Kotlin
supriyasrivatsa
0
740
GIDS18_SupriyaSrivatsa.pdf
supriyasrivatsa
0
610
Other Decks in Technology
See All in Technology
Control Planeで育てるBtoB SaaSの認証基盤 - SRE NEXT 2026
pokohide
1
2.1k
AIに「使われる」時代のSaaS戦略 〜既存WebAPIのMCPサーバー化における開発ノウハウ〜
ekispert_api
0
310
Claude Codeとハーネスについて考えてみる
oikon48
18
9.2k
証券システムを10年Scalaで作り続けるということ - 関数型まつり2026
krrrr38
3
830
最近評価が難しくなった
maroon8021
0
300
DMM.com 購入改善推進チーム におけるCodeRabbitを用いた レビューフロー改善の一例
ysknsid25
2
580
AWS Summit の片隅で、体育座りしながらコミュニティがにぎわう理由を考えた
k_adachi_01
2
370
Amazon EVS で VCF 9.0 / 9.1 のサポート開始まとめ
mtoyoda
0
290
AIと共生する開発者プラットフォーム:バクラクのモノレポ×マイクロサービス基盤
sakajunquality
2
3.2k
しぶいSRE: サーバから見えない障害にどう向き合うか。ラストワンマイルのデバッグ実践 / Shibui SRE
kanny
13
5.8k
Terraform共通モジュールをチーム横断で“変えられる”運用へ ― リリースと適用の分離
kekke_n
1
2.5k
Oracle Base Database Service 技術詳細
oracle4engineer
PRO
15
110k
Featured
See All Featured
Taking LLMs out of the black box: A practical guide to human-in-the-loop distillation
inesmontani
PRO
3
2.3k
Performance Is Good for Brains [We Love Speed 2024]
tammyeverts
12
1.7k
How to Grow Your eCommerce with AI & Automation
katarinadahlin
PRO
1
220
Breaking role norms: Why Content Design is so much more than writing copy - Taylor Woolridge
uxyall
0
340
Documentation Writing (for coders)
carmenintech
77
5.4k
Agile Leadership in an Agile Organization
kimpetersen
PRO
0
190
Making Projects Easy
brettharned
120
6.7k
How to Create Impact in a Changing Tech Landscape [PerfNow 2023]
tammyeverts
55
3.4k
The Art of Programming - Codeland 2020
erikaheidi
57
14k
How to build an LLM SEO readiness audit: a practical framework
nmsamuel
1
800
Helping Users Find Their Own Way: Creating Modern Search Experiences
danielanewman
31
3.2k
Darren the Foodie - Storyboard
khoart
PRO
3
3.4k
Transcript
Mobile, AI and Tensorflow Supriya Srivatsa
None
None
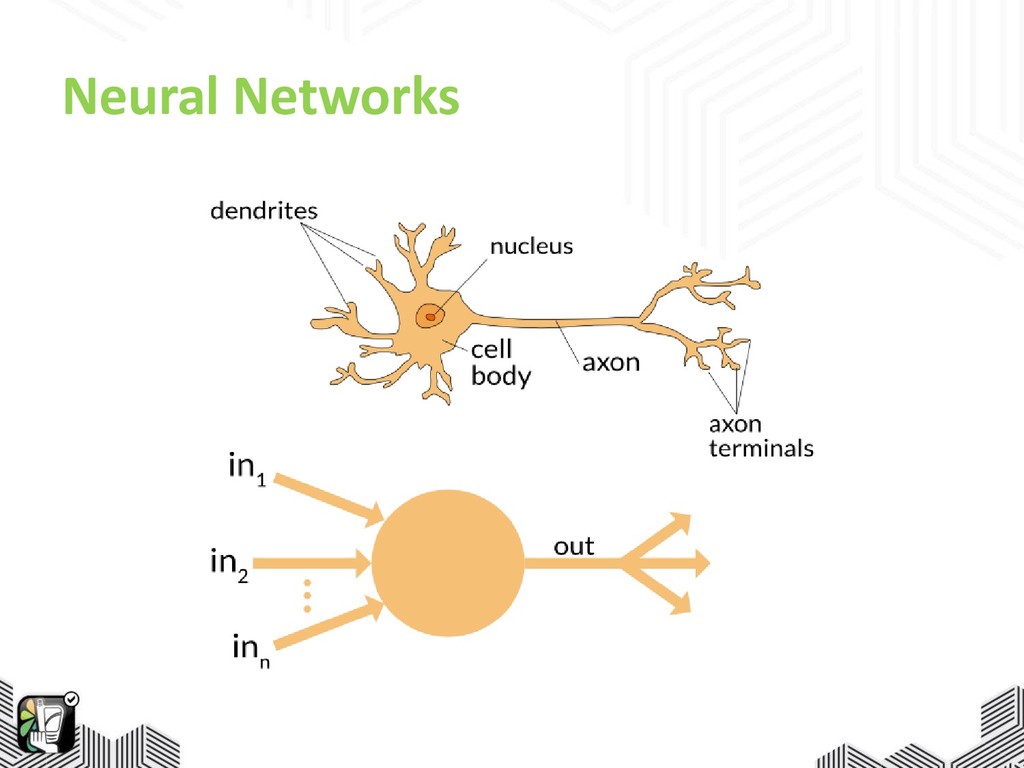
NEURAL NETWORKS Human anatomy inspired learning network.
