Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
文献紹介_201908_Medical Word Embeddings for Spanish...
Search
T.Tada
August 28, 2019
Technology
73
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
文献紹介_201908_Medical Word Embeddings for Spanish_ Development and Evaluation
T.Tada
August 28, 2019
More Decks by T.Tada
See All by T.Tada
文献紹介_202002_Is artificial data useful for biomedical Natural Language Processing algorithms?
tad
0
76
文献紹介_202001_A Novel System for Extractive Clinical Note Summarization using EHR Data
tad
0
190
文献紹介_201912_Publicly Available Clinical BERT Embeddings
tad
0
180
文献紹介_201911_EDA: Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks
tad
0
230
文献紹介_201910_Do Neural NLP Models Know Numbers? Probing Numeracy in Embeddings
tad
0
110
文献紹介_201909_Sentence Mover’s Similarity_ Automatic Evaluation for Multi-Sentence Texts
tad
0
170
文献紹介_201907_Is Word Segmentation Necessary for Deep Learning of Chinese Representations
tad
0
120
文献紹介_201906_Predicting Annotation Difficulty to Improve Task Routing and Model Performance for Biomedical Information Extraction
tad
0
110
文献紹介201905_Context-Aware Cross-Lingual Mapping
tad
0
110
Other Decks in Technology
See All in Technology
最適な自走を最小限の支援で — M&Aで拡大する組織で少人数SREが挑んだ1年 / SRE NEXT 2026
genda
0
620
