Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
文献紹介_201912_Publicly Available Clinical BERT Em...
Search
Sponsored
·
SiteGround - Reliable hosting with speed, security, and support you can count on.
→
T.Tada
December 16, 2019
Technology
180
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
文献紹介_201912_Publicly Available Clinical BERT Embeddings
T.Tada
December 16, 2019
More Decks by T.Tada
See All by T.Tada
文献紹介_202002_Is artificial data useful for biomedical Natural Language Processing algorithms?
tad
0
75
文献紹介_202001_A Novel System for Extractive Clinical Note Summarization using EHR Data
tad
0
190
文献紹介_201911_EDA: Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks
tad
0
230
文献紹介_201910_Do Neural NLP Models Know Numbers? Probing Numeracy in Embeddings
tad
0
110
文献紹介_201909_Sentence Mover’s Similarity_ Automatic Evaluation for Multi-Sentence Texts
tad
0
170
文献紹介_201908_Medical Word Embeddings for Spanish_ Development and Evaluation
tad
0
73
文献紹介_201907_Is Word Segmentation Necessary for Deep Learning of Chinese Representations
tad
0
120
文献紹介_201906_Predicting Annotation Difficulty to Improve Task Routing and Model Performance for Biomedical Information Extraction
tad
0
110
文献紹介201905_Context-Aware Cross-Lingual Mapping
tad
0
110
Other Decks in Technology
See All in Technology
クラウドファンディング版StackChan 3体(4体)をインタラクティブな体験型作品にして展示もした話 / スタックチャンお誕生日会2026
you
PRO
0
220
[チョークトーク資料]AWS DevOps Agent を使いこなす / AWS Dev Ops Agent Chalk Talk AWS Summit Japan 2026
kinunori
4
800
コミュニティの有益性 ~JAWS Days 2026 での体験を通して~ / The Benefits of a Community ~Through My Experience at JAWS Days 2026~
seike460
PRO
0
300
起点・思考・出力で分解する 〜PM業務の自動化設計〜
kazu_kichi_67
2
1.1k
從開發到部署全都交給 AI:實作 AI 驅動的自動化流程
appleboy
0
180
Oracle Cloud Infrastructure:2026年6月度サービス・アップデート
oracle4engineer
PRO
1
370
組織における AI-DLC 実践
askul
0
150
5分でわかる Amazon Connect_20260608
hwangbyeonghun
0
130
MySQL & MySQL HeatWave Report - June 2026
freshdaz
0
200
アラート調査向けAIエージェントの本番導入とその後/AI Agents for Alert Investigation: Production Deployment and After
taddy_919
1
250
クレデンシャル流出 ― 攻撃 3 時間 vs 復旧 10 時間。この非対称性にどう備えるか
kazzpapa3
3
620
いまさら聞けない「仕様駆動開発入門」 〜AI活用時代の開発プロセスを考える〜
findy_eventslides
2
230
Featured
See All Featured
<Decoding/> the Language of Devs - We Love SEO 2024
nikkihalliwell
1
260
Design and Strategy: How to Deal with People Who Don’t "Get" Design
morganepeng
133
19k