Neural Networks
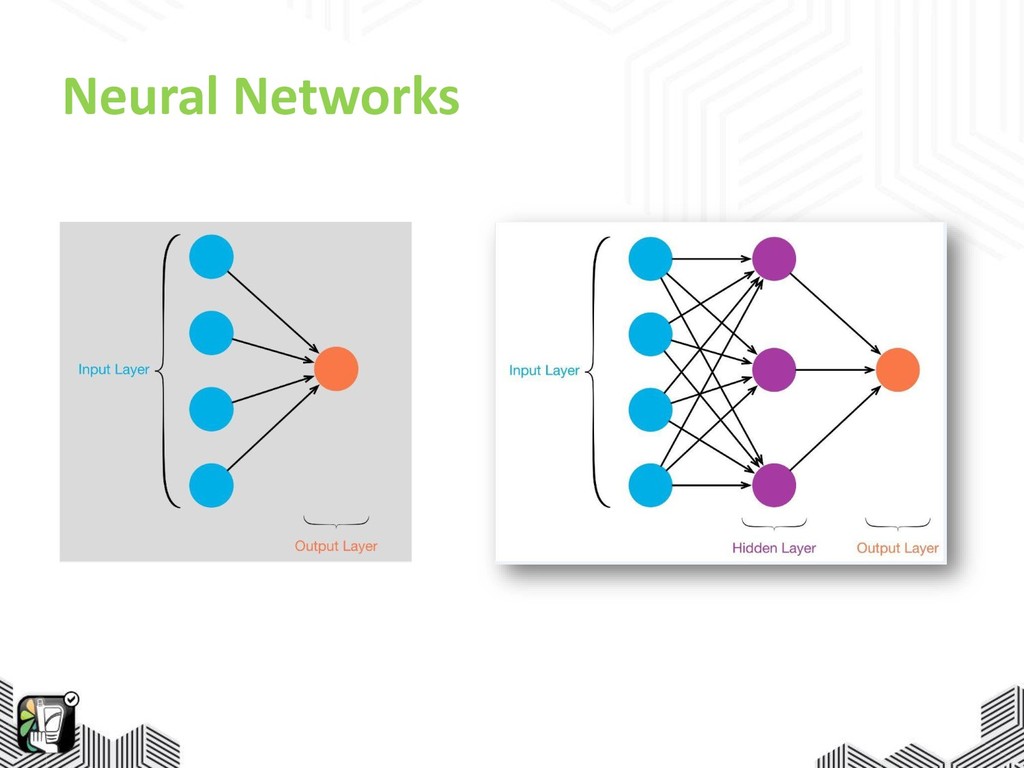
Neural Networks
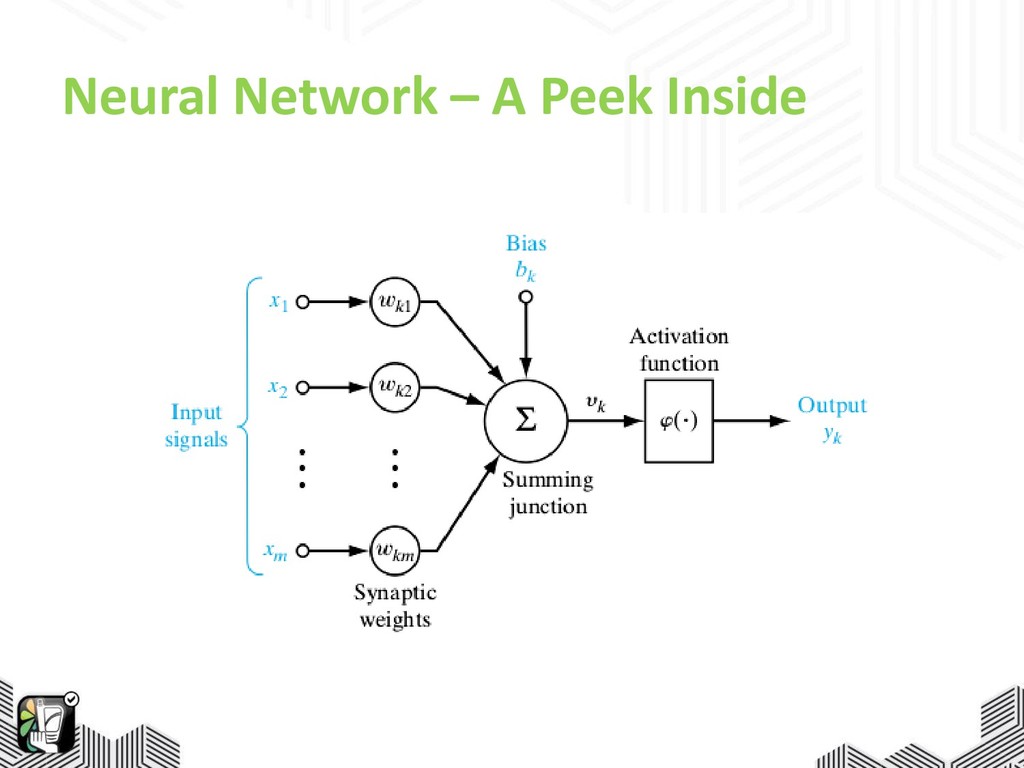
Neural Network – A Peek Inside
