Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
文献紹介_202002_Is artificial data useful for biome...
Search
T.Tada
February 10, 2020
Technology
75
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
文献紹介_202002_Is artificial data useful for biomedical Natural Language Processing algorithms?
T.Tada
February 10, 2020
More Decks by T.Tada
See All by T.Tada
文献紹介_202001_A Novel System for Extractive Clinical Note Summarization using EHR Data
tad
0
190
文献紹介_201912_Publicly Available Clinical BERT Embeddings
tad
0
180
文献紹介_201911_EDA: Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks
tad
0
230
文献紹介_201910_Do Neural NLP Models Know Numbers? Probing Numeracy in Embeddings
tad
0
110
文献紹介_201909_Sentence Mover’s Similarity_ Automatic Evaluation for Multi-Sentence Texts
tad
0
170
文献紹介_201908_Medical Word Embeddings for Spanish_ Development and Evaluation
tad
0
73
文献紹介_201907_Is Word Segmentation Necessary for Deep Learning of Chinese Representations
tad
0
120
文献紹介_201906_Predicting Annotation Difficulty to Improve Task Routing and Model Performance for Biomedical Information Extraction
tad
0
110
文献紹介201905_Context-Aware Cross-Lingual Mapping
tad
0
110
Other Decks in Technology
See All in Technology
5分でわかるDuckDB Quack
chanyou0311
4
260
Agile and AI Redmine Japan 2026
hiranabe
4
500
FPGAの開発コンペでZephyrを使ってみた
iotengineer22
0
220
時期が悪い!それでもRaspberry Piを買って遊んで活用するには / 20260627-osc26do-rpi-jikigawarui
akkiesoft
1
890
[チョークトーク資料]AWS DevOps Agent を使いこなす / AWS Dev Ops Agent Chalk Talk AWS Summit Japan 2026
kinunori
4
800
MySQL & MySQL HeatWave Report - June 2026
freshdaz
0
200
Oracle Cloud Infrastructure:2026年6月度サービス・アップデート
oracle4engineer
PRO
1
370
toB プロダクトから見たWAF
tokai235
0
250
「軸足」は 固定しなくていい - 熱量と強みで描く、しなやかなキャリアの形
kakehashi
PRO
1
280
【FinOps】データドリブンな意思決定を目指して
z63d
2
480
週末にループ・エンジニアリングの理解を深めるためのスライド
nagatsu
0
580
從觀望到全公司落地:AI Agentic Coding 導入實戰 — 流程整合與安全治理
appleboy
0
160
Featured
See All Featured
GraphQLの誤解/rethinking-graphql
sonatard
75
12k
10 Git Anti Patterns You Should be Aware of
lemiorhan
PRO
659
62k
エンジニアに許された特別な時間の終わり
watany
107
250k
Art, The Web, and Tiny UX
lynnandtonic
304
22k
Lessons Learnt from Crawling 1000+ Websites
charlesmeaden
PRO
1
1.3k
Evolution of real-time – Irina Nazarova, EuRuKo, 2024
irinanazarova
9
1.4k
Taking LLMs out of the black box: A practical guide to human-in-the-loop distillation
inesmontani
PRO
3
2.3k
A designer walks into a library…
pauljervisheath
211
24k
[SF Ruby Conf 2025] Rails X
palkan
2
1.1k
Paper Plane
katiecoart
PRO
1
52k
How to Get Subject Matter Experts Bought In and Actively Contributing to SEO & PR Initiatives.
