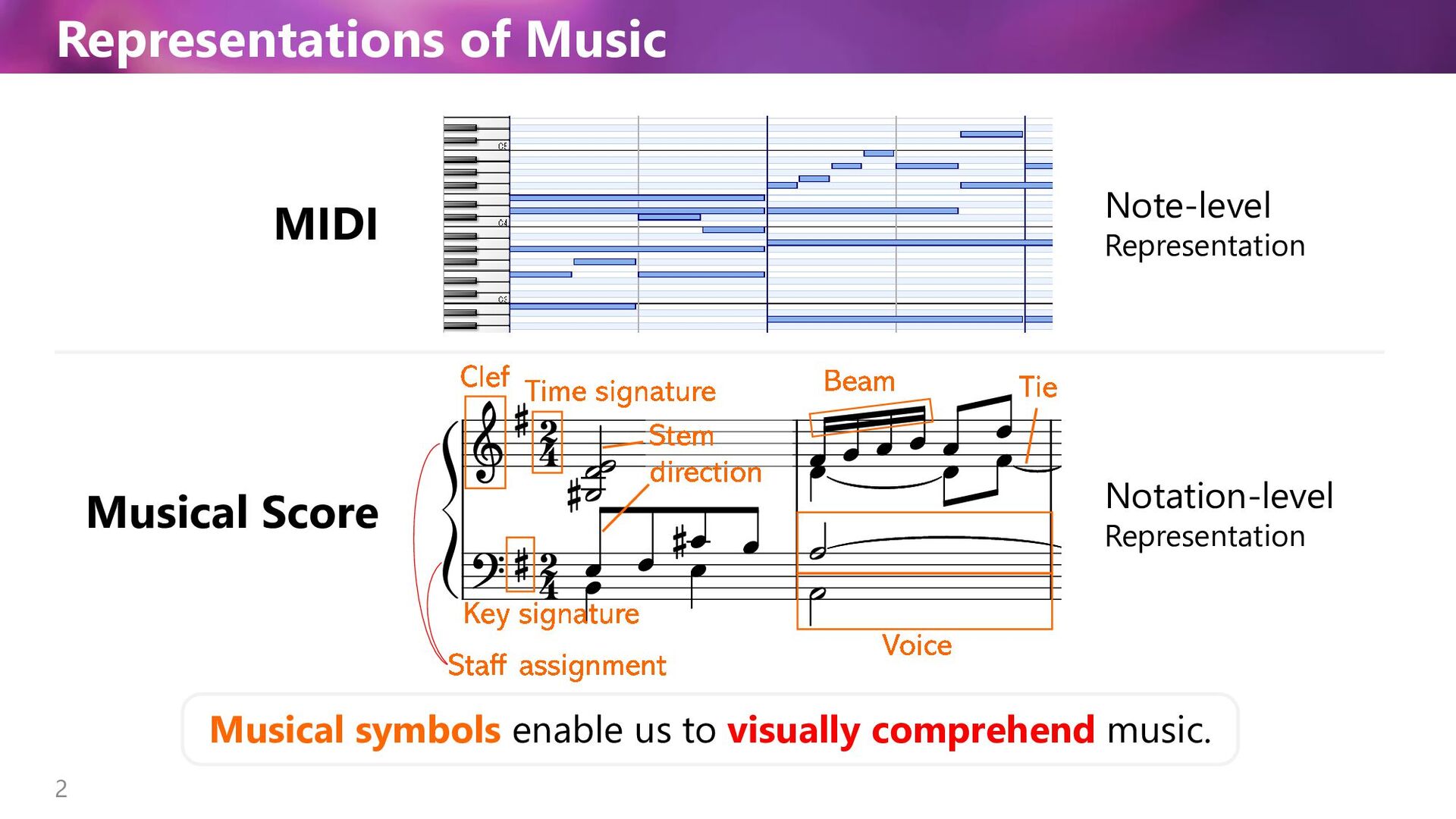
• Music Transformer [CZ Huang et al, 2019] • MIDI-like representation × Transformer • Generates long and coherent music • Pop Music Transformer [YS Huang et al, 2020] • REMI representation × Transformer-XL • Generates beat-aligned music 4 MIDI × Transformer Transformers work well with MIDI-level token representations. (w/ relative pos encoding) How about score-level token representation?
token representations in two ways: 1. Design a new token representation Tokenizing each musical symbol or attribute into a token 2. Utilize existing score formats Existing text-like score formats: ABC notation, Humdrum, and LilyPond 5 Score × Transformer Questions: Can transformers generate musical scores? Which token representation is effective?