クラウド上のデータ復旧で見落としがちな制約: 医療系 SaaS の BCP 設計から得た教訓
kakehashi
PRO
0
2.9k
プライバシー保護の理論と実践
lycorptech_jp
PRO
1
250
プロダクトだけじゃない、社内プロセスにおける自動化・省力化ノススメ
kakehashi
PRO
1
3.1k
Empower GenAI with Agile - あなたのアジャイルが生成AIのバフになる仕組み
hageyahhoo
1
150
ヘルスケア領域における AI 活用と その安全性担保のための取り組み (Leveraging AI in Healthcare and Our Efforts to Ensure Its Safety) - Google I/O Extended Tokyo 2026, July 11, 2026
zettaittenani
0
230
知らん間に、回ってる
ming_ayami
0
360
AWS Blocks を触ってみた/first-tach-aws-blocks
fossamagna
2
150
Claude Code 珍プレー好プレー
shinyasaita
0
300
金融の未来を考える / Thinking About the Future of Finance
ks91
PRO
0
180
Oracle Exadata Database Service on Cloud@Customer X11M (ExaDB-C@C) サービス概要
oracle4engineer
PRO
2
8.4k
Baseline対応のDOMの型定義を作った
uhyo
3
720
Featured
See All Featured
AI in Enterprises - Java and Open Source to the Rescue
ivargrimstad
0
1.4k
Test your architecture with Archunit
thirion
1
2.3k
Unlocking the hidden potential of vector embeddings in international SEO
frankvandijk
0
870
How People are Using Generative and Agentic AI to Supercharge Their Products, Projects, Services and Value Streams Today
helenjbeal
1
230
Automating Front-end Workflow
addyosmani
1370
210k
Raft: Consensus for Rubyists
vanstee
141
7.6k
GraphQLとの向き合い方2022年版
quramy
50
15k
16th Malabo Montpellier Forum Presentation
akademiya2063
PRO
0
170
KATA
mclloyd
PRO
35
15k
