Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
文献紹介201905_Context-Aware Cross-Lingual Mapping
Search
T.Tada
May 08, 2019
Technology
110
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
文献紹介201905_Context-Aware Cross-Lingual Mapping
T.Tada
May 08, 2019
More Decks by T.Tada
See All by T.Tada
文献紹介_202002_Is artificial data useful for biomedical Natural Language Processing algorithms?
tad
0
75
文献紹介_202001_A Novel System for Extractive Clinical Note Summarization using EHR Data
tad
0
190
文献紹介_201912_Publicly Available Clinical BERT Embeddings
tad
0
180
文献紹介_201911_EDA: Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks
tad
0
230
文献紹介_201910_Do Neural NLP Models Know Numbers? Probing Numeracy in Embeddings
tad
0
110
文献紹介_201909_Sentence Mover’s Similarity_ Automatic Evaluation for Multi-Sentence Texts
tad
0
170
文献紹介_201908_Medical Word Embeddings for Spanish_ Development and Evaluation
tad
0
73
文献紹介_201907_Is Word Segmentation Necessary for Deep Learning of Chinese Representations
tad
0
120
文献紹介_201906_Predicting Annotation Difficulty to Improve Task Routing and Model Performance for Biomedical Information Extraction
tad
0
110
Other Decks in Technology
See All in Technology
アラート調査向けAIエージェントの本番導入とその後/AI Agents for Alert Investigation: Production Deployment and After
taddy_919
1
250
週末にループ・エンジニアリングの理解を深めるためのスライド
nagatsu
0
580
AIは、人間らしい仕事の夢を見るか?─ AI時代のtoB/toEプロダクトを再設計する
techtekt
PRO
0
160
「勝手に広まる」人気 AI エージェントを爆速で作ろう!(AWS Summit Japan 2026講演資料)
minorun365
PRO
10
2.6k
AIチャットの改善から見えた、良いAI体験とは / What Constitutes a Good AI Experience: Insights from Improving AI Chat
kubode
0
130
IaC コードを資産へ:AWS CDK 社内ライブラリと横断展開 / aws-summit-japan-2026
gotok365
10
1.6k
Microsoft のサポートとフィードバック総まとめ
murachiakira
PRO
0
120
[AWS Summit Japan 2026]迷っているあなたへ_小さな一歩が、やがて自分を助けてくれる
sh_fk2
2
430
FPC(フレキシブル)基板にZephyr実装してみた。
iotengineer22
0
180
時期が悪い!それでもRaspberry Piを買って遊んで活用するには / 20260627-osc26do-rpi-jikigawarui
akkiesoft
1
890
5分でわかる Amazon Connect_20260608
hwangbyeonghun
0
130
技術・能力を向上する原理原則 #きのこセッションa #きのこ2026
bash0c7
0
140
Featured
See All Featured
How Fast Is Fast Enough? [PerfNow 2025]
tammyeverts
3
620
Building Adaptive Systems
keathley
44
3.1k
ピンチをチャンスに:未来をつくるプロダクトロードマップ #pmconf2020
aki_iinuma
128
56k
The #1 spot is gone: here's how to win anyway
tamaranovitovic
3
1.1k
Design in an AI World
tapps
1
250
Build your cross-platform service in a week with App Engine
jlugia
234
18k
Into the Great Unknown - MozCon
thekraken
41
2.6k
Hiding What from Whom? A Critical Review of the History of Programming languages for Music
tomoyanonymous
2
870
Designing for Performance
lara
611
70k
10 Git Anti Patterns You Should be Aware of
lemiorhan
PRO
659
62k
AI Search: Implications for SEO and How to Move Forward - #ShenzhenSEOConference
aleyda
1
1.3k
Evolution of real-time – Irina Nazarova, EuRuKo, 2024
irinanazarova
9
1.4k
Transcript
- 文献紹介 2019/5/7 - Context-Aware Cross-Lingual Mapping 長岡技術科学大学 自然言語処理研究室 多田太郎
About the paper 2 Authors: Hanan Aldarmaki : The George
Washington University Mona Diab : AWS, Amazon AI Conference: NAACL-HLT 2019 (short paper)
Abstract ・文レベルの類似性をより反映する、単語レベルのマッピングに代わる方法を提案 ・対訳コーパス内のアライメントされた文埋め込みを直接マッピングすることにより、 変換行列にコンテキストを組み込む ・単語アラインメントを有する対訳文を使用して、文脈化された単語埋め込みのマッピングを 実施 3
Introduction ・クロスリンガル単語ベクトルモデルは、言語間の辞書拡張などを可能にするために、複数の 言語からの単語を共有ベクトル空間に埋め込むことが目的(Upadhyay et al.,2016) ・マッピングに直交性の制約を課すことで、元のペアワイズ距離が保持され、単語の翻訳検 索が向上(Artetxe et al., 2016;
Smith et al.,2017) ・単語ベクトル空間は言語間で一貫している傾向がある(Aldarmaki et al.,2018) 語義曖昧性のある語(例: 'bank'、 'coast')および句動詞( 'stand up'の個々の単語な ど)は、使用分布が異なるため、多言語ベクトル空間では一貫性が低下 →アライメント辞書で上のような単語を使用すると、全体的に最適でないマッピング になる可能性がある 4
Introduction ・明示的な語義曖昧解消や言語資源追加なしに、文章の文脈をマッピングプロセスに組み込 むことにより、これら影響を打ち消すための2つのアプローチを提案 1. 言語モデルELMoを基にした文脈化された埋め込み(Peters et al。、2018) 対訳コーパスと単語アライメントを使用して、文脈を反映した埋め込みを抽出して、 マッピングのための辞書を構築 2.
