Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
文献紹介_201907_Is Word Segmentation Necessary for ...
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
T.Tada
July 03, 2019
Technology
120
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
文献紹介_201907_Is Word Segmentation Necessary for Deep Learning of Chinese Representations
T.Tada
July 03, 2019
More Decks by T.Tada
See All by T.Tada
文献紹介_202002_Is artificial data useful for biomedical Natural Language Processing algorithms?
tad
0
75
文献紹介_202001_A Novel System for Extractive Clinical Note Summarization using EHR Data
tad
0
190
文献紹介_201912_Publicly Available Clinical BERT Embeddings
tad
0
180
文献紹介_201911_EDA: Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks
tad
0
230
文献紹介_201910_Do Neural NLP Models Know Numbers? Probing Numeracy in Embeddings
tad
0
110
文献紹介_201909_Sentence Mover’s Similarity_ Automatic Evaluation for Multi-Sentence Texts
tad
0
170
文献紹介_201908_Medical Word Embeddings for Spanish_ Development and Evaluation
tad
0
73
文献紹介_201906_Predicting Annotation Difficulty to Improve Task Routing and Model Performance for Biomedical Information Extraction
tad
0
110
文献紹介201905_Context-Aware Cross-Lingual Mapping
tad
0
110
Other Decks in Technology
See All in Technology
SRE歴2ヶ月でも開発6年の知見を活かして、チームで止まっていた環境改善を前に進めた話
a_ono
0
100
AI 不只幫你寫 Code: 當專案從 300 暴增到 1500, 我們如何撐住 DevOps
appleboy
0
280
Lightning近況報告
kozy4324
0
230
スタートアップにAmazon EKSは早すぎる? マルチプロダクト戦略を加速する Platform Engineeringの実践 / Is Amazon EKS Too Soon for Startups? Practical Platform Engineering to Accelerate a Multi-Product Strategy
elmodev09
1
1.9k
AI-DLCを “そのまま導入しなかった”話 ~組織に合わせてアジャストした 私たちの実践共有~
hiroramos4
PRO
1
440
10年間のブログ発信を振り返って見えたWebアプリケーションエンジニアとしての軌跡
stefafafan
0
190
40代で“やっとエンジニアになれた”――閉じた学びを開き、空の青さを知る / 20260628 Naoki Takahashi
shift_evolve
PRO
4
1.1k
WebGIS AI Agentの紹介
_shimizu
0
590
Oracle Cloud Infrastructure:2026年6月度サービス・アップデート
oracle4engineer
PRO
1
370
秘密度ラベル初心者が第1歩でつまづかないための「設計・運用」ポイント
seafay
PRO
1
500
IaC コードを資産へ:AWS CDK 社内ライブラリと横断展開 / aws-summit-japan-2026
gotok365
10
1.6k
Docker Desktop不要の時代が来る? WSL標準の「wslc」で Linuxコンテナを動かしてみた.
ueponx
0
110
Featured
See All Featured
Building Better People: How to give real-time feedback that sticks.
