Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
文献紹介_202001_A Novel System for Extractive Clini...
Search
Sponsored
·
SiteGround - Reliable hosting with speed, security, and support you can count on.
→
T.Tada
January 20, 2020
Technology
190
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
文献紹介_202001_A Novel System for Extractive Clinical Note Summarization using EHR Data
T.Tada
January 20, 2020
More Decks by T.Tada
See All by T.Tada
文献紹介_202002_Is artificial data useful for biomedical Natural Language Processing algorithms?
tad
0
75
文献紹介_201912_Publicly Available Clinical BERT Embeddings
tad
0
180
文献紹介_201911_EDA: Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks
tad
0
230
文献紹介_201910_Do Neural NLP Models Know Numbers? Probing Numeracy in Embeddings
tad
0
110
文献紹介_201909_Sentence Mover’s Similarity_ Automatic Evaluation for Multi-Sentence Texts
tad
0
170
文献紹介_201908_Medical Word Embeddings for Spanish_ Development and Evaluation
tad
0
73
文献紹介_201907_Is Word Segmentation Necessary for Deep Learning of Chinese Representations
tad
0
120
文献紹介_201906_Predicting Annotation Difficulty to Improve Task Routing and Model Performance for Biomedical Information Extraction
tad
0
110
文献紹介201905_Context-Aware Cross-Lingual Mapping
tad
0
110
