Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
文献紹介_201911_EDA: Easy Data Augmentation Techniq...
Search
Sponsored
·
Ship Features Fearlessly
Turn features on and off without deploys. Used by thousands of Ruby developers.
→
T.Tada
November 28, 2019
Technology
230
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
文献紹介_201911_EDA: Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks
T.Tada
November 28, 2019
More Decks by T.Tada
See All by T.Tada
文献紹介_202002_Is artificial data useful for biomedical Natural Language Processing algorithms?
tad
0
75
文献紹介_202001_A Novel System for Extractive Clinical Note Summarization using EHR Data
tad
0
190
文献紹介_201912_Publicly Available Clinical BERT Embeddings
tad
0
180
文献紹介_201910_Do Neural NLP Models Know Numbers? Probing Numeracy in Embeddings
tad
0
110
文献紹介_201909_Sentence Mover’s Similarity_ Automatic Evaluation for Multi-Sentence Texts
tad
0
170
文献紹介_201908_Medical Word Embeddings for Spanish_ Development and Evaluation
tad
0
73
文献紹介_201907_Is Word Segmentation Necessary for Deep Learning of Chinese Representations
tad
0
120
文献紹介_201906_Predicting Annotation Difficulty to Improve Task Routing and Model Performance for Biomedical Information Extraction
tad
0
110
文献紹介201905_Context-Aware Cross-Lingual Mapping
tad
0
110
Other Decks in Technology
See All in Technology
Flow 不死:AI 時代 DevOps 的不變本質
cheng_wei_chen
2
550
水を運ぶ人としてのリーダーシップ
izumii19
4
1.1k
IaC コードを資産へ:AWS CDK 社内ライブラリと横断展開 / aws-summit-japan-2026
gotok365
10
1.6k
サイバーエージェントにおけるAI推進戦略と変革への取り組み
shotatsuge
0
610
Oracle Cloud Infrastructure:2026年6月度サービス・アップデート
oracle4engineer
PRO
1
370
「勝手に広まる」人気 AI エージェントを爆速で作ろう!(AWS Summit Japan 2026講演資料)
minorun365
PRO
10
2.6k
iOS アプリの「これって不具合ですか?」を AI に調べてもらう
miichan
0
150
SRE歴2ヶ月でも開発6年の知見を活かして、チームで止まっていた環境改善を前に進めた話
a_ono
0
100
Multi-Agent並列開発を 安全に回すための技術 / Technology for Safely Multi-Agent Parallel Development
tooppoo
0
220
40代で“やっとエンジニアになれた”――閉じた学びを開き、空の青さを知る / 20260628 Naoki Takahashi
shift_evolve
PRO
4
1.1k
AWS Summit の片隅で、体育座りしながらコミュニティがにぎわう理由を考えた
k_adachi_01
2
150
FPGAの開発コンペでZephyrを使ってみた
iotengineer22
0
220
Featured
See All Featured
Speed Design
sergeychernyshev
33
1.9k
Designing for Performance
lara
611
70k
Jess Joyce - The Pitfalls of Following Frameworks
techseoconnect
PRO
1
170
Code Reviewing Like a Champion
maltzj
528
40k
How to build a perfect <img>
jonoalderson
1
5.7k
Thoughts on Productivity
jonyablonski
76
5.2k
Templates, Plugins, & Blocks: Oh My! Creating the theme that thinks of everything
marktimemedia
31
2.8k
The untapped power of vector embeddings
frankvandijk
2
1.8k
Exploring anti-patterns in Rails
aemeredith
3
430
世界の人気アプリ100個を分析して見えたペイウォール設計の心得
akihiro_kokubo
PRO
72
40k
AI Search: Where Are We & What Can We Do About It?