livdayseo
0
140
The agentic SEO stack - context over prompts
schlessera
0
830
Transcript
- 文献紹介 2020 Feb. 10 - Is artificial data useful
for biomedical Natural Language Processing algorithms? 長岡技術科学大学 自然言語処理研究室 多田太郎
About the paper 2 Authors: Conference:
・Biomedical領域NLPの開発の主要な障害は、データへのアクセシビリティ ・臨床テキストの疑似データ生成方法を提案 ・生成したデータを使用し、テキスト分類と時間踏まえた関係抽出タスクで実験 ・疑似データによるNN手法の精度向上の可能性を示す ・擬似データのみをトレーニングデータに用いて有用性を確認 3 Abstract
・データ不足は、biomedical領域でのより強力な手法を用いるのに障害 ・疑似データによるデータセットの拡張は、biomedical領域のNLPでも注目される ▷通常の擬似データによる拡張は、20トークン以下の文での取り組みが多い ▷医療テキストを対象とする試みはほとんどない ・キーフレーズを使用して、疑似データを生成 ・生成されたデータのみをトレーニングデータに用い、擬似データの有用性を調査 4 Introduction
・擬似データの生成 1. 段落毎にでキーフレーズ抽出 2. 文レベルで、生成モデルへの入力 Transformerモデルを使用 3. 擬似データ生成 ・擬似データの評価 ▷内部評価
ROUGE-L, BLEU ▷外部評価 2タスクで実験(後述) 5 Methodology
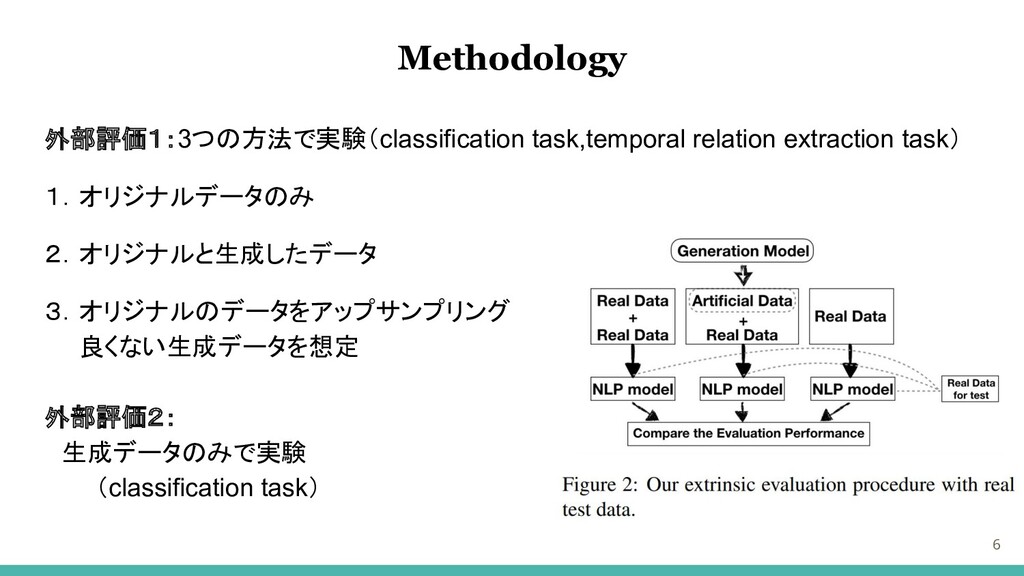
外部評価1:3つの方法で実験(classification task,temporal relation extraction task) 1.オリジナルデータのみ 2.オリジナルと生成したデータ 3.オリジナルのデータをアップサンプリング 良くない生成データを想定 外部評価2:
生成データのみで実験 (classification task) 6 Methodology
・MIMIC-IIIデータベースからのEHRを使用 ・ICUでの成人患者約5万人の匿名化された臨床データ テキスト生成のデータセット 退院サマリを使用 開発データ:126人の記録をランダムに選定 5ワード未満の長さの文は削除 7 Experimental Setup -Data-