Other Decks in Technology
See All in Technology
Lightning近況報告
kozy4324
0
230
Oracle Cloud Infrastructure:2026年6月度サービス・アップデート
oracle4engineer
PRO
1
370
#エンジニアBooks 30分でわかる 「技術記事を書く技術」 / engineer-books 2026-06-30
jnchito
1
130
[AWS Summit Japan 2026]迷っているあなたへ_小さな一歩が、やがて自分を助けてくれる
sh_fk2
2
430
作る力から、見極める力へ — AI時代に広がるエンジニアの価値と役割
rince
0
360
Fabricをフル活用する AI Agent Hub -製造業特化AIエージェントの設計
iotcomjpadmin
0
150
「勝手に広まる」人気 AI エージェントを爆速で作ろう!(AWS Summit Japan 2026講演資料)
minorun365
PRO
10
2.6k
コミットの「なぜ」を読む
ota1022
0
120
UIパーツの設計を「型」から読み解く 〜TSKaigiのセッションから得た学び〜
yud0uhu
0
100
現場のトークンマネジメント
dak2
1
200
AI時代における最適なQA組織の作り方
ymty
3
160
AWS Security Hub CSPMの成功・失敗体験
cmusudakeisuke
0
580
Featured
See All Featured
SEO for Brand Visibility & Recognition
aleyda
0
4.6k
30 Presentation Tips
portentint
PRO
1
330
The B2B funnel & how to create a winning content strategy
katarinadahlin
PRO
1
400
The innovator’s Mindset - Leading Through an Era of Exponential Change - McGill University 2025
jdejongh
PRO
1
210
Crafting Experiences
bethany
1
190
職位にかかわらず全員がリーダーシップを発揮するチーム作り / Building a team where everyone can demonstrate leadership regardless of position
madoxten
62
55k
技術選定の審美眼(2025年版) / Understanding the Spiral of Technologies 2025 edition
twada
PRO
118
120k