aleyda
0
7.6k
What Being in a Rock Band Can Teach Us About Real World SEO
427marketing
0
1k
Transcript
- 文献紹介 2019 Nov. 28 - EDA: Easy Data Augmentation
Techniques for Boosting Performance on Text Classification Tasks 長岡技術科学大学 自然言語処理研究室 多田太郎
About the paper 2 Authors: Conference:
Abstract ・EDA: Easy Data Augmentation を提案 ・文に4種類の編集を行ないデータを拡張 ・ローリソース(データセットが小規模)なタスクに対して強力 ・トレーニングセット100%使用時の精度を50%のデータ+EDAで達成 3
Introduction ・テキスト分類の精度は、トレーニングデータのサイズと質に依存している ・データの拡張により、より堅牢なモデルを得られる ・折り返し翻訳、ノイズを加える、言語モデルを使った同義語置換などがある →有効だがコストが高い ・シンプルかつ言語を問わないデータ拡張を提案 4
EDA 5 トレーニングデータの特定の文に以下4つのいずれかの操作をランダムに実施 ・Synonym Replacement (SR): 文からn単語(ストップワードでない)をランダムで選択 各単語をランダムに選ばれた同義語と置き換え ・Random Insertion
(RI): 文中のランダムな単語(ストップワードでない)のランダムな同義語を取得 文のランダムな位置に挿入 この作業をn回行なう これは先行研究でやってる
EDA 6 トレーニングデータの特定の文に以下4つのいずれかの操作をランダムに実施 ・Random Swap (RS): 文からランダムに2単語を選択し入れ替え この作業をn回行なう ・Random Deletion
(RD): 確率pで文の各単語を削除(pの値は後述)
EDA 7 長い文は多くのノイズを含む可能性がある バランスをとるため変更する単語数nを定める α:文内の変更する単語の割合を示すパラメータ(RDのp=a) l :文の長さ n = αl
EDA 8
Experimental Setup 9 5つのテキスト分類のベンチマークタスクで実験 EDAは小規模なデータセットでより役立つと想定される →トレーニングデータの量を変更し実験(LSTMとCNNを使用)
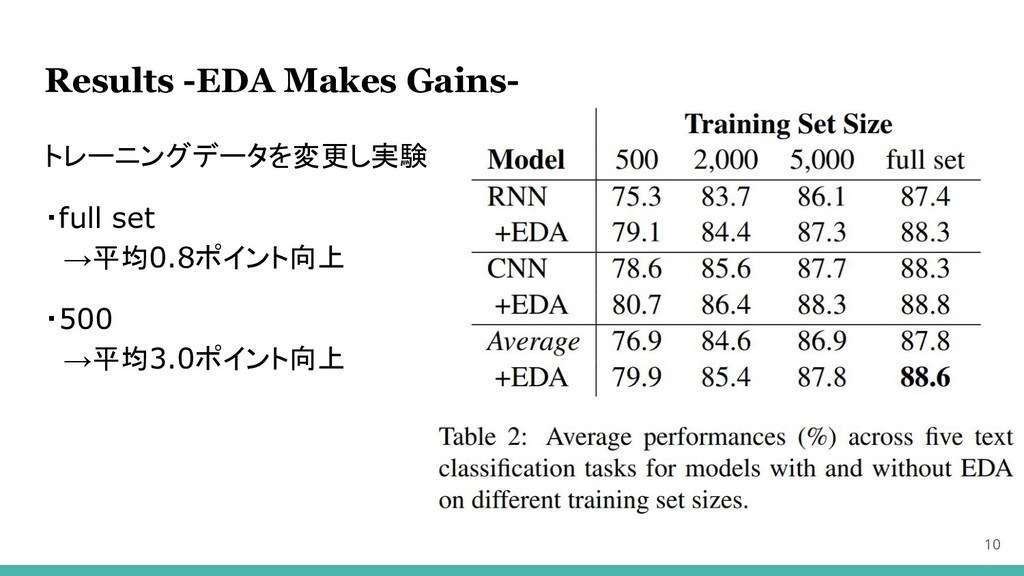
Results -EDA Makes Gains- 10 トレーニングデータを変更し実験 ・full set →平均0.8ポイント向上 ・500