表現型データセット 1,561人の患者の1,600件の退院サマリー(約180K文) 患者が病状を患っているか、発症するリスクがあるかを判断するタスク データセットには、13の表現型(例、進行がん、進行心臓病、進行肺疾患など) テスト:20% (test-pheno)、開発10% (dev-pheno)、 70%をトレーニングと疑似データ生成のテストに使用 (test-gen-pheno) 8
Experimental Setup -Data-
時間関係データセット 2012 i2b2 temporal relations shared task (Sun et al., 2013b)
190文書の退院サマリ 開発:10%(dev-temp)、 残りは疑似データのテストとトレーニングに使用(test-gen-temp) テスト:元々のデータのテスト 時間表現に関する病歴のイベントの相対的な順序を決定するタスク イベント(EVENT)、時間表現(TIMEEX3)、それらの時間的関係(TLINK)が注釈 この研究ではイベントが同時に起きているか(注釈された関係性の33%)を予測 頻度1の単語はプレースホルダーに 9 Experimental Setup -Data-
10 Experimental Setup -Text Generation Models- ・Transformerモデルを使用し、文生成 OpenNMTツールキット(Klein et al.,2017)
・抽出されたキーフレーズを用いて生成(キーフレーズはtrain-genから抽出) Rakeアルゴリズム(Rose et al., 2010)を使用 段落ごとに高いスコアから50%取得 ・各文から抽出されたキーフレーズを入力に 一文当たり平均2.4キーフレーズ、平均の長さ1.7語
11 Experimental Setup -Text Generation Models-
12 表現型分類タスク(binary classification task) 以下モデルで実験 ・CNN ・Naive Bayes classifier (ワードレベルのBoW)
Experimental Setup -Models for Phenotype Classification-
時間関係抽出 ・BiLSTM classifier pre-trained GloVe word embeddings ・Naive Bayes classifier
(ワードレベルのBoW) イベントとイベントごとにoverlapしているか否かの2値分類 13 Experimental Setup -Models for Temporal Relations Extraction-
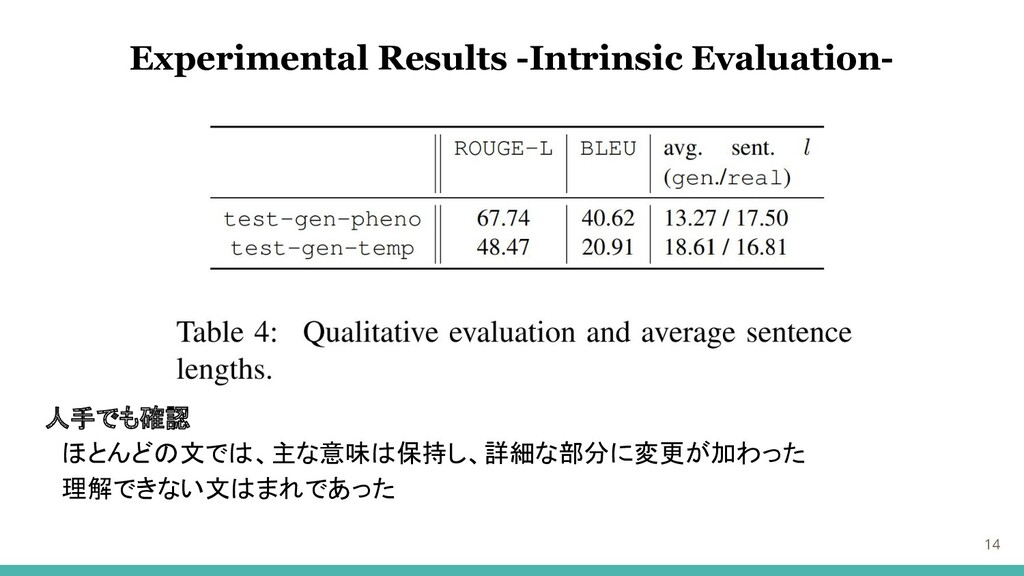
14 Experimental Results -Intrinsic Evaluation- 人手でも確認 ほとんどの文では、主な意味は保持し、詳細な部分に変更が加わった 理解できない文はまれであった