Getting science done with accelerated Python computing platforms
jacobtomlinson
2
240
The Myth of the Modular Monolith - Day 2 Keynote - Rails World 2024
eileencodes
28
3.5k
Jess Joyce - The Pitfalls of Following Frameworks
techseoconnect
PRO
1
170
Discover your Explorer Soul
emna__ayadi
2
1.1k
The Cult of Friendly URLs
andyhume
79
6.9k
The AI Search Optimization Roadmap by Aleyda Solis
aleyda
1
5.9k
Fight the Zombie Pattern Library - RWD Summit 2016
marcelosomers
234
17k
Applied NLP in the Age of Generative AI
inesmontani
PRO
4
2.3k
16th Malabo Montpellier Forum Presentation
akademiya2063
PRO
0
150
Redefining SEO in the New Era of Traffic Generation
szymonslowik
1
350
Transcript
- 文献紹介 2019 Dec. 16 - Publicly Available Clinical BERT
Embeddings 長岡技術科学大学 自然言語処理研究室 多田太郎
About the paper 2 Authors: Conference:
・文脈を考慮した単語埋め込みモデル(ELMoやBERTなど)は、特定分野では 限定的にしか検討されていない ・臨床テキスト用のBERTモデルを調査および公開 一般的な臨床テキスト向けと退院サマリー向け ・提案モデルは、3つの臨床分野NLPタスクで精度高 3 Abstract
・ELMoやBERTなどの文脈を考慮した埋め込み表現はNLPで成功 ・臨床テキストは、一般テキストや非臨床的な生物医学テキストと異なる 臨床分野のBERTモデルの必要性 ・しかし、計算コストが膨大 学習済みモデルを構築し、公開 4 Introduction
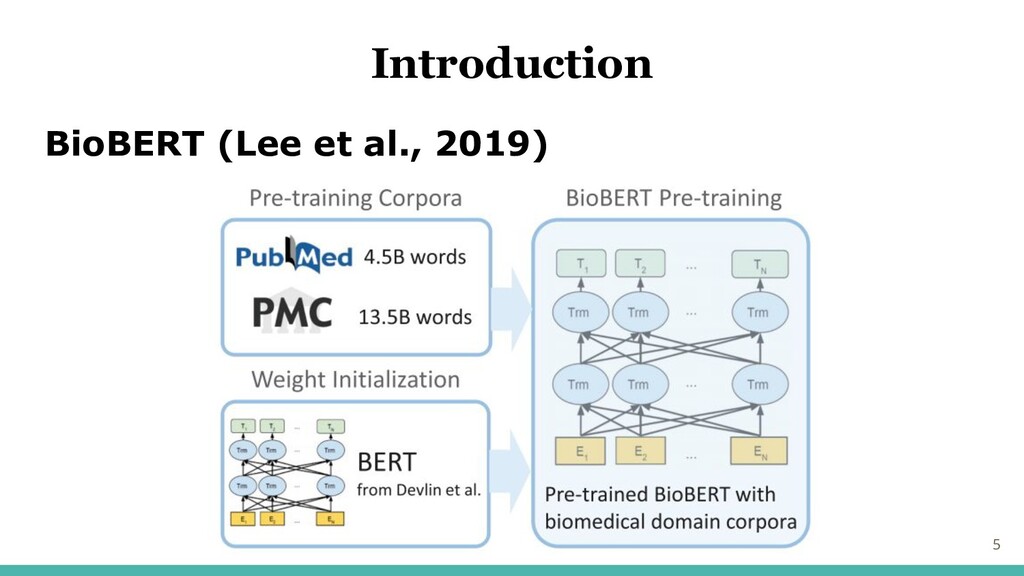
BioBERT (Lee et al., 2019) 5 Introduction