→平均3.0ポイント向上
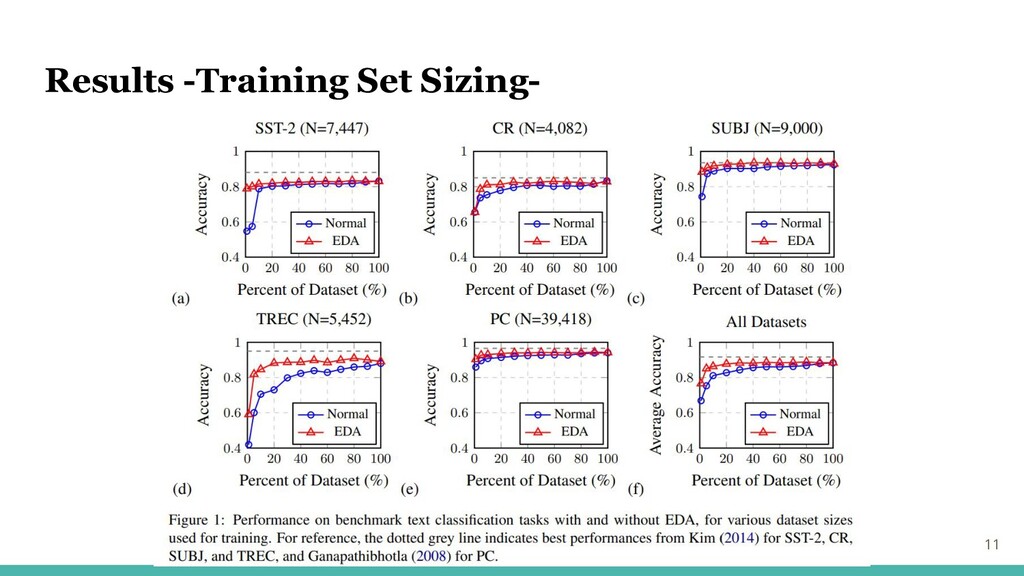
Results -Training Set Sizing- 11
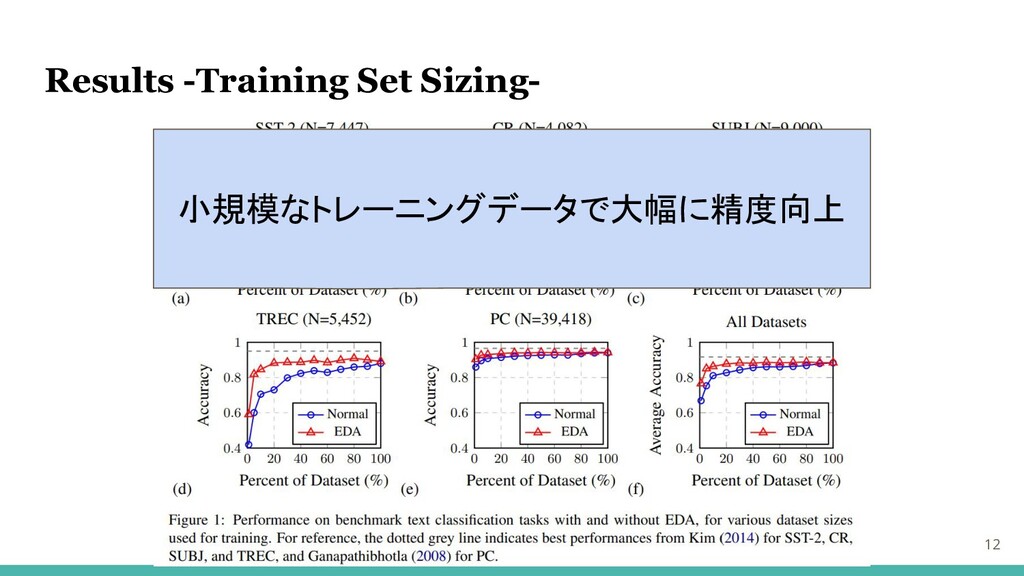
Results -Training Set Sizing- 12 小規模なトレーニングデータで大幅に精度向上
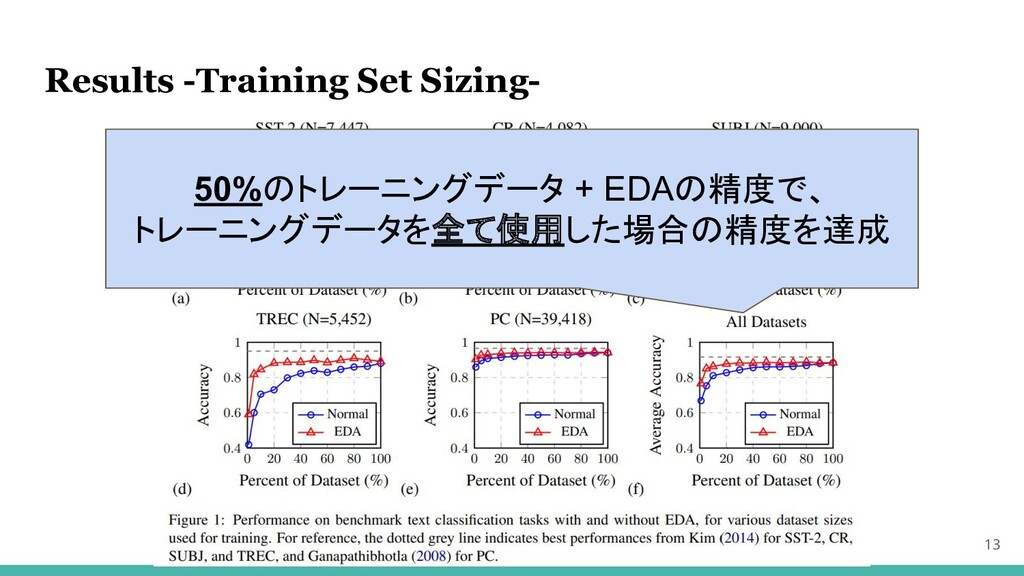
Results -Training Set Sizing- 13 50%のトレーニングデータ + EDAの精度で、 トレーニングデータを全て使用した場合の精度を達成
Results -Does EDA conserve true labels?- 14 操作をして拡張した文の分類クラスは変わらない? ・データの拡張をしない状態のPCタスク(2値)でLSTMをトレーニング ・EDAでテストデータの各文に対し、9つ拡張文を生成し実験
Results -Does EDA conserve true labels?- 15 ほとんど場合で拡張された文が元のラベルと同じ
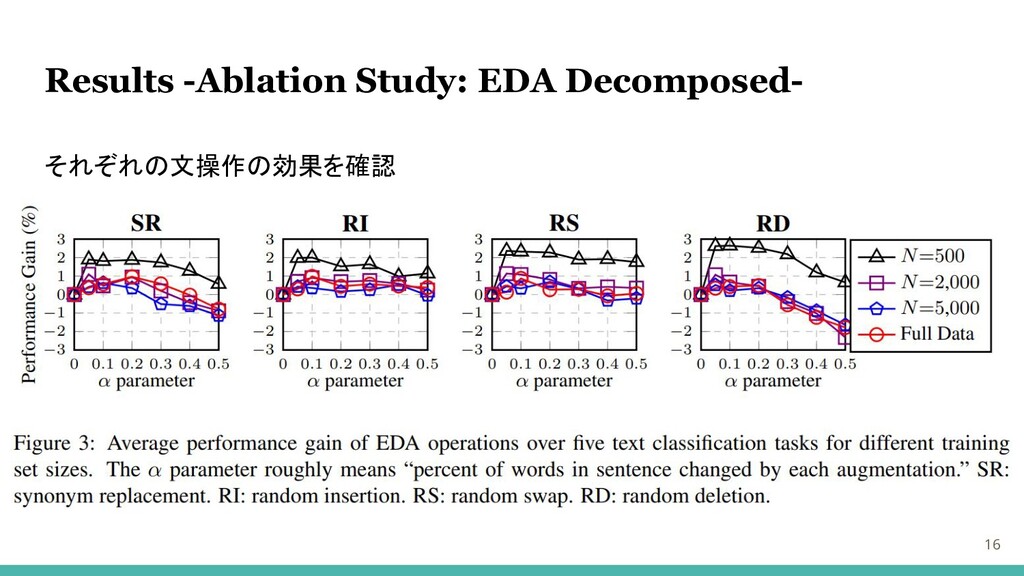
Results -Ablation Study: EDA Decomposed- 16 それぞれの文操作の効果を確認