個々の単語の埋め込みではなく、文埋め込みの変換を学習する 埋め込みは全文にわたる文脈を含んでいるので、このレベルで学習されたマッピング は個々の単語に対してよりロバストと考えられる 5
Approach - Orthogonal Bilingual Mapping - ソースとターゲットのペア<x、y> 列が対応する辞書項目のベクトル表現である行列表現XとY 直交性の制約により、元のソースベクトル空間内のペアワイズ距離が変換後も維持される 解はY
X Tの特異値分解によって求めることができる(Schönemann, 1966) Rは、ソースベクトル空間内の追加のベクトルを変換するために使用できる 6
Approach - Mapping of Contextualized Embeddings - ソース言語とソース言語の翻訳における単語埋め込みは同様の構造を有する傾向がある (Aldarmaki et
al.,2018) しかし、語義曖昧性のある語や句動詞は、使用分布が異なるため、多言語ベクトル空間では 一貫性が低下 →結果、全体的に最適でないマッピングになる可能性がある ・ELMoから文脈化された単語埋め込みを得る(Peters et al.,2018) ・文の埋め込みは、単語埋め込みを平均化しELMoから得る(Perone et al.,2018) ・単語アラインメントを有する並列コーパス、すなわちIBMモデル(Brown et al., 1993)を使用し、 アライメントから文脈化された単語埋め込みの動的辞書を抽出し使用 7
Experiments ・単語埋め込みにはFastText(Bojanowski et al., 2017)を用いたskipgramを使用 ・文脈化単語埋め込みにはELMoを使用 ・文章の埋め込みは、文脈化された平均単語埋め込みとしてELMoから計算 8
Experiments - Data - ・すべてのモデル同じ単一言語と対訳のデータセットを用いて学習をおこなう ・単言語トレーニング the 1 Billion Word
benchmark (Chelba et al., 2014) WMT’13 (Bojar et al., 2013)から約4億トークン相当のサブセット 単言語のELMoとFastTextをトレーニング(パラメータはデフォルト) ・言語間マッピング WMT’13のコモンクロールデータ ・文の翻訳検索の評価 WMT 13テストセット 9