Dealing with People You Can't Stand - Big Design 2015
cassininazir
367
27k
Testing 201, or: Great Expectations
jmmastey
46
8.2k
Darren the Foodie - Storyboard
khoart
PRO
3
3.4k
HU Berlin: Industrial-Strength Natural Language Processing with spaCy and Prodigy
inesmontani
PRO
0
420
[Rails World 2023 - Day 1 Closing Keynote] - The Magic of Rails
eileencodes
38
2.9k
Transcript
- 文献紹介 2020 Jan. 20 - A Novel System for
Extractive Clinical Note Summarization using EHR Data 長岡技術科学大学 自然言語処理研究室 多田太郎
About the paper 2 Authors: Conference: Proceedings of the
2nd Clinical NLP 2019
・電子健康記録(EHR)内の患者のケアと管理に関する情報は埋もれている ▷医師が通常のワークフロー中にレビューすることは難しい ・臨床記録に関する疾患固有の抽出型要約タスクに取り組む ▷主に医師や看護師による記録に焦点を当てる ・EHR固有の特徴量を追加することでシステム全体のパフォーマンスが向上 3 Abstract
・EHRは、患者の健康情報の長期的な記録 ・構造化された(バイタルなど)情報 ・構造化されていない(退院サマリなど)情報 で構成される ・EHRへの移行により、意図せず記録が増大 ▷テンプレートやコピーペーストなどにより、不必要または冗長なデータが ・EHR内の重要な情報はユーザー(医師など)によって異なる 4 Introduction
・最終的な目標は医師が作成した要約に近い要約の出力 ・患者の高血圧または糖尿病に関する重要な情報に焦点を当て要約 ▷抽出型要約に取り組む ・言語資源が少ない 5 Introduction
・高血圧および/または糖尿病の既知の診断を含むアメリカの大規模なEHRで構成 ▷患者EHR内で医師または看護師が作成した記録を使用 ▷選択した記録の約半分を手動で内容確認 ・得られたコーパス: ▷3,453人の外来患者の臨床記録、1つの記録あたり平均138文 ▷12人の内科医または家庭医によって重要な箇所に注釈付け ▷各文書2人が注釈、3人目の医師がチェック ▷文書毎にだいたい4〜5文が選定 ・注釈する情報は、疾患に焦点を合わせた要約として提示されるものを想定 6
Data
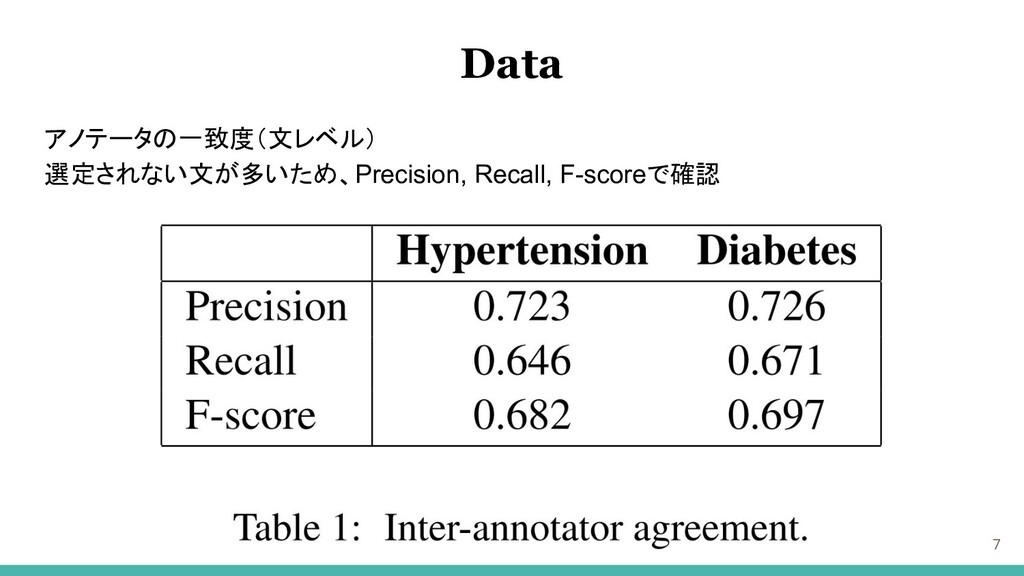