wjessup
370
20k
Joys of Absence: A Defence of Solitary Play
codingconduct
1
400
Measuring & Analyzing Core Web Vitals
bluesmoon
9
870
Amusing Abliteration
ianozsvald
1
210
Primal Persuasion: How to Engage the Brain for Learning That Lasts
tmiket
0
380
Conquering PDFs: document understanding beyond plain text
inesmontani
PRO
4
2.8k
Docker and Python
trallard
47
3.9k
Become a Pro
speakerdeck
PRO
31
6k
The agentic SEO stack - context over prompts
schlessera
0
830
Site-Speed That Sticks
csswizardry
13
1.2k
Making Projects Easy
brettharned
120
6.7k
B2B Lead Gen: Tactics, Traps & Triumph
marketingsoph
0
160
Transcript
- 文献紹介 2019 Jul 3 - Is Word Segmentation Necessary
for Deep Learning of Chinese Representations? 長岡技術科学大学 自然言語処理研究室 多田太郎
About the paper 2 Authors: Conference: ACL 2019
Abstract ・中国語のテキストの単語分割の必要性はあまり調べられていない ・中国語単語分割(CWS)が深層学習に基づく中国語NLPに必要であるか ・4つのエンドツーエンドのNLPベンチマークタスクで実験 ・文字ベースのモデルは一貫して単語ベースのモデルよりも優れていた 3
Introduction 4 ・中国語テキストでは前処理として単語分割を行なうのが一般的 ・単語ベースのモデルにはいくつかの基本的な欠点がある コーパス内の単語のスパース性が過剰適合につながる OOV単語の偏在はモデルの学習能力を制限する →単語の頻度が低いため、モデルでそれらの意味を完全に学習することは不可能 ・最先端の単語セグメンテーションの性能でも完全には程遠い その誤差は下流のNLPタスクに影響 →中国語の単語の境界が非常に曖昧なため