Experiments - Evaluation Framework - ・最近傍探索を用いて、テスト対訳コーパスのターゲット側で正しい翻訳の検索精度 →文翻訳検索におけるクロスリンガルマッピングアプローチの評価をおこなう ・データからどのように影響を受けるか →トレーニングコーパスを分割して100〜100万文で実験
10
Experiments - Alignment Schemes - ELMoでは、単語の埋め込みは文脈から計算する必要がある ・Fast Align(Dyer et al.,
2013)を使用して単語レベルのアライメントを適用することで、 対訳コーパスから文脈化単語の辞書を抽出 ・ソース文とターゲット文に対する文脈化単語埋め込みを計算し,一対一のアライメントを 持つ単語から辞書を抽出した(効率のために辞書の単語数を1Mに制限) ・FastTextでも、同じ対訳セットを使用して単語アライメント確率から辞書を抽出 すべてのアライメントは、ソース言語から英語に実行 11
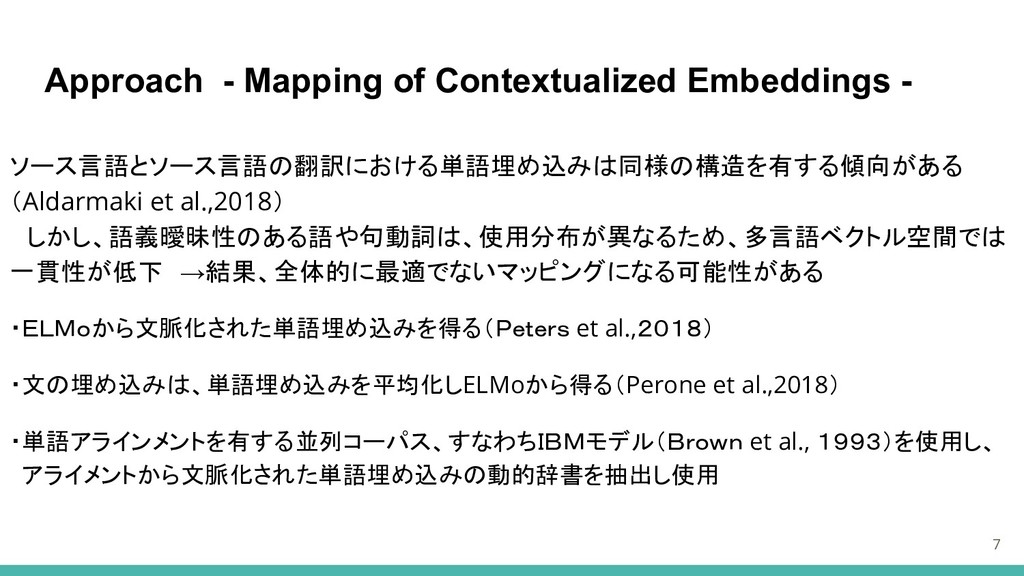
Experiments - Results - 12
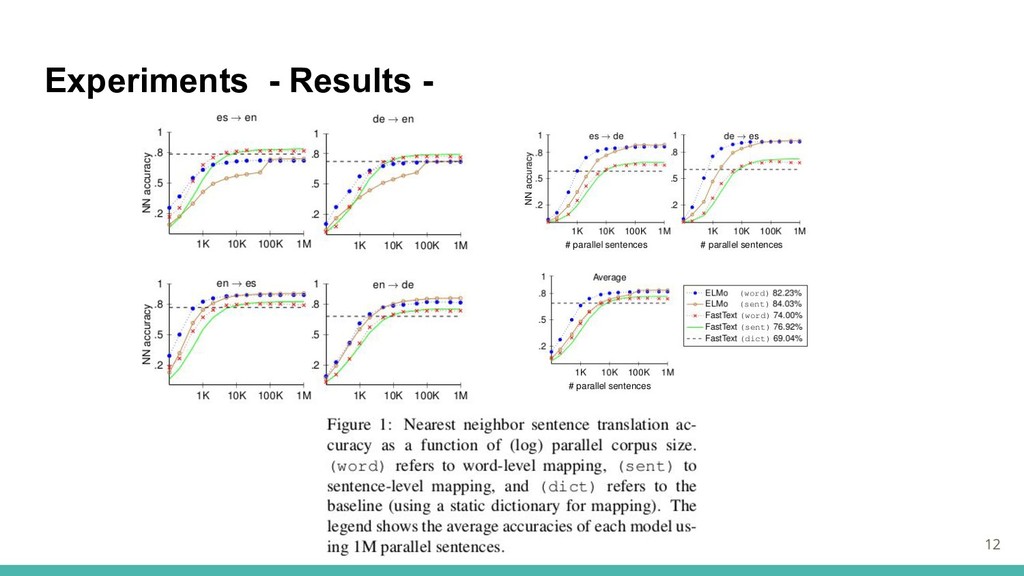
Experiments - Word-level Evaluation - クロスリンガルの単語埋め込みは、他言語の語彙から正しく翻訳を検索する精度で評価される →単語レベルでは文脈とは離れたタスクなので、FastTextのパフォーマンスで評価 文レベルで学習した言語間の変換行列を用いて単語の埋め込みを変換する。 また,人間の判断に対するPearsonとSpearman相関係数の平均を用いて測定した SemEval’17クロスリンガル単語類似性タスク(Camacho-Colladosら、2017)についても評価
13
Experiments - Word-level Evaluation - 14
Experiments - Word-level Evaluation - 15
Conclusions ・マッピングにコンテキストを組み込んだ、単語マッピングアプローチを提案 ・単語アラインメントを有する対訳文を使用して、文脈化された単語埋め込みのマッピング を実施 ・文章翻訳検索において文脈に依存しない単語マッピングよりも優れた精度 ・文レベルの変換は、単語の翻訳品質を損なうことなく、単語レベルのマッピングに使用可 16
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}