15 Experimental Setup -Text Generation Models-
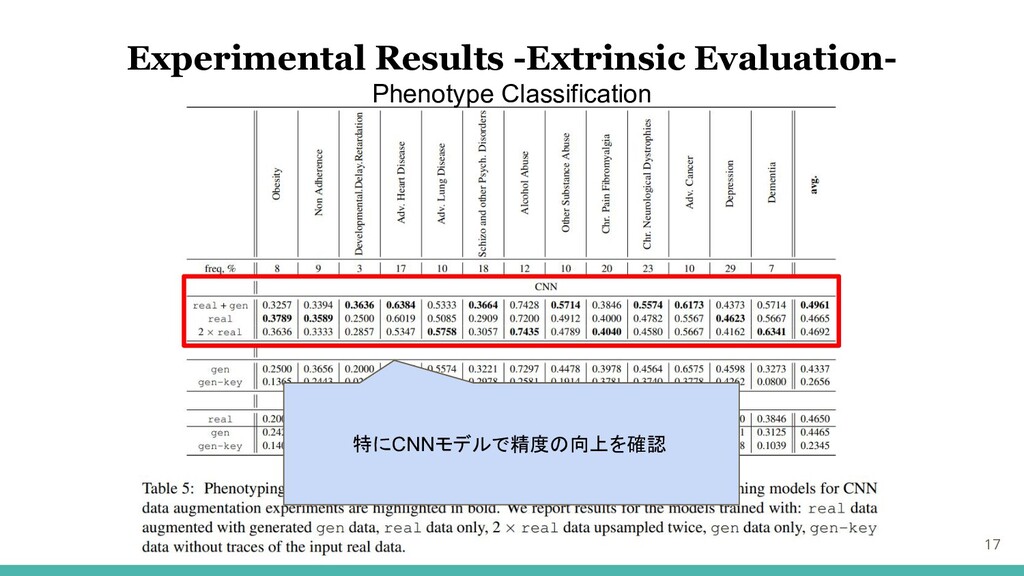
16 Experimental Results -Extrinsic Evaluation- Phenotype Classification
17 特にCNNモデルで精度の向上を確認 Experimental Results -Extrinsic Evaluation- Phenotype Classification
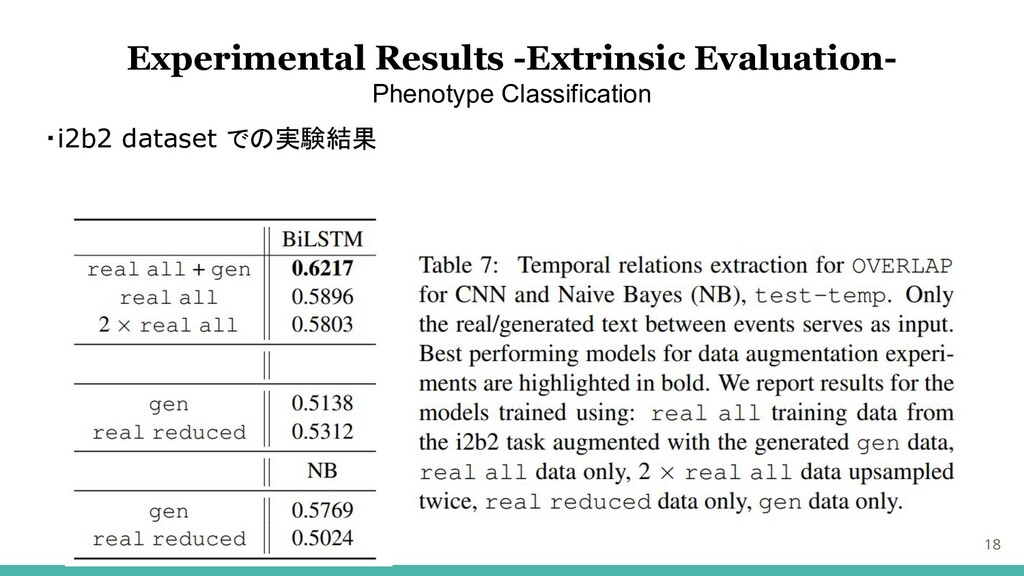
・i2b2 dataset での実験結果 18 Experimental Results -Extrinsic Evaluation- Phenotype Classification
・人手の分析から、生成されたテキストではほとんどの意味が保持 ・疑似データのみを使用した結果は、実際のデータのみを使用した結果と同等 ・本研究は、より長い臨床テキストを生成する問題を検討する最初の研究 ・疑似データを他の下流のタスクに使用する場合、生成されたテキストの臨床的 妥当性を評価するには、さらなる分析が必要 ▷特に臨床研究環境での二次利用をサポートすることを目的としたもの ・テキスト生成モデルを設計するための他のアプローチが必要 19 Discussion
・臨床テキストの疑似データ生成方法を提案 ・生成したデータを使用し、テキスト分類と時間関係抽出タスクで実験 ・疑似データによるNN手法の精度向上の可能性を示す ・擬似データのみをトレーニングデータに用いて有用性を確認 ・データのアクセシビリティの問題を解決するアプローチとなる可能性 20 Conclusion
・Rakeアルゴリズムの元論文 Automatic Keyword Extraction from Individual Documentshttps://www.researchgate.net/publication/227988510_Automatic_ Keyword_Extraction_from_Individual_Documents 21 参考
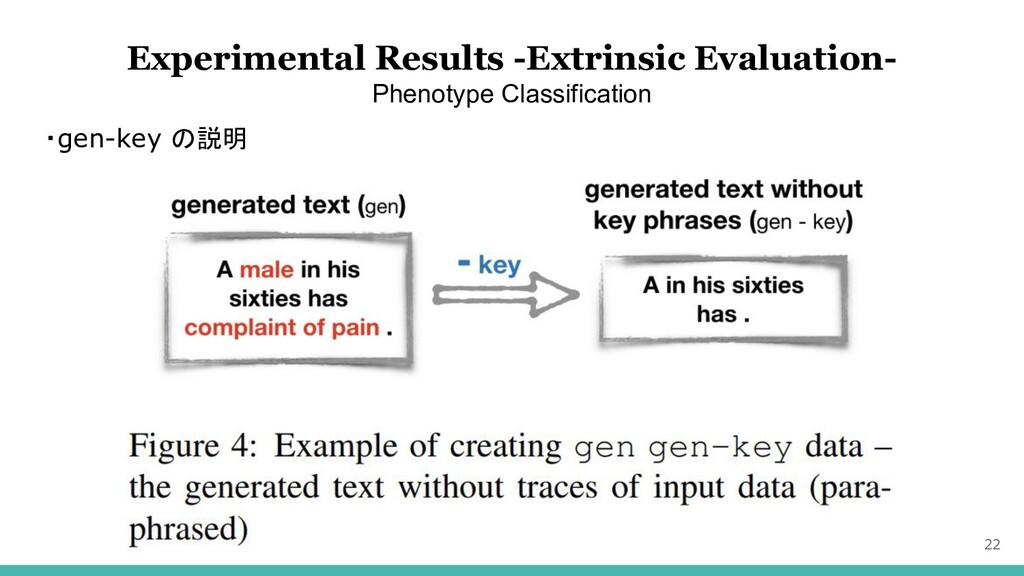
・gen-key の説明 22 Experimental Results -Extrinsic Evaluation- Phenotype Classification
・NBモデルでの重要単語 23 Experimental Results -Extrinsic Evaluation- Phenotype Classification
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}