・単語ベースのモデルを文字ベースのモデルと比較し、有用性を検討
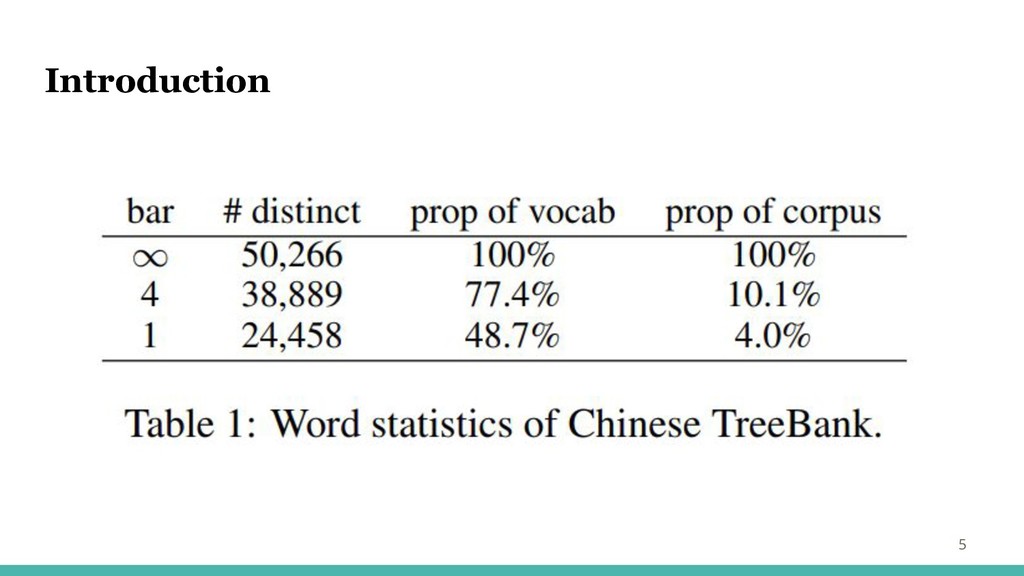
Introduction 5
・ディープラーニングベースの中国語NLPにおける単語分割の効果を評価 言語モデリング、機械翻訳、テキスト分類、文のマッチング/言い換え ・単語ベースのモデルと文字ベースのモデルを比較 グリッドサーチでハイパーパラメータを調整 (学習率、バッチサイズ、ドロップアウト率などの重要な項目) Experimental Results 6
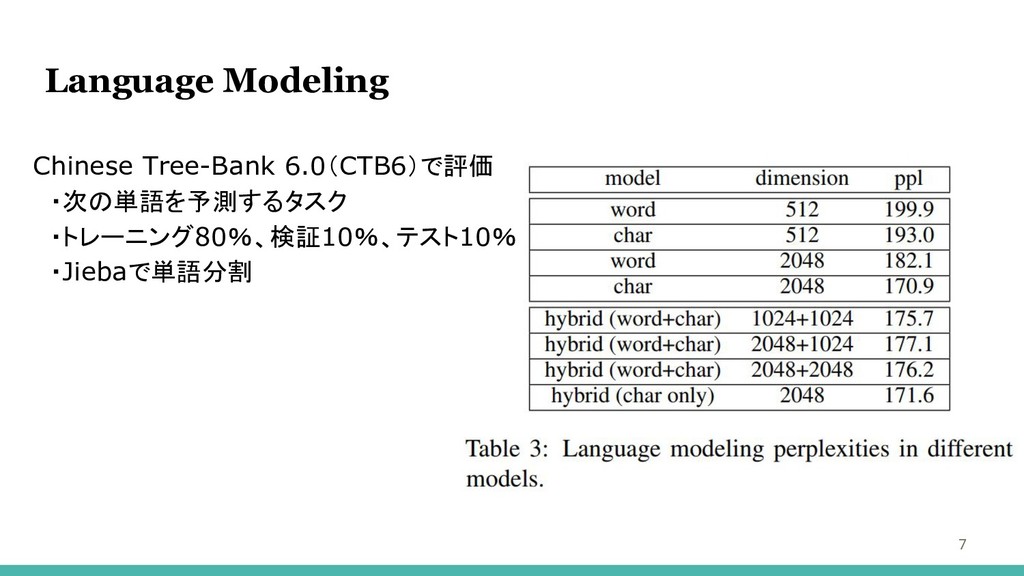
Chinese Tree-Bank 6.0(CT B6)で評価 ・次の単語を予測するタスク ・トレーニング80%、検証10%、テスト10% ・Jiebaで単語分割 Language Modeling 7
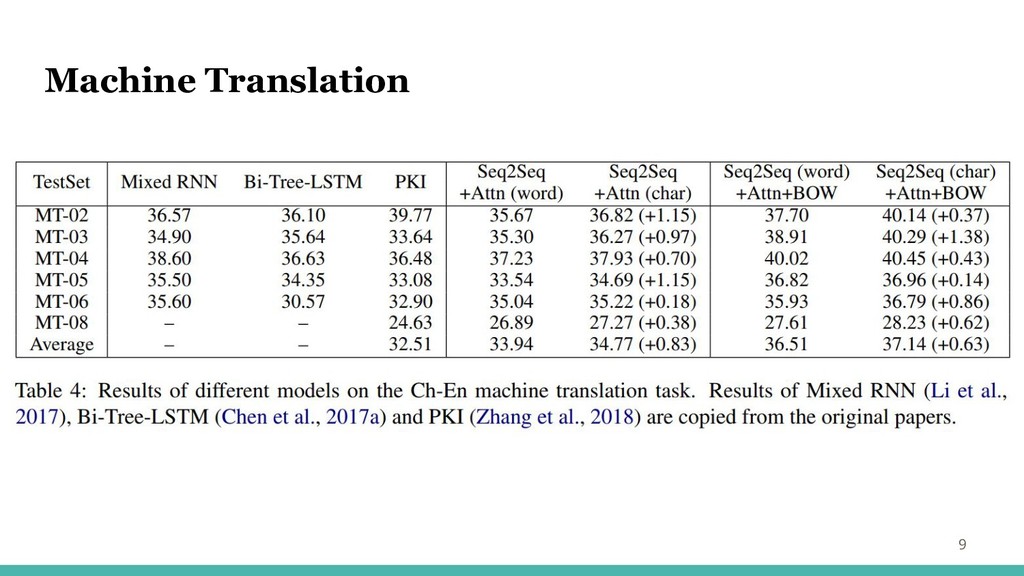
・Ch-En, En-Ch トレーニングセットは、LDCコーパスから抽出された1.25Mの文ペア 検証セット:NIST 2002 テストセット:NIST 2003,2004,2005,2006,2008 語彙サイズ:4,500 Machine Translation