・Data: MIMIC-III v1.4データベースの約200万件の臨床テキスト ・Train: 2種 ・全てのノートタイプのテキストを使用 ・ダウンストリームタスクを考慮、退院サマリーのみを使用 ・Model: 2種 1)Clinical BERT: BERTBaseを初期化し学習 2)Clinical BioBERT: BioBERTから初期化し学習
・計算コスト: GeForce GTX TITAN X 12 GB で約18日 6 Method
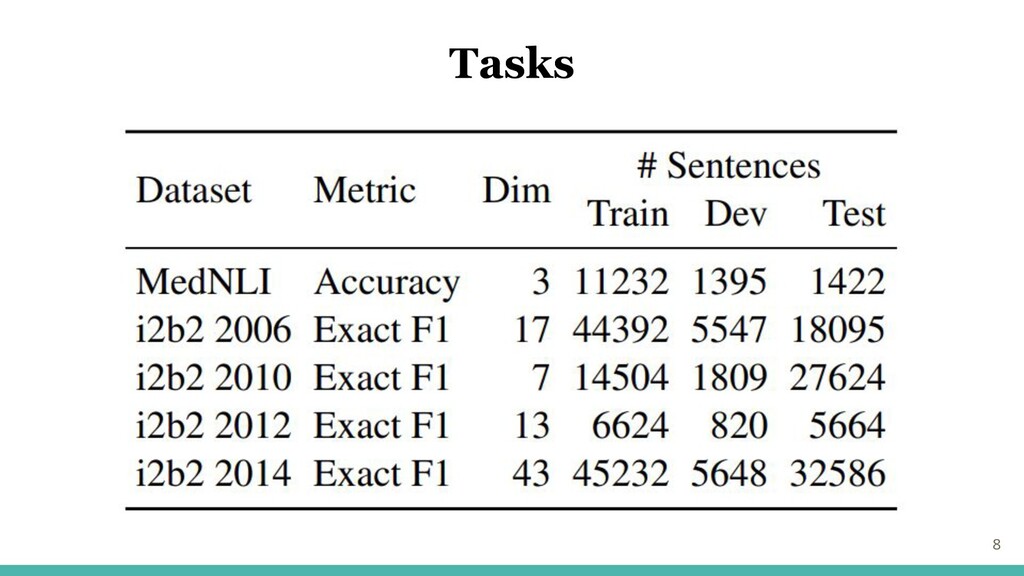
・5つのタスクで評価 MedNLI: 自然言語推論タスク 4つのi2b2のNERタスク 2006: 1B 匿名化タスク 2010: 概念抽出タスク 2012: エンティティ抽出チャレンジ 2014: 7A 匿名化チャレンジ ・最近傍の単語を確認 7 Tasks
8 Tasks
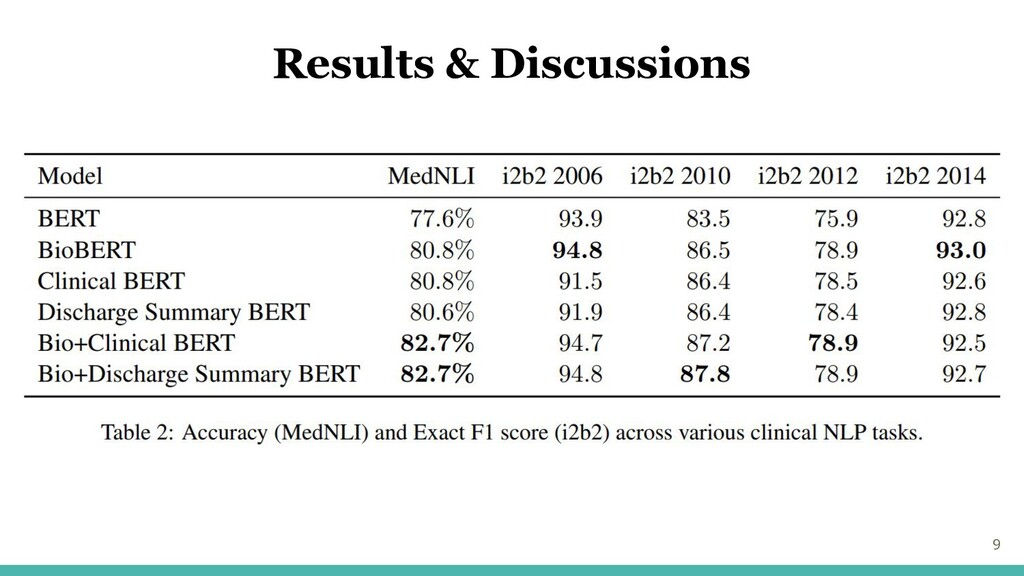
9 Results & Discussions
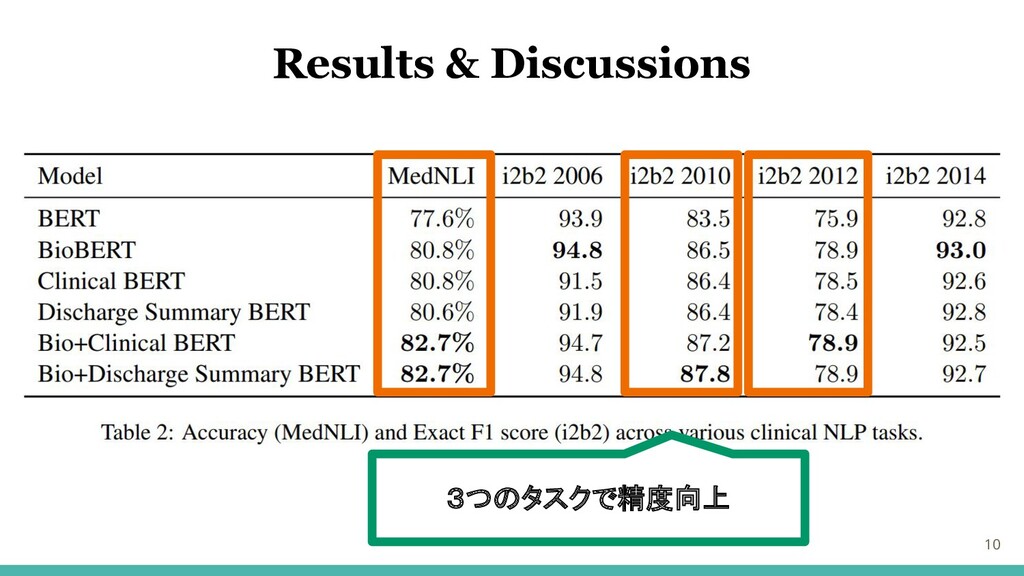
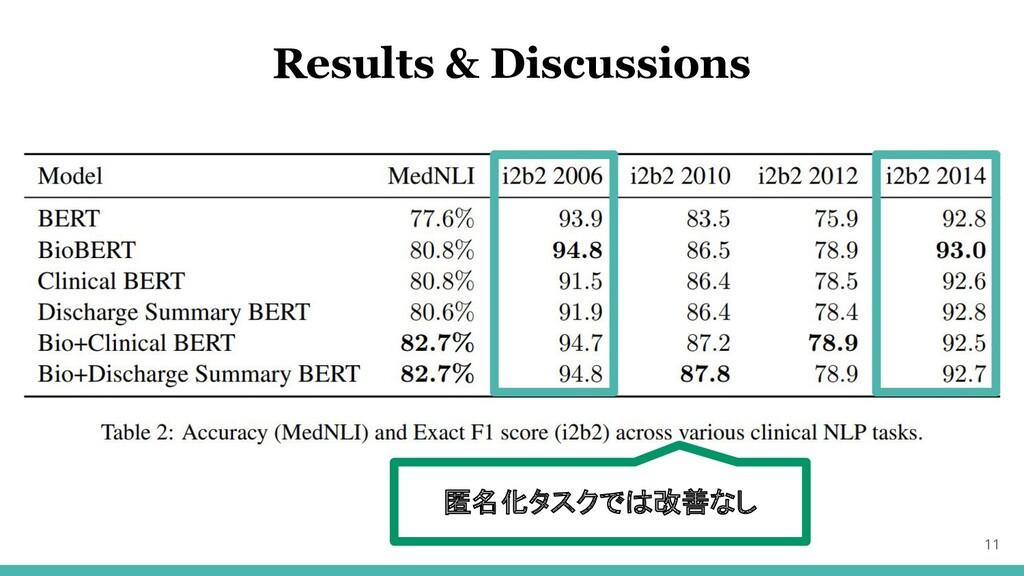
10 Results & Discussions 3つのタスクで精度向上
11 Results & Discussions 匿名化タスクでは改善なし
BioBERTおよびClinical BERTの3つのカテゴリからの3つの最近傍単語 12 Results & Discussions
BioBERTおよびClinical BERTの3つのカテゴリからの3つの最近傍単語 13 Results & Discussions BioBERT: 臨床テキストに関連するのは1つのみ Clinical BERT:
3つ全ての単語が臨床の文脈
・埋め込みの上にこれ以上の高度なモデルアーキテクチャを試していない 精度向上の余地がある ・MIMICには単一医療機関(BIDMC)の集中治療室のメモのみが含まれる 施設間で診療慣行の違いがある 複数の施設のメモを使用することで精度向上の可能性 ・調査したいずれの匿名化タスクも改善されていない 匿名化タスク用に適したコーパスを使用することで解決する可能性 14 Limitations &
Future Work
・臨床テキストでBERTモデルを学習し調査 ・Clinical BERTは匿名化以外の3つのタスクで精度向上 ・臨床分野テキストでの学習済BERTモデルを公開 臨床分野では他にない 訓練に必要な膨大な計算コストを回避可能 15 Conclusion
Appendix 16
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}