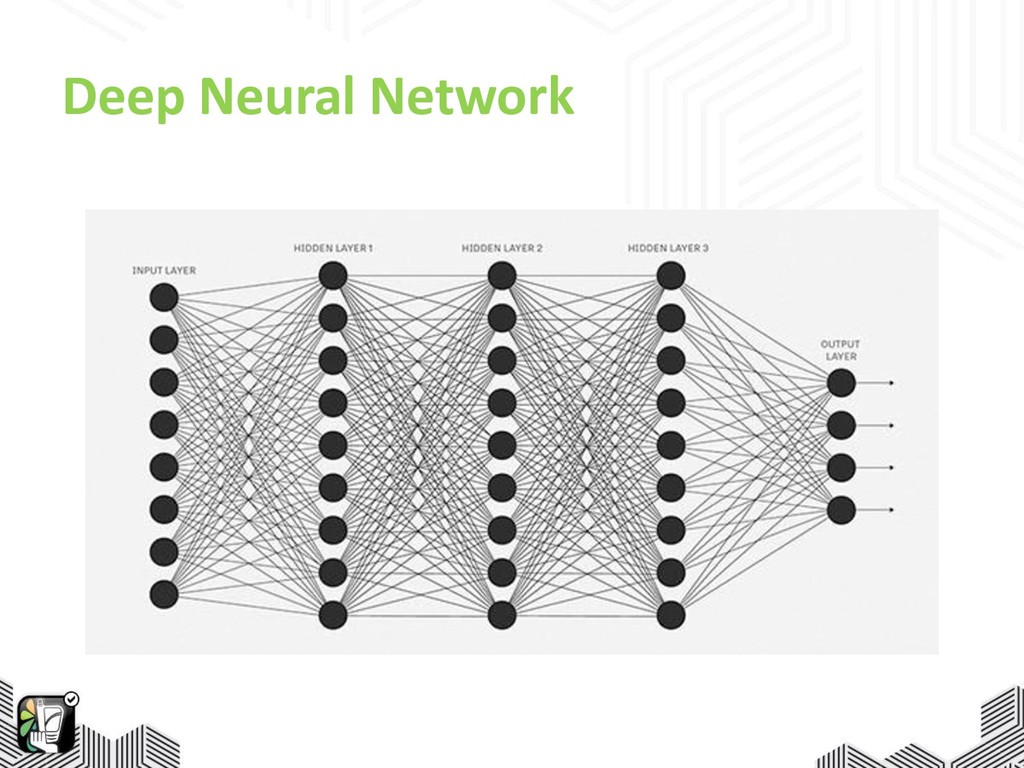
Deep Neural Network
PREDICTION AND INFERENCE How it works today. How it shall
work tomorrow.