8
・テ Machine Translation 9
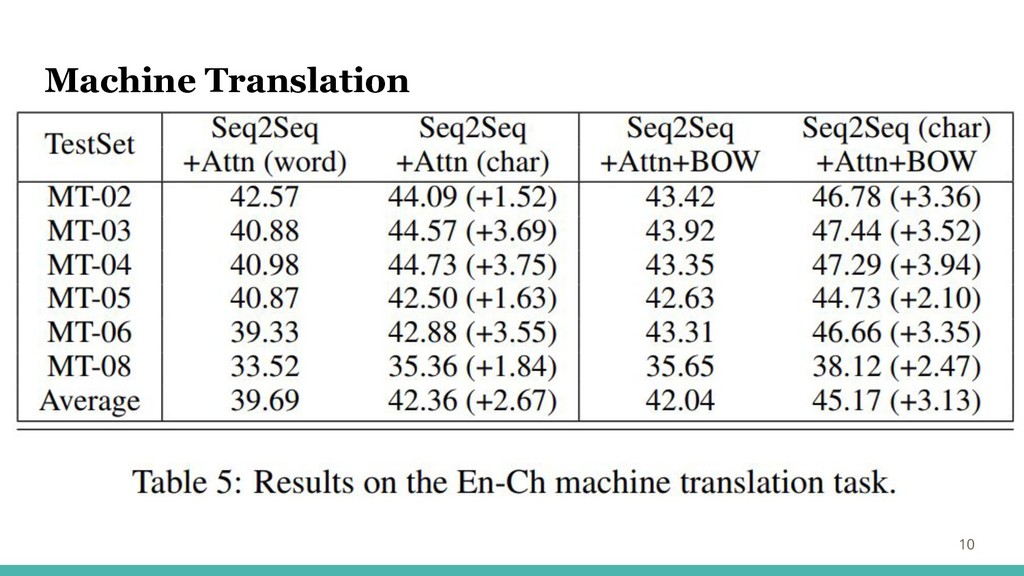
・テ Machine Translation 10
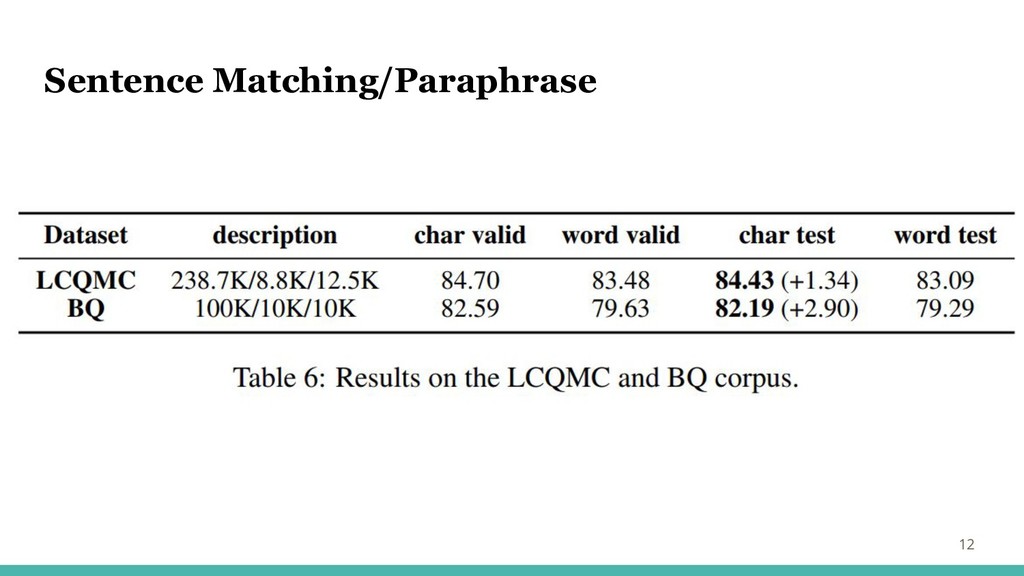
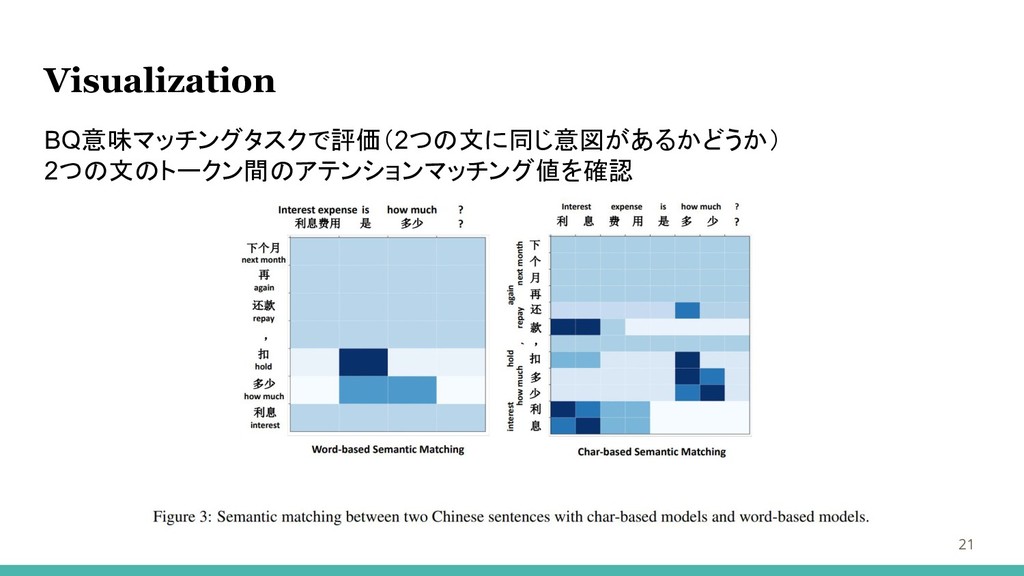
Sentence Matching/Paraphrase 11 BQとLCQMCで評価 Stanford Natural Language Inference (SNLI) Corpusと似たタスク
ペアとなっている2つの文が同じ意味(BQ)、意図(LCQMC)か テキストはJiebaで単語分割 SOTAモデルのBiMPM(2017)を用い実験 BiMPMによって提案された標準設定 ランダムに初期化される200dのword / char埋め込みを使用
Sentence Matching/Paraphrase 12
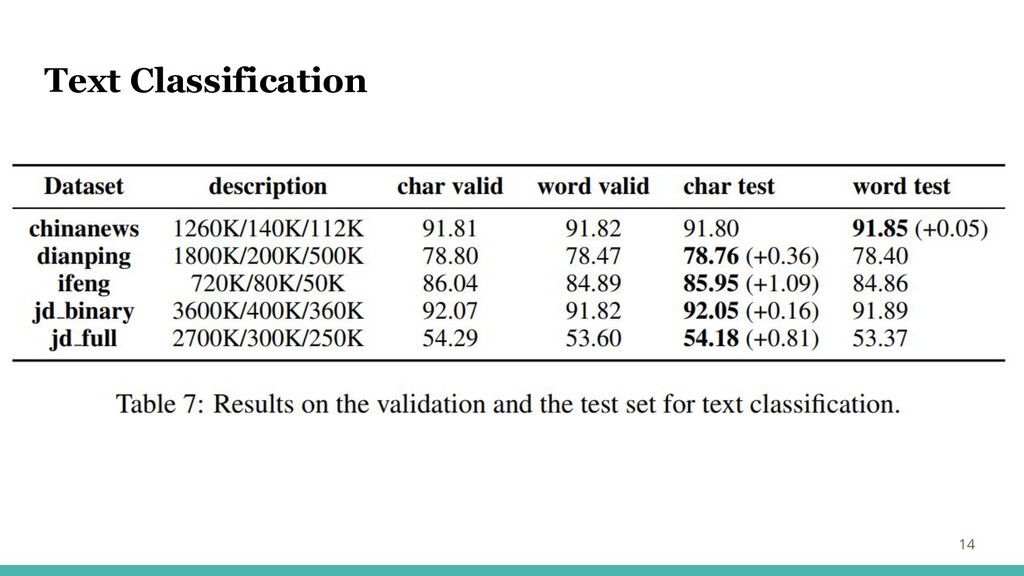
Text Classification 13 5つのデータ・セットで実験 ChinaNews:ニュース記事、7カテゴリ Ifeng:ニュース記事の最初の段落、5カテゴリ JD_Full:製品レビュー、5クラス JD_binary:製品レビュー、2クラス Dianping:レストランのレビュー、2クラス 単語ベースと文字ベースで双方向LSTMモデルをトレーニング
Text Classification 14 ・ト
Domain Adaptation Ability 15 ・学習データと異なる(しかし関連した)データに対しての評価 単語のスパース性により文字ベースのモデルは単語ベースのモデルよりも ドメイン適応能力が高いと仮定 ・感情分析データセットに対して仮説を検証 Dianping(レストランレビュー)とJD_binary(製品レビュー)で評価 トレーニング/テストを入れ替えて2通り行なう
Domain Adaptation Ability 16
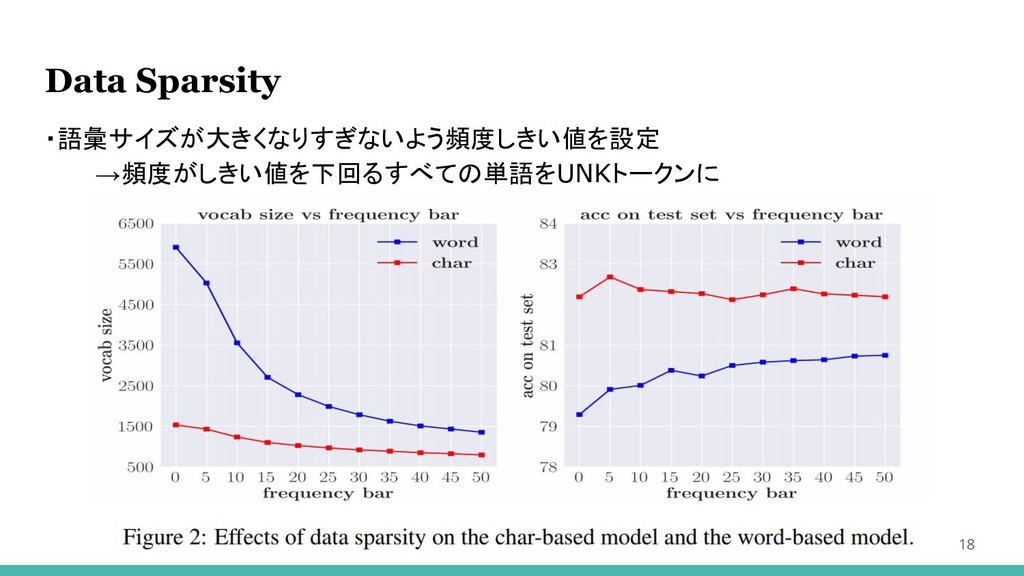
Analysis 17 ・単語ベースのモデルが文字ベースのモデルよりも優れている結果を得た →理由の理解を目指す ・以下項目で確認 Data Sparsit Out-of-Vocabulary Words Visualization
Data Sparsity 18 ・語彙サイズが大きくなりすぎないよう頻度しきい値を設定 →頻度がしきい値を下回るすべての単語をUNKトークンに
