Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
文献紹介_201910_Do Neural NLP Models Know Numbers? ...
Search
Sponsored
·
Ship Features Fearlessly
Turn features on and off without deploys. Used by thousands of Ruby developers.
→
T.Tada
October 28, 2019
Technology
110
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
文献紹介_201910_Do Neural NLP Models Know Numbers? Probing Numeracy in Embeddings
T.Tada
October 28, 2019
More Decks by T.Tada
See All by T.Tada
文献紹介_202002_Is artificial data useful for biomedical Natural Language Processing algorithms?
tad
0
75
文献紹介_202001_A Novel System for Extractive Clinical Note Summarization using EHR Data
tad
0
190
文献紹介_201912_Publicly Available Clinical BERT Embeddings
tad
0
180
文献紹介_201911_EDA: Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks
tad
0
230
文献紹介_201909_Sentence Mover’s Similarity_ Automatic Evaluation for Multi-Sentence Texts
tad
0
170
文献紹介_201908_Medical Word Embeddings for Spanish_ Development and Evaluation
tad
0
73
文献紹介_201907_Is Word Segmentation Necessary for Deep Learning of Chinese Representations
tad
0
120
文献紹介_201906_Predicting Annotation Difficulty to Improve Task Routing and Model Performance for Biomedical Information Extraction
tad
0
110
文献紹介201905_Context-Aware Cross-Lingual Mapping
tad
0
110
Other Decks in Technology