<voice> note_E3 len_1/2 stem_up beam_start note_F#3 len_1/2 stem_up beam_continue note_C#4 stem_up beam_continue note_B3 len_1/2 stem_up beam_stop </voice> <voice> note_B2 len_1 stem_down note_E3 len_1 stem_down </voice> bar … R bar clef_treble key_sharp_1 time_2/4 note_E4 note_D4 note_G#3 len_2 stem_up bar … bar </voice> <voice> R L concatenate Design Principles • One token per symbol or attribute • Combined sequences of staves • Compatible with music21 attributes → to make scores consistent → to build scores easily clef_treble key_sharp_1 time_2/4 clef_bass Score Tokens
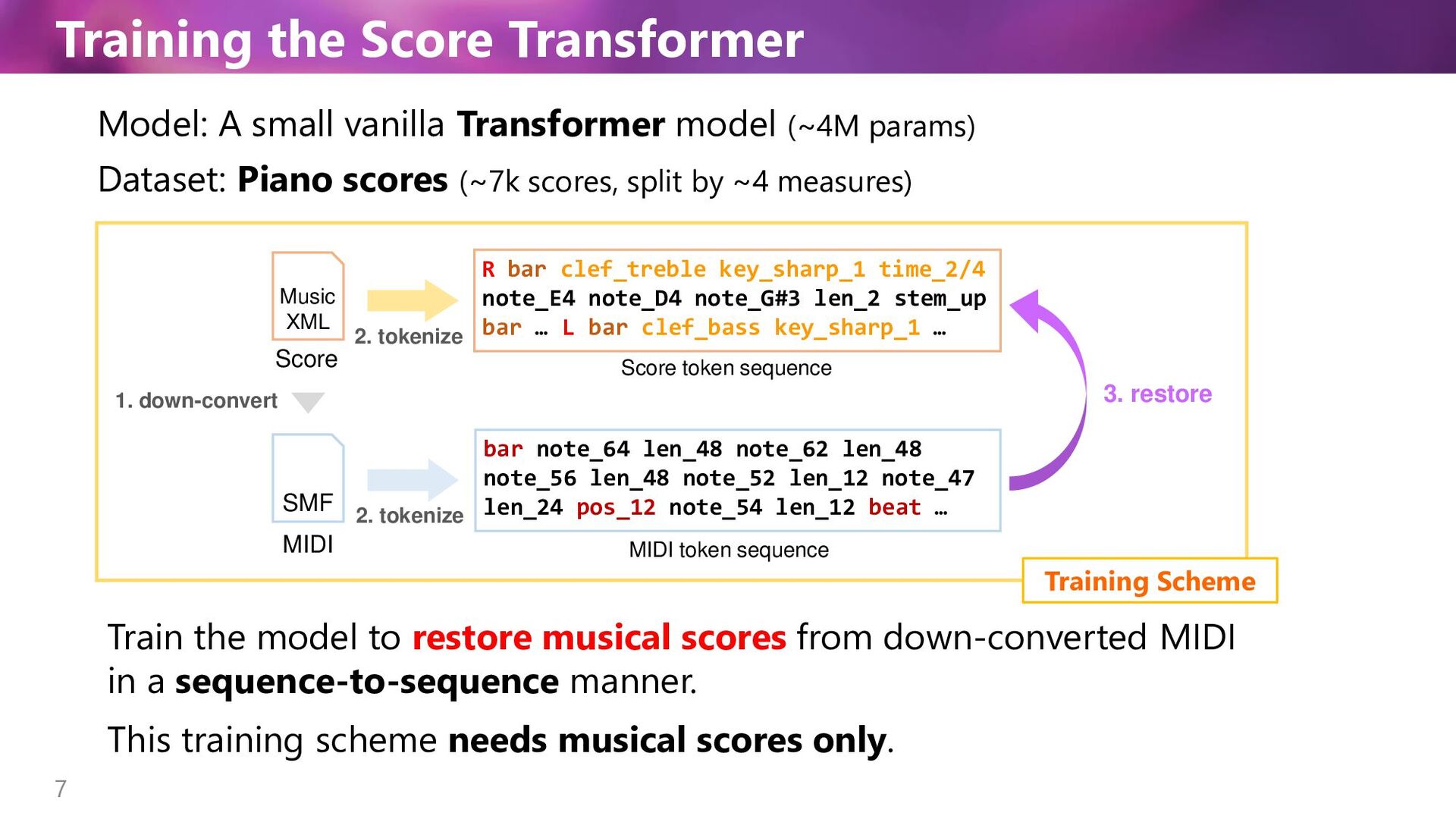
1. down-convert Score token sequence MIDI token sequence 3. restore 2. tokenize R bar clef_treble key_sharp_1 time_2/4 note_E4 note_D4 note_G#3 len_2 stem_up bar … L bar clef_bass key_sharp_1 … bar note_64 len_48 note_62 len_48 note_56 len_48 note_52 len_12 note_47 len_24 pos_12 note_54 len_12 beat … 2. tokenize Model: A small vanilla Transformer model (~4M params) Dataset: Piano scores (~7k scores, split by ~4 measures) Train the model to restore musical scores from down-converted MIDI in a sequence-to-sequence manner. This training scheme needs musical scores only. Training Scheme
separation Stem Direction Beam Count the differences of notations → Calculate error rates Stem Direction Measure differences The metric is based on “A Metric for music notation transcription accuracy [Cogiliati et al, 2017].” on 12 musical aspects
baselines on all 12 musical aspects, with much higher performances. Error rates in % (smaller is better) ・ CTD : Automatic music transcription framework [Cogiliati et al, 2016] ・ Finale 26 ・ MuseScore 3 Music Notation Software Baselines
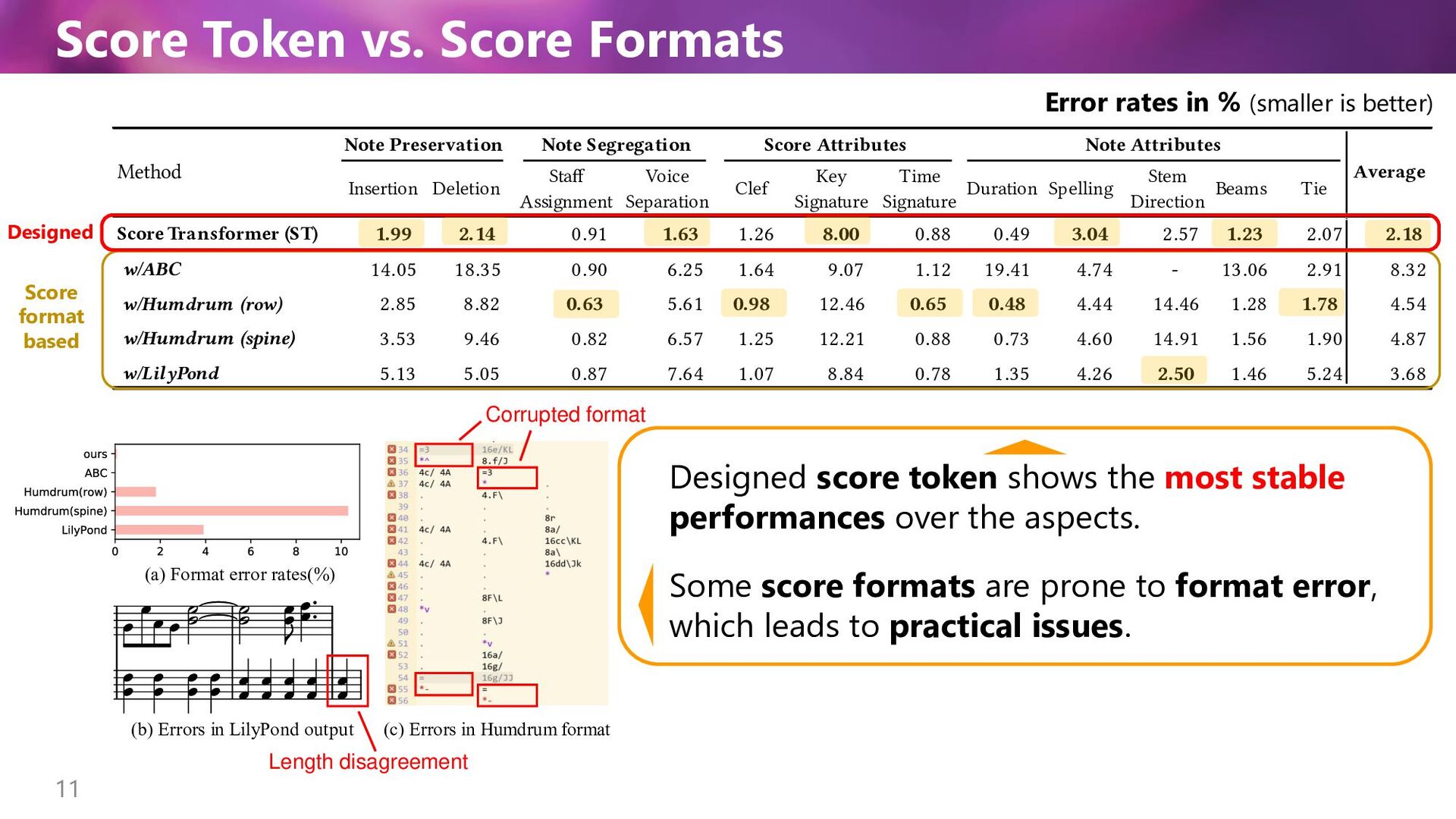