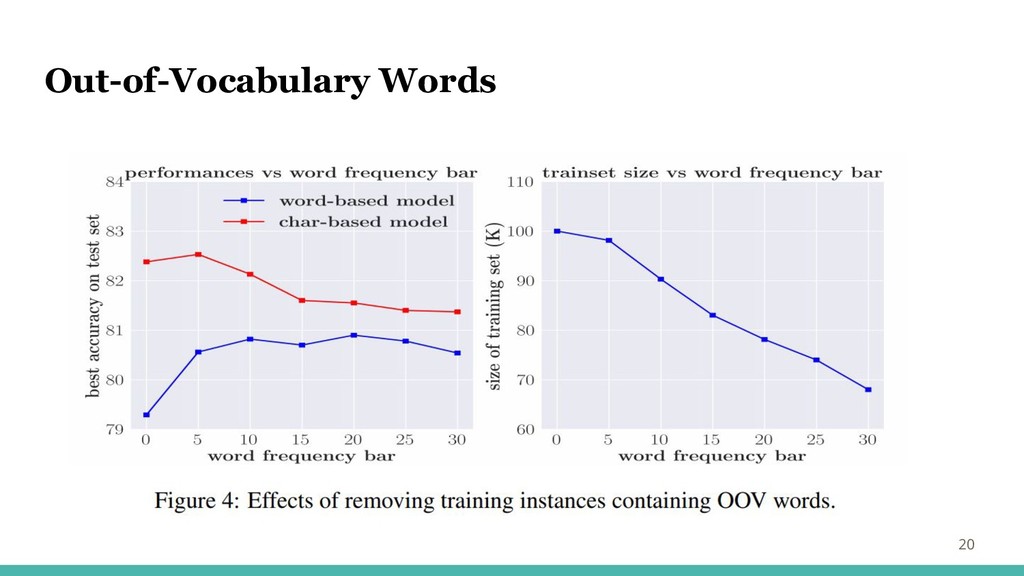
Out-of-Vocabulary Words 19 ・単語ベースのモデルの劣っている理由にOOVが考えられる →OOVの数を減らすことで、単語ベースと文字ベースのギャップを小さくできるのでは ・頻度しきい値を低く設定すると、データのスパース性の問題の悪化が予想される →異なる単語頻度のしきい値に対して、データ・セットから単語OOVを含む文を削除
Out-of-Vocabulary Words 20
Visualization 21 BQ意味マッチングタスクで評価(2つの文に同じ意図があるかどうか) 2つの文のトークン間のアテンションマッチング値を確認
Conclusion 22 ・中国語深層学習での単語分割の必要性について調査 ・4つのNLPタスクで、単語ベースと文字ベースのモデルを評価 ・文字ベースのモデルは一貫して単語ベースのモデルよりも優れていた ・単語ベースモデルの劣っている理由は単語分布のまばらさが原因であることを示した
23
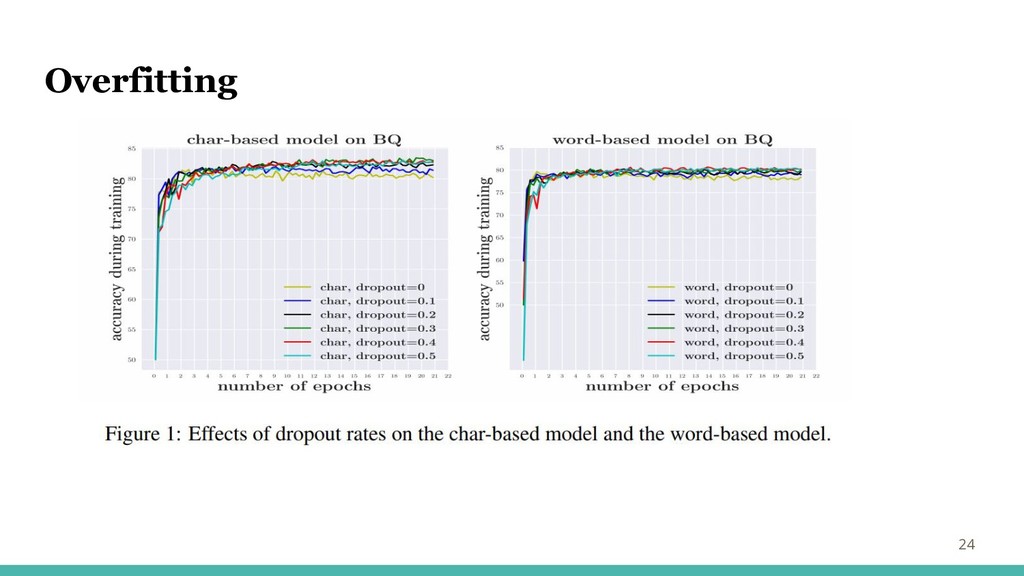
Overfitting 24
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}