The Director’s Chair: Orchestrating AI for Truly Effective Learning
tmiket
1
210
svc-hook: hooking system calls on ARM64 by binary rewriting
retrage
2
330
End of SEO as We Know It (SMX Advanced Version)
ipullrank
3
4.3k
Transcript
- 文献紹介 2019 Aug 28 - Medical Word Embeddings for
Spanish: Development and Evaluation 長岡技術科学大学 自然言語処理研究室 多田太郎
About the paper 2 Authors: Conference: Proceedings of the 2nd
Clinical Natural Language Processing Workshop (NAACLのワークショップ)
Abstract ・医療および臨床NLPでは、単語分散表現がNERや分類など有効なリソース ・スペイン語での医療ドメインの単語埋め込みについて学習・評価 ・生物医学ドメインのスペイン語での単語埋め込みの作成と評価にほとんど注意が払わ れていない ・英語のデータ・セットをスペイン語で活用 3
Material and Methods 4 ・分散表現手法:FastText ・学習コーパス: 1. SciELOデータベース(論文の本文とアブストラクト、スペイン語の地域は不問) 2. Wikipedia(健康、薬理学、薬局、医学、生物学のカテゴリー)
Evaluation -Intrinsic- 5 ・生物医学分野で利用できる標準的なスペイン語のデータセットはない ・学習した埋め込みの評価のため、英語のデータ・セットをスペイン語に適用 使用するデータ・セット: UMNSRSの類似性(UMNSRS-sim)および関連性(UMNSRS-rel)タスク 統合医学言語システム(UMLS)のコンセプトペアで構成されるデータセット(英語) 類似性と関連性について人手で注釈が付けられている UMNSRSsim:566ペア、UMNSRS-rel:587ペアのコンセプト
MayoSRS: 類似性評価に使用 101個のUMLSペアとそれぞれの人手でつけたスコアで構成
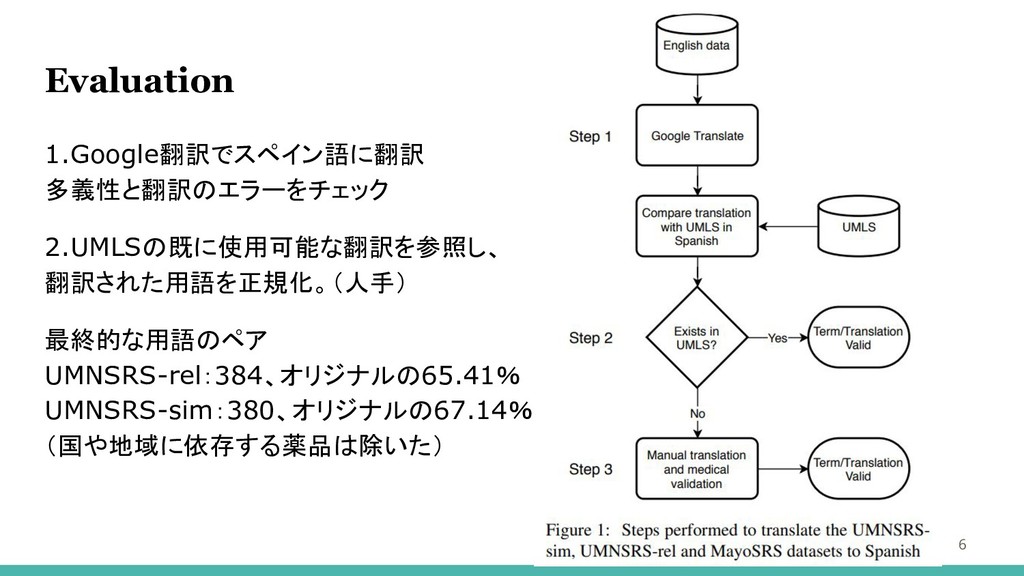
Evaluation 6 1.Google翻訳でスペイン語に翻訳 多義性と翻訳のエラーをチェック 2.UMLSの既に使用可能な翻訳を参照し、 翻訳された用語を正規化。(人手) 最終的な用語のペア UMNSRS-rel:384、オリジナルの65.41% UMNSRS-sim:380、オリジナルの67.14% (国や地域に依存する薬品は除いた)