(smaller is better) Score format based Designed Designed score token shows the most stable performances over the aspects. Some score formats are prone to format error, which leads to practical issues. Length disagreement Corrupted format
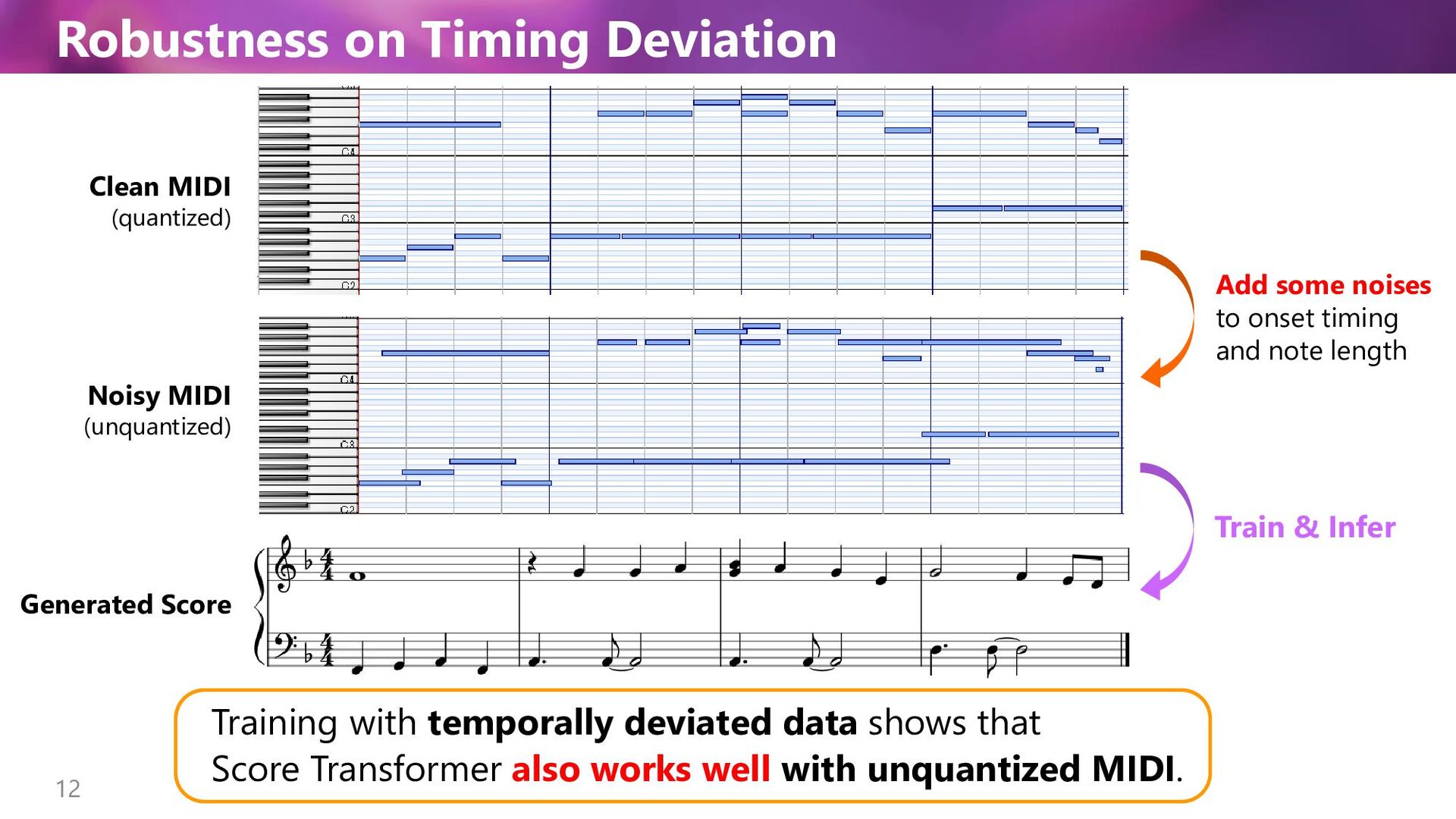
(unquantized) Add some noises to onset timing and note length Training with temporally deviated data shows that Generated Score Train & Infer Score Transformer also works well with unquantized MIDI.
work greatly better than existing methods. Which token representation is effective? ✓ Designed score token is the most effective. + The tokenization tools are publicly available -> https://github.com/suzuqn/ ScoreTransformer Get the tokenization tools! Possible future works: • Extending score token representation ex.) to various instruments, multi-part scores, or other symbols • Application to score-related tasks ex.) Score generation form scratch; Score-to-performance generation
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}