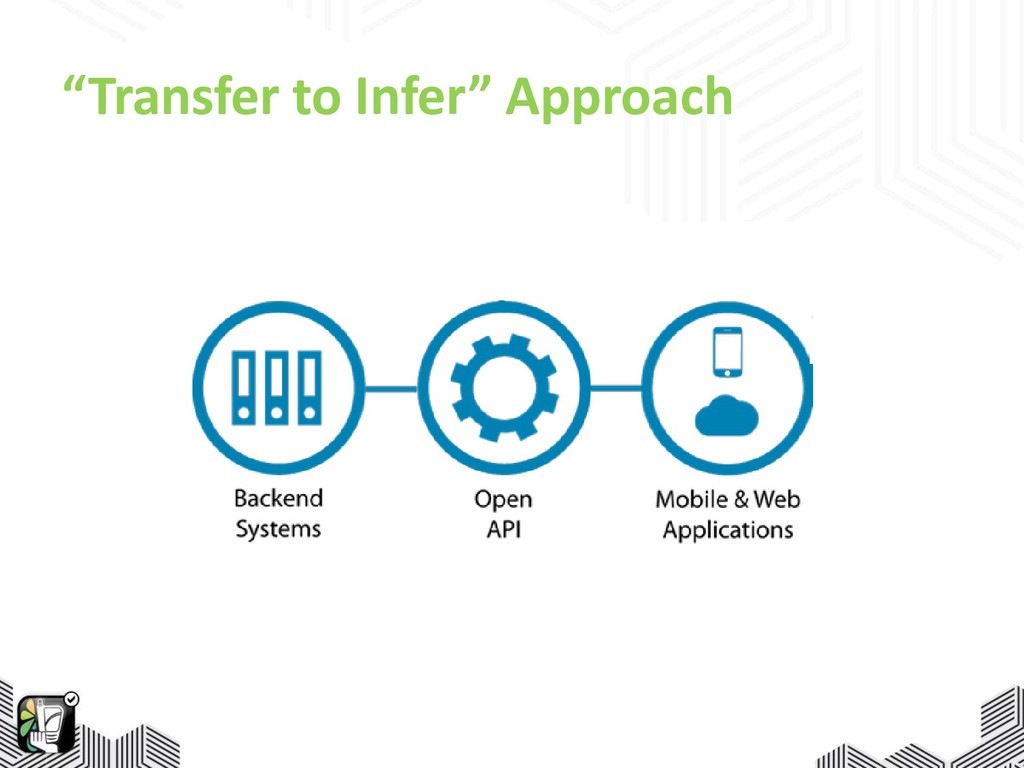
“Transfer to Infer” Approach
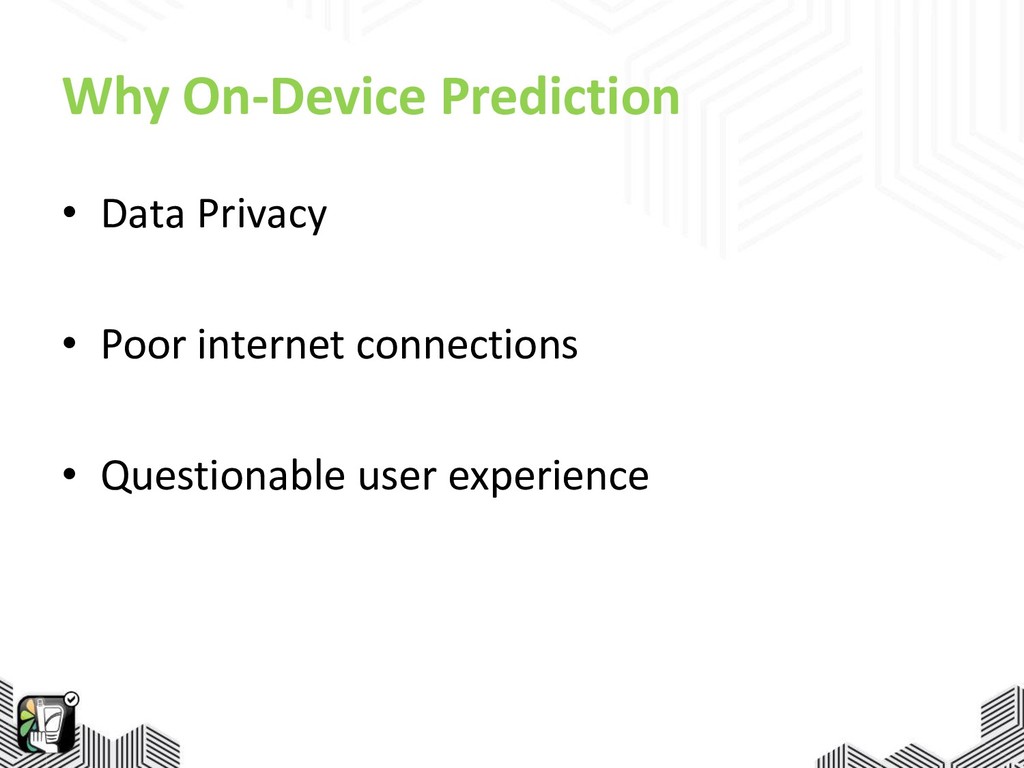
Why On-Device Prediction • Data Privacy • Poor internet connections
• Questionable user experience
To The Rescue…
TensorFlow • Tensor: N Dimensional Arrays • Open source software
library for numerical computation using data flow graphs.