See All in Technology
技術・能力を向上する原理原則 #きのこセッションa #きのこ2026
bash0c7
0
140
水を運ぶ人としてのリーダーシップ
izumii19
4
1.1k
AI-DLCを “そのまま導入しなかった”話 ~組織に合わせてアジャストした 私たちの実践共有~
hiroramos4
PRO
1
440
起点・思考・出力で分解する 〜PM業務の自動化設計〜
kazu_kichi_67
2
1.1k
サイバーエージェントにおけるAI推進戦略と変革への取り組み
shotatsuge
0
610
Hatena Engineer Seminar 37 jj1uzh
jj1uzh
0
150
いまさら聞けない「仕様駆動開発入門」 〜AI活用時代の開発プロセスを考える〜
findy_eventslides
2
230
從觀望到全公司落地:AI Agentic Coding 導入實戰 — 流程整合與安全治理
appleboy
0
160
徹底討論!ECS vs EKS!
daitak
3
1.8k
「勝手に広まる」人気 AI エージェントを爆速で作ろう!(AWS Summit Japan 2026講演資料)
minorun365
PRO
10
2.6k
Agile and AI Redmine Japan 2026
hiranabe
4
500
ぼっちではじめた登壇が「51名」「241件」の発信に化けた
subroh0508
1
330
Featured
See All Featured
Agile that works and the tools we love
rasmusluckow
331
22k
StorybookのUI Testing Handbookを読んだ
zakiyama
31
6.8k
brightonSEO & MeasureFest 2025 - Christian Goodrich - Winning strategies for Black Friday CRO & PPC
cargoodrich
3
740
GitHub's CSS Performance
jonrohan
1033
470k
Improving Core Web Vitals using Speculation Rules API
sergeychernyshev
21
1.5k
Build The Right Thing And Hit Your Dates
maggiecrowley
39
3.2k
実際に使うSQLの書き方 徹底解説 / pgcon21j-tutorial
soudai
PRO
201
75k
Sharpening the Axe: The Primacy of Toolmaking
bcantrill
46
2.9k
Large-scale JavaScript Application Architecture
addyosmani
515
110k
The B2B funnel & how to create a winning content strategy