アノテータの一致度(文レベル) 選定されない文が多いため、Precision, Recall, F-scoreで確認 7 Data
8 Data
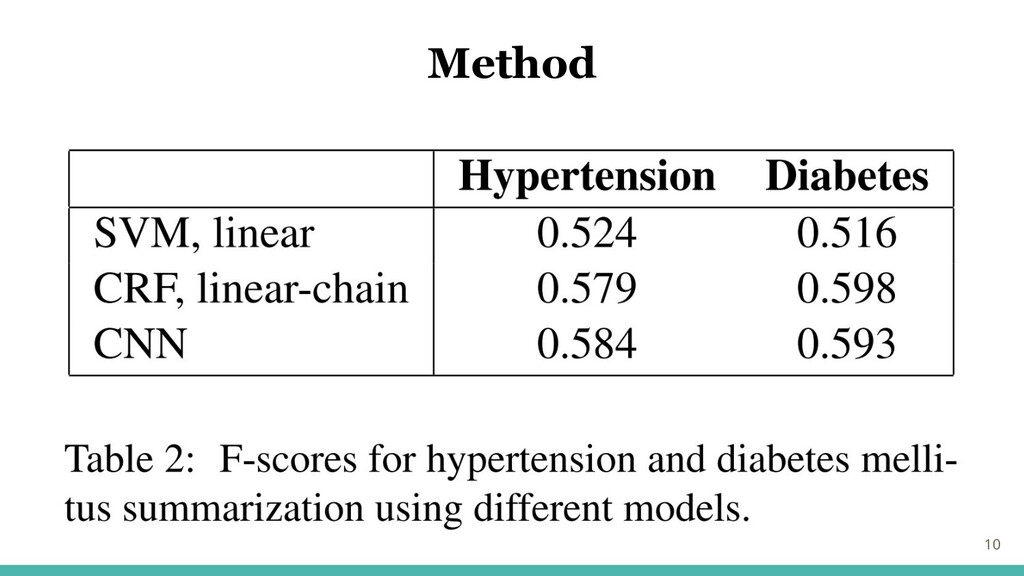
・SVM、Linear-chain CRF、CNNで実験 ・臨床記録では、文は短いことも多く、意味は文脈に依存 ・トレーニングデータの各文書中に要約として注釈が付けられているのは3% (平均138の文) 9 Method
10 Method
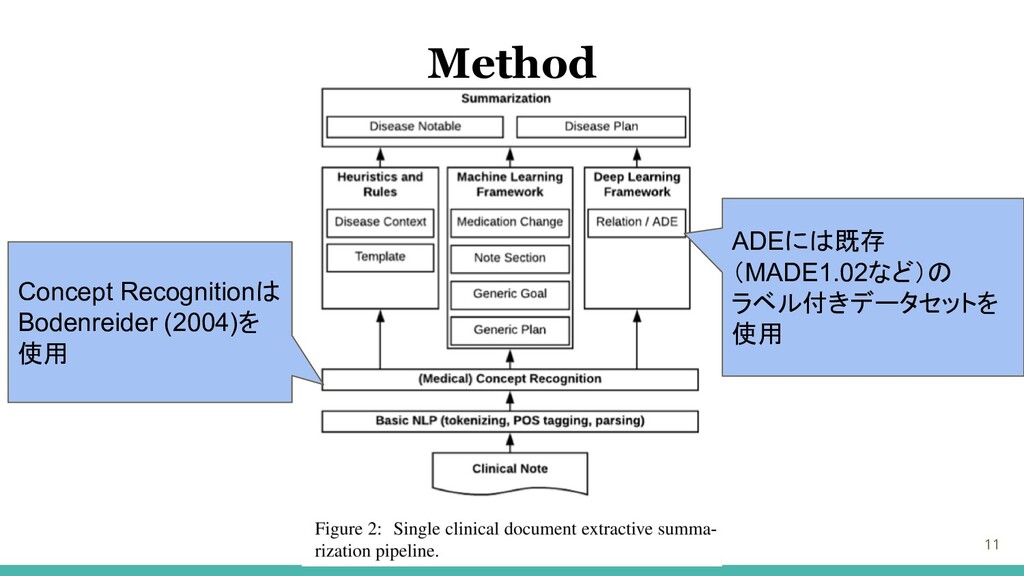
11 Method Concept Recognitionは Bodenreider (2004)を 使用 ADEには既存 (MADE1.02など)の ラベル付きデータセットを
使用
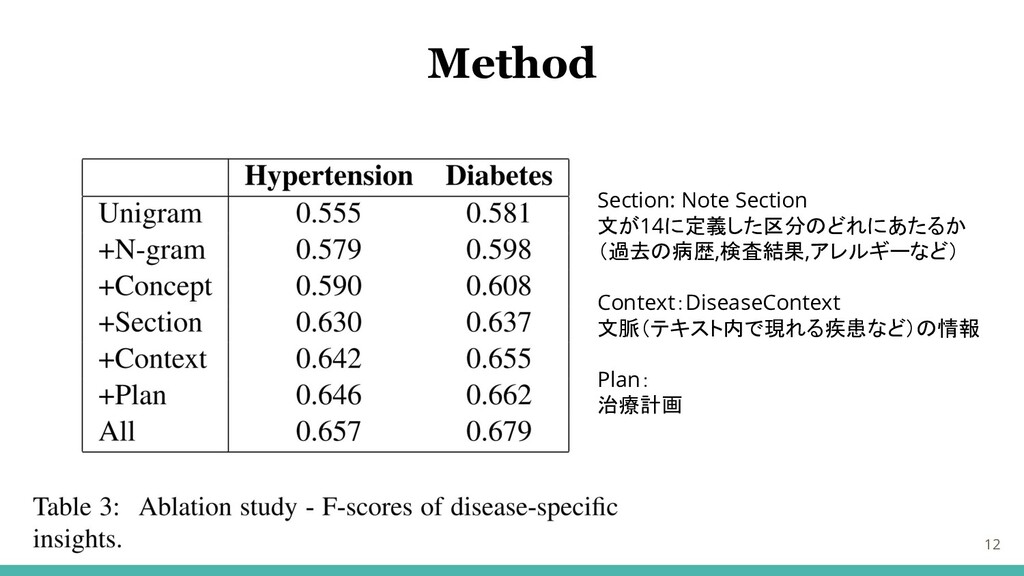
12 Section: Note Section 文が14に定義した区分のどれにあたるか (過去の病歴,検査結果,アレルギーなど) Context:DiseaseContext 文脈(テキスト内で現れる疾患など)の情報 Plan: 治療計画
Method
1.Reasons for Annotator Differences 2.Addressing Issues of Data Scarcity 3.Limitations
in Evaluation 13 Discussion
1.Reasons for Annotator Differences ・参照要約には主観的な要素が残る ・医師2人の注釈でも、何を要約に必要な情報とするかが別れる ・これは、タスクの固有の性質であり、システムで使用する一貫した参照文が必要 ▷3人目の医師の重要性を示している 14 Discussion
2.Addressing Issues of Data Scarcity ・薬物に関する事象(ADE)には既存(MADE1.02など)のラベル付きデータセットを使用 ・既存のデータ・セットも活用することが重要 15 Discussion
3.Limitations in Evaluation ・今回は臨床要約に含めるべきかどうかの微妙な違いを完全には把握していない ・例:薬物に関連する事象(ADE) ▷患者の安全性に大きな影響を与える、重要な情報 ▷患者のケアを管理する際に必要となる、まれなイベント ▷文の重要性は文書の外の知識に依存 ▷他のドメインからの一般的な要約アルゴリズムがすぐに機能しない理由のひとつ 16
Discussion
・臨床記録からの抽出型要約のための自動化システムを提案 ・臨床記録を対象としたパイプラインについて説明 ・豊富なラベル付きデータセットが利用可能になるまでは有用 17 Conclusion
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}