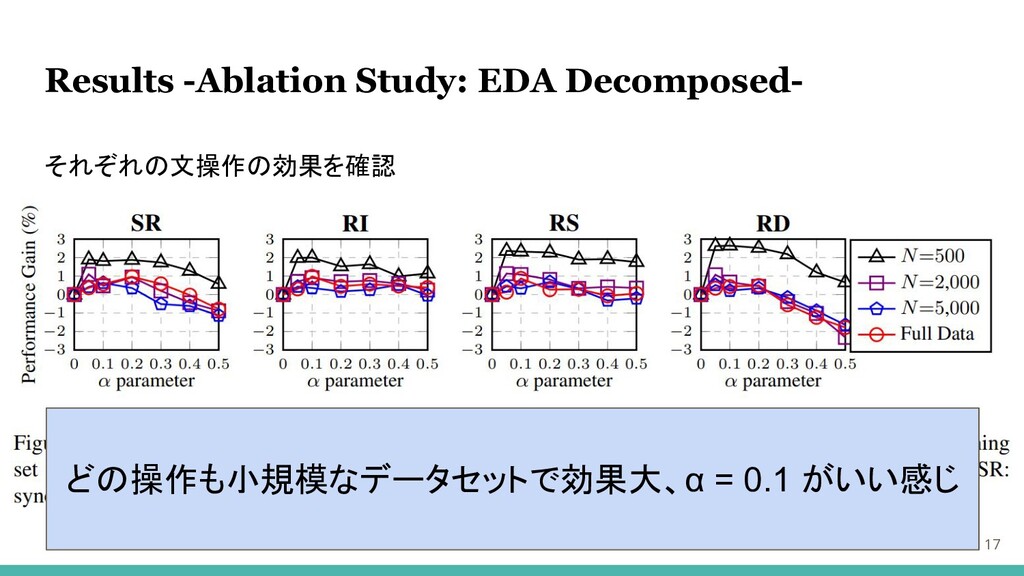
Results -Ablation Study: EDA Decomposed- 17 それぞれの文操作の効果を確認 どの操作も小規模なデータセットで効果大、α = 0.1
がいい感じ
Results -How much augmentation?- 18 どのくらい文を増やすべきか
Results -How much augmentation?- 19 どのくらい文を増やすべきか このくらいが良いらしい
Comparison with Related Work 20 EDAは言語モデルも外部データも必要としない
Discussion and Limitations 21 EDAの限界 ・データの量が十分な場合に精度の向上はわずか ・pre-train モデルを使用する場合、大幅な貢献はもたらさない しかし、NNモデルを大きく複雑にしていく高コストな手法は避けたい
Conclusions 22 ・シンプルかつ低コストなデータ拡張手法を提案 ・5つの分類タスクで精度向上 ・小規模なトレーニングセットでは精度の貢献も大きく、過学習を避けられる
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}