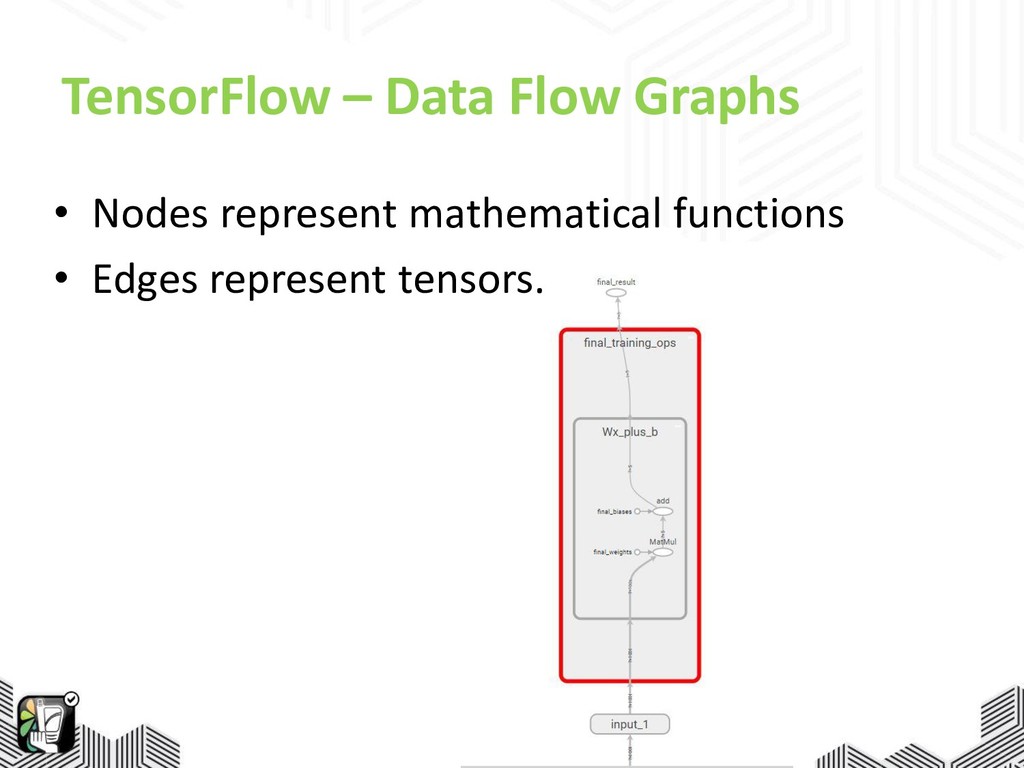
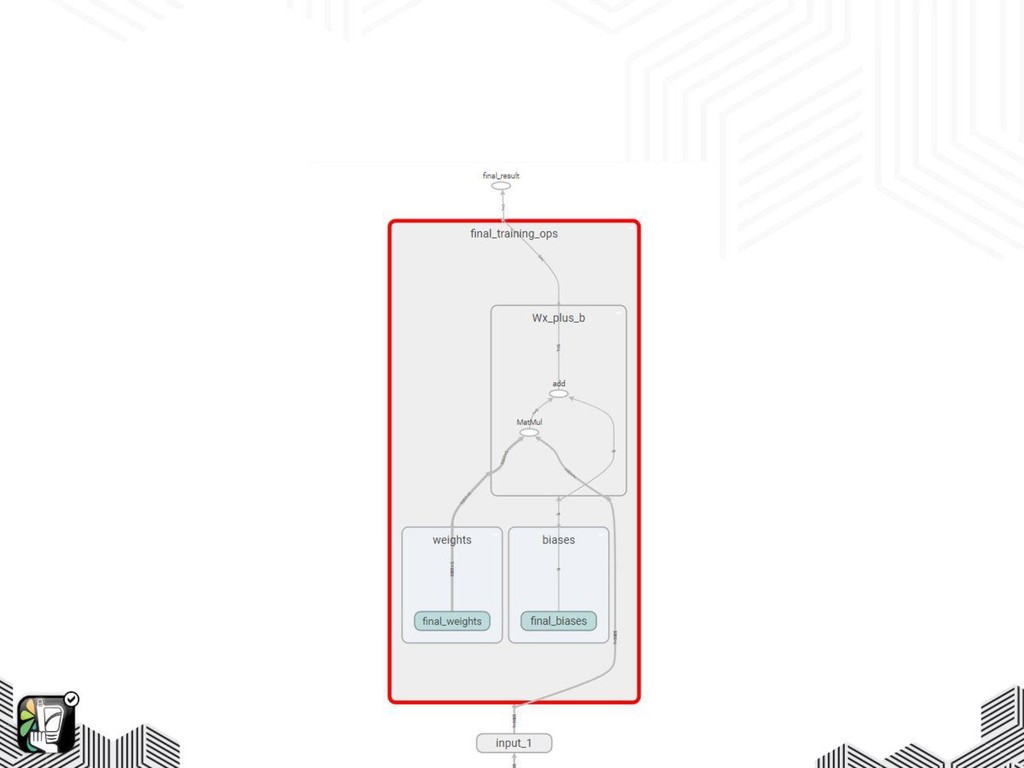
TensorFlow – Data Flow Graphs • Nodes represent mathematical functions
• Edges represent tensors.
Tensorflow – “Deferred Execution” Model • Graph first. Computation Afterward.
import tensorflow as tf x = tf.constant(10) y = tf.Variable(x + 5) print(y)