katarinadahlin
PRO
1
400
Cheating the UX When There Is Nothing More to Optimize - PixelPioneers
stephaniewalter
287
14k
How STYLIGHT went responsive
nonsquared
100
6.2k
Transcript
- 文献紹介 2019 Oct. 28 - Do Neural NLP Models
Know Numbers? Probing Numeracy in Embeddings 長岡技術科学大学 自然言語処理研究室 多田太郎
About the paper 2 Authors: Conference: EMNLP2019 (https://arxiv.org/abs/1909.07940)
Abstract ・複雑な推論タスクでは、数字を理解して扱うことが重要 ・現在、ほとんどのNLPモデルは、テキスト内の数値を他のトークンと同じ方法で処理 ・数値推論が含まれるタスクのSOTAモデルを検証 →数値をどう扱うのが良いのか調査 3
Introduction ・既存のモデルは複雑な推論を行なうことができない(特に数値) ・最近のいくつかのデータ・セットには数値の比較やソート等を必要とする例が含まれる ・最初のステップとして数値の大小関係を理解する必要がある ex. 「23」が「twenty-two」より大きい値を表すこと ・既存のニューラルモデルがどのくらい、どのように数値について学習しているか調査 4
Numeracy Case Study: DROP QA 5 数値推論を必要とするタスクを用いて既存モデルを検証 ・DROP Dataset: カウント、ソート、加算などの数値推論が含まれる
・モデル: NAQANet (Dua et al., 2019) ※DROPのSOTAモデル 数値の大きさや、明示的な比較を実行するための補助コンポーネントは含まれていない 計算能力を必要とする質問、比較の質問と最上級を答える質問に焦点を当てる
Numeracy Case Study: DROP QA 6 DROP Datasetの一例
Numeracy Case Study: DROP QA 7 比較および最上級の質問 大小関係、どちらかなど(DROP Dataset のvalidation
set をフィルタリングし使用)
Numeracy Case Study: DROP QA 8 さっきの例だと、、、 Which player had
a touchdown longer than 20 yards? (1)すべてのタッチダウン距離を抽出 (2)20ヤード超え (3)タッチダウンしたプレーヤー 複数の手順が必要となるタスクで精度低 →タスク自体が難しい
Numeracy Case Study: DROP QA 9 NAQANetによって正しく回答された例(最上級の質問) 結構出来てる!!