Evaluation 7 Baseline Word Embedding: チリ大学NLPグループ(DCC Uchile)から入手可能な埋め込みを使用 学習データ:SBWC(Spanish Billion Word
Corpus) コーパスサイズ: 約1.4 億語 一般ドメイン 学習方法は本論文の学習モデルと同様
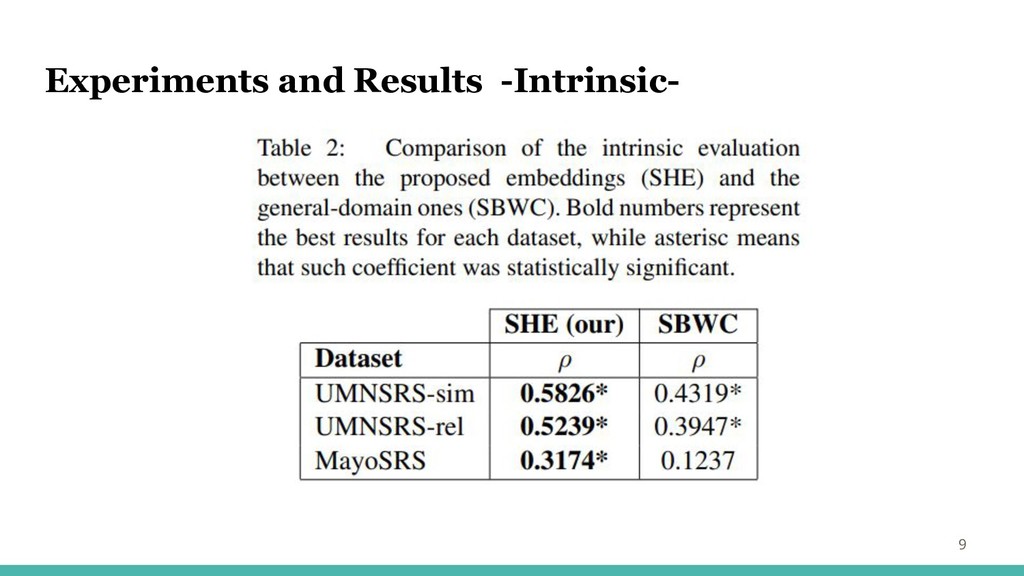
Experiments and Results -Intrinsic- 8 ・翻訳された各ペアが学習したモデルの語彙に存在するかチェック →公平な比較のため ・複数単語による用語については、個々の単語ベクトルの平均を使用 ・各翻訳済みデータセットの比較ペアの最終数:
UMNSRS-sim(322)、UMNSRSrel(252)、MayoSRS(101) ・各ペアのコサイン距離を計算、人手のアノテーションとのピアソン相関係数(ρ)
9 Experiments and Results -Intrinsic-
Evaluation -Extrinsic- 10 Data: スペインの臨床症例コーパス(SPACCC) ・スペインのオープンアクセスの医学出版物の臨床症例セクション ・1000の臨床症例のコレクション、16504の文、396,988語 ・生物医学文献と医学文献、および臨床記録がある ・臨床症例は腫瘍学、泌尿器科、循環器学、感染症など医学分野が限定されない ・Shered
Task に使用されている Software: NeuroNERを使用 ・NERシステム ・LSTM
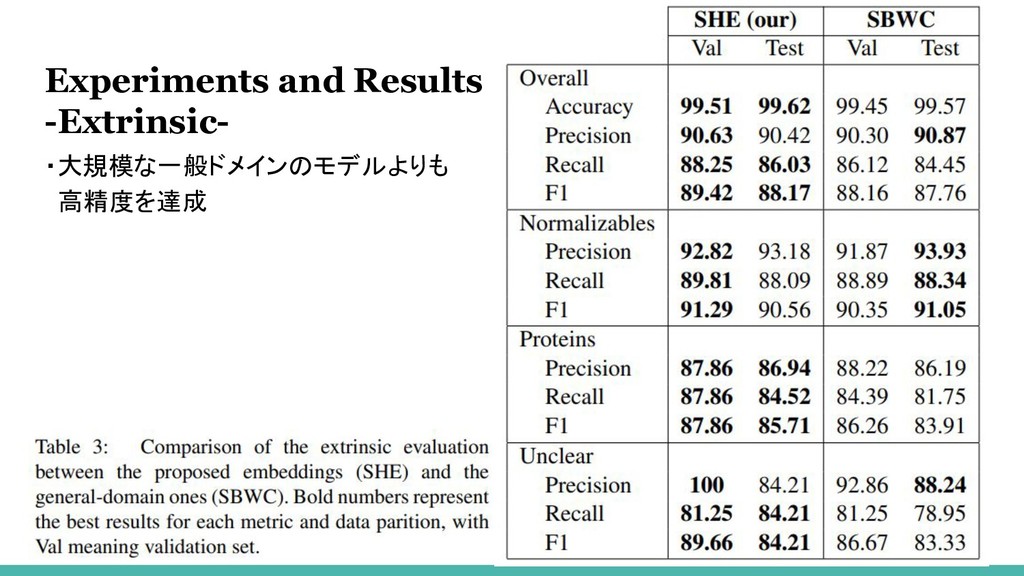
Experiments and Results -Extrinsic- 11 ・コーパスには4つのエンティティラベルが付与: タンパク質、正規化可能な化学物質、正規化できない化学物質、不明な言及 ・正規化できない化学物質についての言及の数 →非常に少ない 評価には含めない
12 ・大規模な一般ドメインのモデルよりも 高精度を達成 Experiments and Results -Extrinsic-
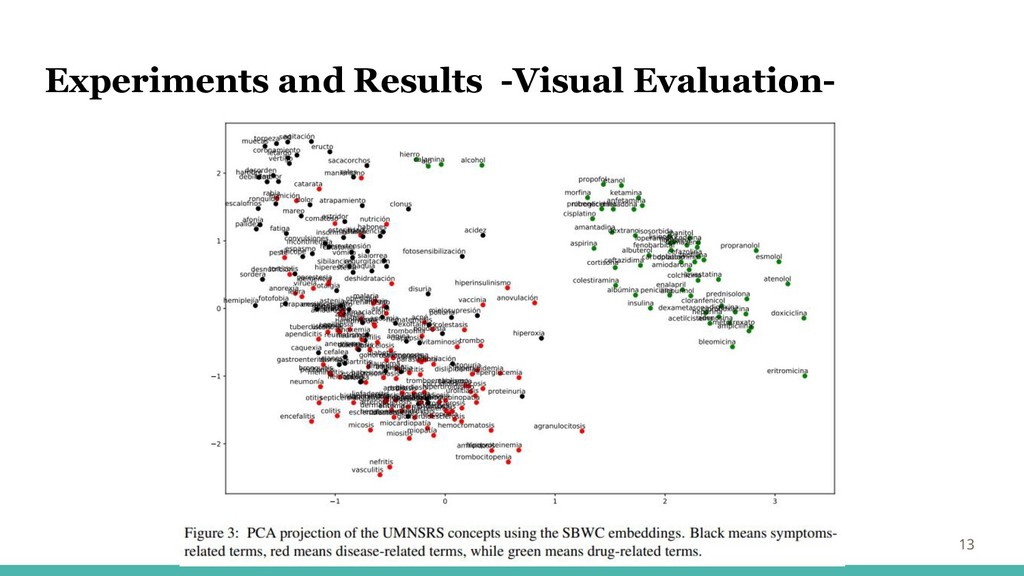
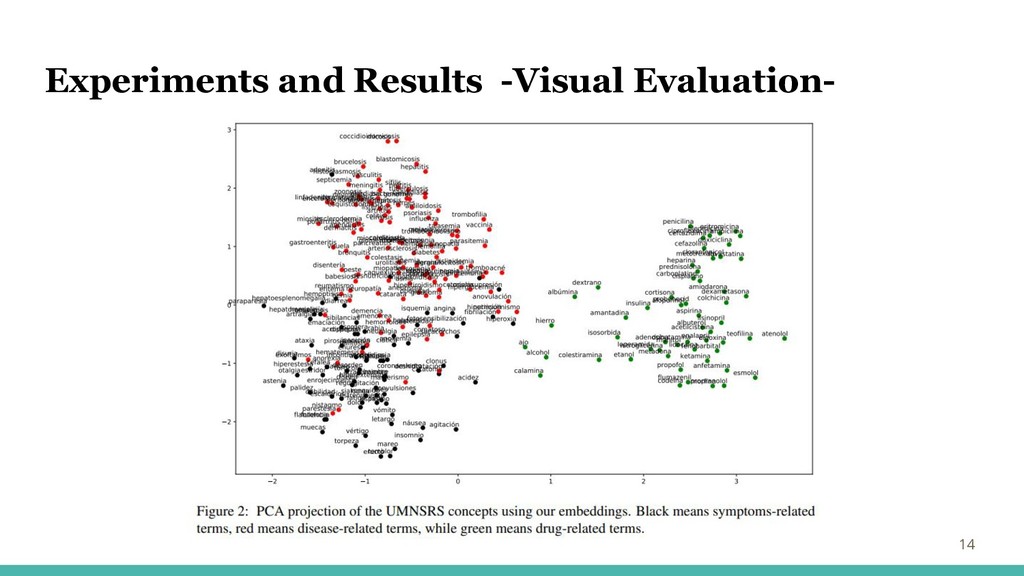
Experiments and Results -Visual Evaluation- 13
Experiments and Results -Visual Evaluation- 14
Discussion and Conclusion 15 ・スペイン語の生物医学ドメインの単語埋め込みについて学習・評価 ・本論文の埋め込みは、一般ドメインの大規模コーパスよりも優れた性能を達成 ・ドメイン内コーパスでトレーニングされたものがより明確に単語のマッピングできる ・スペイン語の医療ドメインの学習済みモデルを公開 ・英語のデータ・セットをスペイン語で活用
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}