Tensorflow – “Deferred Execution” Model • Graph first. Computation Afterward.
import tensorflow as tf x = tf.constant(10) y = tf.Variable(x + 5) model = tf.global_variables_initializer() with tf.Session() as session: session.run(model) print(session.run(y))
None
None
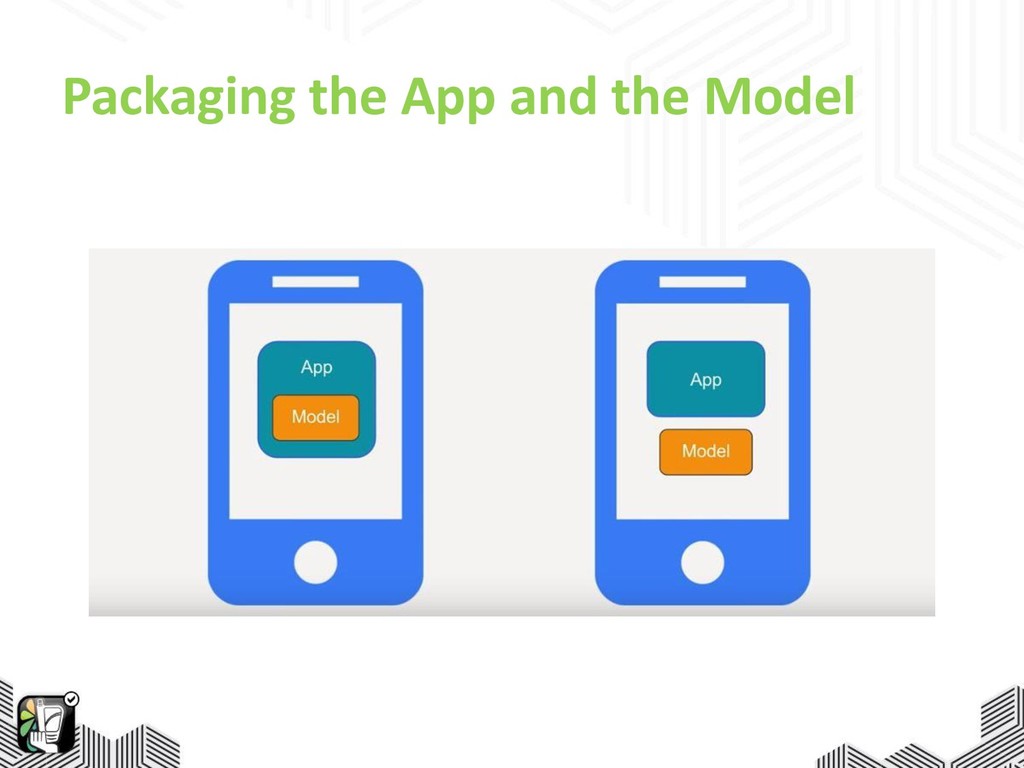
Packaging the App and the Model
QUANTIZATION Compress. And Compress More.