Numeracy Case Study: DROP QA 10 どこまで出来るのか?ストレステスト ・大きい数値: 正のランダムな整数を生成し、その値を各パラグラフの数値に乗算または加算 ・単語形式:
パラグラフ内のすべての数字を置き換え(例:「75」→「seventy-five」) DROP内の数値は小さいため、範囲[0, 100]の整数の単語置換で実施
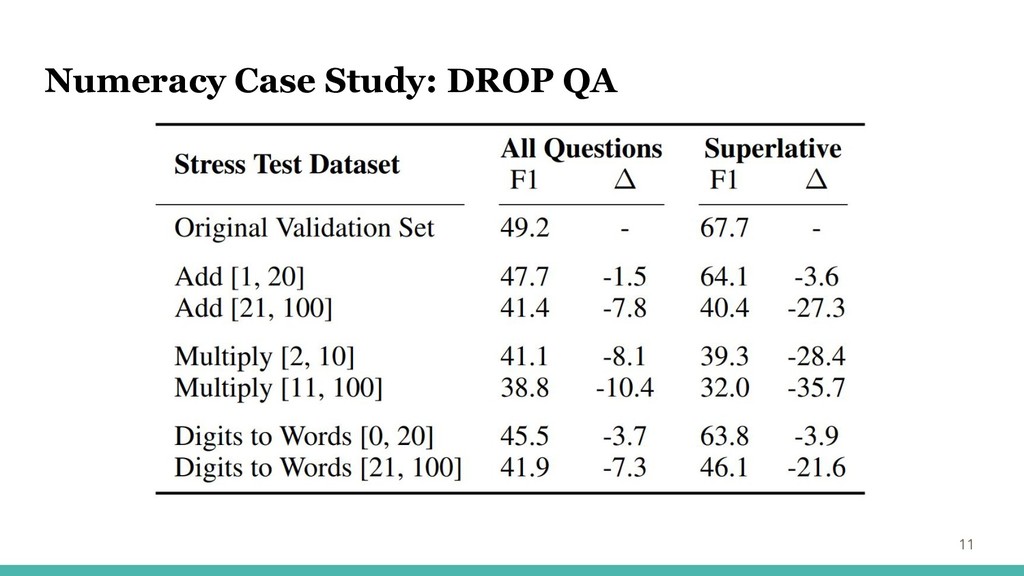
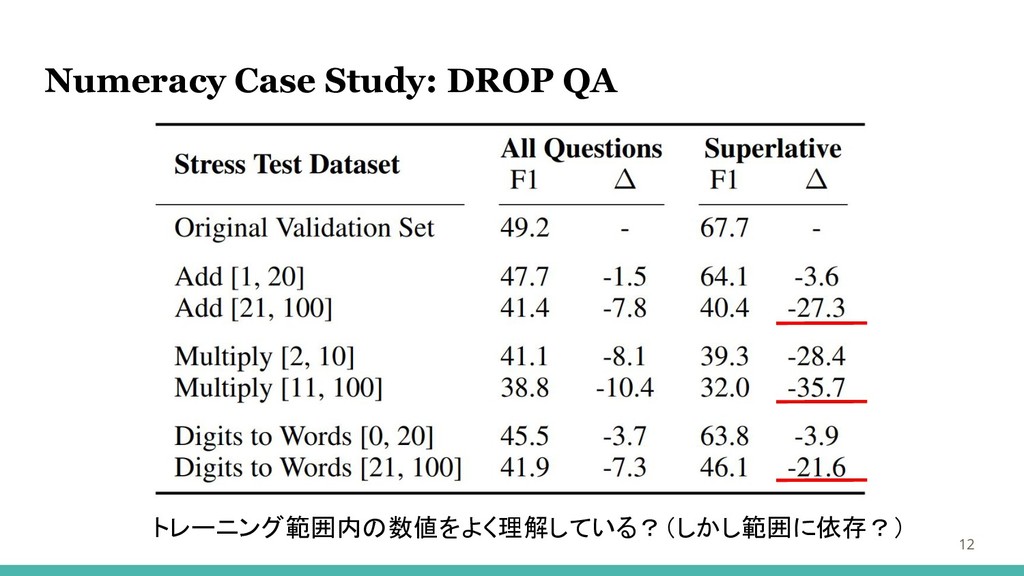
Numeracy Case Study: DROP QA 11
Numeracy Case Study: DROP QA 12 トレーニング範囲内の数値をよく理解している?(しかし範囲に依存?)
Numeracy Case Study: DROP QA 13 NAQANetは、期待以上の数値推論機能を備えていた →この精度を可能にするものは何か? 結果はモデルが以下2点を学習できることを示している 比較アルゴリズム
質問と回答(教師データ)のみから数値の読み取りと理解 数値情報のソースはトークンの埋め込み →つまりNAQANetモデルの文字レベルの畳み込みとGloVeの埋め込み →これらの埋め込みについて調査
Probing Numeracy of Embeddings 14 数について評価するために3つのタスクを実施
Probing Numeracy of Embeddings 15 Training and Evaluation ・トレーニング範囲内の値での精度をみる ・最初に範囲を選択し(実験毎に範囲指定)、指定整数の範囲をシャッフル
・80%をトレーニングセット、20%をテストセットに分割
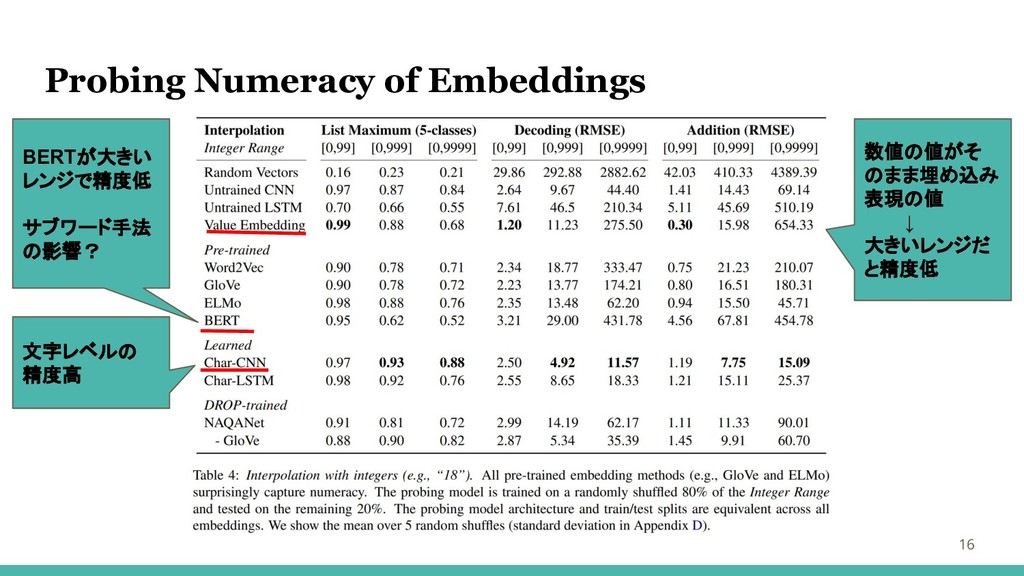
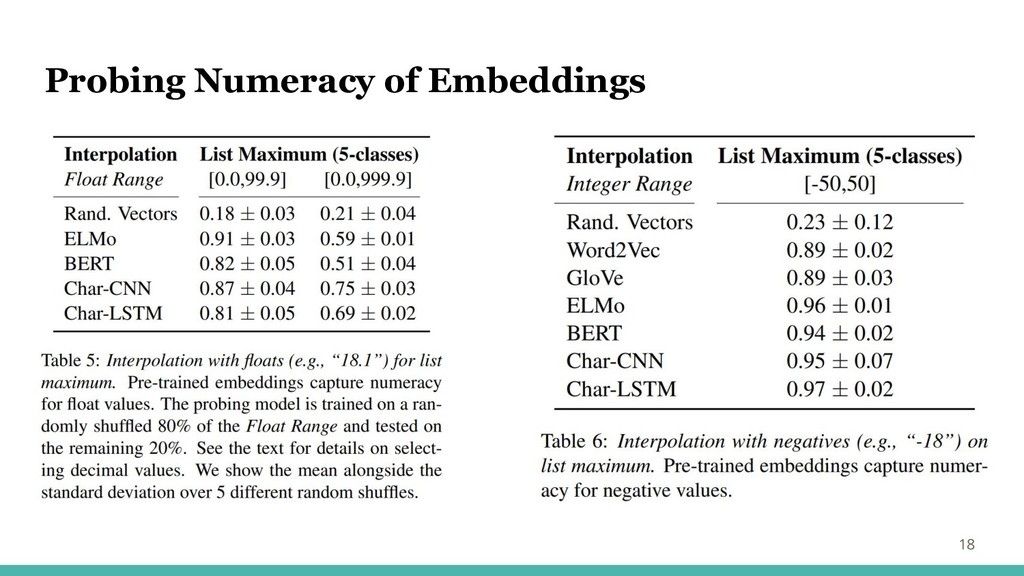
Probing Numeracy of Embeddings 16 文字レベルの 精度高 BERTが大きい レンジで精度低 サブワード手法
の影響? 数値の値がそ のまま埋め込み 表現の値 ↓ 大きいレンジだ と精度低
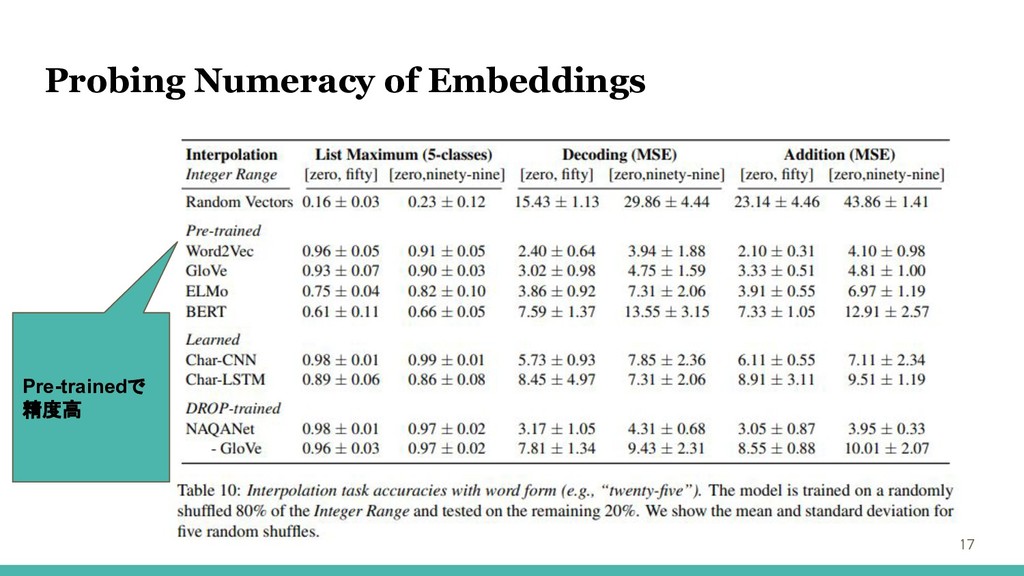
Probing Numeracy of Embeddings 17 Pre-trainedで 精度高
Probing Numeracy of Embeddings 18
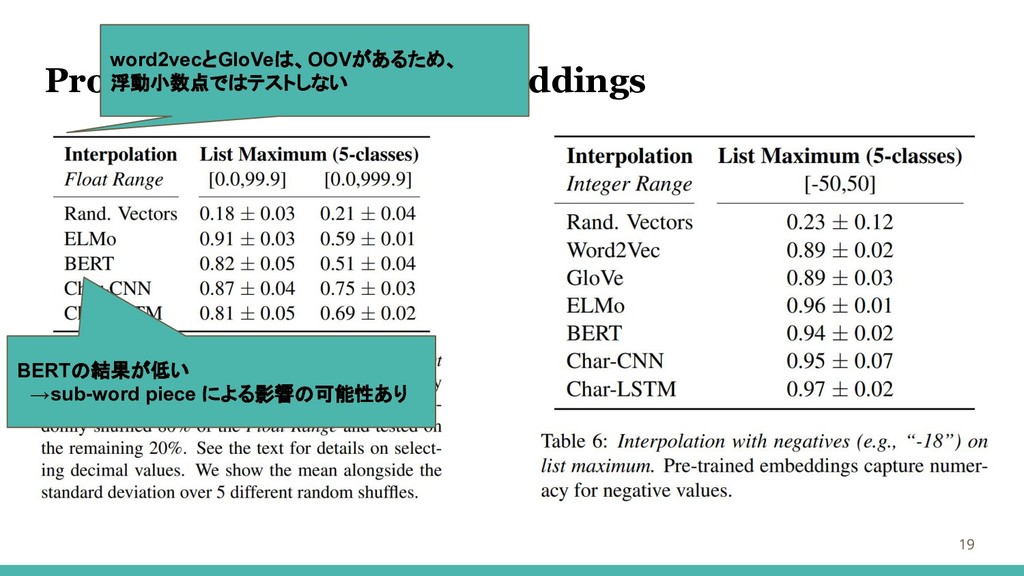
Probing Numeracy of Embeddings 19 BERTの結果が低い →sub-word piece による影響の可能性あり word2vecとGloVeは、OOVがあるため、
浮動小数点ではテストしない
Probing Numeracy of Embeddings 20 NAQANet の実験でトレーニング範囲外の値に苦労している結果がみられた →NAQANet 特性か、一般的な問題か? トレーニングの範囲外の値に対して実験を行い検証