Quantization • Round it up • Transform: round_weights • Compression
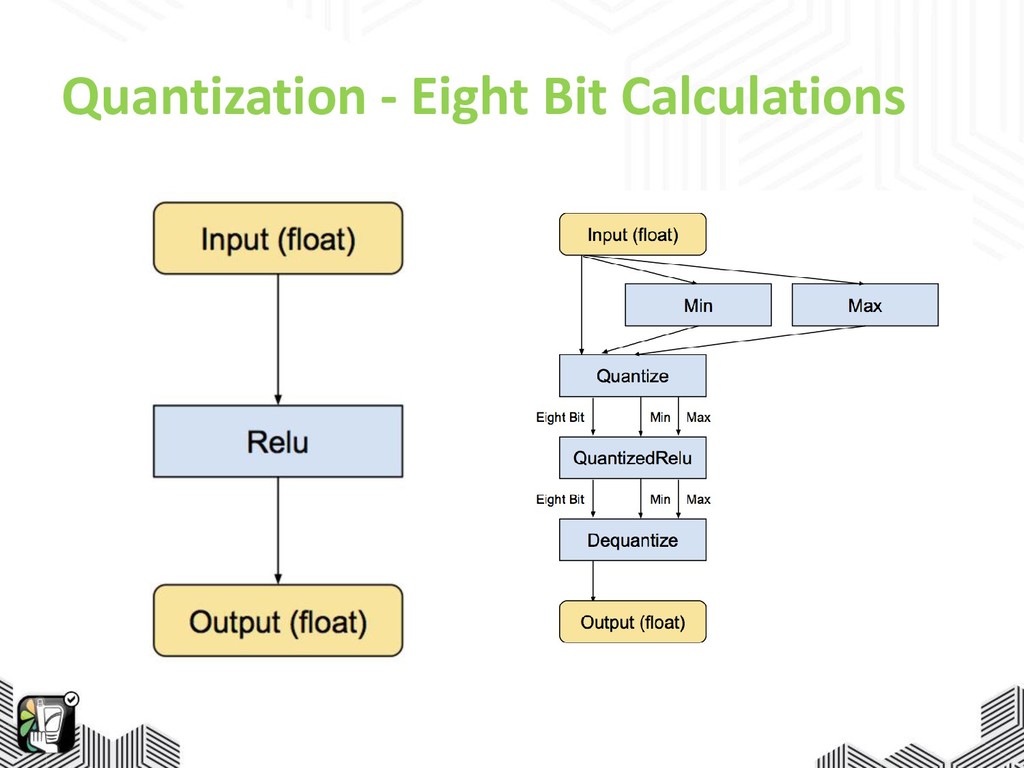
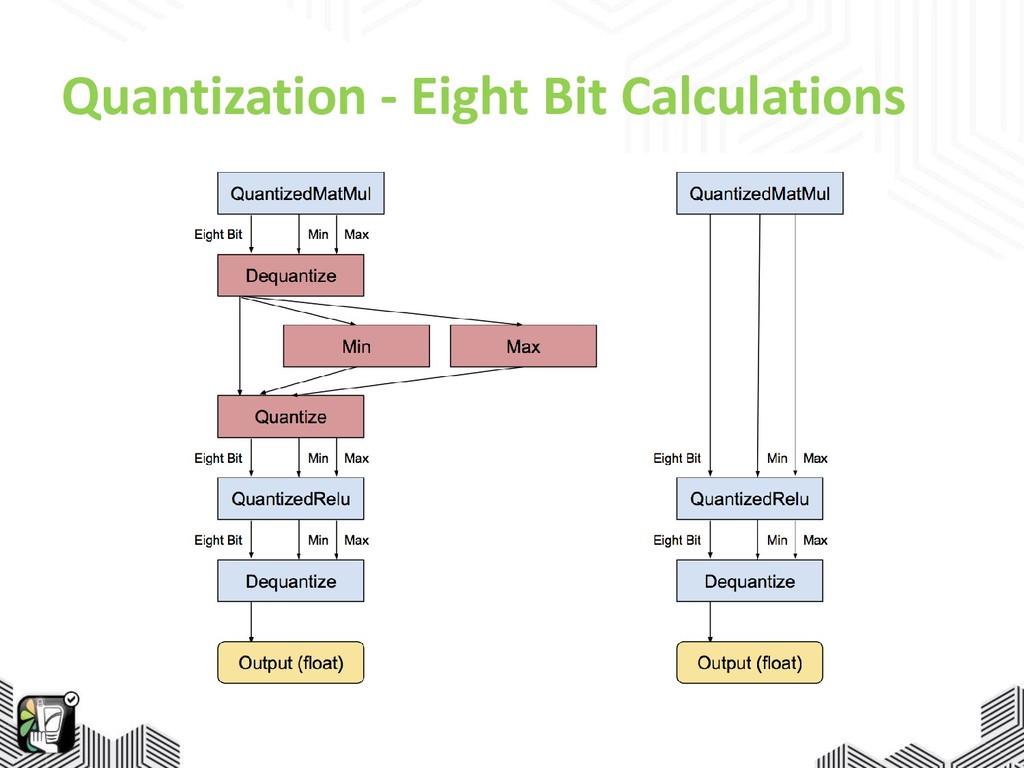
rates: ~8% => ~70% • Shrink down node names • Transform: obfuscate_names • Eight bit calculations
Quantization - Eight Bit Calculations
Quantization - Eight Bit Calculations
None
IMPLEMENTATION Code Away! ☺
Implementation build.gradle buildscript { repositories { jcenter() } dependencies {
classpath 'com.android.tools.build:gradle:2.3.0' } }
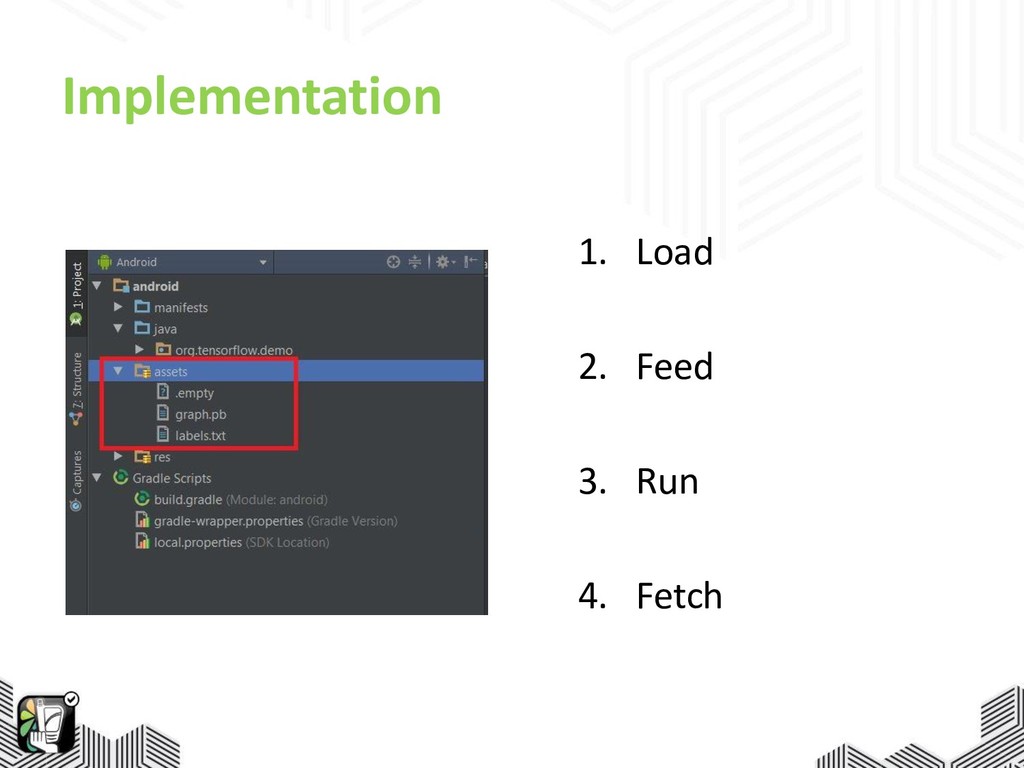
Implementation 1. Load 2. Feed 3. Run 4. Fetch
Implementation 1. Load the model 2. Feed in the input
3. Run the model 4. Fetch the output TensorFlowInferenceInterface inferenceInterface = new TensorFlowInferenceInterface(assetManager, modelFile);
Implementation 1. Load the model 2. Feed in the input
3. Run the model 4. Fetch the output // feed(String s, float[] floats, long… longs) inferenceInterface.feed(inputName, floatValues, 1, inputSize, inputSize, 3);
Implementation 1. Load the model 2. Feed in the input
3. Run the model 4. Fetch the output inferenceInterface.run(outputNames);
Implementation 1. Load the model 2. Feed in the input
3. Run the model 4. Fetch the output // fetch(String s, float[] floats) inferenceInterface.fetch(outputName, outputs);
APPLICATIONS Awesomeness.
Google Translate
None
None
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}