冒頭のNAQANetでの 実験結果の解析
Probing Numeracy of Embeddings 21 トレーニングの範囲外の値でList Maximum トレーニング: [0,150] テスト:
[151,160], [151,180], [151,200] 全ての手法で、精度が下がる結果 特にトークンベクトルで大きく下がった
Probing Numeracy of Embeddings 22 トレーニングの範囲外の値でDecoding と Addition トレーニング:[-500,500](青) テスト:[2000、2000](赤)
どの埋め込み方法も範囲外の 値には対応出来ず
Probing Numeracy of Embeddings 23 トレーニングの範囲外の値でDecoding と Addition トレーニング:[-500,500](青) テスト:[2000、2000](赤)
どの埋め込み方法も範囲外の 値には対応出来ず Trask et al. (2018) でもモデルがトレーニング範囲外の値への対応が難しいこと に触れている →彼らはニューラルモデル自体に起因すると考察している
Probing Numeracy of Embeddings 24 範囲外の値を補う疑似データ トレーニングデータの例を複製し、冒頭の実験で行なった加算および乗算の手法を使用
Conclusion 25 ・DROPデータ・セットを用いて既存モデルの数字の学習について調査 (DROPのSOTAモデルと各種分散表現モデル) ・Pretrained Embeddingsが自然に数値(単語→数字)をエンコードすることを確認 ・トレーニングデータ外の値をニューラルモデルで推定することは困難
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Probing Numeracy of Embeddings 21 トレーニングの範囲外の値でList Maximum トレーニング: [0,150] テスト:](https://files.speakerdeck.com/presentations/744c98975a80405c9d8aa33b37aea95f/slide_20.jpg){kind=link}
 テスト:[2000、2000](赤)](https://files.speakerdeck.com/presentations/744c98975a80405c9d8aa33b37aea95f/slide_21.jpg){kind=link}
 テスト:[2000、2000](赤)](https://files.speakerdeck.com/presentations/744c98975a80405c9d8aa33b37aea95f/slide_22.jpg){kind=link}
{kind=link}
{kind=link}